
今天,在 2022 NVIDIA GTC 主题演讲中, NVIDIA 首席执行官 Jensen Huang 介绍了新的 NVIDIA H100 张量核心 GPU 基于新的 NVIDIA 漏斗 GPU 架构。这篇文章让你看看新的 H100 GPU ,并介绍了NVIDIA Hopper 架构 GPU 的重要新功能。
NVIDIA H100 张量核心 GPU 介绍
NVIDIA H100 张量核心 GPU 是我们设计的第九代数据中心 GPU ,用于在前一代 NVIDIA A100 张量核心 GPU 上为大规模 AI 和 HPC 提供数量级性能跳跃。 H100 延续了 A100 的主要设计重点,提高了人工智能和 HPC 工作负载的可扩展性,大大提高了架构效率。

对于当今的主流 AI 和 HPC 机型,配备 InfiniBand interconnect 的 H100 的性能是 A100 的 30 倍。新的 NVLink 交换系统互连针对一些最大且最具挑战性的计算工作负载,这些工作负载需要跨多个 GPU 加速节点的模型并行性来适应。这些工作负载带来了新一代的性能飞跃,在某些情况下, InfiniBand 的性能比 H100 再次提高了三倍。
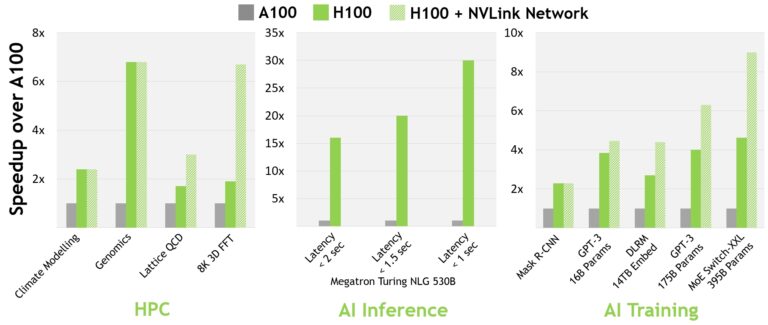
所有性能数据都是初步的,基于当前的预期,并可能会随着运输产品的变化而变化。 A100 集群: HDR IB 网络。 H100 集群: NDR IB 网络,带有 NVLink 交换系统(如图所示) GPU :气候建模 1K , LQCD 1K ,基因组学 8 , 3D-FFT 256 , MT-NLG 32 (批次大小: A100 为 4 , 1 秒 H100 为 60 , A100 为 8 , 1.5 和 2 秒 H100 为 64 ), MRCNN 8 (批次 32 ), GPT-3 16B 512 (批次 256 ), DLRM 128 (批次 64K ), GPT-3 16K (批次 512 ), MoE 8K (批次 512 ,每个 GPU 一名专家).
2022 年春天 GTC 宣布了新的NVIDIA Grace Hopper 超级芯片产品。NVIDIA Hopper H100 张量核心 GPU 将为 NVIDIA Grace Guffer-SuxCube CPU + GPU 架构,为兆字节规模加速计算而建,并在大型 AI 和 HPC 上提供 10X 更高性能。
NVIDIA Grace Hopper 超级芯片利用ARM体系结构的灵活性来创建一个 CPU 和服务器架构,从加速计算开始。H100与 Nvidia Grace CPU 配对,与超高速 NVIDIA 芯片到芯片互连,提供900 Gb/s的总带宽,比PCIE GE5快7X。与当今最快的服务器相比,这种创新设计提供了高达30倍的聚合带宽,对于使用TB数据的应用程序,其性能高达10倍。
NVIDIA H100 GPU 主要功能概述
- 新的 streaming multiprocessor ( SM )有许多性能和效率改进。主要的新功能包括:
- 新的 第四代张量核 芯片到芯片的速度比 A100 快 6 倍,包括每 SM 加速比、额外的 SM 计数和更高的 H100 时钟。与上一代 16 位浮点选项相比,基于每个 SM , Tensor Core 在等效数据类型上的 MMA (矩阵乘法累加)计算速率是 A100 SM 的 2 倍,在使用新 FP8 数据类型时是 A100 的 4 倍。稀疏特性利用深度学习网络中的细粒度结构化稀疏性,将标准张量核心运算的性能提高了一倍
- 新的 DPX Instructions 在 A100 GPU 上将动态编程算法的速度提高了 7 倍。两个例子包括用于基因组处理的史密斯 – 沃特曼算法,以及用于在动态仓库环境中为一组机器人寻找最佳路径的弗洛伊德 – 沃沙尔算法。
- 3 倍于 IEEE FP64 和 FP32 与 A100 相比,芯片间的处理速度更快,因为每个 SM 的时钟性能比 A100 快 2 倍,加上额外的 SM 计数和更高的 H100 时钟。
- 新线程块集群 功能 支持以比单个 SM 上的单个线程块更大的粒度对局部性进行编程控制。这扩展了 CUDA 编程模型,向编程层次结构添加了另一个级别,现在包括线程、线程块、线程块集群和网格。集群允许多个线程块在多个 SMs 上并发运行,以同步、协作方式获取和交换数据。
- 分布式共享内存 允许在多个 SM 共享内存块之间进行负载、存储和原子的直接 SM-to-SM 通信。
- 新的 asynchronous execution 功能包括一个新的 张量记忆加速器( TMA ) 单元,它可以在全局内存和共享内存之间高效地传输大块数据。 TMA 还支持集群中线程块之间的异步复制。还有一个新的 异步事务屏障 用于进行原子数据移动和同步。
- 新transformer 发动机结合使用软件和定制的 NVIDIA Hopper Tensor 核心技术,专门设计用于加速 transformer 模型训练和推理。 transformer 引擎智能管理并动态选择 FP8 和 16 位计算,自动处理每层 FP8 和 16 位之间的重新转换和缩放,与上一代 A100 相比,在大型语言模型上提供高达 9 倍的人工智能训练和高达 30 倍的人工智能推理加速。
- HBM3 存储子系统 的带宽比上一代增加了近 2 倍。 H100 SXM5 GPU 是世界上第一款 GPU HBM3 内存,提供了一流的 3 TB / s 内存带宽。
