AI 在规模、复杂性和多样性方面的快速增长推动了对 大型语言模型 (LLM) 训练性能的不断需求。要提供出色的性能,需要能够在整个数据中心规模上高效地训练模型。这是通过技术堆栈的每一层 — 包括芯片、系统和软件 — 的卓越工艺来实现的。
我们的 NVIDIA NeMo 框架 是一个端到端的云原生框架,旨在构建、自定义和部署生成式 AI 模型。它整合了一系列先进的并行技术,以实现大规模 LLM 的高效训练。
实际上,NeMo 支持 NVIDIA 最近在 MLPerf 训练 行业标准基准测试中提交的出色 GPT-3 1750 亿参数性能数据,每个 H100 GPU 可实现高达 797 TFLOPS 的性能。此外,在 NVIDIA 提交的最大规模测试中,使用了前所未有的 10752 个 H100 Tensor Core GPU,实现了创纪录的性能和近线性的性能扩展。
今天,NVIDIA 宣布即将在 1 月发布的 NeMo 框架将包含一系列优化和新功能。这些功能将显著提升 NVIDIA AI Foundations 模型的性能,包括 Llama 2、NeMo Megatron-3 以及其他 LLM,并扩展了对 NeMo 模型架构的支持。此外,它还提供了一种急需的并行技术,使得在 NVIDIA AI 平台上训练各种模型变得更加容易。
将 Lama 2 70B 预训练和监督式微调速度提升高达 4.2 倍
Lama 2 是一种热门的开源大型语言模型,最初由 Meta 开发。最新版本的 NeMo 包含许多可提高 Lama 2 性能的改进。与在 A100 GPU 上运行的上一个 NeMo 版本相比,在 H200 GPU 上运行的最新 NeMo 版本可将 Lama 2 的预训练和监督式微调性能提高 4.2 倍。
第一个改进是添加了模型优化器状态的混合精度实现。这降低了模型容量需求,并将与模型状态交互的操作的有效内存带宽提高了 1.8 倍。
旋转位置嵌入 (RoPE) 运算(许多近期 LLM 架构采用的先进算法)的性能也得到了提升。此外,Swish-Gated Linear Unit (SwiGLU) 激活函数的性能也得到了优化,在现代 LLM 中,该函数通常可取代高斯误差线性单元 (GELU).
最后,Tensor Parallelism 的通信效率得到大幅提升,并且针对 Pipeline Parallelism 的通信块大小进行了调整。
总的来说,这些改进基于 GPU 上的 Tensor Core 利用率,NVIDIA Hopper 架构使得每个 H200 GPU 能够实现高达 836 TFLOPS 的性能,适用于 Lama 2 70B 的预训练和监督式微调。
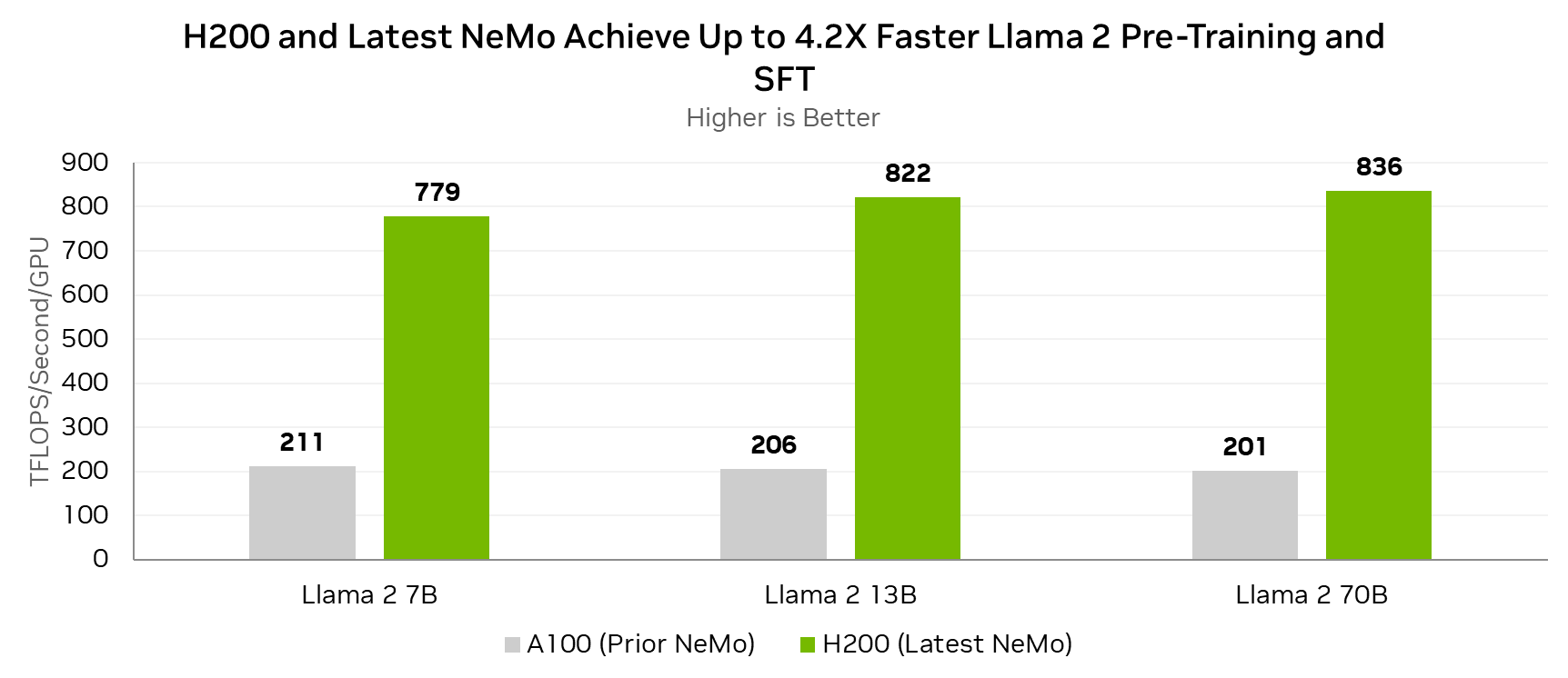
每个 GPU 的测量性能。全局批量大小=128.
||Lama 2 7B:序列长度 4096 A100 8x GPU,NeMo 23.08 H200 8x GPU,NeMo 24.01-alpha
