在生成式人工智能中,机器不仅可以从数据中学习,还可以生成类似人类的文本、图像、视频等。检索增强生成 (RAG) 是一种突破性的方法。
RAG 工作流程基于 大型语言模型(LLM),可以理解查询并生成响应。但是,LLM 存在局限性,包括训练复杂性和缺乏当前 (有时是专有) 信息。此外,当未根据特定数据进行训练以回答提示时,它们往往会产生幻觉并合成事实错误的信息。RAG 通过向 LLM 提供企业特定信息来增强查询,以帮助克服这些限制。
在本文中,我们讨论了 RAG 如何助力企业为各种企业用例创建高质量、相关且引人入胜的内容。我们深入探讨了扩展 RAG 以处理大量数据和用户所面临的技术挑战,以及如何使用由 NVIDIA GPU 计算、加速以太网网络、网络存储和 AI 软件提供支持的可扩展架构来应对这些挑战。
RAG 使企业能够充分利用数据
典型的 RAG 工作流程使用 向量数据库,这类数据管理系统专为执行相似性搜索而定制,用于存储和检索与查询相关的企业特定信息。
通过将 RAG 集成到其信息系统中,企业可以利用大量内部和外部数据来生成具有洞察力的最新上下文相关内容。这种融合是一次重大飞跃,使企业能够利用其数据和领域专业知识,为个性化客户互动开辟新途径,简化内容创建,并提高知识用例的效率。
但是,在企业规模部署 RAG 会面临一系列挑战,包括管理数百个数据集和数千名用户的复杂性。这就需要一个能够高效处理此类大规模操作的处理和存储需求的分布式架构。
要扩展此架构,您必须嵌入、向量化数百万文档、图像、音频文件和视频并将其编入索引,同时还能适应每天嵌入新创建的内容。