- 50MB 二级缓存体系结构 缓存了大量模型和数据集以供重复访问,从而减少了对 HBM3 的访问。
- 第二代多实例 GPU ( MIG )技术与 A100 相比,每个 GPU 实例的计算容量增加约 3 倍,内存带宽增加近 2 倍。 MIG level TEE 现在首次提供机密计算能力。最多支持七个单独的 GPU 实例,每个实例都有专用的 NVDEC 和 NVJPG 单元。现在,每个实例都包含自己的一组性能监视器,可与 NVIDIA 开发人员工具配合使用。
- 新的机密计算支持 保护用户数据,抵御硬件和软件攻击,并在虚拟化和 MIG 环境中更好地隔离和保护虚拟机( VM )。 H100 实现了世界上第一个本机机密计算 GPU ,并以全 PCIe 线速率使用 CPU 扩展了可信执行环境( TEE )。
- 第四代 NVIDIA NVLink 在所有 reduce 操作中提供了 3 倍的带宽增加,与上一代 NVLink 相比,一般带宽增加了 50% ,多 GPU IO 的总带宽为 900 GB / s ,是 PCIe Gen 5 带宽的 7 倍。
- Third-generation NVSwitch 技术包括驻留在节点内部和外部的交换机,用于连接服务器、群集和数据中心环境中的多个 GPU 。节点内的每个 NVSwitch 提供 64 个第四代 NVLink 链路端口,以加速多 GPU 连接。交换机总吞吐量从上一代的 7.2 TB / s 增加到 13.6 TB / s 。新的第三代 NVSwitch 技术还为集体运营提供了硬件加速,多播和 NVIDIA 的网络规模大幅缩减。
- 新的 NVLink 交换系统 互连技术和基于第三代 NVSwitch 技术的新的第二级 NVLink 开关 引入了地址空间隔离和保护,使多达 32 个节点或 256 个 GPU 能够在 2:1 锥形胖树拓扑中通过 NVLink 连接。这些连接的节点能够提供 57.6 TB / s 的全对全带宽,并能提供令人难以置信的 FP8 稀疏 AI 计算的 1 exaFLOP 。
- PCIe 第 5 代 提供 128 GB / s 的总带宽(每个方向 64 GB / s ),而第 4 代 PCIe 的总带宽为 64 GB / s (每个方向 32 GB / s )。 PCIe Gen 5 使 H100 能够与性能最高的 x86 CPU 和 SmartNIC 或数据处理器( DPU )连接。
还包括许多其他新功能,以改进强大的可扩展性,减少延迟和开销,并通常简化 GPU 编程。
NVIDIA H100 GPU 深入架构
基于新NVIDIA Hopper GPU 架构的 Nvidia H100 GPU 具有多个创新:
- 新的第四代张量核在更广泛的人工智能和高性能计算任务中执行比以往更快的矩阵计算。
- 新的 transformer 引擎使 H100 的人工智能训练速度提高了 9 倍,人工智能训练速度提高了 30 倍。与前一代 A100 相比,大型语言模型的推理速度有所提高。
- 新的 NVLink 网络互连使 GPU 能够跨多个计算节点在多达 256 个 GPU 之间进行 GPU 通信。
- 安全 MIG 将 GPU 划分为独立的、大小合适的实例,以最大限度地提高较小工作负载的服务质量( QoS )。
许多其他新的体系结构功能使许多应用程序的性能提高了 3 倍。
NVIDIA H100 是第一款真正的异步 GPU 。 H100 将 A100 的全局异步传输扩展到所有地址空间的共享异步传输,并增加了对张量内存访问模式的支持。它使应用程序能够构建端到端的异步管道,将数据移入和移出芯片,完全重叠并隐藏数据移动和计算。
现在,使用新的张量内存加速器管理 H100 的全部内存带宽只需要少量 CUDA 线程,而大多数其他 CUDA 线程可以专注于通用计算,例如新一代张量核的预处理和后处理数据。
H100 将 CUDA 线程组层次结构扩展为一个称为线程块集群的新级别。集群是一组线程块,保证可以并发调度,并支持跨多个 SMs 的线程的高效协作和数据共享。集群还可以更高效地协同驱动异步单元,如张量内存加速器和张量内核。
协调越来越多的片上加速器和不同的通用线程组需要同步。例如,使用输出的线程和加速器必须等待产生输出的线程和加速器。
NVIDIA asynchronous transaction barriers 使集群内的通用 CUDA 线程和片上加速器能够高效地同步,即使它们位于不同的 SMs 上。所有这些新功能使每个用户和应用程序都能随时充分使用其 H100 GPU 的所有单元,使 H100 成为迄今为止功能最强大、可编程性最强、能效最高的 NVIDIA GPU 。
为 H100 GPU 供电的完整 GH100 GPU 是使用为 NVIDIA 定制的 TSMC 4N 工艺制造的,具有 800 亿个晶体管,芯片尺寸为 814 毫米2,以及更高频率的设计。
NVIDIA GH100 GPU 由多个 GPU 处理集群( GPC )、纹理处理集群( TPC )、流式多处理器( SMS )、 L2 高速缓存和 HBM3 存储器控制器组成。
GH100 GPU 的全面实施包括以下装置:
- 8 个 GPC , 72 个 TPC ( 9 个 TPC / GPC ), 2 个 SMs / TPC ,每个完整 GPU 144 条 SMs
- 每个 SM 128 个 FP32 CUDA 内核,每个完整 GPU 18432 个 FP32 CUDA 内核