||Lama 2 13B:序列长度 4096 A100 8x GPU,NeMo 23.08 H200 8x GPU,NeMo 24.01-alpha
||Lama 2 70B:序列长度 4096 A100 32x GPU,NeMo 23.08 H200 8x GPU,NeMo 24.01-alpha
H200 GPU 与最新版本的 NeMo 相结合,可以实现出色的 Lama 2 训练吞吐量,与运行上一个 NeMo 版本的 A100 GPU 相比,可实现高达 4.2 倍的提升。
| 训练令牌/秒/GPU | Lama 2 13B | Lama 2 70B | |
|---|---|---|---|
| H200 (最新 NeMo) | 小行星 16913 | 9432 | 1880 年 |
| A100 (之前的 NeMo) | 小行星 4583 | 2357 | 451 |
| 加速 | 3.7 倍 | 4.0 倍 | 4.2 倍 |
每个 GPU 的测量性能。全局批量大小=128.
||Lama 2 7B:序列长度 4096 A100 8x GPU,NeMo 23.08 H200 8x GPU,NeMo 24.01-alpha
||Lama 2 13B:序列长度 4096 A100 8x GPU,NeMo 23.08 H200 8x GPU,NeMo 24.01-alpha
||Lama 2 70B:序列长度 4096 A100 32x GPU,NeMo 23.08 H200 8x GPU,NeMo 24.01-alpha
从上下文来看,基于八路 NVIDIA HGX H200 的单个系统可以在长度为 4096 的序列上使用 70B 参数以超过 15000 个令牌/秒的速率对 Lama 2 进行微调。这意味着它可以在 18 小时多一点的时间内完成包含 1B 令牌的监督式微调任务。
完全分片数据并行
全分片数据并行 (FSDP) 是深度学习社区中众所周知的热门功能。它被主要框架(包括 PyTorch、DeepSpeed 和 JAX)中的深度学习从业者所使用,并应用于各种模型。
FSDP 可应用于各种模型,并且对于 LLM 尤其有用,因为现代 LLM 的计算和内存需求远远超出了单个高级 GPU 的范围。
对模型进行管线处理是一种有效的性能优化。但这需要模型具有非常规则的结构(例如,同一层重复 128 次),因为不同的层分布在不同的 GPU 上,并且数据以管线方式在它们之间流动。
FSDP 为开发者提供了更高的易用性,并将各种情况下的性能损失降至最低。这是因为模型的数据和内存是按层分布的,因此更容易管理常规或不规则的神经网络结构。
作为数据并行性的自然扩展,FSDP 通常可通过简单的模型包装器来使用,而无需考虑模型的分区方式(就像管道并行中的情况一样)。这还可以更轻松地将 FSDP 扩展到新的和新兴的模型架构,例如多模态 LLM.
