
NVIDIA NeMo-RL 的初始版本通过 PyTorch DTensor(也称为 FSDP2)提供训练支持。该后端不仅实现了与 Hugging Face 生态系统的原生集成,还支持快速实验,并可通过 PyTorch 原生并行化技术(包括 FSDP2、张量并行、序列并行和上下文并行)实现高效扩展。
然而,当模型规模接近数千亿参数时,DTensor 方案逐渐显现出其局限性。大型模型的激活值会带来巨大的内存开销,导致重新计算成本过高,训练速度显著下降。此外,DTensor 方案缺乏针对 NVIDIA CUDA 的优化内核以及其他关键的性能增强功能,难以实现最优的吞吐量。这些挑战凸显了对更高效解决方案的迫切需求,而 NVIDIA Megatron-Core 库正是为应对这一需求而设计的。
探索最新的 NeMo-RL v0.3 版本,该版本包含详细的文档、示例脚本和配置文件,支持在 Megatron-Core 后端高效地对大型模型进行后训练。
使用 Megatron 作为后端进行强化学习
Megatron-Core 采用 GPU 优化技术与高吞吐量性能增强功能,专为大规模语言模型的高效训练而设计。其 6D 并行化策略可优化通信与计算模式,支持多种模型架构,实现训练过程的无缝扩展。
NeMo-RL 增加了对 Megatron-Core 的支持,使开发者能够在后训练阶段充分利用其优化功能。尽管 Megatron-Core 提供了丰富的底层配置选项,但对于初次接触该库的用户而言,手动配置这些参数可能颇具挑战。NeMo-RL 通过自动处理后台复杂的调优过程,显著简化了使用流程,并为用户提供了更简洁、直观的配置接口。
开始使用 Megatron 进行训练
启用基于 Megatron 的训练非常简单,只需在 YAML 配置文件中添加 policy.megatron_cfg 部分即可。
policy:
...
megatron_cfg:
enabled: true
activation_checkpointing: false
tensor_model_parallel_size: 1
pipeline_model_parallel_size: 1
...
optimizer:
...
scheduler:
...
distributed_data_parallel_config:
grad_reduce_in_fp32: false
overlap_grad_reduce: true
overlap_param_gather: true
average_in_collective: true
use_custom_fsdp: false
data_parallel_sharding_strategy: "optim_grads_params"
查看完整示例。
训练期间,配置文件中的所有参数都将传递给 Megatron。在将 Megatron 相关配置添加到配置文件并设置 enabled=True 后,即可开始模型训练。训练的启动方式与 DTensor 类似,具体操作可参考 README 或我们的 DeepScaleR 复现指南。
结果
基于 Megatron 的训练既支持密集模型,也支持专家混合(MoE)模型。下表列出了几种常用模型在使用 GRPO(Group Relative Policy Optimization)方法时的步骤时间细分,表中所示时间为各训练任务第 22 至 29 步的平均值。
| 模型 | 后端服务 | 节点 | 每个节点的 GPU 数量 | 总步数时间 (秒) | 策略训练 (s) | 改装 (s) | 生成 (s) | 获取 logprobs (s) | 平均值:每个样本生成的 token 数量。 |
| Llama 3.1-8B Instruct | Megatron | 1 | 8 | 112 | 28 | 5 | 58 | 18 | 795 |
