机器人智能体要与环境中的物体进行交互,必须了解周围物体的位置和方向。此信息描述了 3D 空间中刚体的六自由度 (DOF) 姿态,详细说明了平移和旋转状态。
准确的姿态估计对于确定如何定位机械臂以特定方式抓取或放置物体至关重要。用例包括用于拾放操作的机器人操作,尤其适用于包装箱、部件装载和食品包装等任务的仓库场景。了解物体的姿态对于机器人对人类的切换也至关重要,在医疗健康、零售和家庭场景中也很有用。
NVIDIA 开发了深度物体姿态估计 (DOPE),用于查找物体的六个 DOF 姿态。在本文中,我们将展示如何生成合成数据来训练物体的 DOPE 模型。
深度物体姿态估计
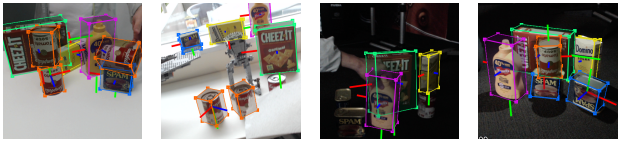
DOPE 是由 NVIDIA 开发的一次性 DNN,可通过 RGB 图像估算六个感兴趣物体的自由度姿态,以实现机器人操作环境中的物体。它仅根据合成数据进行训练,并且需要一个纹理 3D 模型。它为真实的抓取和抓取操作提供足够的准确性,公差为 2 厘米。
DOPE 是一个实例级模型,这意味着 DOPE 模型必须针对类中的每种对象类型进行专门训练。例如,我们无法训练单个 DOPE 模型来检测所有类型的椅子,而是必须为每个椅子类型训练一个模型。
再举一个例子,如果一个应用检测四个不同颜色的几何相似框,则需要四个 DOPE 模型实例进行推理,即在每个彩色框上专门训练一个 DOPE 模型实例。
DOPE 的优势
- 它可以完全基于合成数据进行训练,从而降低数据收集和标注成本。
- 处理物体遮挡。
- 通过结合用于训练的域随机化和逼真合成数据,减少现实差距挑战。
- 它使用 Perspective-n -point (PnP) 算法处理不同的摄像头内部结构,无需重新训练。
- NVIDIA Isaac ROS 支持 DOPE,可提供 GPU 加速的物体姿态估计。
现实差距挑战
仅在合成数据上训练的网络在处理真实数据时通常表现不佳。微调或域随机化等技术有助于提高性能。
域随机化是在模拟环境中更改场景照明、比例、姿态、颜色和物体纹理等参数的方法。这样做的目的是为神经网络提供足够的各种域参数,以改进对真实环境的泛化。这样,真实数据就会显示为网络的另一个变体。