在小于全局批量大小的规模上有足够的并行性时,FSDP 还可以实现与张量并行性和管道并行性方法的传统组合具有竞争力的性能。
| GPT-20B 训练性能 (BF16) | |||||
| H100 GPU 数量 | 8 | 16 | 32 | 64 | 128 |
| FSDP | 0.78 倍 | 0.88 倍 | 0.89 倍 | 0.86 倍 | 0.96 倍 |
| 3D 并行度 | 1.0 倍 | 1.0 倍 | 1.0 倍 | 1.0 倍 | 1.0 倍 |
测量性能。全局批量大小=256,序列长度=2048
多专家模型
提高生成式 AI 模型的信息吸收和泛化能力的一种经过验证的方法是增加模型中的参数数量。但是,随着模型容量的增加,执行推理所需的计算量也会增加,从而增加在生产环境中运行模型的成本。
最近,一种名为“多专家模型 (MoE)”的机制引起了极大的关注。该机制能够在训练和推理计算需求不按比例增加的情况下提高模型容量。MoE 架构通过条件计算方法来实现这一点,其中每个输入令牌仅路由到一个或几个专家神经网络层,而不是通过它们全部路由。这将模型容量与所需的计算解。
最新版本的 NeMo 引入了对具有专家并行性的基于 MoE (Mixture of Experts) 的 LLM (Large Language Models) 架构的官方支持。此实现采用的架构类似于平衡分配专家 (BASE),其中每个 MoE 层将每个令牌精确地传送给一位专家,并采用算法实现负载均衡。NeMo 使用基于Sinkhorn算法的路由,以在各个专家之间平衡令牌负载。
基于 NeMo 的 MoE 模型支持专家并行,可与数据并行结合使用,在数据并行秩中分配 MoE 专家。NeMo 还提供了任意配置专家并行的能力。用户可以以各种方式将专家映射到不同的 GPU,而不限制单个设备上的专家数量(但是,所有设备必须包含相同数量的专家)。NeMo 还支持专家并行大小小于数据并行大小的情况。
开发者可以将 NeMo 专家并行方法与 NeMo 提供的许多其他并行维度(包括张量、管线和序列并行)结合使用。这有助于在具有多个 NVIDIA GPU 的集群上高效训练具有超过万亿个参数的模型。
使用 TensorRT-LLM 的 RLHF
现在,使用 TensorRT-LLM 在 RLHF 循环内进行推理的能力增强了 NeMo 对基于人类反馈的强化学习 (RLHF) 的支持。
