
为了实现光线跟踪的高效率,您必须构建一个在每个阶段都能很好地缩放的管道。这从网格实例选择及其数据处理开始,以优化跟踪和着色您遇到的每个命中。
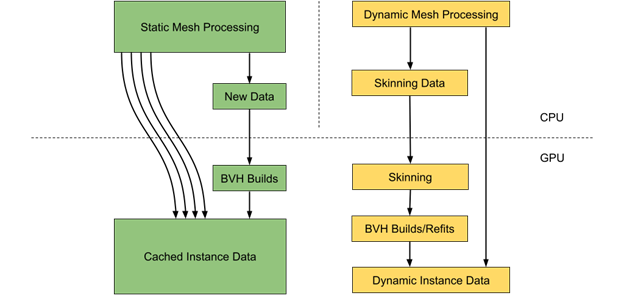
实例数据生成
在普通场景中,静态对象可能比动态对象多得多。然而,每个动态对象的处理可能需要更多的时间,因为它需要更新顶点数据和相应的 BVH 结构。
在 CPU 上并行执行静态和动态对象数据处理可能是一个好主意。这通常涉及实例数据提取以及所需的加速结构的构建和更新。
静态网格数据可以高效地缓存在 GPU 上,包括每个实例的转换矩阵,以避免额外的数据处理和内存传输。仅每个实例就需要 64 字节的内存。使用直接映射的视频存储器( BAR1 )也是执行数据上传到 GPU 的良好策略。
动态对象选择
某些光线跟踪效果(如反射或阴影)需要支持非平截头体对象以提高渲染精度。在许多情况下,这需要将相机周围的所有对象都包含在一定半径内。
即使对于那些位于视锥体中的对象,对每个帧执行所需的更新也可能不可行。这迫使您为动态对象制定某种形式的优先级,以选择每帧要处理的对象的子集。
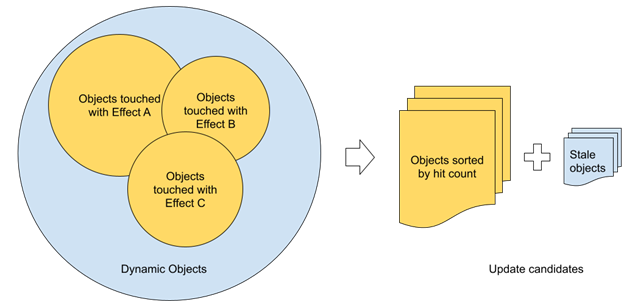
例如,对于需要更新的每个对象,可以尝试根据边界球体定义的立体角和到摄影机的距离来定义优先级。为了确保所有对象都经过一段时间的处理,还应考虑自上次更新以来的帧数。
虽然立体角听起来对优先级定义来说是合理的,但它可能不会导致为更新选择一组最佳对象。在大多数情况下,这是因为没有考虑可见性项。对于光线跟踪,可以直接根据照射每个对象的光线数来估计可见性。对象更新优先级可以直接从中导出。
与动态网格的循环更新相比,这种方法可以在复杂场景中更好地工作,因为它将更新预算本地分配给网格。这是光线跟踪的最大区别。
使用多个光线跟踪效果时,可以计算每个效果的所有光线,并为每个对象使用一个值。从技术上讲,如果需要,可以使用着色器原子增量来计算每帧上的所有光线。实际上,如果此时性能非常关键,在屏幕空间中使用稀疏采样可以减少潜在冲突的数量。
每个对象都会分配一个唯一的标识符,该标识符可用作缓冲区中的偏移量,以存储每帧每个对象的光线计数。此缓冲区使用一组相应的 CPU 可见缓冲区进行数据读回。回读调用可以在最后一个光线跟踪效果完成后立即发出,并且数据应该可以在下一帧中使用。
此管道至少引入了一帧延迟,由于连续帧之间的高数据相关性,这不是问题。对于需要最高优先级立即更新的新可见对象,应采取特殊处理。
一些复杂对象可能由多个网格组成,这些网格可能会以不同的频率进行更新。在某些情况下,由于遮挡而不可见的特写部分可能会在没有应用所需更新的情况下突然导致视觉伪影。为了减轻这种情况,可以将光线对象相交驱动的可见性与其他度量相结合,以确保其余网格的延迟更新。
批量顶点数据处理
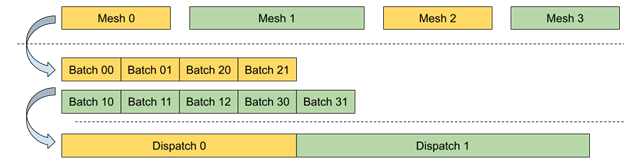
动态网格顶点数据处理需要高度并行性,单个调用之间的状态变化数量最少,以在 CPU 和 GPU 侧获得更好的性能。这可以使用无绑定资源模型部分实现,其中所有所需资源都可以直接从 GPU 上的着色器代码获得,而无需显式的 CPU 端绑定。
对 GPU 占用率低的潜在任务的另一个优化是将整个工作负载分解为可以并行高效处理的统一批次。每个批次都包含处理一系列顶点和应用变换所需的所有属性。这样,可以使用单个Dispatch调用处理共享同一着色器的多个动态网格。
着色器表数据和更新
着色器表包含一组着色器记录,这些记录由着色器标识符和一组可选属性组成。这些属性与通过本地根签名访问的资源绑定和着色的每个几何部分相关联。
仅着色器标识符就需要 32 字节的存储空间。在许多情况下,唯一记录的数量远远少于 TLAS 中的几何结构,并且数据可以直接在 GPU 上高效地并行填充。
