
本系列介绍 开发和部署 ( M L ) 模型 。在本文中, 你将学习 如何部署 ML 模型到 Google 云平台 . 第 1 部分给出了 ML 工作流概括 ,考虑了使用机器学习和数据科学来实现商业价值所涉及的各个阶段。在第 2 部分中,您将学习 训练并保存 ML 模型 并将其部署为 ML 系统的一部分。
在为 ML 系统构建端到端管道时,最后一步是将经过训练的模型部署到生产环境中。成功的部署意味着 ML 模型已从研究环境中移出并集成到生产环境中,例如,作为一个实时应用程序。
在本文中,您将学习使用 Google 云平台( GCP )将 ML 模型投入生产的三种方法。虽然您可以使用其他几种环境,例如 AWS 、 Microsoft Azure 或本地硬件,但本教程使用 GCP 部署 web 服务。
正在设置
通过您的 Google 帐户注册 Google Cloud Platform 。系统会提示您填写一些信息,包括您的信用卡详细信息。但是,您注册该平台将不收取任何费用。您还可以在前 90 天获得价值 300 美元的免费信贷。
创建帐户后, 创建新的项目 并将其命名为 GCP-deployment-example 。不要将项目链接到组织。
确保已将当前项目更改为新创建的项目。
在 Google App Engine 上部署 ML 模型
在您可以在 GoogleAppEngine 上部署模型之前,还有一些额外的模块要添加到代码中。
本节中使用的代码可以在 /kurtispykes/gcp-deployment-example GitHub repo 中找到。
第一步是在predict.py模块中创建推理逻辑:
import joblib
import pandas as pd
model = joblib.load("logistic_regression_v1.pkl")
def make_prediction(inputs):
"""
Make a prediction using the trained model
"""
inputs_df = pd.DataFrame(
inputs,
columns=["sepal_length_cm", "sepal_width_cm", "petal_length_cm", "petal_width_cm"]
)
predictions = model.predict(inputs_df)
return predictions
本模块中的步骤包括:
- 将持久化模型加载到内存中。
- 创建一个将一些输入作为参数的函数。
- 在函数中,将输入转换为 pandas
DataFrame并进行预测。
接下来,推理逻辑必须封装在 web 服务中。我用 Flask 包装模型。有关详细信息,请参阅main.py:
import numpy as np
from flask import Flask, request
from predict import make_prediction
app = Flask(__name__)
@app.route("/", methods=["GET"])
def index():
"""Basic HTML response."""
body = (
"<html>"
"<body style='padding: 10px;'>"
"<h1>Welcome to my Flask API</h1>"
"</body>"
"</html>"
)
return body
@app.route("/predict", methods=["POST"])
def predict():
data_json = request.get_json()
sepal_length_cm = data_json["sepal_length_cm"]
sepal_width_cm = data_json["sepal_width_cm"]
petal_length_cm = data_json["petal_length_cm"]
petal_width_cm = data_json["petal_width_cm"]
data = np.array([[sepal_length_cm, sepal_width_cm, petal_length_cm, petal_width_cm]])
predictions = make_prediction(data)
return str(predictions)
if __name__ == "__main__":
app.run()
在代码示例中,您创建了两个端点:
index:可以看作是主页/predict:用于与部署的模型交互。
您必须创建的最后一个文件是 app.yaml ,其中包含用于运行应用程序的运行时。
runtime: python38
在 Google Cloud 控制台中,执行以下步骤:
- 在切换菜单上,选择 App Engine 。您可能必须选择 View all products 才能访问 App Engine ,它与 Serverless 产品一起列出)。
