想象一下:你正在网上商店里浏览,寻找一双完美的跑鞋。但是有成千上万的选择,你从哪里开始呢?突然,一个“为您推荐”区域吸引了你的眼球。你很感兴趣,点击一下,几秒钟内,就会出现一个根据你独特喜好定制的跑鞋列表。就好像网站了解你的品味、需求和风格。
欢迎来到推荐系统,这里尖端技术结合了数据分析,人工智能(AI),以及改变我们数字体验的魔力。
这篇文章深入探讨了推荐系统的迷人领域,并探讨了构建两阶段候选重新排序的建模方法。我提供了如何在代表性不足的语言中克服数据短缺的专业提示,以及如何实现这些最佳实践的技术演练。
构建两阶段候选人重新评级概述
对于每个用户,推荐系统必须从可能数百万个项目中预测出该用户感兴趣的几个项目。这是一项艰巨的任务。一种强大的建模方法称为两阶段候选重新排序。
图 1 显示了这两个阶段。在第一阶段,模型识别用户可能感兴趣的数百个候选项目。在第二阶段,模型将该列表从最有可能到最不可能进行排序。最后,该模型向用户建议最有可能的项目。
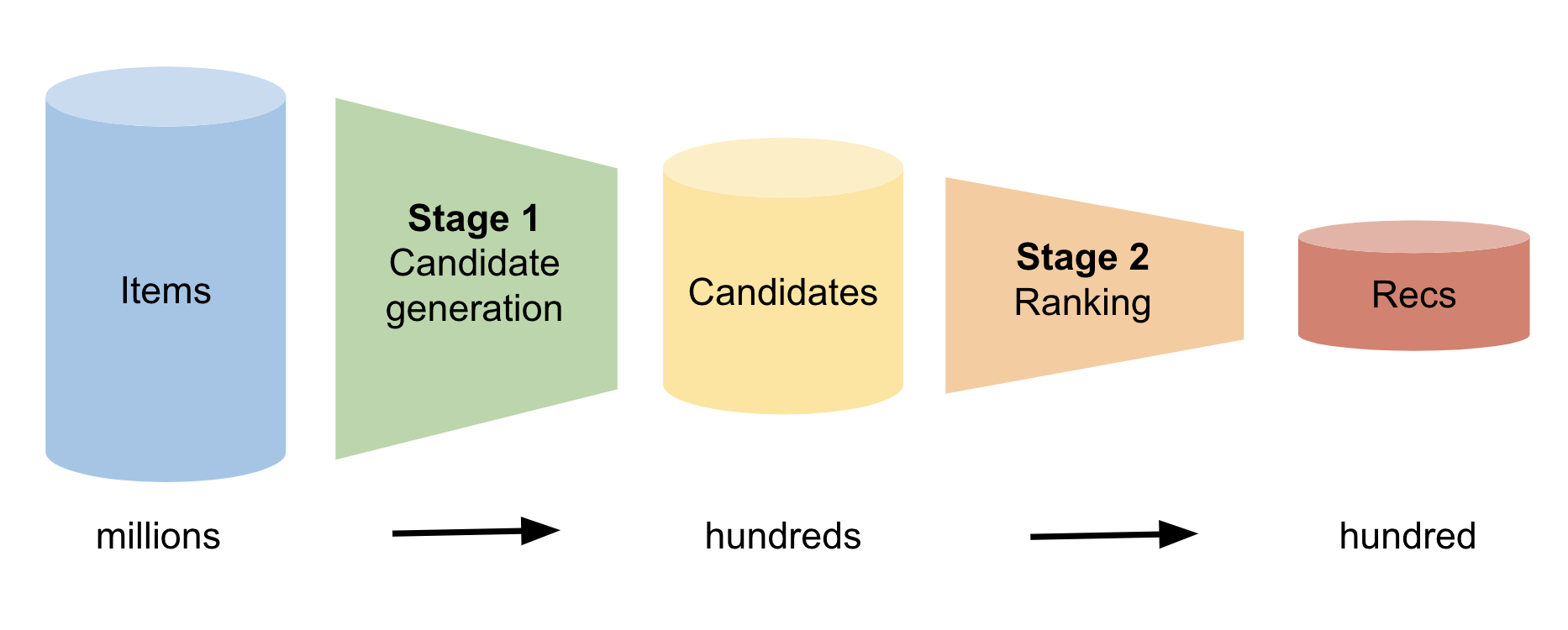
第 1 阶段:候选人生成
生成候选者的方法有很多,包括统计方法和深度学习方法。生成候选者的一种统计技术是构建共访问矩阵。您遍历所有用户历史会话,并维护每对项目在用户会话中共存的频率的累积计数。因此,您就知道了与每个项目经常配对的前 100 个项目。
现在,给定一个特定的用户,您可以通过迭代其用户历史记录并组合与其历史记录中每个项目相关联的所有前 100 个列表来生成候选项目。许多项目出现多次。候选者是这个由数百个项目组成的串联列表中最常见的项目。
第二阶段:排名
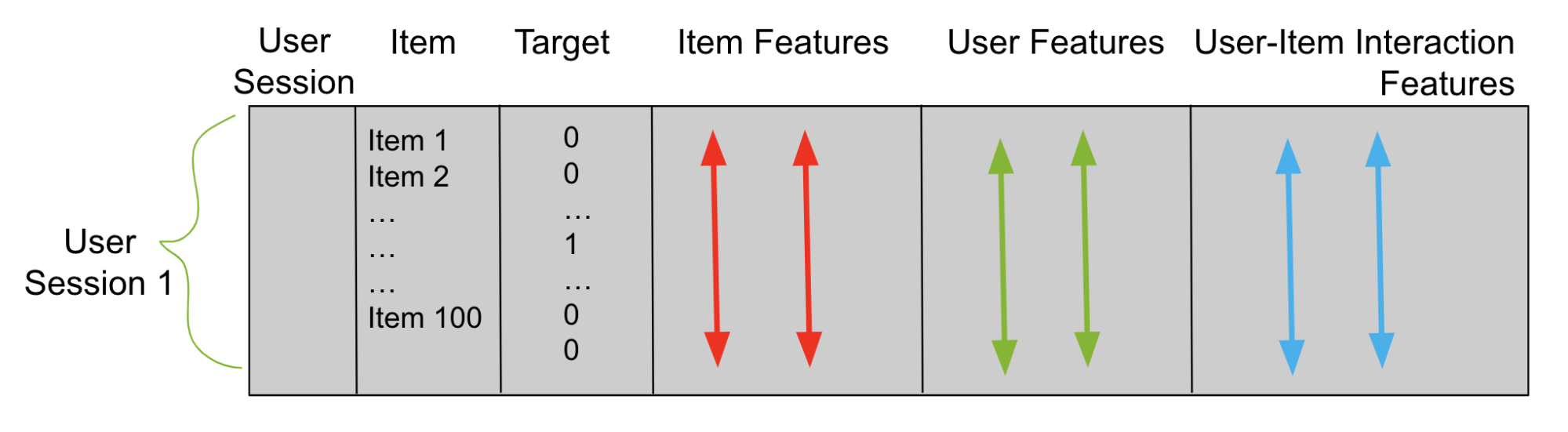