CPU 仅跟踪几何图形和相应材料标识符的列表。顶点缓冲区访问和材质属性的所有数据都可以永久存储在视频存储器中,每帧上新创建或更新的网格都会进行增量更新。
考虑压缩所有记录以节省内存,并根据几何体的最大数量而不是实例计数乘以每个实例的最大几何体来分配着色器表存储。
如果材质数据不包含在记录中,并且可以通过实例描述符中的 InstanceID 访问,则记录总数可以等于仅表示几何体部分的唯一底层加速结构的数量。
对于具有几何体和材质数据的特定排列的一般情况,请考虑在着色器记录中直接打包额外的每网格属性,以避免在执行与命中组关联的着色器时出现额外的内存间接寻址。

每个网格(实例)具有固定几何体的方法可以简化内存分配和数据重用,但所需的内存总量高度取决于每个网格的最大几何体数量。
优化 TLAS 旋转
如果 TLAS 实例的局部边界框是轴对齐的,则其跟踪效率会更高。您无法控制单个实例转换,但可以为所有实例提供全局转换,以缩短跟踪时间。
在运行时,您可以分析特写实例转换,并根据它们的相对旋转将它们分类到多个容器中。为了进一步简化,只考虑绕垂直轴的旋转。分类后,可以使用最小化所有实例的相对旋转角度的容器。
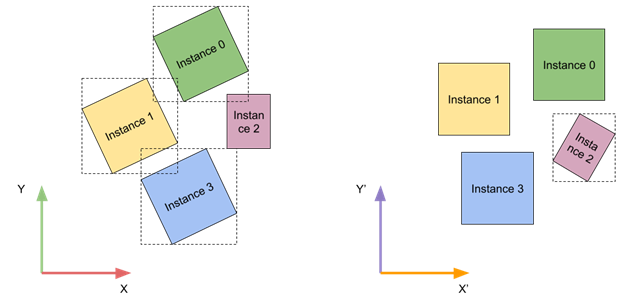
这种方法可能不适用于每种类型的内容。一个很好的例子是城市环境中有统一的城市街区方向。现实世界中的一个例子是纽约市的曼哈顿区,它的街道网格与日落方向对齐。
顶点数据访问
在光栅化和光线跟踪管道之间共享顶点数据通常是一个好主意。在某些情况下,可以尝试仅为光线跟踪使用优化的布局。可以在光线命中时直接计算位置,纹理坐标可能是任何命中着色器执行过程中唯一需要的属性。
其他属性可以以较低的精度存储,甚至可以按基元定义,这不需要通过索引缓冲区进行额外的间接寻址。
Alpha 测试几何体
具有头发和毛发等 alpha 测试的高多边形几何体对于直接跟踪来说可能具有挑战性。在许多情况下,它可能工作得很好,但有时应该采取额外的措施,以确保性能开销得到控制。
降低跟踪成本的一种方法是从预跟踪开始,即跟踪屏幕空间中每个像素的局部邻域,类似于屏幕空间阴影或环境遮挡技术。您不必对屏幕上的每个像素执行此步骤,以确保没有额外的开销。为此,可以使用 G 缓冲区曲面中存储的其他数据来标记属于头发或毛发的像素。
粗糙表面上的漫反射全局照明或反射可能不需要精确的反照率或阿尔法测试结果。可以存储每个基本体的平均材质值。这样,可以通过在 any-hit 着色器执行期间随机评估不透明度来获得良好的结果,而无需额外的逐顶点属性提取和插值或纹理采样。
如果仍然需要精确的 alpha 测试,那么最好创建一个简化的、通用的任意命中着色器,并在可能的情况下使用它。在许多情况下,使用一组纹理坐标和纹理索引进行采样就足够了。
屏幕空间数据采样
有时在拍摄光线时,您可能会在屏幕上看到一个原始的相交点。这使您有机会在重新投影后使用前一帧的照明数据,并提高输出的性能和质量。它可以很好地用于漫反射照明传播,因为光线方向对照明没有影响。
在着色器中执行任何其他代码之前,可以检查屏幕空间数据采样。可以跳过任何进一步的照明代码,以提高性能。
或者,您可以仅从 G 缓冲区中采样材质数据,然后仍然运行着色管道。对于较薄的物体,应采取一定的精度,这可能需要在重新投影后对其正常情况进行额外检查。确保从右侧对曲面进行采样。此外,与主视图相比,当光线跟踪效果使用简化的材质或着色时,该方法值得尝试改善照明质量。
总结
使用这些提供的指南作为构建高性能光线跟踪渲染管道的基础,重点关注 GPU 和 CPU 性能。与 API 相关的常见最佳实践仍然有效,也应予以考虑。其他步骤可以包括添加顶级功能,例如对 micro-meshes 和 Shader Execution Reo r dering 的支持。