另一个挑战是确保交互式多模态应用程序的低延迟响应。由于需要集成数据企业应用程序以及结构化和非结构化数据存储,因此需要实时处理和响应,而大规模实现这一目标可能具有挑战性。
生成式 AI 的数据索引和存储也构成了挑战。
传统企业应用可以压缩数据并将其存储以进行高效检索,以支持索引和语义搜索,而基于 RAG 的数据库可以扩展到比原始文本文件及其相关元数据大 10 倍以上。这将导致数据增长和存储方面的重大挑战。
为了获得最佳结果,企业必须投资加速计算、网络和存储基础设施,这对于处理训练和部署 RAG 模型所需的大量数据至关重要。
如何实现可扩展且高效的 RAG 推理
在 GTC 2024 上,NVIDIA 推出了 生成式 AI 微服务目录,为开发者提供用于创建和部署自定义 AI 应用的企业级基础模组。
企业可以将这些微服务用作创建 RAG 驱动的应用的基础。通过将其与 NVIDIA RAG 工作流程示例相结合,您可以加快生成式 AI 应用的构建和产品化过程。
在本文中,我们使用多节点 GPU 计算推理、加速以太网网络和网络连接存储对这些 RAG 工作流程示例进行基准测试。我们的测试结果表明,高性能网络和网络连接存储可实现高效且可扩展的生成式 AI 推理,使企业能够开发由 RAG 驱动的应用,在促进持续数据处理的同时,还可扩展到数千名用户。
图 1 显示了包含两个阶段和数据管线的 RAG 工作流程。
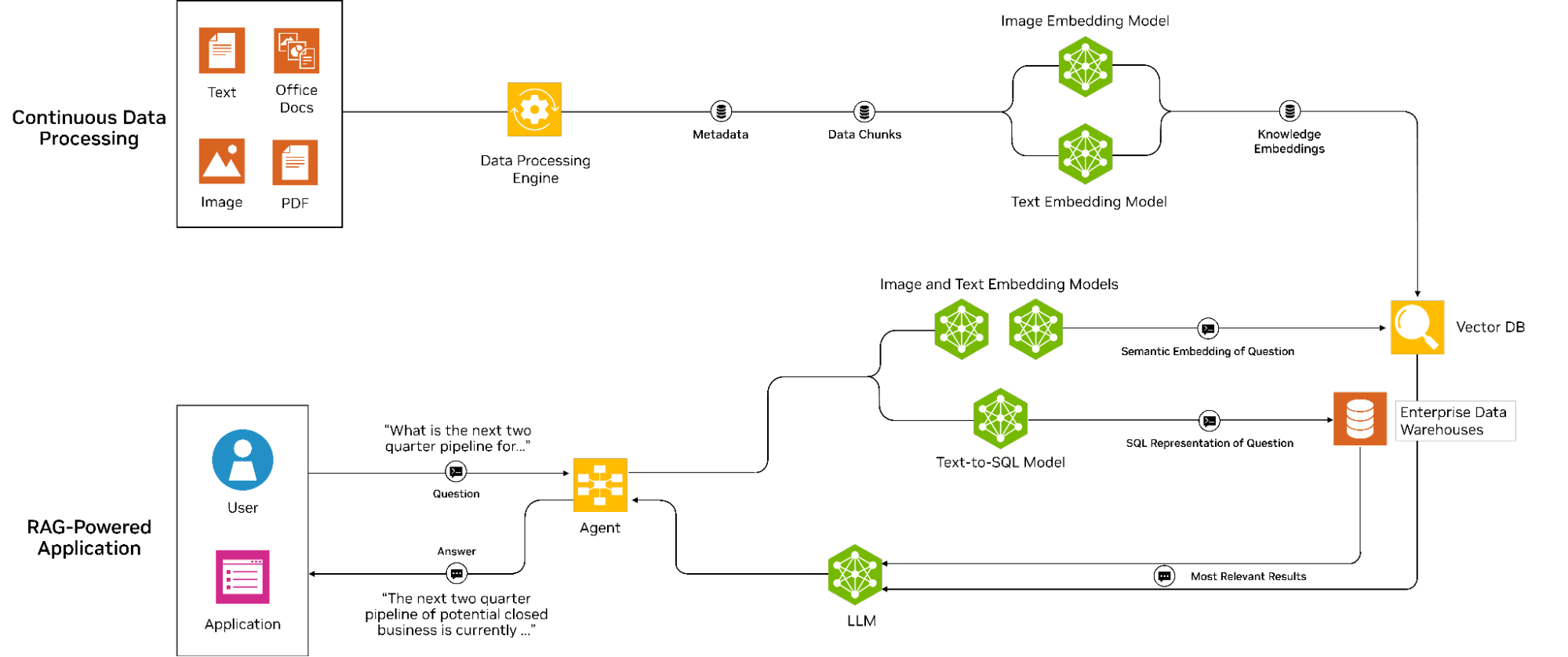
在第一阶段,数据提取将文档和其他数据模式转换为数字嵌入,然后在向量数据库中对其进行索引。此过程支持基于相似度分数高效检索相关文档。