使用阶段 1 中的候选者,构建一个表格数据帧(图 2),用于训练重新排序器。想象一下,第 1 阶段为每个用户生成 100 个候选者。然后,对于每个经过训练的数据用户,您的表格数据框架有 100 行。一列是用户,另一列是候选项。为目标添加第三列。具有与该行用户正确匹配的候选项的每一行在目标列中都有一个 1,否则为 0。
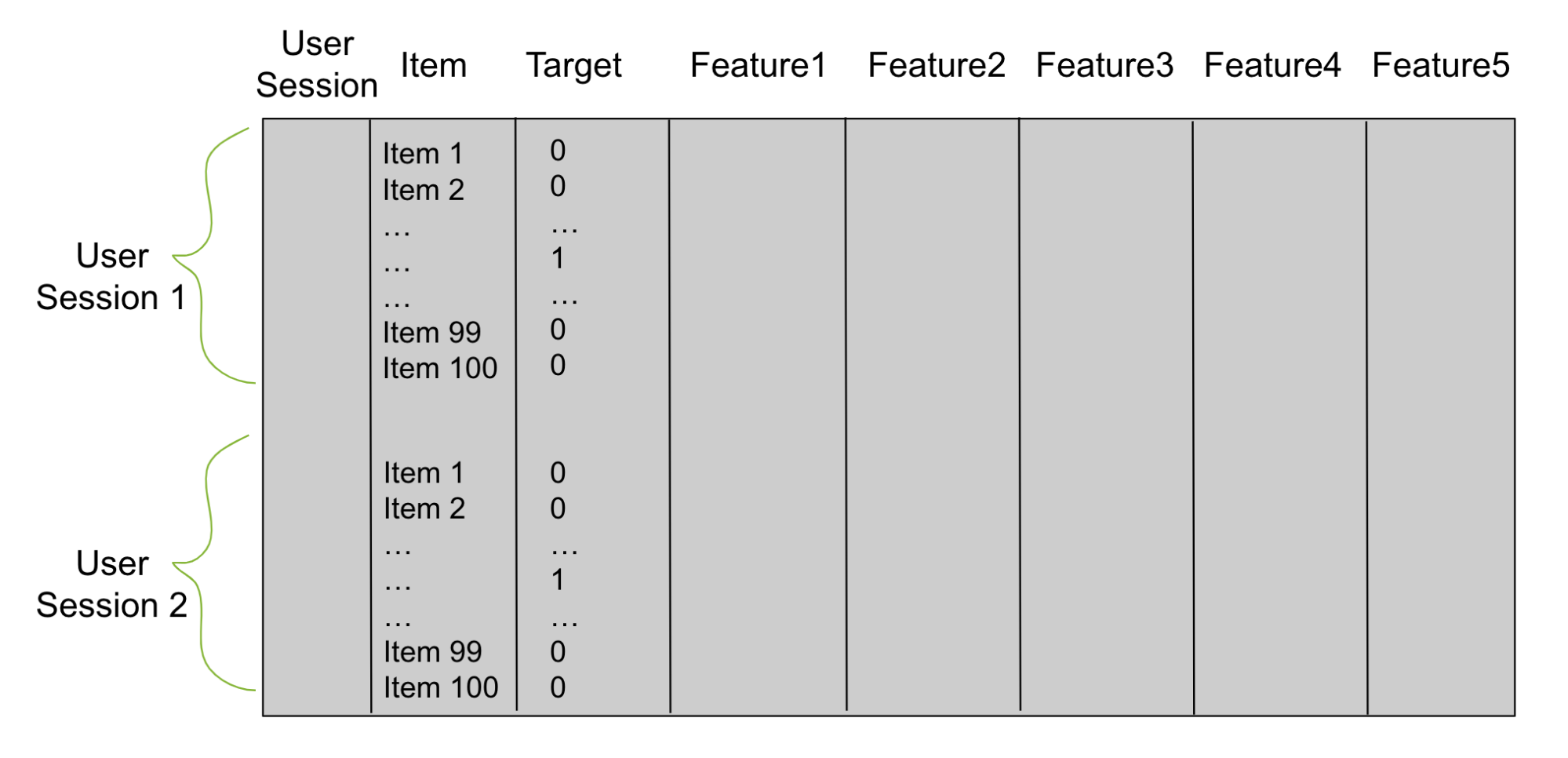
接下来,添加描述用户会话的列和称为功能列的项目。这些特征列是重新排序器用来学习模式和预测目标列的。你用二元分类目标或成对或列表排名目标来训练你的重新排名者。之后,您使用这个经过训练的模型来预测看不见的测试用户会话的项目。
代表性不足的语言的数据匮乏
两阶段候选重新排序方法(以及任何其他方法)需要大量的训练数据来正确地训练机器学习或深度学习模型。流行语言通常有很多现有的数据,但对于历史上代表性不足的语言来说,情况并非如此。
倡导服务不足的语言至关重要,原因有几个,例如促进包容性、增加全球影响力以及提高在线用户的参与度和满意度。
为了构建对代表性不足的语言的推荐系统,我建议使用迁移学习。通过利用通用语言的数据集,模型可以识别现有的模式,并将这些学习应用于支持未被广泛使用的语言。这有助于您克服小型数据集的挑战,并创建一个更具包容性的数字世界。
开发多语言推荐系统的专业技巧
为了克服数据短缺,在第一阶段和第二阶段,使用迁移学习将信息从一种语言应用到另一种语言。许多项目具有多种语言的等价项。因此,一种语言中的用户-项目交互行为可以被翻译成另一种语言。
以下是加快多语言推荐引擎开发过程的重要提示。
候选人生成提示
- 首先,通过使用流行语言和代表性不足语言中存在的用户历史记录,为代表性不足的语言创建共同访问矩阵。
- 一定要使用预先训练好的多语言表达项目 大语言模型(LLM)进行嵌入。然后,使用余弦相似度来查找代表性不足语言中的候选项。