- 每个 SM 4 个第四代张量核,每个完整 GPU 576 个
- 6 个 HBM3 或 HBM2e 堆栈, 12 个 512 位内存控制器
- 60 MB 二级缓存
- 第四代 NVLink 和 PCIe 第 5 代
NVIDIA H100 GPU 与 SXM5 板形因子包括以下单元:
- 8 条 GPC , 66 条 TPC , 2 条 SMs / TPC ,每个 GPU 132 条 SMs
- 每个 SM 128 个 FP32 CUDA 核,每个 GPU 16896 个 FP32 CUDA 核
- 每个 SM 4 个第四代张量核,每个 GPU 528 个
- 80 GB HBM3 , 5 个 HBM3 堆栈, 10 个 512 位内存控制器
- 50 MB 二级缓存
- 第四代 NVLink 和 PCIe 第 5 代
具有 PCIE Gen 5 板形状因子 的NVIDIA H100 GPU 包括以下单元:
- 7 或 8 个 GPC , 57 个 TPC , 2 条 SMs / TPC ,每个 GPU 114 条 SMs
- 128 个 FP32 CUDA 颜色/ SM ,每个 GPU 14592 个 FP32 CUDA 颜色
- 每个 SM 4 个第四代张量核,每个 GPU 456 个
- 80 GB HBM2e , 5 个 HBM2e 堆栈, 10 个 512 位内存控制器
- 50 MB 二级缓存
- 第四代 NVLink 和 PCIe 第 5 代
与基于 TSMC 7nm N7 工艺的上一代 GA100 GPU 相比,使用 TSMC 4N 制造工艺使 H100 能够增加 GPU 核心频率,提高每瓦性能,并包含更多 GPC 、 TPC 和 SMs 。
图 3 显示了一个完整的 GH100 GPU 和 144 条短信。 H100 SXM5 GPU 有 132 条短信, PCIe 版本有 114 条短信。 H100 GPU 主要用于执行 AI 、 HPC 和数据分析的数据中心和边缘计算工作负载,但不用于图形处理。 SXM5 和 PCIe H100 GPU 中只有两个 TPC 支持图形(也就是说,它们可以运行顶点、几何体和像素着色器)。
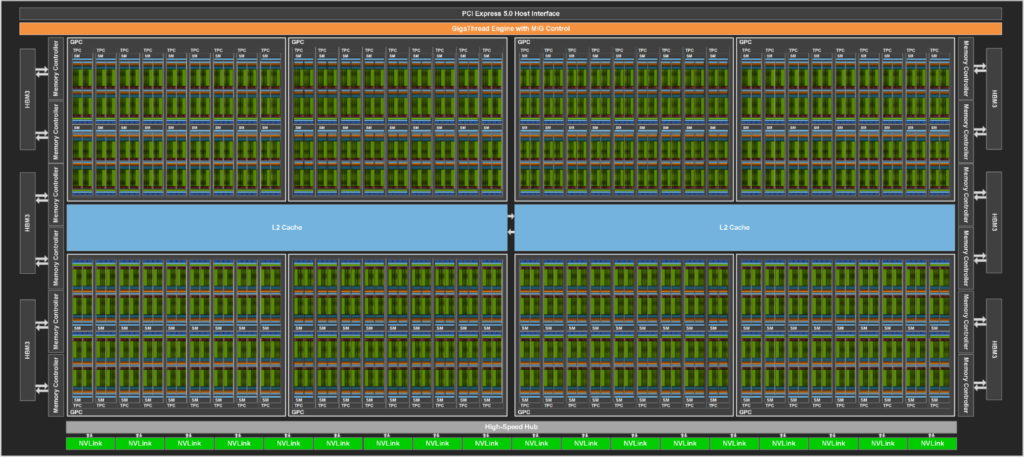
H100 SM 架构
在NVIDIA A100 张量核心 GPU SM 架构上, H100 SM 由于引入了 FP8 而使每 100 浮点运算功率 A100 峰值翻倍,并且在先前所有张量核心、 FP32 和 FP64 数据类型、时钟时钟上加倍 A100 原始 SM 计算功率。
与上一代 A100 相比,新的 transformer 引擎与 NVIDIA Hopper FP8 Tensor Core 相结合,在大型语言模型上提供了高达 9 倍的人工智能训练和 30 倍的人工智能推理加速。新的 NVIDIA Hopper DPX 指令使史密斯 – 沃特曼算法处理基因组学和蛋白质测序的速度提高了 7 倍。
新的 NVIDIA Hopper 第四代 Tensor Core 、 Tensor Memory Accelerator ,以及许多其他新的 SM 和通用 H100 架构改进,在许多其他情况下,共同提供高性能计算机和人工智能高达 3 倍的性能。
| NVIDIA H100 SXM51 | NVIDIA H100 PCIe1 | |
| Peak FP641 | 30 TFLOPS | 24 TFLOPS |
| Peak FP64 Tensor Core1 | 60 TFLOPS | 48 TFLOPS |
| Peak FP321 | 60 TFLOPS | 48 TFLOPS |
| Peak FP161 | 120 TFLOPS | 96 TFLOPS |
| Peak BF161 | 120 TFLOPS | 96 TFLOPS |
| Peak TF32 Tensor Core1 | 500 TFLOPS | 1000 TFLOPS2 | 400 TFLOPS | 800 TFLOPS2 |
| Peak FP16 Tensor Core1 | 1000 TFLOPS | 2000 TFLOPS2 | 800 TFLOPS | 1600 TFLOPS2 |
| Peak BF16 Tensor Core1 | 1000 TFLOPS | 2000 TFLOPS2 | 800 TFLOPS | 1600 TFLOPS2 |
| Peak FP8 Tensor Core1 | 2000 TFLOPS | 4000 TFLOPS2 | 1600 TFLOPS | 3200 TFLOPS2 |
| Peak INT8 Tensor Core1 | 2000 TOPS | 4000 TOPS2 | 1600 TOPS | 3200 TOPS2 |
- H100 的初步性能评估基于当前预期,并可能会随着运输产品的变化而变化
- 使用稀疏特性的有效 TFLOPS / top
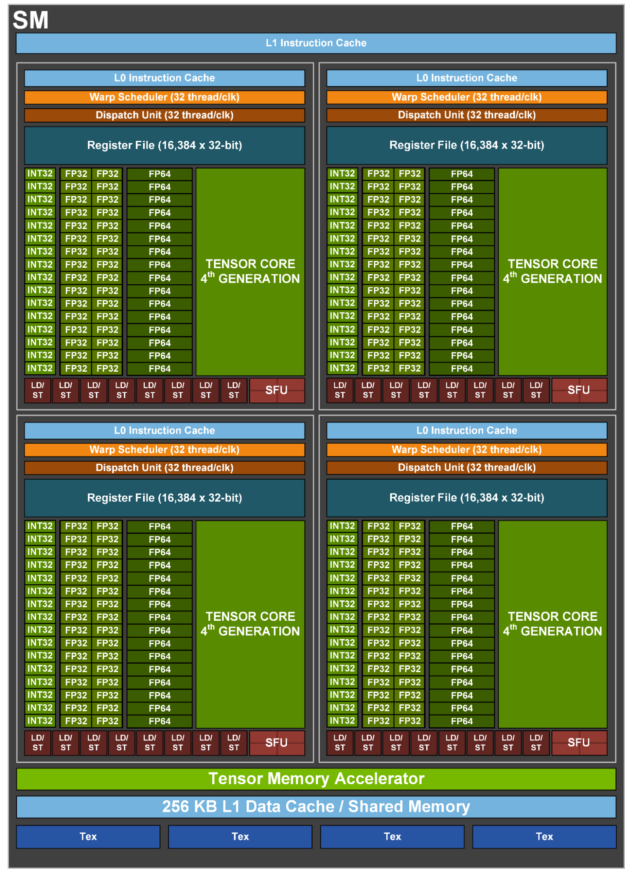
H100 SM 主要功能概述
- 第四代张量核:
- 与 A100 相比,芯片到芯片的速度提高了 6 倍,包括每 SM 的加速比、额外的 SM 计数和更高的 H100 时钟。
- 与上一代 16 位浮点选项相比,基于每个 SM , Tensor Core 在等效数据类型上的 MMA (矩阵乘法累加)计算速率是 A100 SM 的 2 倍,在使用新 FP8 数据类型时是 A100 的 4 倍。