查询阶段从用户输入问题时开始,该问题也会被转换为嵌入并用于在向量数据库中搜索相关内容。检索相关内容后,系统会将其传递给 LLM 进行进一步处理。原始输入问题以及增强上下文会提供给 LLM,LLM 会针对用户的查询生成更精确的答案。
此工作流支持有效检索和生成信息,使其成为适用于各种企业应用程序的强大工具。
加速的以太网网络、网络连接的存储擅长数据提取
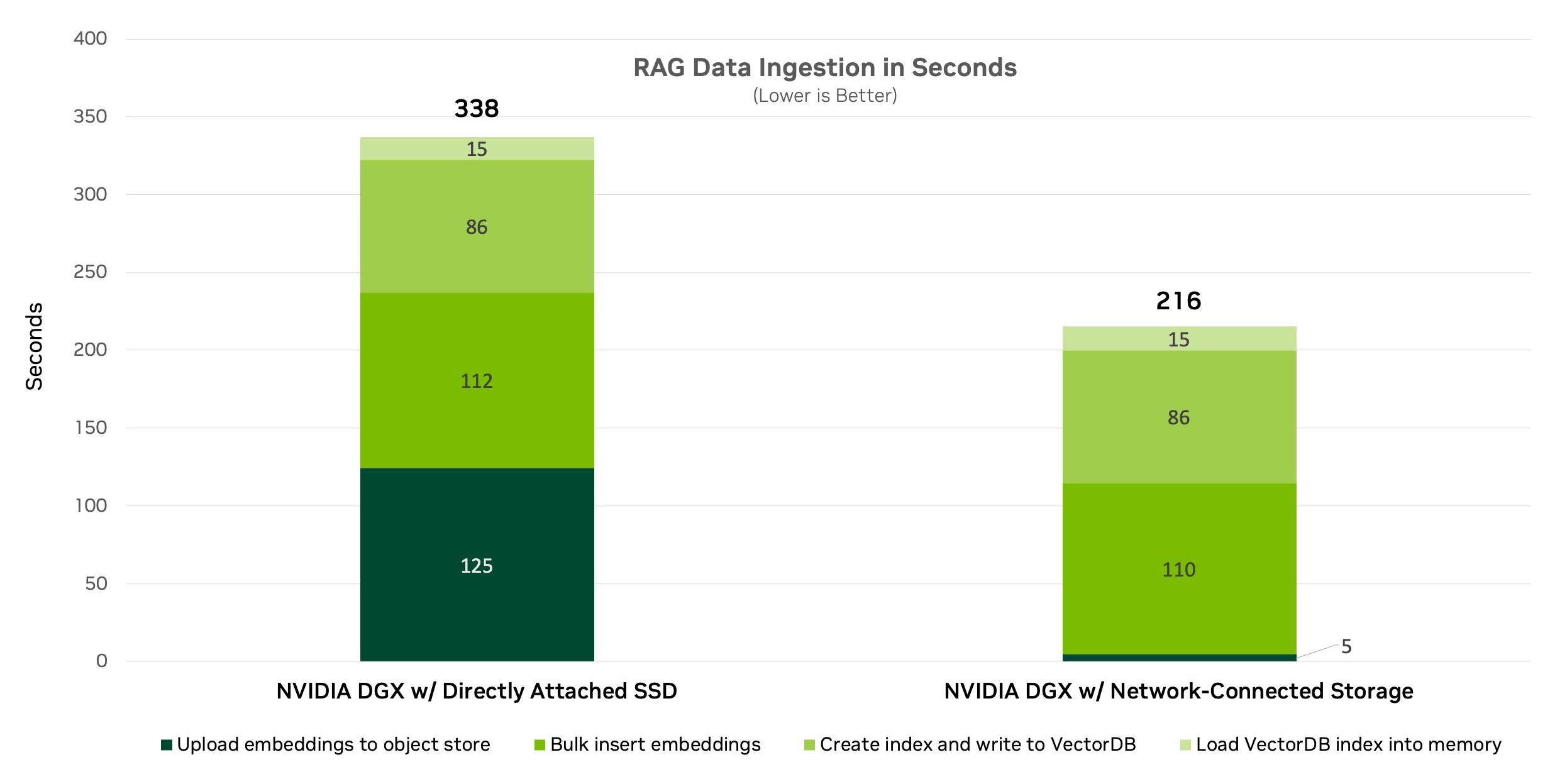
我们最初基于单个 GPU 节点测试了数据提取流程。图 2 显示了使用一个配备 8 块 A100 GPU 的 DGX 系统和一个专为对象存储工作负载设计的网络连接全闪存存储平台进行的测试设置。
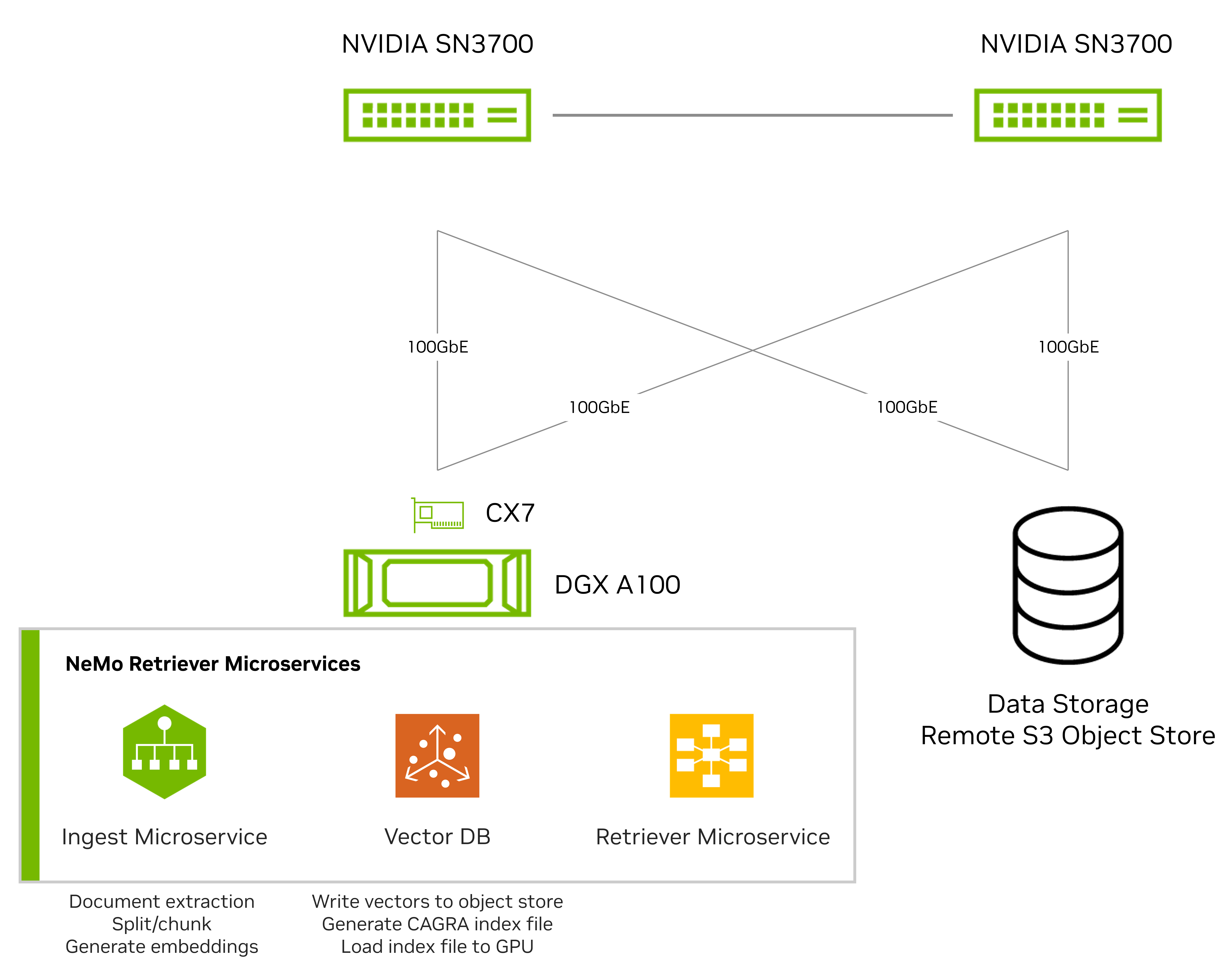
DGX 系统通过 NVIDIA ConnectX-7 网卡 使用加速的 NVMe-over-Fabrics (NVMe – oF) 和 Amazon S3 对象存储协议,并由两台 NVIDIA Spectrum SN3700 交换机连接。
我们使用 NeMo Retriever 微服务 对PDF文档(包括文本和图像)的嵌入和索引性能进行了比较。此次比较涉及DGX系统和网络连接存储中的直连存储(DAS)。
图 3 显示了单节点数据提取基准测试的结果。它显示,与使用 DAS 相比,使用 Amazon S3 的网络连接存储将数据提取速度提高了 36%,将处理时间缩短了 122 秒。这表明网络连接存储是更好的数据提取选择,同时还依赖于网络速度和延迟。
加速以太网网络对于提供稳健、高性能和安全的连接至关重要。除了增强文档嵌入外,网络连接存储还提供各种企业级数据管理功能。