- 使用预先训练的多语言 LLM 嵌入初始化 NN 嵌入。然后,对用户和项目嵌入之间的余弦相似性进行微调,以在代表性不足的语言中找到候选项目。
排名提示
- 在重新排序的表格数据框架中,可以使用流行语言的项目功能作为代表性不足语言的项目特征。
- 通过将从流行语言学习的用户项目模式转移到代表性不足的语言来创建用户项目交互功能。
- 最后,使用流行语言中的用户项数据帧行来训练代表性不足的语言的重新排序器。
教程:多语言推荐系统
为了帮助您测试这些方法,我将为您介绍构建多语言推荐系统的优化过程。
候选生成实现
候选生成的目标是为每个用户生成数百个项目建议。两种流行的技术是使用共访问矩阵和使用表示学习。将迁移学习与共访问矩阵一起使用是很简单的。
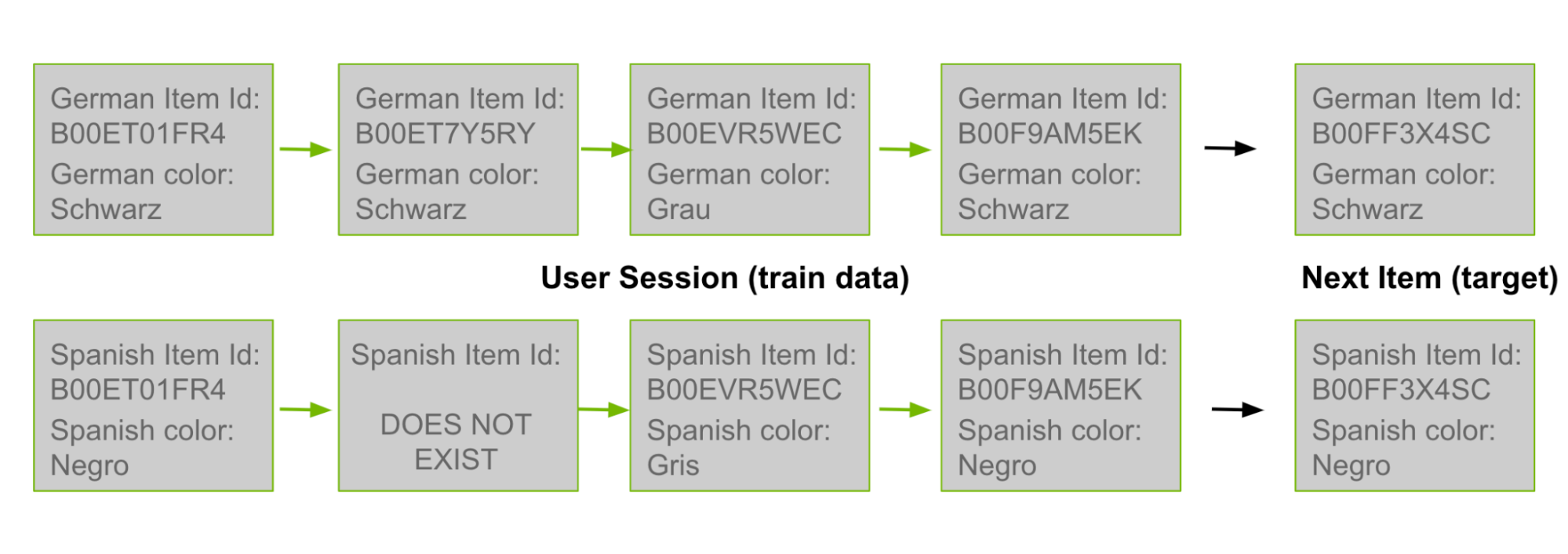
在这篇文章的前面,我讨论了共同访问候选生成是如何基于对用户历史中共存的产品 ID 对进行计数的。由于许多产品 ID 存在于多种语言中,您可以使用德语用户历史记录中的对作为西班牙语共同访问矩阵中的计数。在图 3 中,最上面的德语行来自训练数据。然后将其“翻译”为西班牙语,如下面一行所示。
程序如下。
- 给定一对西班牙语产品 ID,您可以迭代其他五种语言的用户:英语、德语、日语、意大利语和法语。
- 每当您在其中一个用户的历史记录中观察到西班牙产品 ID 对时,请将此西班牙商品对的计数加 1。或者你可以使用不同的权重,比如在计数上加 0.5。
- 累积所有西班牙语项目对的计数后,继续像以前一样生成候选项,方法是将新的共同访问矩阵应用于每个西班牙语用户的历史记录,为西班牙语用户生成候选项。
使用 RAPIDS cuDF 创建共访问矩阵是最快、最有效的方法。要了解更多,请参阅带有示例代码的 Jupyter 笔记本使用手工规则的候选者重新排名模型。