- 稀疏特性利用深度学习网络中的细粒度结构化稀疏性,将标准张量核心运算的性能提高了一倍
- 新的 DPX instructions 在 A100 GPU 上将动态编程算法的速度提高了 7 倍。两个例子包括用于基因组处理的史密斯 – 沃特曼算法,以及用于在动态仓库环境中为一组机器人寻找最佳路径的弗洛伊德 – 沃沙尔算法。
- 3 倍于 IEEE FP64 和 FP32 与 A100 相比,芯片间的处理速度更快,因为每个 SM 的时钟性能比 A100 快 2 倍,加上额外的 SM 计数和更高的 H100 时钟。
- 256 KB 的组合共享内存和一级数据缓存,比 A100 大 1.33 倍。
- 新的 asynchronous execution 功能包括一个新的 张量记忆加速器( TMA ) 单元,它可以在全局内存和共享内存之间高效地传输大块数据。 TMA 还支持集群中线程块之间的异步复制。还有一个新的 异步事务屏障 用于进行原子数据移动和同步。
- 新的 线程块簇 功能公开了对多条短信的位置控制。
- 分布式共享内存 支持跨多个 SM 共享内存块的装载、存储和原子的 SM 到 SM 直接通信
H100 张量核结构
张量核是专门用于矩阵乘法和累加( MMA )数学运算的高性能计算核,为人工智能和 HPC 应用提供了突破性的性能。与标准浮点( FP )、整数( INT )和融合乘法累加( FMA )操作相比,在一个 NVIDIA GPU 中跨 SMs 并行运行的张量核在吞吐量和效率上都有了显著提高。
在NVIDIA V100GPU 中首次引入张量核,并在每个新的 NVIDIA GPU 体系结构生成中进一步增强。
H100 中新的第四代 Tensor Core 体系结构每 SM (时钟对时钟)提供的原始密集稀疏矩阵数学吞吐量是 A100 的两倍,考虑到 H100 比 A100 更高的 GPU 升压时钟,这一数字甚至更高。支持 FP8 、 FP16 、 BF16 、 TF32 、 FP64 和 INT8 MMA 数据类型。新的 Tensor 核还具有更高效的数据管理,可节省高达 30% 的操作数传递能力。
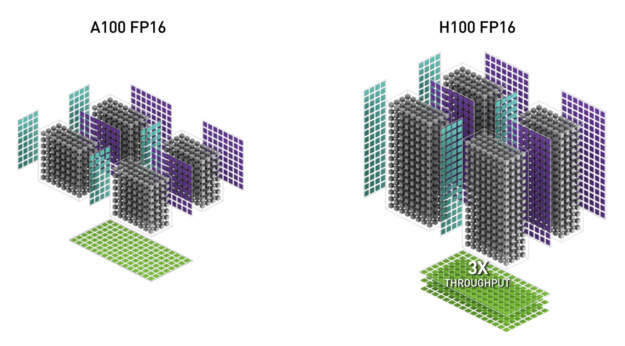
NVIDIA Hopper FP8 数据格式
H100 GPU 增加了 FP8 张量核,以加速人工智能训练和推理。如图 6 所示, FP8 张量磁芯支持 FP32 和 FP16 累加器,以及两种新的 FP8 输入类型:
- 具有 4 个指数位、 3 个尾数位和 1 个符号位的 E4M3
- E5M2 ,具有 5 个指数位、 2 个尾数位和 1 个符号位
E4M3 支持需要更少动态范围和更高精度的计算,而 E5M2 提供更宽的动态范围和更低的精度。与 FP16 或 BF16 相比, FP8 将数据存储需求减半,吞吐量翻倍。
本文后面介绍的新 transformer 引擎使用 FP8 和 FP16 精度来减少内存使用并提高性能,同时仍保持大型语言和其他模型的准确性。
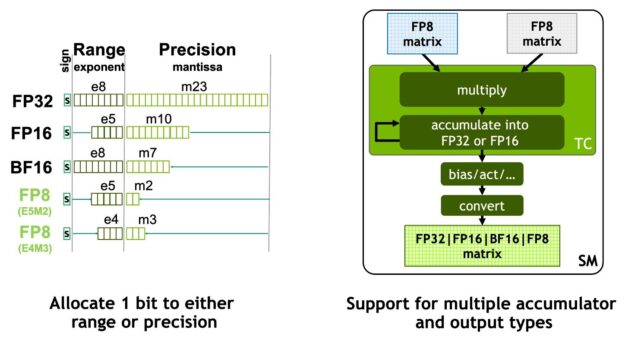
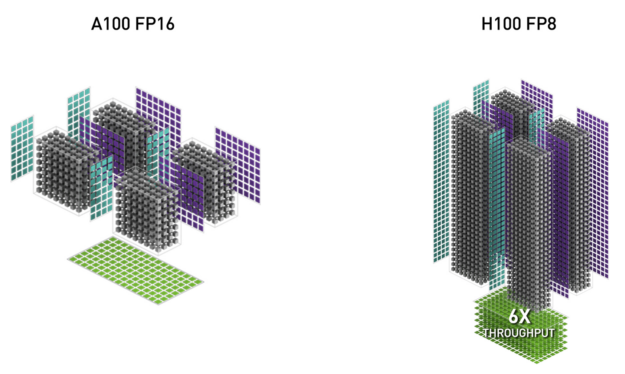
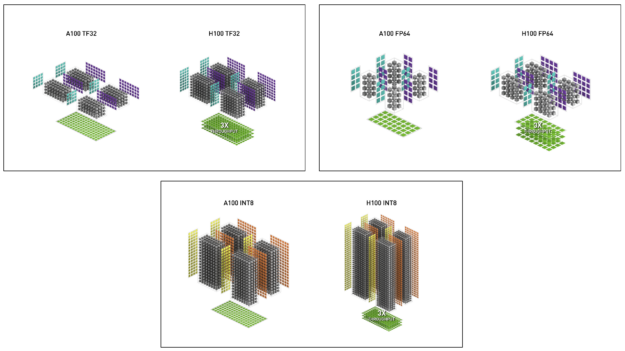
表 2 显示了多种数据类型的 H100 数学加速比超过 A100 。
| (measurements in TFLOPS) | A100 | A100 Sparse | H100 SXM51 | H100 SXM51 Sparse | H100 SXM51 Speedup vs A100 |
| FP8 Tensor Core | 2000 | 4000 | 6.4x vs A100 FP16 | ||
| FP16 | 78 | 120 | 1.5x | ||
| FP16 Tensor Core | 312 | 624 | 1000 | 2000 | 3.2x |
| BF16 Tensor Core | 312 | 624 | 1000 | 2000 | 3.2x |
| FP32 | 19.5 | 60 | 3.1x | ||
| TF32 Tensor Core | 156 | 312 | 500 | 1000 | 3.2x |
| FP64 | 9.7 | 30 | 3.1x | ||
| FP64 Tensor Core | 19.5 | 60 | 3.1x | ||
| INT8 Tensor Core | 624 TOPS | 1248 TOPS | 2000 | 4000 | 3.2x |
1 – H100 基于当前预期和运输产品变化的初步性能估计
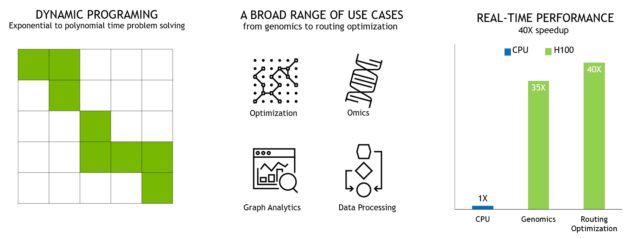
用于加速动态规划的新 DPX 指令
许多蛮力优化算法的特点是,在解决较大的问题时,子问题的解决方案会被多次重用。动态规划( DP )是一种通过将复杂的递归问题分解为更简单的子问题来解决它的算法技术。通过存储子问题的结果,无需在以后需要时重新计算, DP 算法将指数问题集的计算复杂度降低到线性范围。
DP 通常用于广泛的优化、数据处理和基因组学算法。
- 在快速发展的基因组测序领域,史密斯 – 沃特曼 DP 算法是最重要的方法之一。
- 在机器人技术领域, Floyd Warshall 是一个关键算法,用于实时通过动态仓库环境为一组机器人寻找最佳路线。