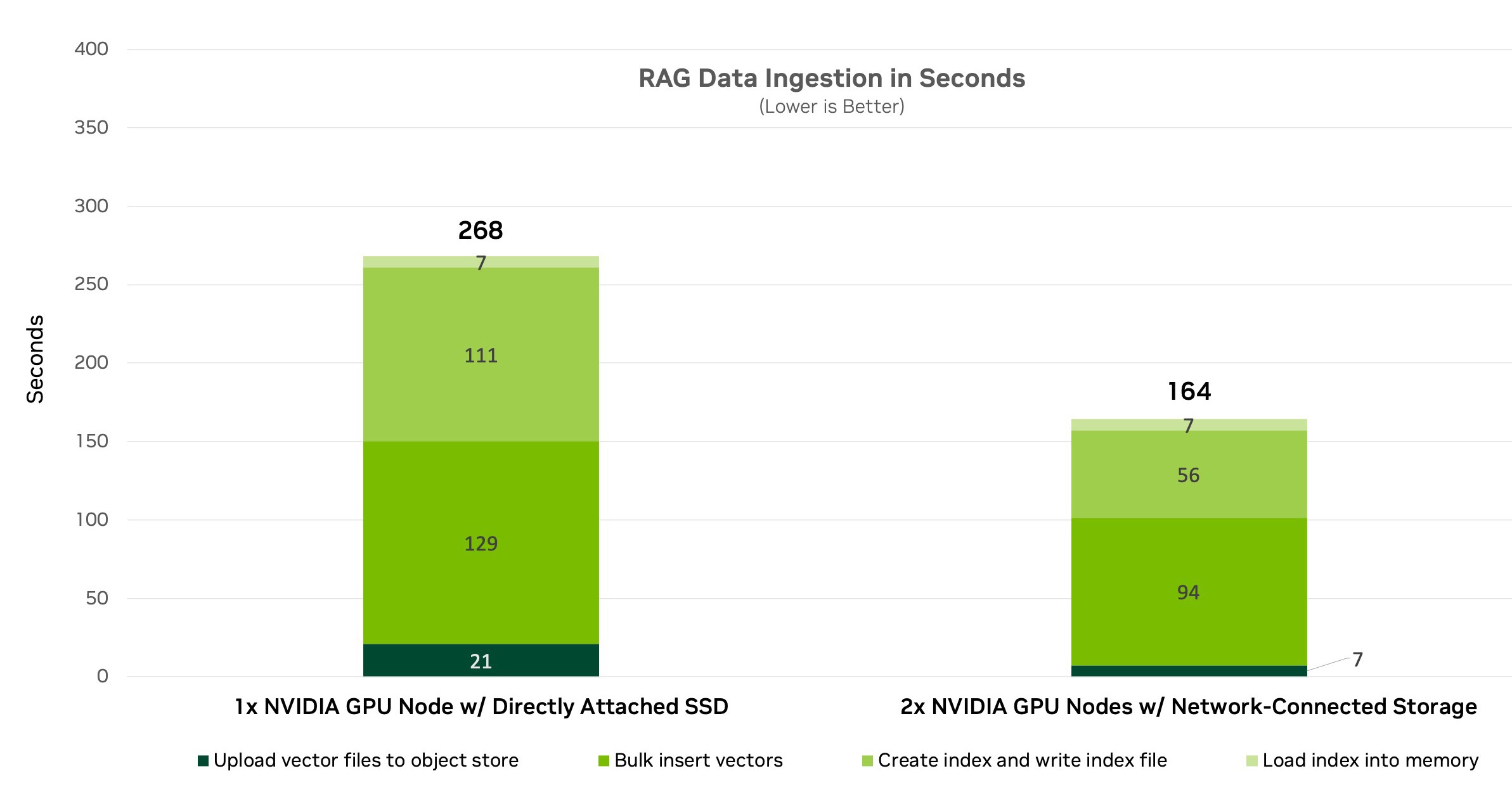
然后,我们使用多节点 RAG 设置进行测试,该设置使用通过 NVIDIA BlueField-3 DPU 连接的分布式微服务架构 (图 4)。随着多个节点并行运行,以上传嵌入、计算索引并插入向量数据库,性能也随之提升。
我们比较了在每台服务器中使用直接连接 SSD 与网络连接存储的性能。对于服务器内的 SSD,MinIO 充当对象存储层。对于网络连接存储,我们绕过 MinIO,测试了存储系统自己的原生 Amazon S3 对象接口。
结果表明,多节点提供的性能比使用单节点更快,处理时间缩短了近 102 秒。这些结果证明了多节点 GPU 加速与企业级网络连接存储相结合的性能优势。
适用于 RAG 驱动型应用程序的网络连接存储的优势
联网存储支持通过网络访问块、文件和对象,而无需直接将存储介质连接到服务器。
联网存储不仅为基于 RAG 的应用程序提供了明显的性能优势,而且还提供了额外的企业优势,使其成为增强自然语言处理的最佳数据平台。
适用于 RAG 工作流程的网络连接存储具有以下优势:
- 实时流数据提取:网络连接存储支持从各种来源(例如社交媒体、网络、传感器或物联网设备)提取实时流数据。RAG 应用程序可以使用这些数据生成相关的最新内容。DAS 可能无法处理大量且快速的流数据,或者可能需要额外的处理或缓冲来存储数据。
- 可扩展性:在不影响性能或数据可用性的情况下,通过添加更多磁盘或设备来扩展存储容量更容易。相比之下,DAS 的可扩展性有限,可能需要停机或重新配置以进行存储升级。