- 从 App Engine 页面,选择 Create Application 。
- 选择要在其中创建应用程序的区域。
- 将应用程序语言设置为 Python 并使用 Standard 环境。
在右上角,选择终端图标。这将激活云外壳,这意味着您不必下载云 SDK 。
在部署应用程序之前,必须上载所有代码。由于通过 web 服务与 ML 模型交互所需的所有代码都上传到 gcp-deployment-example/app_engine/ 中的 GitHub 上,因此您可以从云外壳中克隆此存储库。
将代码 URL 复制到剪贴板并导航回 GCP 上的云外壳。向 shell 输入以下命令:
git clone https://github.com/kurtispykes/gcp-deployment-example.git
通过输入以下命令导航到代码存储库:
cd gcp-deployment-example/app_engine
接下来, initialize the application 。确保您选择了最近创建的项目。
现在,部署应用程序。从云 shell 运行以下命令。如果系统提示您继续,请输入Y。
gcloud app deploy
部署完成后,您将获得服务部署位置的 URL 。打开提供的 URL 以验证应用程序是否正常运行。您应该看到 欢迎使用我的 Flask API 消息。
接下来,测试/predict端点。
使用 Postman 发送 POST 请求以测试成功部署
您可以使用 Postman 向/predict端点发送 POST 请求。 Postman 是开发人员设计、构建、测试和迭代 API 的 API 平台。
要开始,请选择 免费注册 。有一个完整的教程,但为了本篇文章的目的,请直接跳到主页。
从那里,选择 Workspaces 、 My Workspace 、 New ,然后选择 HTTP Request 。
接下来,将 HTTP 请求从GET更改为POST,并在请求 URL 中插入到已部署服务的链接。
之后,导航到Body标头并选择raw,以便插入示例实例。选择send。
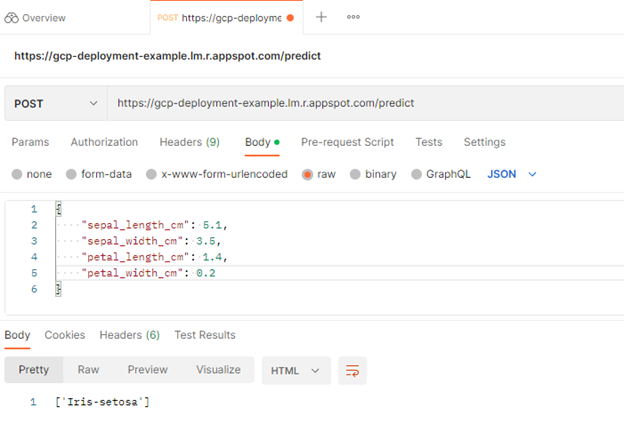
您向/predict端点发送了 POST 请求,其中包含一些定义模型输入的原始数据。在响应中,模型返回[‘Iris-setosa’],这是模型成功部署的积极指示。
您还可以使用 GCP 上提供的其他服务部署模型。
在 Google 云功能上部署 ML 模型
云功能是 GCP 上可用的无服务器技术之一。我对代码做了一些更改,以使部署到云功能无缝。第一个也是最明显的区别是不再从本地存储库导入序列化模型。相反,您正在调用 Google 云存储中的模型。
将模型上传到 Google 云存储
在 GCP 部署示例项目中,选择切换菜单。导航到 Cloud Storage 并选择 Buckets 、 Create Bucket 。这将提示您为存储桶和其他配置提供名称。我把我的名字命名为model-data-iris。
创建桶后,下一个任务是上传持久化模型。选择 Upload Files ,导航到存储模型的位置,然后选择它。
现在,您可以使用 Google Cloud 中的各种服务来访问此文件。要访问云存储,必须从google.cloud导入storage对象。
下面的代码示例显示了如何从 Google 云存储中访问模型。您也可以在 gcp-deployment-example/cloud_functions/main.py 中看到完整的示例。
import joblib
import numpy as np
from flask import request
from google.cloud import storage
storage_client = storage.Client()
bucket = storage_client.get_bucket("model-iris-data") # remember to change the bucket name
blob = bucket.blob("logistic_regression_v1.pkl")
blob.download_to_filename("/tmp/logistic_regression_v1.pkl")
model = joblib.load("/tmp/logistic_regression_v1.pkl")
def predict(request):
data_json = request.get_json()
sepal_length_cm = data_json["sepal_length_cm"]
sepal_width_cm = data_json["sepal_width_cm"]
petal_length_cm = data_json["petal_length_cm"]
petal_width_cm = data_json["petal_width_cm"]