DOPE 通过结合用于训练的域随机化和逼真的合成数据来弥合现实差距,并很好地推广到真实的用例。
架构
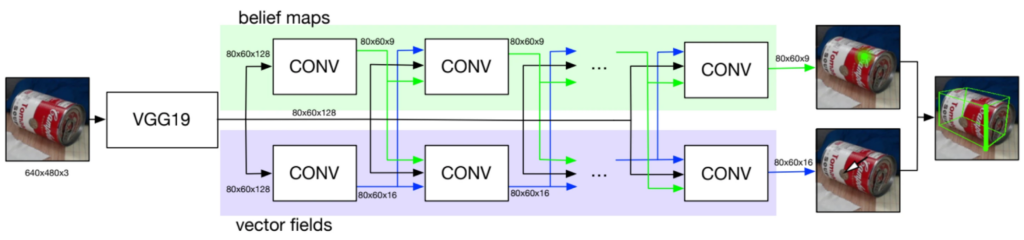
DOPE 是一种单次全卷积神经网络,其设计灵感源自卷积式姿态机(CPM)和多人姿态估计器。该架构由标准 CNN(如 VGG19 或带有额外卷积层的 ResNet)组成。
想要全面了解 DOPE 架构和数据生成管道,请参阅 深度物体姿态估计:用于语义机器人抓取家居物体的方法。
数据集
NVIDIA 提供了基于预训练 DOPE 模型训练的 NVIDIA 家居用品 (HOPE) 数据集,该数据集包含 28 个不同环境中的玩具杂货店对象。它是 6D 物体姿态估计基准测试的一部分,可以在 这里 和 这里 访问。
在实例级别,DOPE 必须使用针对与应用程序相关的感兴趣对象的数据集进行训练。要生成用于训练 DOPE 的数据集,需要对象的 3D 模型。可以使用 BundleSDF 方法,该方法由 NVIDIA 开发,使用单目 RGBD 摄像头,无需使用昂贵的 3D 传感器。
数据生成
可以使用 NVIDIA Isaac Sim 为 DOPE 生成用于域随机化的合成数据。我们专注于两个数据集(MESH 和 Dome),并实施随机化技术,类似于在NViSII 论文中所述。
这些数据集可为目标物体周围的场景添加飞行干扰素,并对光照条件、干扰素的颜色和材质进行随机化处理。Dome 使用的干扰素比 MESH 少,可提供更逼真的背景。

关于如何使用 Isaac Sim 为 DOPE 创建训练数据的信息,请访问 NVIDIA 文档。
您可以指定要针对每种类型(MESH 和 Dome)生成的图像数量。良好的 MESH/Dome 分割取决于用例。尝试找到适合您的模型的启发式算法(例如,MESH/Dome 之间的启发式算法为 25/75)。如果在单个对象上生成数据和训练 DOPE,包含大约 2 万张图像的训练数据集通常就足够了。
生成的数据集包括图像和带注释的 JSON 文件。每个 JSON 文件都包含有关对象的信息,包括相应图像中的对象类、位置、方向和可见性。可见性表示对象的可见程度(在遮挡情况下),并可用于过滤图像以进行训练。