- 元数据标注:网络连接存储支持使用元数据(例如标签、类别、关键字或摘要)进行数据标注。RAG 应用可使用此元数据根据查询或上下文检索数据源并对其进行排名。DAS 可能不支持数据标注,也可能需要单独的数据库或索引来存储元数据。
- 利用率:网络连接存储(Network Attached Storage, NAS)可让多个用户和应用程序同时访问相同的数据,从而优化存储资源的利用率,而不会产生重复数据或冲突。相比之下,直接连接存储(Direct Attached Storage, DAS)可能会导致存储未充分利用或过度使用,具体取决于需求和特定服务器内的数据分配。
- 可靠性:网络连接存储通过使用高级独立磁盘冗余阵列 (RAID) 功能或其他方法来保护数据免受磁盘故障、网络故障或断电的影响,提高了可靠性和数据可用性。相比之下,直接连接存储在磁盘或服务器发生故障时,可能会丢失数据或损坏,因为 DAS 无法利用 RAID 或其他冗余技术。
- 删除重复内容:网络存储通过消除跨文件或设备的重复或冗余数据来减少存储空间和网络带宽。DAS 可能会存储相同数据的多个副本,从而浪费存储空间和网络资源。
- 数据来源引文:网络连接存储(Network Attached Storage, NAS)可以提供数据的来源引用,例如 URL、作者、日期或许可证。RAG 应用程序(基于规则和知识的应用程序)可以使用这些信息来对数据源进行属性识别和验证,并确保所生成内容的质量和可靠性。DAS(直接连接存储)可能不提供数据来源引用,也可能需要手动或外部方法来跟踪数据来源。