H100 引入 DPX 指令,使 DP 算法的性能比 NVIDIA Ampere GPU 提高了 7 倍。这些新指令为许多 DP 算法的内环提供高级融合操作数支持。这将大大加快疾病诊断、物流路线优化甚至图形分析的解决速度。
H100 计算性能摘要
总体而言,考虑到 H100 的所有新计算技术进步, H100 的计算性能比 A100 提高了约 6 倍。图 10 以级联方式总结了 H100 的改进:
- 132 条短信比 A100 108 条短信增加 22%
- 由于新的第四代 Tensor 内核, H100 短信的速度提高了两倍。
- 在每个 Tensor 内核中,新的 FP8 格式和相关的 transformer 引擎提供了另一个 2 倍的改进。
- H100 中时钟频率的增加带来了大约 1.3 倍的性能提升。
总的来说,这些改进使 H100 的峰值计算吞吐量约为 A100 的 6 倍,这对于世界上最需要计算的工作负载来说是一个重大飞跃。
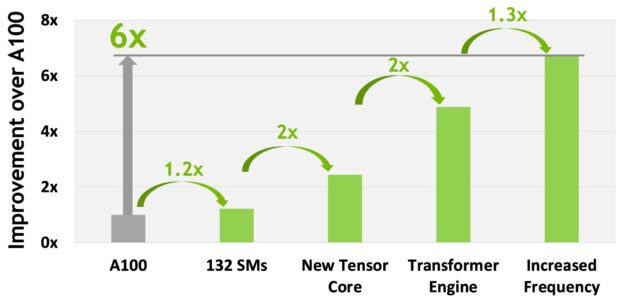
H100 的吞吐量是全球的 6 倍大多数需要计算的工作负载。
H100 GPU 层次结构和异步改进
在并行程序中实现高性能的两个关键是数据局部性和异步执行。通过将程序数据移动到尽可能靠近执行单元的位置,程序员可以利用对本地数据进行低延迟和高带宽访问所带来的性能。 异步执行涉及寻找与内存传输和其他处理重叠的独立任务。目标是让 GPU 中的所有单元都得到充分利用。
在下一节中,我们将探讨添加到 NVIDIA Hopper 中 GPU 编程层次结构中的一个重要新层,它以比单个 SM 上的单个线程块更大的规模公开局部性。我们还介绍了新的异步执行功能,这些功能可以提高性能并减少同步开销。
线程块簇
CUDA 编程模型长期以来依赖于 GPU 计算体系结构,该体系结构使用包含多个线程块的网格来利用程序中的局部性。线程块包含在单个 SM 上并发运行的多个线程,这些线程可以与快速屏障同步,并使用 SM 的共享内存交换数据。然而,随着 GPU 超过 100 个 SMs ,计算程序变得更加复杂,作为编程模型中表示的唯一局部单元的线程块不足以最大限度地提高执行效率。
H100 引入了一种新的线程块集群体系结构,它以比单个 SM 上的单个线程块更大的粒度公开了对局部性的控制。线程块集群扩展了 CUDA 编程模型,并在 GPU 的物理编程层次结构中添加了另一个级别,以包括线程、线程块、线程块集群和网格。
集群是一组线程块,保证并发调度到一组 SMs 上,其目标是实现多个 SMs 之间线程的高效协作。 H100 中的集群在 GPC 内的 SMs 中同时运行。
GPC 是硬件层次结构中的一组 SMs ,它们在物理上总是紧密相连。集群具有硬件加速障碍和新的内存访问协作能力,将在以下部分讨论。 GPC 中用于 SMs 的专用 SM-to-SM 网络在群集中的线程之间提供快速数据共享。
在 CUDA 中,网格中的线程块可以在内核启动时选择性地分组到集群中,如图 11 所示,集群功能可以从 CUDA cooperative_groups API 中利用。
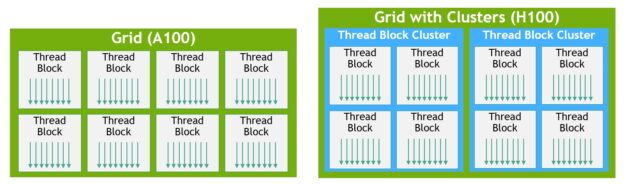
网格由传统 CUDA 编程模型中的线程块组成,如 A100 所示,如图左半部分所示。NVIDIA 的 Hopper 架构增加了可选的集群层次结构,在图的右半部分显示。
分布式共享内存
使用集群,所有线程都可以通过加载、存储和原子操作直接访问其他 SM 的共享内存。此功能称为分布式共享内存( DSEM ),因为共享内存虚拟地址空间在逻辑上分布在集群中的所有块上。
DSEM 使 SMs 之间的数据交换更加高效,不再需要通过全局内存写入和读取数据来传递数据。群集专用的 SM-to-SM 网络确保了对远程 DSEM 的快速、低延迟访问。与使用全局内存相比, DSEM 将线程块之间的数据交换速度提高了约 7 倍。
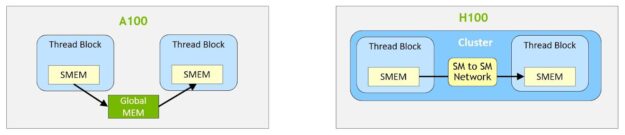
在 CUDA 级别,集群中所有线程块的所有 DSEM 段都映射到每个线程的通用地址空间中,这样所有 DSEM 都可以用简单的指针直接引用。 CUDA 用户可以利用 cooperative _ groups API 构造指向集群中任何线程块的通用指针。 DSEM 传输也可以表示为异步复制操作,与基于共享内存的屏障同步,以跟踪完成情况。
图 13 显示了在不同算法上使用集群的性能优势。集群使您能够直接控制 GPU 的更大部分,而不仅仅是单个 SM ,从而提高了性能。集群支持与更多线程的协作执行,与单线程块相比,集群可以访问更大的共享内存池。
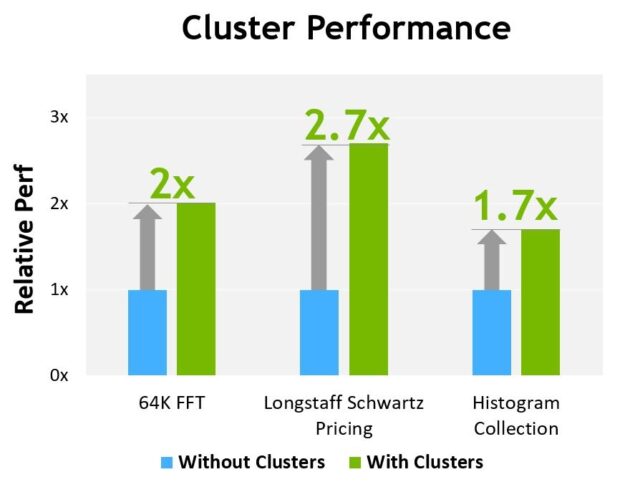
H100 的初步性能评估基于当前预期,并可能会随着运输产品的变化而变化
异步执行
每一代 NVIDIA GPU 都包括许多架构增强功能,以提高性能、可编程性、能效、 GPU 利用率和许多其他因素。最近几代 NVIDIA GPU 包含了异步执行功能,以实现数据移动、计算和同步的更多重叠。
在 NVIDIA Hopper 架构提供了新的功能,提高异步执行,并使进一步重叠的内存副本与计算和其他独立的工作,同时也最小化同步点。我们描述了称为张量内存加速器( TMA )的新异步内存复制单元和一个新的异步事务屏障。
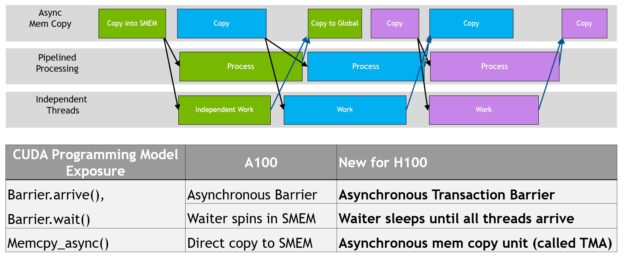
数据移动、计算和同步的编程重叠。异步并发和最小化同步点是性能的关键.
