
组织正在以前所未有的速度将机器学习(ML)集成到整个系统和产品中。他们正在寻找解决方案,以帮助处理在生产规模部署模型的复杂性。
NVIDIA Triton Management Service (TMS) 是 NVIDIA AI Enterprise 独家提供的一款新产品,有助于实现这一目标。具体来说,它有助于管理和协调一支由 NVIDIA Triton Inference Servers 在 Kubernetes 集群中运行的团队。TMS 使用户能够扩展其 NVIDIA Triton 部署,以高效地处理各种各样的工作负载。它还改善了开发人员协调所需资源和工具的体验。
本文探讨了开发人员和 MLOps 团队在大规模部署模型时面临的一些最常见的挑战,以及 NVIDIA Triton 管理服务如何解决这些挑战。
扩展人工智能模型部署的挑战
任何规模的模型部署都会带来一系列挑战。开发人员需要考虑如何平衡各种框架、模型类型和硬件,同时最大限度地提高性能并与环境的其他组件接口。
NVIDIA Triton 是一个强大的解决方案,旨在处理各种问题,并从部署的机器中获取最佳的吞吐量和性能。然而,随着组织将人工智能纳入更多的核心工作流程,推理工作负载的数量和大小可能会超过单个服务器所能处理的。因此,模型部署必须进行扩展。新的部署规模带来了一系列新的挑战,包括管理分布式推理工作负载的成本和复杂性。
部署成本
随着部署更多的模型并为它们找到更多的用例,很快就有必要扩展部署以利用资源集群。一个简单的方法是在添加更多模型时保持集群的线性扩展,使所有模型始终处于活动状态并随时准备进行推理。
然而,这不是一种具有无限规模潜力的方法。当您可以选择提高当前可用硬件的利用率时,专注于扩展服务集群的容量可能会导致不必要的开支。您还必须应对在本地添加更多资源或在云中遇到配额限制的后勤挑战。
其他扩展方法可能看起来成本较低,但可能会导致急剧的性能权衡。例如,您可以等待将模型加载到内存中,直到推理请求到来,这会导致等待时间过长,并延长首次推理的时间。或者,您可能会过度投入计算资源,导致执行过程中上下文切换带来的性能损失,以及设备内存不足带来的错误。
通过对工作负载进行仔细的预规划和主机代管,您可以避免其中一些最糟糕的问题。尽管如此,这只会加剧大规模部署的第二个主要问题。
操作复杂性
在小规模和需要模型编排的流程开发的早期,手动配置和部署模型是可行的。但是,随着 ML 部署的扩展,协调所有必要的资源变得越来越具有挑战性。您需要管理何时启动或扩展服务器,在哪里加载特定模型,如何将请求路由到正确的位置,以及如何在环境中处理模型生命周期。
确定哪些模型可以共存为这些部署增加了另一层复杂性。如果同时加载到同一设备中,大型型号可能会超过 GPU 或 CPU 的内存容量。一些框架(如 PyTorch 和 TensorFlow )即使在卸载模型后也会保留分配给它们的任何内存,这导致当来自这些框架的模型与来自其他框架的模型一起运行时,利用率低下。
通常,不同的模型在资源分配和服务器配置方面会有不同的要求,因此很难在单一类型的部署上实现标准化。
具有成本效益的人工智能模型部署和扩展
Triton 管理服务通过三种主要策略来解决这些挑战:简化 Triton 推理服务器部署,最大限度地提高资源使用率,以及监控/扩展 Triton Triton 推理服务器。
简化部署
TMS 使用简化的 gRPC API 和命令行工具,自动化 Kubernetes 上 Triton 服务器实例的部署和管理。有了这些接口,您就不需要编写大量的代码或配置文件来创建部署、服务和 Kubernetes 资源。相反,您可以使用 API 或 CLI 轻松启动 Triton 服务器,并根据需要自动将模型加载到这些服务器上。
TMS 还采用分组的方法来优化 GPU 或 CPU 存储器利用率。这可以防止不同的框架(如 PyTorch 和 TensorFlow 模型)在同一服务器上运行时出现问题,并且无法释放未使用的 GPU 或 CPU ?存储器相互连接。
最大限度地利用资源
TMS 按需加载模型,并在不使用时使用租赁系统卸载模型,以确保模型不会在集群中保持不必要的活动状态。为了建立模型,您可以提交一个带有指定时间线或检查机制的 API 请求。如果正在使用该模型,系统将保持该模型可用;否则,它将被取下。