通过将包含所有用户历史记录的数据帧(即,具有列 user 和历史记录项的数据帧)合并到关键用户上的自身,可以创建所有历史对。然后按项目对分组并聚合计数。
import cudf
df = cudf.DataFrame(ALL_USER_HISTORIES)
df = df.merge(df, on='user')
df['wgt'] = 1
df = df.groupby(['item_x','item_y']).wgt.sum()
表示学习、LLM 和深度学习嵌入是当前的热门话题。除了共同访问矩阵之外,为每个用户生成候选项的另一种选择是创建有意义的距离嵌入。如果你为每个项目都有有有意义的距离嵌入,那么你可以使用一个模型来预测每个用户的嵌入。接下来,找到与该预测嵌入最接近的 100 个嵌入(通过余弦相似性),并将其用作候选嵌入(图 4)。
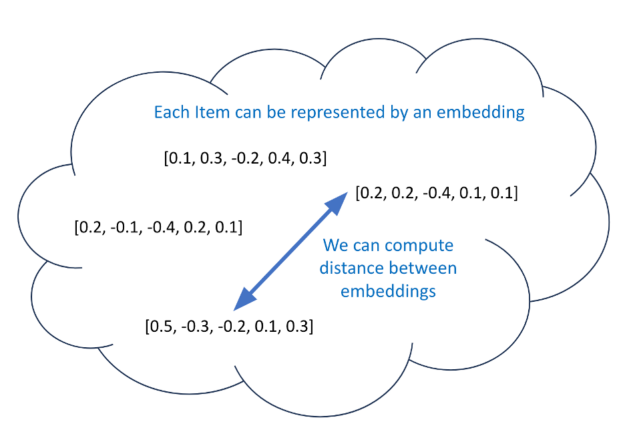
为项目训练有意义的距离嵌入的过程称为表示学习。嵌入N中的维度向量N维度空间。在训练过程中,相似项目的嵌入被修改为更靠近(通过一些距离度量),而不同项目的嵌入则被修改为至少具有预定义的间隙距离(边缘)他们之间。
在表示学习过程中使用迁移学习的一种方法是用多语言句子嵌入来预初始化嵌入。每个项目都有一个标题,无论是英文、德文、日文、西班牙文、意大利文还是法文。例如,您可以从 Hugging Face 的 stsb-xlm-r 多语言模型中预初始化每个项目,并嵌入其标题。这个模型已经在许多不同的语言上进行了训练,并从所有语言中转移了学习。之后,您可以使用图 5 所示的模型使用训练数据对嵌入进行微调。
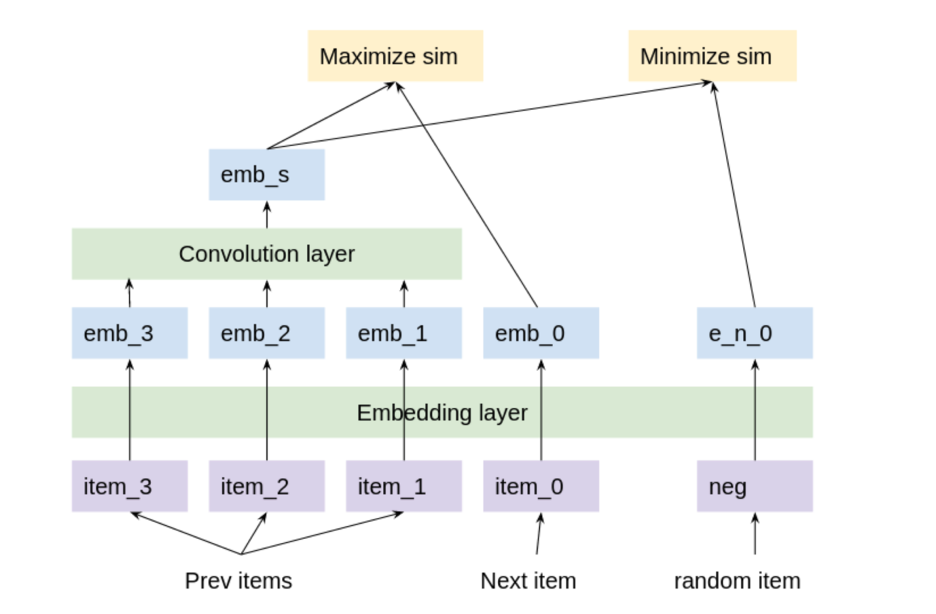