TensorRT-LLM 可加速 Actor 模型的推理阶段,该阶段目前占用了大部分端到端计算时间。Actor 模型是正在对齐的感兴趣模型,将成为 RLHF 过程的最终输出。
即将发布的 NeMo 版本通过 TensorRT-LLM 实现 RLHF 的管道并行,使其能够以更少的节点实现更好的性能,同时还支持更大的模型。
事实上,对于 Lama 2 70B 参数模型,与在同一 H100 GPU 上不使用 TensorRT-LLM 的 RLHF 循环相比,在配备 H100 GPU 的 RLHF 循环中使用 TensorRT – LLM 可实现高达 5.6 倍的性能提升。
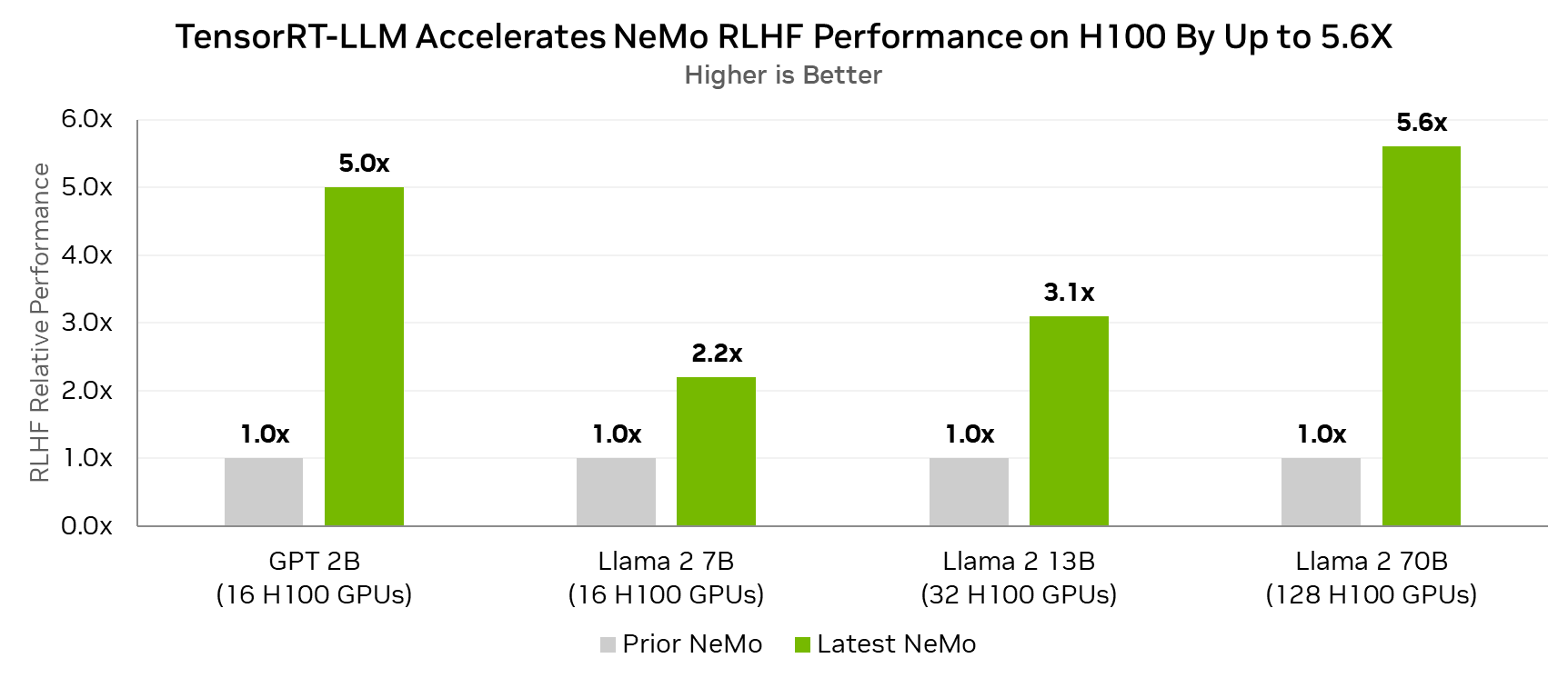
测量性能。全局批量大小=64,滚动大小=512,最大生成长度=1024.
在实施的 RLHF 算法中,每个结果的一半节点运行 Actor,另一半运行 Critical.
突破生成式 AI 的界限
AI 训练需要全栈方法。 NVIDIA NeMo 会定期更新,为训练高级生成式 AI 模型提供最佳性能。它采用最新的训练方法来提高性能,并为 NVIDIA 平台用户提供更高的灵活性。
NVIDIA 平台的应用范围极其广泛,能够端到端地加速整个 AI 工作流程,包括数据准备、模型训练以及部署推理。继 10 月推出 TensorRT-LLM 之后,NVIDIA 最近展示了在单个 H200 GPU 上运行最新的 Falcon-180B 模型的能力。该模型利用了 TensorRT-LLM 的先进 4 位量化技术,同时保持了 99% 的准确率。欲了解更多关于此实现的信息,请访问关于 TensorRT-LLM 的最新帖子。
NVIDIA AI 平台不断以光速提升性能、通用性和功能。因此,它是开发和部署当今生成式 AI 应用程序以及发明为未来提供动力支持的模型和技术的首选平台。
开始使用 NeMo 框架
我们的 NVIDIA NeMo 框架 可以作为 GitHub 上的开源库、NGC 上的容器使用,同时也是 NVIDIA AI Enterprise 的一部分。NVIDIA AI Enterprise 是一个为企业级 AI 提供的软件平台,它具备安全性、稳定性、可管理性和强大的支持功能。