
This series looks at the development and deployment of machine learning (ML) models. This post gives an overview of the ML workflow, considering the stages involved in using machine learning and data science to deliver business value. In part 2, you train an ML model and save that model so it can be deployed as part of an ML system. Part 3 shows you how to deploy ML models on Google Cloud Platform (GCP).
When using machine learning to solve problems and deliver business value, the techniques, tools, and models you use change depending on the use case. However, when moving from an idea to a deployed model, you pass through a common set of workflow stages.
Previously, I covered how to build a machine learning microservice and how to build an instant machine learning application using Streamlit. In both tutorials, the ML model only operated locally. This is sufficient for demonstration, but impractical if your model must continuously serve predictions on the internet.
Machine learning workflow
The ML workflow has the following major components:
- Exploration and data processing
- Modeling
- Deployment
Each phase can be broken down into smaller procedures.
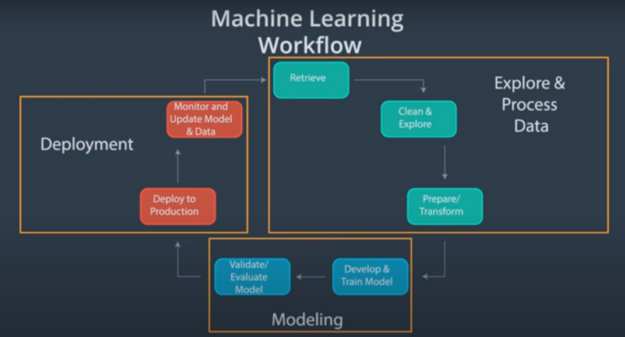
(Source: Become a Machine Learning Engineer Nanodegree (Udacity))
Figure 1 shows a visual representation of the end-to-end workflow for a typical machine learning project. Here’s more information about each component.
Exploration and processing
Significant work goes into ensuring the dataset being used for an ML project is of good quality, as this data serves as the basis for reliable performance during the modeling phase. If you feed low-quality data to the model, you can expect poor or faulty results.
This part of the workflow often takes up the most time. Data exploration and processing can be further broken down into the following stages:
- Data retrieval: An ML project requires high-quality data, which is not always immediately accessible. You may be required to implement data acquisition techniques, such as scraping or manual data collection.
- Data cleaning and exploration: Data is also seldom ready to be instantly processed. You must clean it for optimal performance in the desired use case. You should also understand the dataset you are working with, hence the need for exploration.
- Data preparation or transformation: In the final stage, data is engineered to extract representative features of the real-world problem being solved. The data is then transformed into a format that an ML model can consume.
Modeling
When most data practitioners think of machine learning, their minds gravitate to the modeling component. The modeling phase encompasses the following stages:
- Model development and training: This stage is about feeding data to the machine learning model and then tuning hyperparameters so the model can generalize well to unseen data inputs.
- Model validation and evaluation: The performance of a machine learning model must be evaluated to determine if it is behaving as expected. This involves identifying a numeric metric to evaluate the model’s performance on unseen data inputs.
Model deployment
Finally, the deployment phase involves making the ML model accessible to end users, monitoring the model’s performance in production, and updating the model.
Deploying an ML model is not merely about the model in isolation. Data practitioners deploy the entire ML pipeline, which dictates how you codify and automate the end-to-end workflow.
There are several options for how you can achieve this.
Different model deployment options
ML applications are produced to solve a specific problem. Thus, the true value of any ML application can often only be realized when the model or algorithm is actively being used in a production environment.
The process of shifting an ML model from an offline research environment to a live production environment is known as deployment.
Deployment is a critical component of the ML workflow. It enables the model to serve its intended purpose. Plenty of thought must go into how you want to deploy your ML model during the project planning phase. The factors to consider when deciding on your deployment type are beyond the scope of this post. However, I provide some insight into the options that you have available.
Web service
The most straightforward option to deploy your machine learning model is to create a web service. This means predictions from the model are obtained by querying the web service.
Using a web service to deploy your machine learning model consists of the following primary steps:
- Building the model: An ML model must be created and then wrapped in the web service. However, model building typically requires a different set of resources from the main web service application. It makes sense to separate the model training and web service application environments.
- Building the web application: After the model is trained, it must be persisted so it can be imported into the web application. The web application is the inference logic wrapped using frameworks for developing web services such as Flask, FastAPI, and Django.
- Hosting the web service: For your web service to be consumed around the clock, automated, and scalable, you must host the application. This can be done by using hosting providers. In the third part of this series, you use Google App Engine.
For more information about the first two steps, see Building a Machine Learning Microservice with FastAPI.
Serverless computing
Deploying a machine learning model using serverless computing means you want to serve your model predictions without worrying about how to manage the underlying infrastructure, such as compute resources.
There is still a server. All that’s happened is that you’ve passed the responsibility of managing the server to a cloud provider. You can now focus more on writing better-performing code.
Examples of serverless compute providers include the following:
To deploy a machine learning model using Google Cloud Functions, see part 3 of this series, Machine Learning in Practice: Deploy an ML Model on Google Cloud Provider.
Managed AI cloud
A managed AI cloud does exactly what it says on the tin. You provide a serialized model, and at the expense of less control, the cloud provider completely manages the infrastructure for you. In other words, you can reap the optimization benefits of cloud computing without becoming an expert in everything.
Examples of managed AI cloud providers include the following:
What’s next?
Now that you understand the end-to-end ML workflow and have seen possible ways to deploy an ML model, continue to part 2, Machine Learning in Practice: Build an ML Model, where you train a model on some data.