这种使用 Isaac Sim 生成数据的方法,可以类似地创建数据集,例如YCB 视频数据集,这些数据集可以用于训练其他 6D 姿态估计模型。
物体对称
DOPE 在与目标对象绑定的长方体边角上进行训练。此对象中的旋转对称性可能会产生多个帧,这些帧在像素上相同,但有不同的长方体边角标记。
请在 GitHub 上观看视频 Deep Object Pose 视频了解详情。
目前,Isaac Sim 的数据生成方法没有特别处理旋转对称性。然而,NVIDIA 提供了使用 NViSII 合成数据生成脚本来处理对称性的方法。这些脚本可以在 GitHub 上找到。
训练 DOPE
在生成训练数据集后,NVIDIA 将提供用于训练 DOPE 的脚本。您可以将脚本指向训练数据,并指定要训练模型的批量大小和训练次数。
该脚本会保存有用的训练信息(包括损失图和信念图),您可以使用 TensorBoard 查看这些信息。
推理和评估
训练 DOPE 模型后,您可以对测试数据集运行推理。根据测试数据中的图像,您可以在提供的配置文件中指定配置参数,也可以编写自己的参数。
我将感兴趣对象的物理尺寸包含在对象配置文件中。我使用 3D 查看器 加载 3D 模型并查找维度。推理工作流程使用这些维度生成检测到的物体周围的边界框的结果。

运行推理后,我们会提供评估工作流程,以量化方式评估模型的性能。评估时需要真实数据、推理步骤的预测结果以及目标对象的 3D 模型(.obj 格式)。我们会渲染对象的 3D 模型,以计算真实数据和预测结果之间的 3D 误差。
使用 ADD 指标,我们提供两个计算误差的选项:
- 平均距离 (ADD) 是使用预测姿态和真实姿态之间的最近点距离计算得出的平均距离。
- 长方体距离计算使用3D模型的8个立方体点(真值)和预测的立方体点计算平均距离。这种方法比计算ADD的速度更快,但准确度较低。
仅针对任意物体的域随机化数据,在 30 万张图像中,观察到的曲线下最大区域 (AUC) 为 66.64.仅使用包含 60 万张照片级逼真图像的数据集时,观察到的 AUC 为 62.94.结合使用域随机化和照片级逼真的合成图像时,准确度最高 (77.00 AUC)。
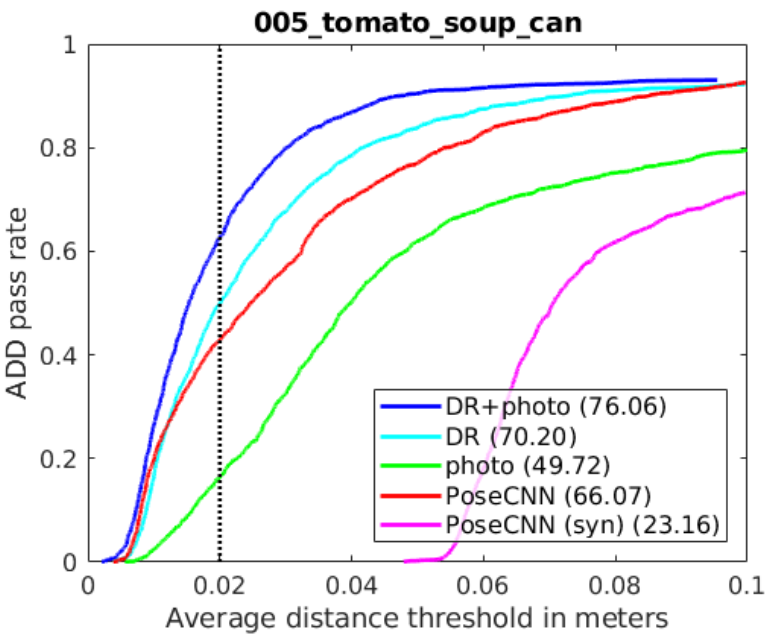