- 备份:连接网络的存储通过使用快照、复制或其他方法在不同位置或设备上创建数据副本来促进数据备份和恢复。DAS 可能需要手动或复杂的备份程序,这可能很耗时或容易出错。
- 数据保护和保留:网络连接存储通过使用加密、压缩或其他技术来保护数据免遭未经授权的访问或修改,从而确保数据保护和保留。它还使用策略、规则或法规来管理数据生命周期,例如数据的创建、删除或存档。相比之下,直接连接存储可能不提供数据保护和保留功能,或者可能需要额外的软件或硬件来实现数据安全和治理。
结束语
检索增强型生成通过利用生成式 AI 的强大功能 (通过企业特定的环境和信息增强),为企业利用数据提供了巨大的潜力。
但是,大规模部署 RAG 会带来诸多挑战,例如管理大型数据集、确保交互式应用程序的低延迟以及满足生成式 AI 的存储需求。
为了克服这些挑战,企业必须扩展其基于 RAG 的生成式 AI 基础架构。为了高效运行,此基础架构必须在整个数据中心堆栈 (加速计算、快速网络、网络连接存储和企业 AI 软件) 中进行适当的规模和架构设计。
生成式 AI 是一个快速增长的新领域。随着 RAG 的扩展以支持视频等新模式,数据处理需求继续快速增长。 NVIDIA 生成式 AI 微服务与多节点 NVIDIA GPU 计算推理、加速以太网网络和网络连接存储相结合,展示了企业级 RAG 推理的效率。
如需详细了解如何扩展基于 RAG 的生成式 AI 应用,请不要错过 NVIDIA GTC 2024:
- 通过优化的以太网 AI 网络实现企业生成式 AI – NVIDIA GTC 会议
- 所有 检索增强生成 GTC 会议
您可以通过注册 NVIDIA GTC或按需访问会话。