张量记忆加速器
为了帮助提供强大的新 H100 张量内核,新的张量内存加速器( TMA )提高了数据获取效率,它可以将大数据块和多维张量从全局内存传输到共享内存,然后再传输回来。
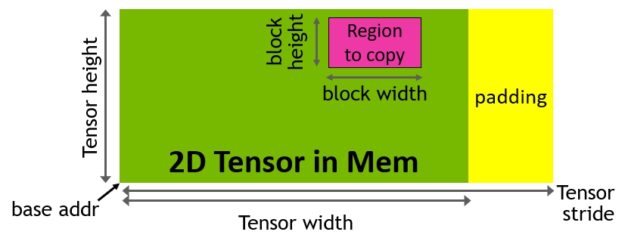
TMA 操作使用拷贝描述符启动,该描述符使用张量维度和块坐标指定数据传输,而不是每个元素寻址(图 15 )。可以指定达到共享内存容量的大数据块,并将其从全局内存加载到共享内存,或从共享内存存储回全局内存。 TMA 通过支持不同的张量布局( 1D-5D 张量)、不同的内存访问模式、缩减和其他功能,显著降低了寻址开销,提高了效率。
TMA 操作是异步的,并利用 A100 中引入的基于共享内存的异步屏障。此外, TMA 编程模型是单线程的,其中选择 warp 中的一个线程来发出异步 TMA 操作( cuda::memcpy_async ),以复制张量。因此,多个线程可以在 cuda::barrier 上等待数据传输的完成。为了进一步提高性能, H100 SM 增加了硬件来加速这些异步屏障等待操作。
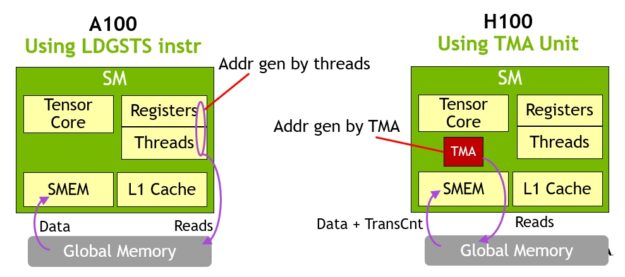
TMA 的一个关键优点是,它可以释放线程来执行其他独立的工作。在 A100 上(图 16 ,左图),异步内存拷贝是使用一条特殊的LoadGlobalStoreShared指令执行的,因此线程负责生成所有地址并在整个拷贝区域中循环。
在 NVIDIA Hopper 上, TMA 负责一切。在启动 TMA 之前,单个线程会创建一个拷贝描述符,从那时起,地址生成和数据移动将在硬件中处理。 TMA 提供了一个简单得多的编程模型,因为它承担了复制张量段时计算跨距、偏移和边界计算的任务。
异步事务屏障
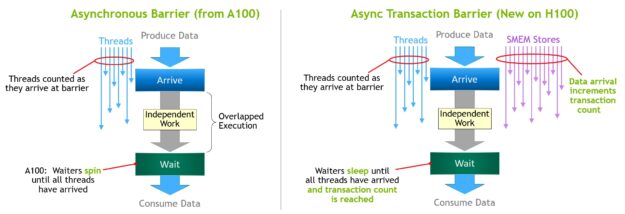
异步屏障最初引入NVIDIA 安培架构(图 17 ,左)。考虑一组线程产生数据,它们在一个屏障之后都消耗的数据。异步屏障将同步过程分为两个步骤。
- 首先,当线程完成生成其共享数据部分时,会向
Arrive发送信号。此Arrive是非阻塞的,因此线程可以自由执行其他独立工作。 - 最终,这些线程需要所有其他线程生成的数据。此时,它们执行一个
Wait,这会阻止它们,直到每个线程都发出Arrive信号。
异步屏障的优点是,它们使提前到达的线程能够在等待时执行独立的工作。这种重叠是额外性能的来源。如果所有线程都有足够的独立工作,那么障碍实际上就没有了,因为Wait指令可以立即失效,因为所有线程都已经到达。
NVIDIA Hopper 的新功能是 waiting 线程能够在所有其他线程到达之前休眠。在以前的芯片上,等待线程会在共享内存中的屏障对象上旋转。
尽管异步屏障仍然是NVIDIA 的漏斗编程模型的一部分,但它增加了一种新的屏障形式,称为异步交易屏障。异步事务屏障类似于异步屏障(图 17 ,右图)。它也是一个分割屏障,但它不仅计算线程到达,还计算事务。
NVIDIA Hopper 包含一个用于写入共享内存的新命令,该命令传递要写入的数据和事务计数。事务计数本质上是字节计数。异步事务屏障在Wait命令处阻塞线程,直到所有生产者线程执行Arrive,并且所有事务计数之和达到预期值。
异步事务屏障是用于异步 mem 拷贝或数据交换的强大新原语。如前所述,集群可以通过隐含的同步进行线程块到线程块的数据交换,集群的能力建立在异步事务壁垒之上。
H100 HBM 和二级缓存内存体系结构
GPU 内存体系结构和层次结构的设计对应用程序性能至关重要,并影响 GPU 大小、成本、功耗和可编程性。 GPU 中存在许多内存子系统,从大量片外 DRAM (帧缓冲)设备内存、不同级别和类型的片上内存,到 SM 中用于计算的寄存器文件。
H100 HBM3 和 HBM2e DRAM 子系统
随着 HPC 、 AI 和数据分析数据集的规模不断扩大,计算问题变得越来越复杂,需要更大的 GPU 内存容量和带宽。
- NVIDIA P100 是世界上第一个支持高带宽 HBM2 存储技术的 GPU 体系结构。
- NVIDIA V100 提供了更快、更高效、更高容量的 HBM2 实现。
- NVIDIA A100 GPU 进一步增加 HBM2 的性能和容量。
H100 SXM5 GPU 通过支持 80 GB (五层)的快速 HBM3 内存,提供了超过 3 TB /秒的内存带宽,实际上比两年前推出的 A100 内存带宽增加了 2 倍。 PCIe H100 提供 80 GB 的高速 HBM2e ,内存带宽超过 2 TB /秒。
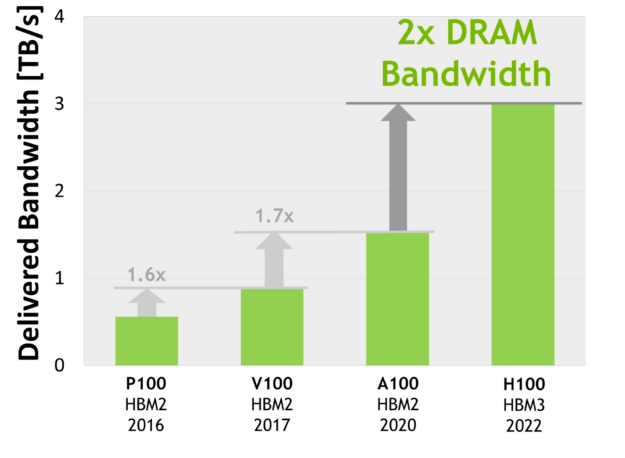
内存数据速率未最终确定,可能会在最终产品中发生变化。
H100 二级缓存
H100 中的 50 MB 二级缓存比 A100 40 MB 二级缓存大 1.25 倍。它可以缓存更大部分的模型和数据集,以便重复访问,减少对 HBM3 或 HBM2e DRAM 的访问,并提高性能。
二级缓存使用分区交叉结构,对直接连接到分区的 GPC 中 SMs 的内存访问进行本地化和缓存数据。二级缓存驻留控制优化容量利用率,使您能够有选择地管理应保留在缓存中或被逐出的数据。
HBM3 或 HBM2e DRAM 和二级缓存子系统都支持数据压缩和解压缩技术,以优化内存和缓存的使用和性能。
| GPU Features | NVIDIA A100 | NVIDIA H100 SXM51 | NVIDIA H100 PCIe1 |
| GPU Architecture | NVIDIA Ampere | NVIDIA Hopper | NVIDIA Hopper |
| GPU Board Form Factor | SXM4 | SXM5 | PCIe Gen 5 |
| SMs | 108 | 132 | 114 |
| TPCs | 54 | 62 | 57 |
| FP32 Cores / SM | 64 | 128 | 128 |
| FP32 Cores / GPU | 6912 | 16896 | 14592 |
| FP64 Cores / SM (excl. Tensor) | 32 | 64 | 64 |
| FP64 Cores / GPU (excl. Tensor) | 3456 | 8448 | 7296 |
| INT32 Cores / SM | 64 | 64 | 64 |
| INT32 Cores / GPU | 6912 | 8448 | 7296 |
| Tensor Cores / SM | 4 | 4 | 4 |
| Tensor Cores / GPU | 432 | 528 | 456 |
| GPU Boost Clock (Not finalized for H100)3 |
1410 MHz | Not finalized | Not finalized |
| Peak FP8 Tensor TFLOPS with FP16 Accumulate1 | N/A | 2000/40002 | 1600/32002 |
| Peak FP8 Tensor TFLOPS with FP32 Accumulate1 | N/A | 2000/40002 | 1600/32002 |
