将大量文本库转换为数字表示 (称为嵌入) 的过程对于生成式 AI 至关重要。从语义搜索和推荐引擎到检索增强生成 (RAG) ,各种技术都依赖于嵌入来转换数据,以便 LLM 和其他模型能够理解和处理数据。
然而,为数百万或数十亿的文档生成嵌入需要大规模处理。Apache Spark 是应对这一挑战的首选框架,可在机器集群中巧妙地分发大规模数据处理作业。然而,虽然 Spark 解决了规模问题,但生成嵌入本身需要大量计算。加速这些作业以及时获得结果需要加速计算,这增加了配置和管理底层 GPU 基础设施的复杂性。
本文将介绍如何通过在配备无服务器 GPU 的 Azure 容器应用 (ACA) 上部署分布式 Spark 应用来解决此挑战。这种强大的组合使 Spark 能够熟练地编排大型数据集,而 ACA 则完全消除了管理和扩展计算的复杂性。在本示例中,我们构建了一个专用的工作容器,将 NVIDIA RAPIDS Accelerator for Spark 等高性能库与 Hugging Face 的开源模型打包在一起,从而创建灵活且可扩展的解决方案。
最终打造出无服务器、按使用付费的平台,为要求严苛的 AI 和数据处理应用提供高吞吐量和低延迟。这种方法提供了一个可以轻松调整的强大模板。对于寻求最大性能和支持的企业部署,可以使用 NVIDIA NIM 微服务替换自定义的 worker 来升级架构。
构建无服务器、分布式 GPU 加速的 Apache Spark 应用
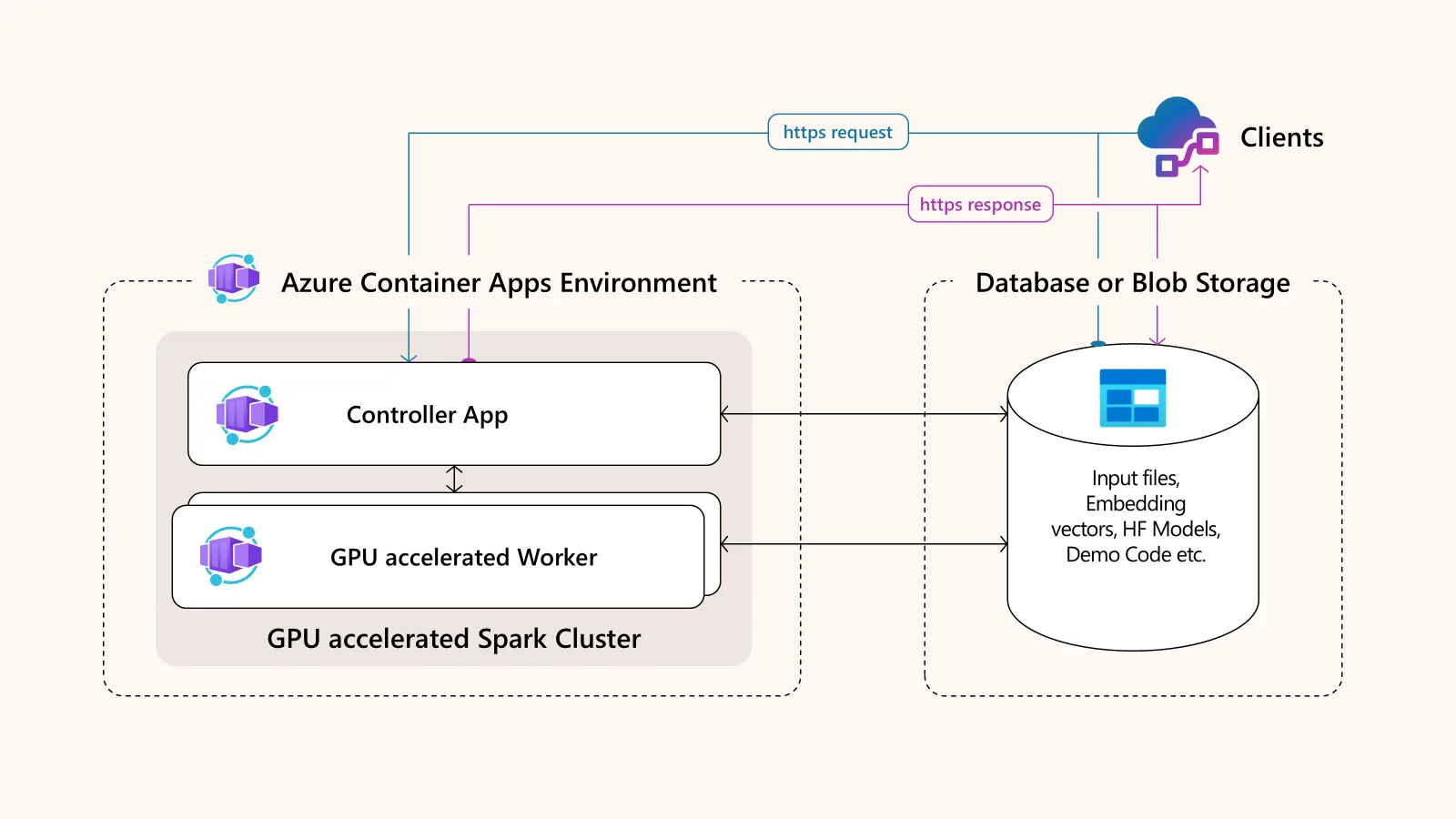
此解决方案的架构简单而强大,仅由两个主要的无服务器容器应用程序组成。这些应用程序部署在 Azure 容器应用程序环境中,可以协同工作。
其核心架构特性:
- Apache Spark 前端控制器 (主) 应用程序:在 CPU 上运行并编排工作。它还提供用于提交作业的端点,可以是用于开发的 Jupyter 接口,也可以是用于生产工作负载的 HTTP 触发器。
- 一个或多个 Spark worker 应用:这些应用经过 GPU 加速,并在 Azure 容器应用无服务器 GPU 上运行。它们执行繁重的数据处理任务,并可自动扩展以处理大量请求。
- 共享数据存储层:此层使用 Azure Files,允许控制器和工作者共享代码、模型和数据,从而简化开发和部署。
此设置旨在实现性能和便利性,使您能够轻松构建和测试复杂的分布式应用程序。
预备知识
开始之前,请确保您已完成以下内容:
- 可访问创建资源的 Azure 订阅。
- SQL Server 实例 ( Azure SQL 或 SQL Server 2022/ 2025) 以及包含文本数据的表格。
- 熟悉 Azure 容器应用、Apache Spark、Docker 和 Python。
- Azure 容器应用无服务器 GPU 的配额
- Azure-Serverless-GPU-Embedding GitHub 存储库中的示例代码。克隆此资源库以开始使用。
第 1 步:设置 Apache Spark 控制器应用
首先,部署 Spark 前端应用。控制器应用的主要目标是告知 Spark 工作节点要执行的任务和托管 Web 服务以接收请求。
构建容器镜像
此应用程序有两个协同工作的 Docker 容器,一个用于 Spark (主部分) ,另一个用于前端 (交互) 。Spark 容器将 SPARK_LOCAL_IP 环境变量设置为 0.0.0.0,以确保其可以接受来自任何网络上工作节点的连接。