使用所有列车数据用户历史对模型进行微调。每三个连续的历史项目与一个正项目目标配对,该正项目目标是下一个连续项目。每个三元组与 4096 个负面项目目标配对,这些目标是随机选择的项目。反向传播最大化了预测嵌入和正目标之间的余弦相似性。并且它最小化了预测嵌入和负目标之间的余弦相似性。之后,您可以为每个项目进行有意义的距离嵌入,并为每个用户进行预测嵌入。
使用 NVIDIA Merlin 框架是创建基于 transformer 的会话感知推荐系统的一种快速简便的方法,该系统可以使用预训练嵌入。想要了解更多信息,请参阅 时尚电商的基于会话的下一项预测 和 使用预训练嵌入进行训练 的 Jupyter 笔记本。
您也可以使用 NVIDIA Merlin Dataloader。
排名实施
阶段 2 的目标是训练重新排序器,该重新排序器预测每个用户的所有可能候选项目中每个候选项目正确的可能性。为了成功地训练模型,除了用户、项目和目标列之外,还需要特征列。要素列有三种类型:
- 项目功能
- 用户功能
- 用户项目交互功能
项目特征描述项目。例如,您可以添加商品价格功能。然后,在项目价格列中,具有项目 A 的重新排序数据帧中的每一行都有相应的价格 A(图 6)。
在项目特征上使用迁移学习很容易。要将学习从德语转移到西班牙语,可以从德语用户历史数据创建项目功能,然后将其合并到西班牙语项目。
例如,对于每个商品的产品 ID,计算它在所有德国用户历史记录中出现的频率。然后,在你的带有西班牙语项目 A 的重新排序数据帧中的每一行,在德语项目流行度列中都有相应的德语流行度 A。这之所以有效,是因为许多商品的产品 ID 同时存在于德语和西班牙语中。如果某个西班牙语产品 ID 在德语中不存在,则在德语商品流行度栏中插入 Nan 。