| PyT DTensor | 1 | 8 | 122 | 38 | 4 | 57 | 19 | 777 | |
| Llama 3.1-70B Base | Megatron | 8 | 8 | 147 | 28 | 14 | 84 | 18 | 398 |
| PyT DTensor* | 8 | 8 | 230 | 97 | 15 | 82 | 28 | 395 | |
| Qwen3 32B** | Megatron | 8 | 8 | 213 | 68 | 7 | 96 | 40 | 3283 |
| Qwen3 30B-A3B** | Megatron | 8 | 8 | 167 | 50 | 12 | 78 | 23 | 3251 |
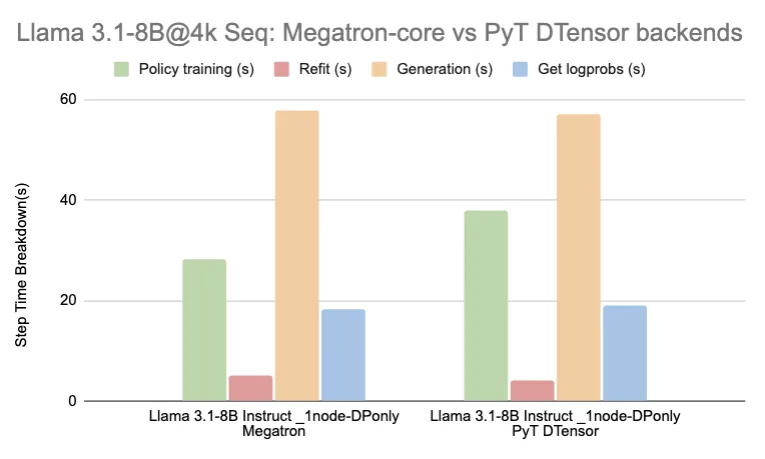

通过采用 Megatron-Core 提供的性能优化,我们在保持与 DTensor 相同收敛特性的同时,实现了更优的训练性能,如图所示。

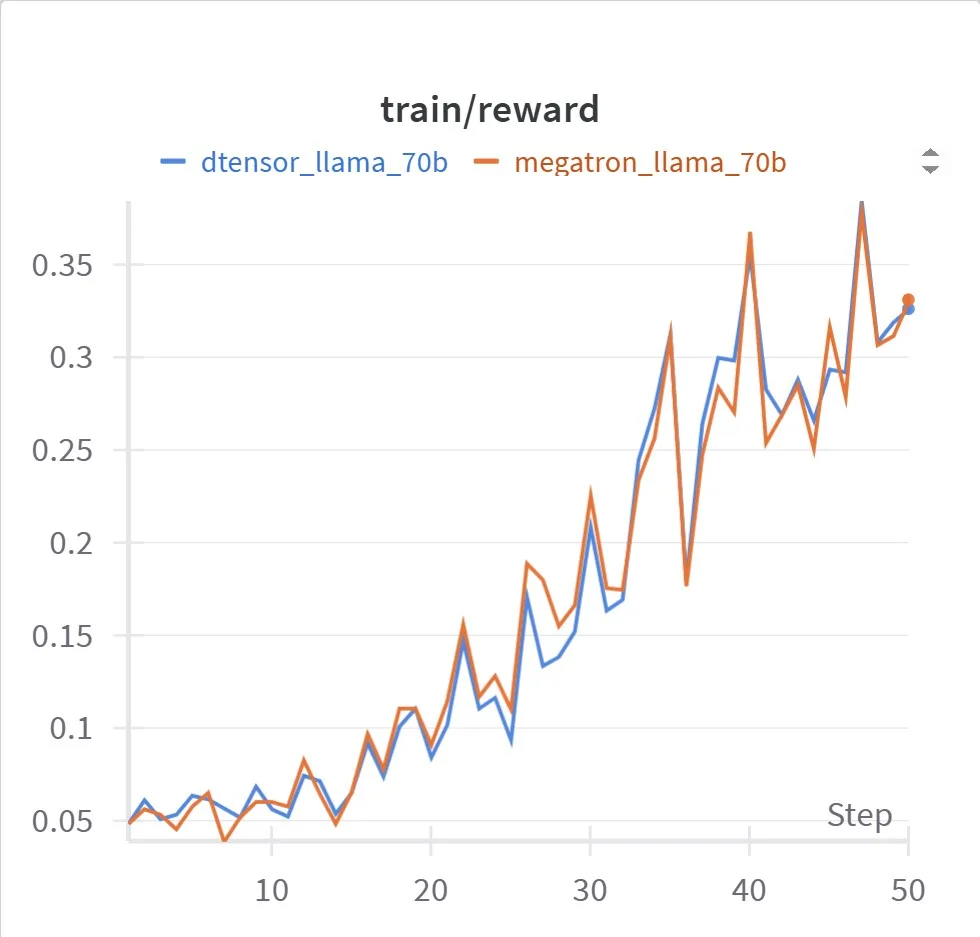
以下命令用于生成相应的奖励曲线:
## 8B -- requires a single node
## dtensor
uv run ./examples/run_grpo_math.py --config examples/configs/grpo_math_8B.yaml \
loss_fn.use_importance_sampling_correction=True
## megatron
uv run ./examples/run_grpo_math.py --config examples/configs/grpo_math_8B_megatron.yaml \
policy.sequence_packing.enabled=True loss_fn.use_importance_sampling_correction=True
## 70B -- requires 8 nodes
## dtensor
uv run ./examples/run_grpo_math.py --config examples/configs/grpo_math_8B.yaml \
policy.model_name=meta-llama/Llama-3.1-70B policy.tokenizer.name=meta-llama/Llama-3.1-70B-Instruct \
policy.generation.vllm_cfg.tensor_parallel_size=4 policy.max_total_sequence_length=4096 \
cluster.num_nodes=8 policy.dtensor_cfg.enabled=True policy.dtensor_cfg.tensor_parallel_size=8 \
policy.dtensor_cfg.sequence_parallel=True policy.dtensor_cfg.activation_checkpointing=False \
loss_fn.use_importance_sampling_correction=True
## megatron
uv run ./examples/run_grpo_math.py --config examples/configs/grpo_math_70B_megatron.yaml \
policy.model_name=meta-llama/Llama-3.1-70B policy.tokenizer.name=meta-llama/Llama-3.3-70B-Instruct \
policy.sequence_packing.enabled=True loss_fn.use_importance_sampling_correction=True
