驾驶员之间的沟通常常远超于转向灯和刹车灯的使用,很多情况下都依赖于人与人之间的交流,而并非汽车技术,比如,示意另一辆车继续前行、观察另一位驾驶员是否注意到了自己、友好地向对面的车挥手等。
在不久的将来,自动驾驶汽车(AV)必将与人类驾驶员共存,因此它们需要能够理解这种行为,才能做出不阻碍交通的安全决策。
为了在训练中解决这一挑战,开发者必须能够预测其他车辆的未来运动会如何受到自动驾驶汽车行动的影响。NVIDIA Research团队在最近发表的一篇论文中介绍了一种交通建模方法——Trajeglish,其能够以语言模型对单词和短语进行标记的方式,来对车辆运动进行标记化处理,以此实现逼真的多车辆驾驶场景仿真。
在 Waymo 仿真智能体挑战赛(Waymo Sim Agents Challenge)的第一轮(V0)中,与其他16个交通模型相比,使用这种标记化处理方法生成的交通轨迹最为逼真,比之前最先进的模型高出3.3%。
如同语言模型将段落分解成单词和短语一样,Trajeglish通过将每个场景分解成标记来模拟多智能体交通场景。这种方法可以考虑每个智能体和轨迹之间的相互关系,并根据它们的初始位置对运动进行预测,以涵盖所有可能发生的交互。
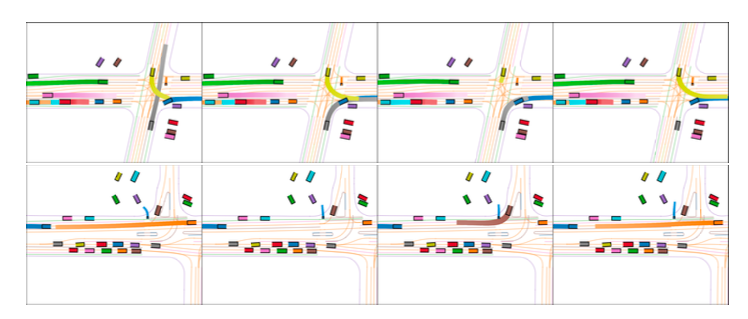
图 1. Trajeglish 仅根据行车日志的初始时间步而建模的场景,黑色标记处用于提示模型的初始状态。
在只有现实场景初始时间步的情况下,Trajeglish也能严格按照日志数据,真实仿真其他车辆如何对自动驾驶汽车的行动做出反应。
模拟人类行为
在单车道高速公路场景中,模拟人类的驾驶行为相对简单,因为在此类场景中很少有交叉路口、物体或行人。
但在城市环境中,由于交通流量和道路种类的增加,模拟多辆车的难度要大得多。为了建立适用于更广泛场景的交通模型,近期的方法都在追求模仿行车日志中所观察到的驾驶行为。
为了在仿真中做到这一点,需要对一个智能体在每个时间步中的实际行动进行采样,所采样的行动必须符合“时间步内依赖关系”,即对应所有其他智能体在该时间步所选择的行动。
现实世界中的各行为主体都具有独立的行为,但在交通模型中,由于记录行车日志的时间步不连续,因此时间步之间的任何交互都会表现为协调行为,这使得时间步内依赖关系变得十分必要。通常不会记录在日志数据中的交流,如眼神接触或转向灯等,也会使记录场景中的行为主体之间表现出协调。
Trajeglish需要清楚地模拟这种时间步内依赖关系。为此,Trajeglish采用与语言模型相同的方式对给定场景进行标记化处理,使模型能够根据场景情境只预测可能的轨迹或标记。然后,Trajeglish通过分析所有标记化场景的分布,模拟该时间步中的下一步行动。
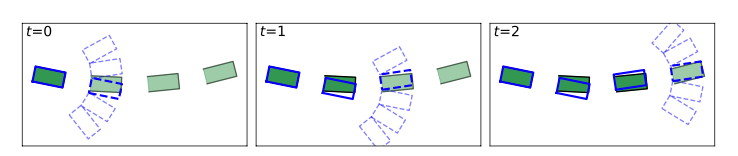
图2. Trajeglish通过迭代找到与下一状态角距离最小的标记对轨迹进行标记化处理。
这个预测下一个标记的过程会不断重复。在对一定数量的标记进行采样后,Trajeglish就能掌握足够的上下文,对各种长度和任意数量智能体的场景进行预测。
领先方法
Trajeglish 与 Waymo 仿真智能体 V0排行榜上的其他16个模型进行了比较,每个模型的任务是根据1秒钟的初始驾驶信息,为最多128个智能体同时对32个场景一致的轨迹进行仿真。