用户特征列和项目特征列通常使用数据框架创建groupby命令。为每个用户或项创建一个属性,然后将其合并到数据帧中。最快捷、最有效的方法是使用 RAPIDS cuDF 。
import cudf
item_features = data.groupby(‘item’)\
.agg({‘item:count’,’user:nunique’,’price:first’})
df = df.merge(item_features, left_on=’item’,
right_index=True, how=’left’)
user_features = data.groupby(‘user’)\
.agg({‘user:count’,’item:nunique’})
df = df.merge(user_features, left_on=’user’,
right_index=True, how=’left’)
用户-项目交互特性描述了行的候选项目和该行的用户之间的关系。这些特征对于每一行都有不同的值。生成用户-项目交互特征的一种常见方法是描述用户的最后一个历史项目与其候选项目之间的关系。
使用从流行语言到代表性不足语言的迁移学习的一种方法是使用多语言信息为所有项目创建有意义的距离嵌入。然后,用户-项目交互特征可以是用户的最后历史项目和基于嵌入的候选项目之间的余弦相似性得分。
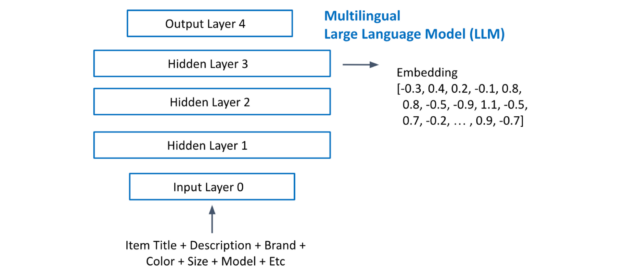
图 7 显示了从多语言 LLM 中提取项目嵌入。您将每个项目的所有文本连接起来,并将其输入到 LLM 中。提取最后一个隐藏层激活作为嵌入。
使用流行语言中的信息来改进代表性不足的语言推荐的第三种方法是使用流行语言的数据帧行来训练你的代表性不足 GBT 重新库。首先,对所有语言的数据帧使用相同的列功能,然后将所有数据帧合并为一个新的数据帧。之后,您的数据帧很大。