DOPE 仅使用合成图像进行训练。然而,即使在出现遮挡和极端光照变化的情况下,它在使用其他摄像头拍摄的场景中仍然表现出色。其性能优于 PoseCNN 和 BB8,后者使用真实数据或合成数据与真实数据的组合进行训练。
为进行直接比较,从 YCB 数据集中选择了 5 个物体,而 DOPE 在 5 个物体中的 4 个中实现了高于 PoseCNN 的 AUC.
如需了解更多详情,请参阅DOPE 论文。请访问我们的 GitHub,了解更多信息关于推理和评估。
使用 Isaac ROS 姿态估计
Isaac ROS 提供了一个 ROS 2 包,用于使用 DOPE 进行姿态估计。它使用 NVIDIA Triton 或 NVIDIA TensorRT 与 Isaac ROS DNN 推理。
在训练 DOPE 模型后,您可以在 Omniverse 上使用此软件包运行推理,适用于NVIDIA Jetson或配备 NVIDIA GPU 的系统。
您还可以对来自摄像头流的实时图像执行推理,但这是一个计算密集型任务。姿态估计的帧率低于摄像头输入率。我们的 DOPE 图形在 NVIDIA Jetson AGX Orin 上以 39.8 FPS 运行,在 NVIDIA RTX 4060 Ti 上以 89.2 FPS 运行,基于 Isaac ROS 基准测试 工作流程。
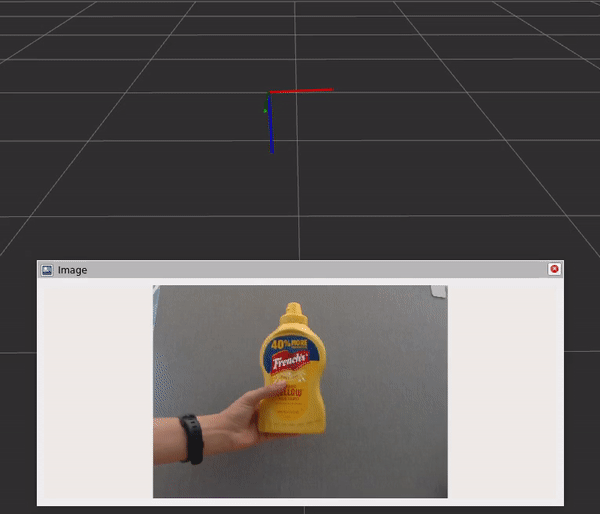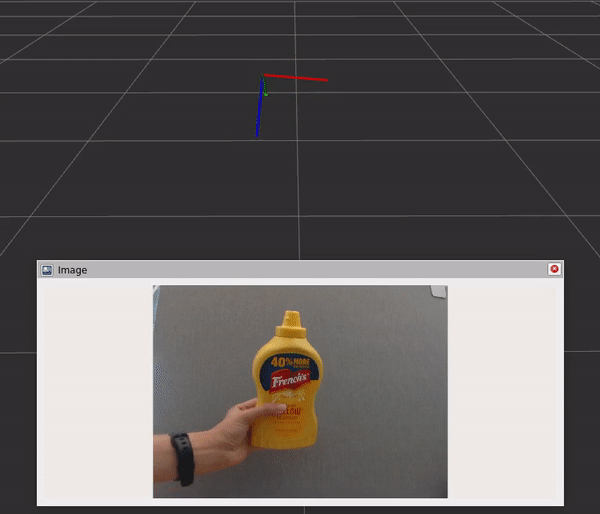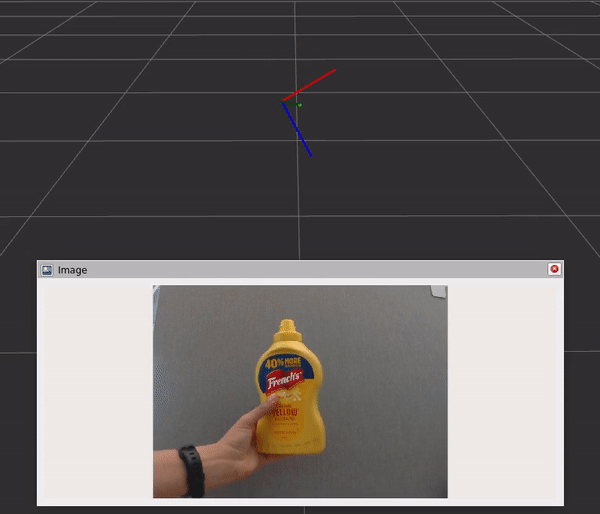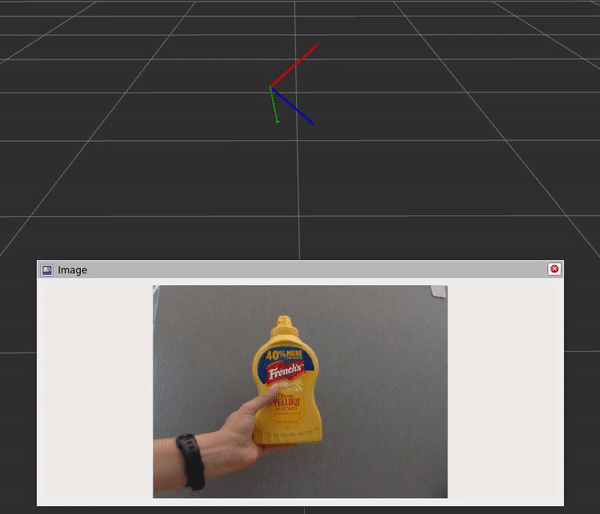
该图包含三个组件和步骤:
- DNN 图像编码器节点将原始图像转换为标准化张量。
- TensorRT 节点将输入张量转换为信念图张量。
- DOPE 解码器节点将信念贴图转换为一系列姿势。
要深入了解不同 Isaac ROS 软件包的性能和基准测试方法,请查阅性能概要。此外,您还可以在 GitHub 上查看 Isaac ROS 姿态估计的发布信息:https://github.com/NVIDIA-ISAAC-ROS/isaac_ros_pose_estimation。