data = np.array([[sepal_length_cm, sepal_width_cm, petal_length_cm, petal_width_cm]])
predictions = model.predict(data)
return str(predictions)
在 Google Cloud 控制台的切换菜单上,选择 Cloud Functions 。要查看菜单,您可能必须选择 View all products 并展开 Serverless 类别。
接下来,选择 Create Function 。如果这是您第一次创建云函数,则要求您启用 API 。选择 Enable 继续。
还要求您进行以下配置设置:
- 函数名称= Predict 。
- Trigger type = HTTP 。
- Allow unauthenticated invocations =已启用。
在运行时、构建、连接和安全设置部分中还有其他配置,但对于本示例,默认值是可以的,因此选择 Next 。
在下一页中,要求您设置运行时并定义源代码的来源。在 Runtime 部分,选择您正在使用的 Python 版本。我使用的是 Python 3.8 。确保在源代码头中选择了 Inline Editor 。
复制并粘贴云函数用作main.py文件入口点的以下代码示例。
{
"sepal_length_cm" : 5.1,
"sepal_width_cm" : 3.5,
"petal_length_cm" : 1.4,
"petal_width_cm" : 0.2
}
使用内联编辑器更新 requirements.txt :
flask >= 2.2.2, <2.3.0
numpy >= 1.23.3, <1.24.0
scitkit-learn >=1.1.2, <1.2.0
google-cloud-storage >=2.5.0, <2.6.0
确保将 Entry point 值更改为端点的名称。在这种情况下,它是predict。
完成所有更改后,选择 Deploy 。部署可能需要几分钟的时间来安装依赖项并启动应用程序。完成后,您会看到成功部署的模型的函数名称旁边有一个绿色的勾号图标。
现在,您可以在 Testing 选项卡上测试应用程序是否正常工作。使用以下示例代码进行测试:
{
"sepal_length_cm" : 5.1,
"sepal_width_cm" : 3.5,
"petal_length_cm" : 1.4,
"petal_width_cm" : 0.2
}
如果您使用与前面相同的输入,则会得到相同的响应。
现在,您已经学会了使用 GoogleCloudFunctions 部署 ML 模型。使用此部署,您不必担心服务器管理。您的云功能仅在收到请求时执行,并且 Google 管理服务器。
在 Google AI 云上部署 ML 模型
之前的两个部署要求您编写不同程度的代码。在谷歌人工智能云上,你可以提供经过训练的模型,他们为你管理一切。
在云控制台上,从切换菜单导航到 AI Platform 。在 Models 选项卡上,选择 Create Model 。
您可能会注意到一条警告消息,通知您 Vertex AI ,这是另一个将 AutoML 和 AI 平台结合在一起的托管 AI 服务。这一讨论超出了本文的范围。
在下一个屏幕上,系统会提示您选择一个区域。选择区域后,选择 Create Model 。为模型命名,相应地调整区域,然后选择 Create 。
转到创建模型的区域,您应该可以看到模型。选择型号并选择 Create a Version 。
接下来,您必须将模型链接到云存储中存储的模型。本节有几个重要事项需要注意:
- AI 平台上
scikit-learn的最新模型框架版本是 1.0.1 版,因此您必须使用此版本来构建模型。 - 模型必须存储为
model.pkl或model.joblib。
为了遵守 GCP AI 平台的要求,我使用所需的模型版本创建了一个新的脚本,将模型序列化为model.pkl,并将其上传到谷歌云存储。有关更多信息,请参阅 /kurtispykes/gcp-deployment-example GitHub repo 中的更新代码。
- Model name:
logistic_regression_model - 选中 Use regional endpoint 复选框。
- Region: 欧洲西部 2
- 在 models 部分,确保仅选择 europe-west2 区域。
为要创建的模型版本选择 Save 。创建模型版本可能需要几分钟的时间。
通过选择模型版本并导航到 Test & Use 标题来测试模型。输入输入数据并选择 Test 。
总结
祝贺现在您知道了使用 Google 云平台( GCP )部署 ML 模型的三种不同方法。
为了巩固您从本教程中获得的知识,我鼓励您使用这三种部署创建自己的应用程序。此外,考虑什么选项最适合特定的用例。
在以下任何平台上与我连接:
寻求从数据摄取到部署机器学习的帮助或指导?加入 Data Processing 论坛。