前端容器有一个 SPARK_MASTER_URL 变量,使用端口 7077 将其设置为应用程序 URL。此外,它具有 APP_MODE 环境变量,允许您切换与 Spark 主程序的交互方式。您可以使用 Jupyter 进行开发和调试,使用 HTTP/ HTTPS 进行 API 模式。
您可以将自定义内容添加到 GitHub 存储库中提供的 dockerfile.master 和 dockerfile.interact 中,构建容器镜像,并将其推送到 Azure 容器注册表 (ACR) 。
创建控制器应用
现在,根据 ACR 中的两个镜像 ( Spark 主镜像和客户端交互) 创建控制器应用程序。要使用 GPU 加速,请根据可用的 NVIDIA GPU 大小创建 GPU 工作负载配置文件。请注意,NVIDIA A100 和 NVIDIA T4 GPU 目前由 Azure 容器应用程序提供支持。
使用可公开访问的 Azure 虚拟网络创建 Azure 容器应用环境,并将 GPU 工作负载配置文件附加到其中。此环境应将 Azure File Share 添加为卷挂载,用于存储输入数据、写入输出结果以及在 Spark 控制器和工作节点之间共享文件。
配置网络和扩展
通过启用入口并设置端口号,将应用程序配置为在其 REST API 端点的端口 8888 上接受公共 Web 流量。您还必须添加额外的 TCP 端口 7077,以便 Spark 节点彼此通信。对于调试,您可以选择在其他端口 (例如 8080) 上公开 Spark UI。必须始终将此控制器应用的比例设置为 1。
第 2 步:部署 GPU 加速的 Spark worker 应用
下一步是部署 Spark worker 应用。工作者应用将连接到主服务器,并负责执行实际的数据处理和 AI 模型推理。与单个控制器不同,您可以部署多个将自动连接到它的 worker。
构建工作容器镜像
此特定示例使用 Dockerfile.worker 构建工作容器,其中包含基础 NVIDIA 基础镜像、适用于 Apache Spark 的 NVIDIA RAPIDS 加速器库,以及从 Hugging Face 加载预训练开源嵌入模型 (all-MiniLM-L6-v2) 的应用代码。RAPIDS 加速器是一个库,可在不更改代码的情况下为 Spark 提供嵌入式加速,利用 GPU 显著加速数据处理和传统机器学习任务。
然后,您可以将此工作镜像推送到 ACR 中,以便部署。它应与控制器应用共享相同的 Azure 虚拟网络和存储。
请注意,虽然此示例展示了如何使用 Hugging Face 嵌入模型构建工作容器,但对于生产部署,您可以使用 NVIDIA NIM 微服务。NVIDIA NIM 微服务提供预构建、企业级支持的生产级容器,这些容器采用先进的 AI 模型,并将在 NVIDIA GPU 上提供最佳推理性能。
例如,NVIDIA NIM 微服务可用于 NV-Embed-QA 系列等功能强大的嵌入模型,该系列专为高性能检索和问答任务而构建。
创建工作应用
如上一节所述,使用构建的 worker 容器镜像创建 worker 应用。使用无服务器 GPU 工作负载配置文件在 Azure 容器应用程序 (ACA) 环境中部署应用程序。ACA 会自动处理 NVIDIA 驱动程序和 CUDA 工具包的设置,因此您可以专注于应用程序代码,而不是基础架构。