| Peak FP16 Tensor TFLOPS with FP16 Accumulate1 | 312/6242 | 1000/20002 | 800/16002 |
| Peak FP16 Tensor TFLOPS with FP32 Accumulate1 | 312/6242 | 1000/20002 | 800/16002 |
| Peak BF16 Tensor TFLOPS with FP32 Accumulate1 | 312/6242 | 1000/20002 | 800/16002 |
| Peak TF32 Tensor TFLOPS1 | 156/3122 | 500/10002 | 400/8002 |
| Peak FP64 Tensor TFLOPS1 | 19.5 | 60 | 48 |
| Peak INT8 Tensor TOPS1 | 624/12482 | 2000/40002 | 1600/32002 |
| Peak FP16 TFLOPS (non-Tensor)1 | 78 | 120 | 96 |
| Peak BF16 TFLOPS (non-Tensor)1 | 39 | 120 | 96 |
| Peak FP32 TFLOPS (non-Tensor)1 | 19.5 | 60 | 48 |
| Peak FP64 TFLOPS (non-Tensor)1 | 9.7 | 30 | 24 |
| Peak INT32 TOPS1 | 19.5 | 30 | 24 |
| Texture Units | 432 | 528 | 456 |
| Memory Interface | 5120-bit HBM2 | 5120-bit HBM3 | 5120-bit HBM2e |
| Memory Size | 40 GB | 80 GB | 80 GB |
| Memory Data Rate (Not finalized for H100)1 |
1215 MHz DDR | Not finalized | Not finalized |
| Memory Bandwidth1 | 1555 GB/sec | 3000 GB/sec | 2000 GB/sec |
| L2 Cache Size | 40 MB | 50 MB | 50 MB |
| Shared Memory Size / SM | Configurable up to 164 KB | Configurable up to 228 KB | Configurable up to 228 KB |
| Register File Size / SM | 256 KB | 256 KB | 256 KB |
| Register File Size / GPU | 27648 KB | 33792 KB | 29184 KB |
| TDP1 | 400 Watts | 700 Watts | 350 Watts |
| Transistors | 54.2 billion | 80 billion | 80 billion |
| GPU Die Size | 826 mm2 | 814 mm2 | 814 mm2 |
| TSMC Manufacturing Process | 7 nm N7 | 4N customized for NVIDIA | 4N customized for NVIDIA |
- H100 的初步规格基于当前预期,并可能会在运输产品中发生变化
- 使用稀疏特性的有效顶部/ t 顶部
- GPU Peak Clock and GPU Boost Clock are synonymous for NVIDIA Data Center GPU
由于 H100 和 A100 Tensor Core GPU 设计用于安装在高性能服务器和数据中心机架中,为 AI 和 HPC 计算负载供电,因此它们不包括显示连接器、用于光线跟踪加速的 NVIDIA RT Core 或 NVENC 编码器。
计算能力
H100 GPU 支持新的计算能力 9.0 。表 4 比较了 NVIDIA GPU 体系结构不同计算能力的参数。
| Data Center GPU | NVIDIA V100 | NVIDIA A100 | NVIDIA H100 |
| GPU architecture | NVIDIA Volta | NVIDIA Ampere | NVIDIA Hopper |
| Compute capability | 7.0 | 8.0 | 9.0 |
| Threads / warp | 32 | 32 | 32 |
| Max warps / SM | 64 | 64 | 64 |
| Max threads / SM | 2048 | 2048 | 2048 |
| Max thread blocks (CTAs) / SM | 32 | 32 | 32 |
| Max thread blocks / thread block clusters | N/A | N/A | 16 |
| Max 32-bit registers / SM | 65536 | 65536 | 65536 |
| Max registers / thread block (CTA) | 65536 | 65536 | 65536 |
| Max registers / thread | 255 | 255 | 255 |
| Max thread block size (# of threads) | 1024 | 1024 | 1024 |
| FP32 cores / SM | 64 | 64 | 128 |
| Ratio of SM registers to FP32 cores | 1024 | 1024 | 512 |
| Shared memory size / SM | Configurable up to 96 KB | Configurable up to 164 KB | Configurable up to 228 KB |
Transformer 发动机
Transformer 模型是当今广泛使用的语言模型(从 BERT 到 GPT-3 )的支柱,它们需要巨大的计算资源。 Transformers 最初是为自然语言处理( natural language processing , NLP )开发的,越来越多地应用于计算机视觉、药物发现等不同领域。
它们的规模继续呈指数级增长,现在已达到数万亿个参数,导致它们的培训时间长达数月,这对于业务需求来说是不切实际的,因为需要大量计算。例如, Megatron 图灵 NLG ( MT-NLG )需要 2048 NVIDIA A100 GPU 运行 8 周才能进行训练。总体而言, transformer 模型在过去 5 年中以每 2 年 275 倍的速度增长,远远快于大多数其他人工智能模型(图 19 )。
H100 包括一个新的 transformer 引擎,该引擎使用软件和定制的 NVIDIA Hopper Tensor 核心技术,显著加速变压器的人工智能计算。
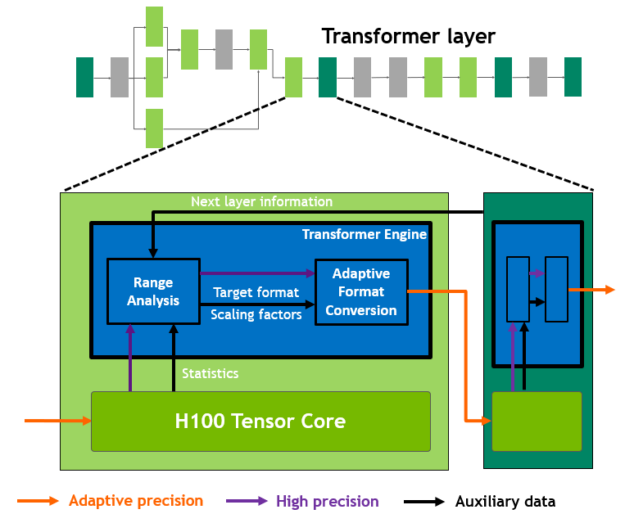