这些运行采用了多项性能和收敛性优化功能,以确保实现最佳吞吐量和快速收敛。
- 序列打包: 多个序列被打包到
max_total_sequence_length中,这一操作称为序列打包。序列打包能够减少填充 token 的数量,尤其在序列长度差异较大时效果显著。对于 Llama 70B 模型,启用序列打包可将整体训练步骤时间缩短约一半,且不会影响模型收敛。该功能已由 Megatron-Core 和 DTensor 后端支持。有关 NeMo-RL 中序列打包的更多详细信息,请参阅我们的文档。 - 重要性采样:NeMo-RL 在训练和推理阶段采用不同的框架以实现最佳性能,但这可能导致两者在 token 概率上存在细微差异。为缓解这一问题,可使用重要性采样方法,该方法根据每个样本在推理与训练概率之间的关系,为其分配相应的权重。启用重要性采样有助于降低不同运行结果之间的方差,并提升 Megatron-Core 与 DTensor 策略之间的一致性。有关 NeMo-RL 中重要性采样的更多详细信息,请参阅我们的文档。
长序列支持
我们还可以结合使用 Megatron-Core 和 DTensor 实现上下文并行,以支持长上下文训练。例如,以下示例展示了 Llama 3.3 70B 在使用 Megatron 后端、序列长度为 16k 时的当前性能表现。我们同样支持更长的序列长度,并正在持续优化长上下文训练的性能。
| 模型 | 最大序列长度 | 节点 (Node) | 每个节点的 GPU 数量 | 上下文并行大小 | 总步数时间 (秒) | 策略训练 (s) | 改装 (s) | 世代 (s) | 获取 logprobs (s) | 平均值:每个样本生成的 token 数量。 |
| Llama 3.3-70B Instruct | 16,384 | 16 | 8 | 4 | 445 | 64 | 17 | 287 | 75 | 749 |
表2:Llama 3.3-70B Instruct 在使用 Megatron 后端、16K 长上下文窗口下的性能表现
其他值得注意的功能
除了 Megatron 训练后端外,NeMo-RL V0.3 还引入了多项令人振奋的新功能,可有效支持各类模型的后训练。
- 异步部署:用户现在可通过设置
policy.generation.async_engine=True启用 vLLM 异步引擎,使多轮强化学习的速度提升 2 至 3 倍。 - 非同域生成(DTensor 后端):现在用户可以选择将训练和生成的后端部署在不同的 GPU 集群上。当训练与生成任务的并行化策略或世界大小不兼容,或在共置模式下因内存卸载不足而无法满足资源需求时,该功能尤为有用。更多详细信息请参见 0.3.0 版本说明。
即将推出
请密切关注以下即将推出的功能:
- 支持使用 Megatron 后端,可更高效地运行参数规模达数十亿的大型 MOE 模型,包括 DeepSeek-V3 和 Qwen3-235B-A22B。
- 高度优化的改装。
- FP8 生成支持。
- 支持 Megatron 和 DTensor VLM。
- 使用 Megatron-Core 后端进行非共置生成。
结论
本文展示了在使用 Megatron-Core 后端的 NeMo-RL v0.3 时,相较于 PyTorch DTensor,如何显著提升强化学习的训练吞吐量,尤其在 Llama 70B 等大规模模型上表现更为突出。通过 GPU 优化内核、4D 并行、序列打包和重要性采样等关键技术,NeMo-RL 有效保障了大模型训练的效率与收敛性。此外,我们还验证了其对长上下文训练的良好支持,即使在 16k 序列长度下仍能保持出色的性能表现。
探索 NVIDIA NeMo RL 的文档、示例配置和脚本,了解如何利用 Megatron-Core 优化大型模型的后训练。