当有足够的容量时,TMS 也会自动在同一台设备上对模型进行主机代管。要启用此功能,您需要在部署期间预先指定模型的预期 GPU 内存使用情况。虽然还没有自动测量的方法,但您可以依靠Triton Model Analyzer以及其他基准测试工具来预测内存需求。这些功能使您能够在现有集群上运行更多的工作负载,从而节省成本,并减少获取更多计算资源的需要。
监控和自动缩放
由于高可用性的需求,TMS 会跟踪各种 Triton 服务器的运行状况和容量。自动缩放功能已集成到系统中,使 TMS 能够基于模型部署配置自动执行 Kubernetes Horizontal Pod 自动缩放。您可以指定用于自动缩放的指标,以及指示何时应进行缩放的条件。在多个 Triton 实例之间实现自动缩放时,也会应用负载平衡。
Triton 管理服务如何运作
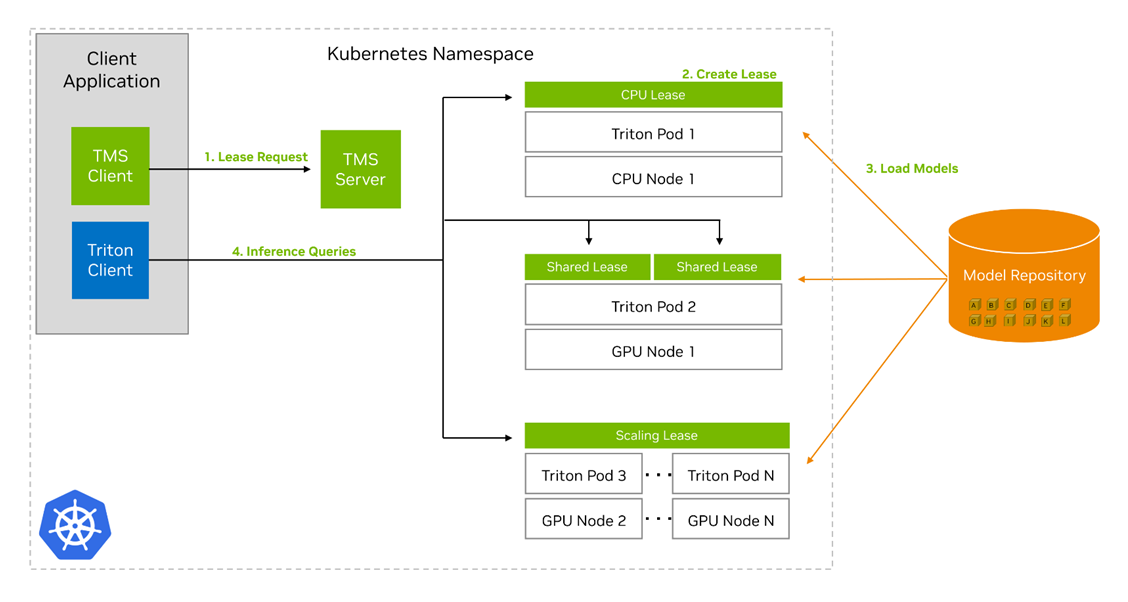
要安装 TMS,请将具有可配置值的 Helm 图表部署到 Kubernetes 集群中。这个 Helm 图将 TMS 服务器控制平面分解到集群中,同时还有一个包含 TMS 许多配置设置的配置图。您可以通过对 TMS 服务器的 gRPC API 调用或使用提供的 tmsctl 命令行工具来操作 TMS。
TMS 的关键概念是租赁租赁的核心是模型和一些相关元数据的分组,它们告诉 TMS 如何处理这些模型,以及它们的部署存在哪些限制。用户可以创建、续订和释放租约。创建租约需要通过唯一标识符从预定义的存储库中指定一组模型,以及元数据,包括:
- 计算租赁所需的资源
- 用于本租约的 Triton 的图像/版本
- 最短租赁期限
- 用于检测租约中模型活动的窗口大小
- 扩展租赁的指标和阈值
- 可以收集具有新租约的模型或租约的限制
- 可用于寻址的租约的唯一名称
TMS 服务器收到租约请求时,会执行以下操作以创建租约:
- 检查模型存储库,查看模型是否存在并且可以访问。
- 如果模型存在并且可以访问,请检查集群中是否存在符合新租约限制的现有 Triton 推理服务器。
- 如果不存在,请创建一个新的 Kubernetes pod,其中包含 Triton Inference Server container 和 Triton Sidecar container。
- 如果存在,选择一个现有的 Triton pod 来添加租约。
- 在任何一种情况下, Triton Pod 中的 Triton Sidecar 都会从存储库中提取租约中的模型,并将其加载到其配对的 Triton 服务器中。
TMS 还将创建其他几个 Kubernetes 资源,以帮助租赁的管理和路由:
- A. 如果 Triton pods 挂了,部署后将使它们恢复。
- A. Kubernetes service 基于可用于寻址租约中的模型的租约名称。
- A. horizontal pod autoscaler 会根据在租约中定义的度量和阈值自动创建 Triton pods 的副本。
创建租约后,您可以使用 Triton Inference Server API 或现有的 Triton client 向服务器发送推理请求以供执行。无需任何修改,您就可以使用 Triton Management Service 部署的 Triton 推理服务器。
开始使用 NVIDIA Triton 管理服务
如果您想开始使用 NVIDIA Triton 管理服务并了解更多关于其特性和功能的信息,请查看 AI Model Orchestration with Triton Management Service 实验室 LaunchPad。该实验室提供对启用 GPU 的 Kubernetes 集群的免费访问,以及安装 Triton 管理服务并使用它部署各种人工智能工作负载的分步指南。
如果您有现有的兼容内部部署系统或云实例,可以申请一个 90 天的 NVIDIA AI Enterprise 评估许可证来试用 Triton 管理服务。如果您是 NVIDIA AI Enterprise 的现有用户,只需登录NGC Enterprise Catalog。