混合精度的目标是智能地管理精度以保持精度,同时仍能获得更小、更快的数值格式的性能。在 Transformer 模型的每一层, transformer 引擎分析张量核产生的输出值的统计信息。
Transformer 引擎知道下一个是哪种类型的神经网络层,以及它所需的精度,因此在将张量存储到内存之前,还可以决定将张量转换为哪种目标格式。与其他数字格式相比, FP8 的范围更为有限。
为了最佳地使用可用范围, Transformer 引擎还使用根据张量统计数据计算的比例因子,动态地将张量数据缩放到可表示的范围。因此,每一层都以其所需的精确范围运行,并以最佳方式加速。
第四代 NVLink 和 NVLink 网络
新兴的 exascale HPC 和万亿参数人工智能模型(用于超人类对话人工智能等任务)需要数月的训练,即使是在超级计算机上。将这种延长的培训时间从几个月压缩到几天,以便对企业更有用,需要服务器集群中每个 GPU 之间进行高速、无缝的通信。 PCIe 带宽有限,造成了瓶颈。为了构建最强大的端到端计算平台,需要更快、更可扩展的 NVLink 互连。
NVLink 是NVIDIA 的高带宽、节能、低延迟、无损 GPU 到 – GPU 互连,包括弹性特性,如链路级错误检测和数据包重放机制,以保证数据的成功传输。新的第四代 NVLink 在 H100 GPU 中实现,与NVIDIA A100 张量核心 GPU 中使用的第三代 NVLink 相比,提供 1.5 倍的通信带宽。
对于多 GPU I / O 和共享内存访问,新的 NVLink 以 900 GB / s 的总带宽运行,提供的带宽是 PCIe Gen 5 的 7 倍。 A100 GPU 中的第三代 NVLink 在每个方向上使用四个差分对(通道),以创建单个链路,在每个方向上提供 25 GB / s 的有效带宽。相比之下,第四代 NVLink 在每个方向上仅使用两个高速差分对来形成单个链路,在每个方向上也提供 25 GB / s 的有效带宽。
- H100 包括 18 个第四代 NVLink 链路,可提供 900 GB / s 的总带宽。
- A100 包括 12 个第三代 NVLink 链路,可提供 600 GB /秒的总带宽。
在第四代 NVLink 的基础上, H100 还引入了新的 NVLink 网络互连,这是 NVLink 的一个可扩展版本,使 GPU 能够跨多个计算节点在多达 256 个 GPU 节点之间进行 GPU 通信。
与常规 NVLink 不同, NVLink 网络引入了一个新的网络地址空间,所有 GPU 共享一个公共地址空间,请求直接使用 GPU 物理地址路由。 H100 中的新地址转换硬件支持将所有 GPU 地址空间彼此隔离,并与网络地址空间隔离。这使得 NVLink 网络能够安全地扩展到更大数量的 GPU 。
由于 NVLink 网络端点不共享公共内存地址空间,因此不会在整个系统中自动建立 NVLink 网络连接。相反,与 InfiniBand 等其他网络接口类似,用户软件应该根据需要明确地在端点之间建立连接。
第三代网络交换机
新的第三代 NVSwitch 技术包括驻留在节点内部和外部的交换机,用于连接服务器、集群和数据中心环境中的多个 GPU 。节点内的每个新的第三代 NVSwitch 都提供 64 个第四代 NVLink 链路端口,以加速多 GPU 连接。交换机总吞吐量从上一代的 7.2 TB / s 增加到 13.6 TB / s 。
新的第三代 NVSwitch 还通过多播和 NVIDIA SHARP 在网络缩减方面提供了集体操作的硬件加速。加速集体包括write broadcast(all_gather)、reduce_scatter和broadcast atomics。与在 A100 上使用 NVIDIA 集体通讯图书馆 ( NCCL )相比,结构内多播和减少提供了高达 2 倍的吞吐量增益,同时显著减少了小数据块大小集合的延迟。 NVSwitch collectives 的加速功能显著降低了短信在集体通信中的负载。
新型 NVLink 交换系统
结合新的 NVLINK 网络技术和新的第三代 NVSwitch , NVIDIA 能够以前所未有的通信带宽水平构建大规模 NVLINK 交换系统网络。每个 GPU 节点暴露出节点中 GPU 的所有 NVLink 带宽的 2:1 锥形级别。这些节点通过 NVLink 交换机模块中包含的第二级 NVSwitch 连接在一起, NVLink 交换机模块位于计算节点之外,并将多个节点连接在一起。
NVLink 交换机系统最多支持 256 GPU 。连接的节点可以提供 57.6 TB 的全对全带宽,并可以提供令人难以置信的 FP8 稀疏人工智能计算的 1 倍。
图 21 显示了基于 A100 和 H100 的 32 节点 256 GPU DGX 叠加的比较。基于 H100 的 SuperPOD 使用新的 NVLink 交换机互连 DGX 节点。
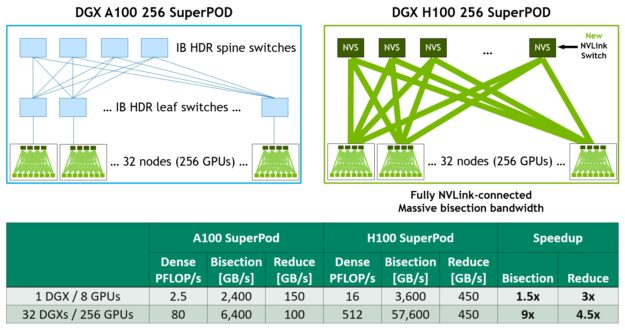
DGX H100 SuperPads 可跨越多达 256 GPU ,使用基于第三代 NVSwitch 技术的新型 NVLink 交换机,通过 NVLink 交换机系统完全连接。如图所示,与基于 A100 、具有类似规模、采用 leaf spine 架构的机器相比, H100 系统根本不需要 InfiniBand 连接。
例如,与上一代 InfiniBand 系统相比,采用 2:1 锥形胖树拓扑结构的 NVLink 网络互连使所有对所有交换机的对分带宽增加了 9 倍,使所有减少的吞吐量增加了 4.5 倍。
PCIe 第 5 代
H100 集成了 PCI Express Gen 5 x16 通道接口,提供 128 GB / s 的总带宽(每个方向 64 GB / s ),而 A100 中包含的 Gen 4 PCIe 总带宽为 64 GB / s (每个方向 32 GB / s )。
使用其 PCIe Gen 5 接口, H100 可以与性能最高的 x86 CPU 和 SmartNICs 以及 数据处理器 ( DPU )接口。 H100 设计用于与 NVIDIA BlueField-3 DPU 的最佳连接,用于 400 Gb / s 以太网或下一个数据速率( NDR ) 400 Gb / s InfiniBand 网络加速,用于安全的 HPC 和 AI 工作负载。
H100 增加了对本机 PCIe 原子操作的支持,如 32 位和 64 位数据类型的原子 CA 、原子交换和原子提取添加,加快了 CPU 和 GPU 之间的同步和原子操作。 H100 还支持单根输入/输出虚拟化( SR-IOV ),该虚拟化支持为多个进程或虚拟机共享和虚拟化单个 PCIe 连接的 GPU 。 H100 允许连接 GPU 的单个 SR-IOV PCIe 的虚拟功能( VF )或物理功能( PF )通过 NVLink 访问对等方 GPU 。
总结
有关增强应用程序性能的其他新的和改进的 H100 功能的更多信息,请参阅 NVIDIA H100 Tensor Core GPU 体系结构 whitepaper.
致谢
我们要感谢斯蒂芬·琼斯、曼宁德拉·帕希、阿图尔·卡兰布尔、哈里·佩蒂、乔·德莱尔、杰克·乔奎特、马克·哈梅尔、纳文·切鲁库里、布兰登·贝尔、乔纳·阿尔本以及许多其他NVIDIA GPU 建筑师和工程师,他们为这篇文章做出了贡献。