该挑战赛根据分布匹配度来评估每个仿真的真实性,计算出这些仿真场景的若干统计数据,并与在记录场景中计算出的这些统计数据进行比较。数据越接近,得分就越高。
根据Waymo的参数,作为唯一使用标记化处理方法的模型,Trajeglish得出的结果最为真实。从质量上看,在智能体互动密集的场景中,Trajeglish的性能遥遥领先,比如交通拥堵、并线场景和四向停车路口等。
Waymo排行榜对每个模拟的三个方面进行评估,分别为运动学(如速度等)、交互或与最近车辆的距离,以及轨迹是否保持在可行驶区域内。整体逼真度为这些类别的加权平均值。
根据这些参数,Trajeglish在场景整体逼真度方面比以前的最先进模型提高了 3.3%,在交互方面提高了9.9%。
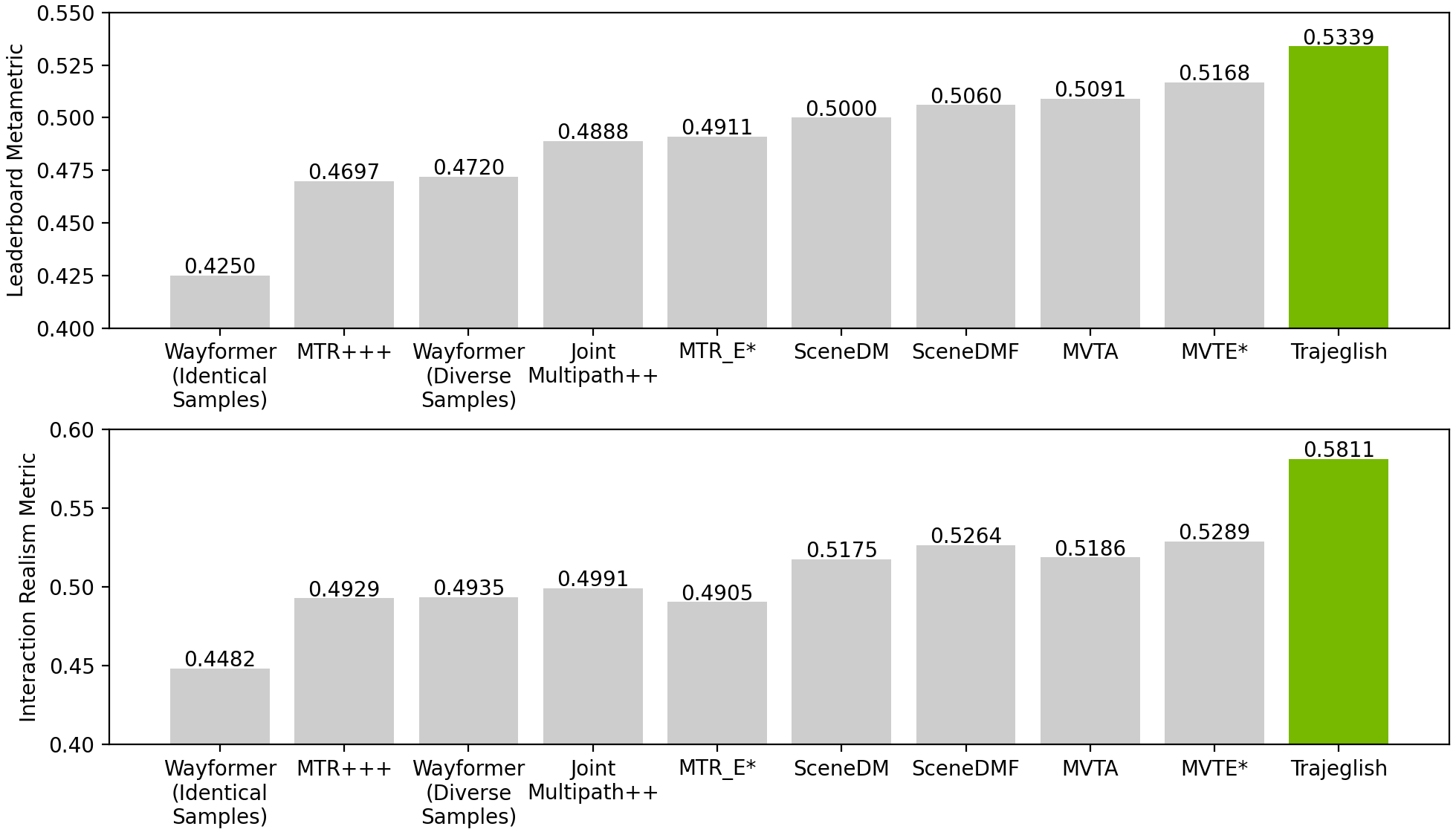
图3. Trajeglish与Waymo仿真智能体挑战赛其他参赛模型的成绩对比(标有星号的是使用集成技术的参赛模型)
总结
人类的驾驶行为存在着很多细微差别,这给仿真再现工作带来了巨大的挑战。由于语言模型可以应对人类语言中相似的复杂性,因此通过借鉴语言模型,可以使这项任务变得更加容易。
这使得自动驾驶汽车的开发者可以在仿真中使用保真度更高的交通模型来加速训练、测试和验证。
更多信息,请阅读论文全文以及Trajeglish:学习驾驶场景语言项目页面(https://research.nvidia.com/labs/toronto-ai/trajeglish/)。
相关资源
- GTC session: Data-Driven AV Development: Data Management and MLOps (Spring 2023)
- GTC分会:数据驱动的自动驾驶汽车开发:数据管理和MLOPs(2023年春季)
- GTC session: Navigating the AV Landscape: Balancing Safety, Innovation, and Regulation (Spring 2023)
- GTC分会:驾驭自动驾驶汽车环境:平衡安全、创新和监管(2023年春季)
- GTC session: Accelerating AV Development with AI, Simulation, and Synthetic Data (Spring 2023)
- GTC分会:使用AI、仿真和合成数据加速自动驾驶汽车的开发(2023年春季)
- Webinar: Accelerate AV Development with DGX Cloud and NVIDIA AI Enterprise
- 网络研讨会:使用DGX Cloud和NVIDIA AI Enterprise加速自动驾驶汽车的开发
- Webinar: Inception Workshop 101 – Getting Started with Conversational AI
- 网络研讨会:Inception入门研讨会:对话式AI入门
- Webinar: Exploring Efficient Tools for Autonomous Vehicle Development and Tuning
- 网络研讨会:探索用于自动驾驶汽车开发和调整的高效工具