使用 RAPIDS Dask cuDF XGB 在多个 GPU 上训练具有数百万行的 GBT 是最佳方法!想要了解更多详细信息,请参阅KDD cup 解决方案代码。
代码的关键行如下:
import xgboost as xgb
import dask, dask_cudf
from dask.distributed import Client
client = Client(cluster)
df = dask_cudf.read_parquet(FILES).persist()
dtrain = xgb.dask.DaskQuantileDMatrix(
client, df[FEATURES], df[TARGET])
xgb.dask.train(client, xgb_parms, dtrain)
结论
在网上浏览时,推荐系统可能看起来很神奇,但正如你在这篇文章中所了解到的,多语言推荐引擎的内部工作是确定的,可以理解。
在这篇文章中,我将分享 NVIDIA 和 NVIDIA Merlin 团队的 Kaggle 大师们在最近的KDD cup 2023 多语言推荐系统竞赛中的表现,该竞赛由 Amazon 主持。
我还介绍了推荐系统的两阶段候选重新排序技术。这是一种强大的技术,有助于解决许多推荐系统的需求。接下来,我为您提供了一些专业提示,帮助您为代表性不足的语言培训推荐系统。我分享了 RAPIDS 和 NVIDIA Merlin 框架如何帮助您构建推荐系统。
我希望你能在下一个推荐系统项目中使用其中的一些想法。通过改进针对代表性不足语言的在线推荐系统,我们都可以让互联网更具包容性,扩大全球影响力,提高用户参与度和满意度。