自动扩展
与控制器 (固定比例为 1) 不同,工作实例的数量是动态的。当大型数据处理作业开始时,ACA 可以根据负载自动扩展工作进程实例的数量。它可以在几分钟内从零快速扩展到多个 GPU 实例,以满足需求,关键是,可以将实例缩减到零,以避免为闲置资源付费。与始终开启的传统集群相比,这种方法可以节省大量成本。
工作应用没有 Ingress。一切都建立在内部沟通的基础之上。
第 3 步:运行分布式文本嵌入作业
随着 Spark 控制器和工作应用程序的运行,无服务器 GPU 加速的 Apache Spark 集群将处于活动状态,并随时准备处理数据。在本示例中,产品描述数据由 SQL Server 处理,文本嵌入使用由工作者 GPU 加速的 Hugging Face 模型生成,然后将结果写回 SQL Server 数据库。作业的提交方法因控制器 APP_MODE 环境变量而异,如第 1 步所述。
使用 Jupyter 连接 (开发模式)
如果将控制器应用程序环境变量 APP_MODE 设置为 tg_ 11,您可以导航至控制器应用程序的公共 URL,该 URL 将自动将 Jupyter notebook 连接到您共享的 Azure 文件存储。您可以在 Notebook 中创建 Spark 会话,通过 JDBC 连接到 SQL Server 数据库,然后执行嵌入作业。有关示例,请参阅 NVIDIA/ GenerativeAIExamples GitHub repo 中的 spark-embedding.pyJupyter notebook。
您还可以通过标准的 Spark UI 监控作业进度,您将在其中看到正在利用的工作进程以及在无服务器 GPU 上用于处理的 CUDA。
使用 HTTP (生产模式) 触发
要启用生产模式,请将控制器 APP_MODE 环境变量设置为 tg_ 13,以显示用于自动化的安全 HTTP 端点。然后,可以通过已调度的 Bash 脚本或使用 SQL Server 外部 REST 端点功能直接从数据库中启动嵌入作业。
一旦触发,控制器将完全自动化端到端工作流程。此工作流包括读取 SQL 表中的数据、将处理分配给 GPU worker,以及以可靠、免提的方式将最终嵌入写回目标表。
有关在生产模式下触发作业的示例,请参阅 trigger-mode.py 文件。请注意,您需要将占位符 URL 替换为已部署控制器应用程序的实际公共 URL。
开始使用无服务器分布式数据处理
通过在 Azure 容器应用无服务器 GPU 上部署自定义的 GPU 加速 Apache Spark 应用,您可以构建高效、可扩展且经济高效的分布式数据处理解决方案。这种无服务器的方法减轻了基础设施管理的负担,使您能够动态扩展强大的 GPU 资源,以满足 AI 工作负载的需求。
在同一架构内从基于 Jupyter 的交互式开发环境迁移到基于触发器的生产就绪型系统的能力提供了巨大的灵活性。这种开源工具和无服务器基础设施的强大组合为您提供了一条清晰的生产路径,以应对最苛刻的数据挑战。您可以通过采用 NVIDIA NIM 微服务进一步优化企业级性能和支持。
要开始部署该解决方案,请查看 NVIDIA/ GenerativeAIExamples GitHub repo 中提供的代码。如需了解详情并观看演示演练,请观看采用 Azure 容器应用无服务器 GPU 的安全新一代 AI 应用。