这篇文章是关于优化端到端人工智能.
虽然 NVIDIA 硬件可以以难以置信的速度处理构成神经网络的单个操作,但确保您正确使用这些工具是很重要的。在 ONNX 中使用 ONNX Runtime 或 TensorRT 等开箱即用的工具通常会给您带来良好的性能,但既然您可以拥有出色的性能,为什么还要满足于良好的性能呢?
在这篇文章中,我讨论了一个常见的场景,即带有 DirectML 后端的 ONNX Runtime 。这是构建 WinML 的两个主要组件。当在 WinML 之外使用时,它们可以在支持运算符集以及支持 DML 以外的后端(如 TensorRT )方面提供极大的灵活性。
为了获得 ONNX Runtime 和 DML 的出色性能,通常值得超越基本实现。从使用 ONNX Runtime 时的常见场景开始。
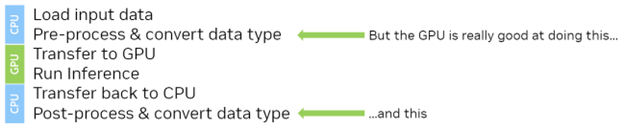
- 一些图像数据是从磁盘加载的。
- int8 图像数据以某种方式进行预处理,例如缩放并转换为 float16 。
- 图像数据被加载到 GPU 上。
- 对图像数据进行推理。
- 将结果加载回 CPU 。
- 结果经过后处理,或者可能发送到另一个模型。
这里有几个问题。如果从头开始使用 ONNX Runtime ,则提供指向系统( CPU )内存中数据的指针。当您通过调用Ort::Session::Run(...)以及当推理完成时将数据传输回系统( CPU )存储器。
虽然从实现的角度来看,这听起来很方便,但您可能在推理之前有一个预处理阶段,在推理之后有一个后处理阶段。使用当前的工作流程,您必须对 CPU 上的数据进行预处理和后处理,或者在 ONNX Runtime 第二次将所有数据传输回 GPU 进行推理之前,往返于 GPU ‘。
一个更好的方法是将原始数据加载到 GPU ,无论是完整加载还是分块加载,先对 GPU ‘执行预处理步骤(稍后将对此进行详细介绍),然后将其保留在 GPU 上,以便进行推理。通过这种方式,您已经利用 GPU 的大规模并行能力来执行预处理步骤,并减少了初始传输的大小,因为您现在正在传输 int8 数据,而不是 float16 数据。
理论上这一切都很好,但如何使用 ONNX Runtime 和 DirectML 将其付诸实践?为此,您必须深入研究 DirectX 12 , DirectML 就是基于它构建的。
有关我在本文中讨论的实现的更多信息,请参阅code example以及评论。
DirectX12
与 OpenGL 和 CUDA 相比, DirectX 12 可能有些冗长。对于渲染图形,可能有很多管道状态需要管理。您只需要使用计算管道,这要简单得多。无论如何, DirectX 12 与其他任何 API 或 SDK 一样,都有学习曲线,但既不陡峭也不冗长。
DirectX12 通过公开较低级别的构造来实现对 GPU 的快速且高度可配置的访问,您可以使用这些构造来控制在 GPU ‘上安排工作的时间和方式。带 DML 的 ONNX Runtime 已经使用了它,但您希望访问 ONNX 和 DML 正在使用的相同资源,以便使用它们执行预处理和传输。
DirectX 12 公开了名为命令队列。您可以将命令记录到 CPU 上的这些队列中,并将它们发送到要调度的 GPU 。这些命令可以多次运行,而无需重新记录。通过创建多个队列,您可以在 GPU 上并行执行多个作业。通常情况下,单个推理可能不会使 GPU 上的处理器饱和,并且您可能能够同时做多件事。稍后将对此进行详细介绍。
以下是 DirectX 12 工作流的高级视图:
- 获取图形卡(适配器)的参考。
- 创建对图形设备的逻辑引用。您可以使用它来分配内存和发出命令。
- 从设备中获取对命令队列的引用。
- 编写用于预处理的计算着色器,这比您想象的要简单。
- 创建计算管道状态对象。
- 在设备上分配一些内存用于输入和输出。您可以随时在该内存之间进行传输。
- 将命令添加到命令队列中。
- 执行队列。
您创建的队列与 ONNX Runtime 提供给 DirectML 的队列相同。您可以构建新的高性能功能,作为 ONNX Runtime 已经提供的功能的扩展。
您将要学习的内容适用于 ONNX 和 DirectML ,以及许多其他计算任务。
获取图形卡的参考
根据您的系统类型,您可能有一个图形卡、多个图形卡,或者根本没有图形卡。
要做的第一件事是查询系统,以发现您可以玩什么。这使您能够通过 Direct X Graphics interface ( DXGI )获取与实际物理设备的接口。通过此物理设备接口,您可以创建对逻辑设备使您可以访问 DirectX 运行所需的设备内存和命令队列。
有几种类型的命令队列可用于不同的任务,例如渲染、复制和计算工作。可以并行执行一些任务,例如复制和计算工作。有关详细信息,请参阅代码示例.
设置 ONNX 运行时

要在此项目中将 ONNX Runtime 与 DirectML 一起使用,请首先设置对逻辑设备的引用。然后,使用逻辑 DirectX12 设备创建对 DML 设备的引用。您还可以创建一个队列供 DML 使用。然后,当您为 DML 执行提供程序创建会话选项结构时,您可以使用扩展表单,使用先前创建的 DirectX12 构造来创建 ORT 会话。
Ort::SessionOptions opts;
OrtSessionOptionsAppendExecutionProviderEx_DML(
opts, m_dml_device.Get(),
m_copy_queue->GetD3D12CmdQueue().Get())
现在,您可以使用SessionOptions对象
创建会话后,您现在可以开始初始化资源,将输入数据传递给模型,并从模型接收输出数据。要做到这一点,您可以在模型中查询它所期望的张量形状和格式。
内存和内存传输
如果从基本实现中使用 ONNX Runtime ,则输入和输出数据将在 CPU 内存中启动, ONNX Run 将管理与 GPU 之间的传输。在简单的情况下,例如当对图像的整体进行推理时,这可能是可以的。
然而,在实践中,大多数大图像都被分解成瓦片,可能有一些重叠并按顺序处理。在这种情况下,通过自己管理转移可以获得相当大的性能提升。
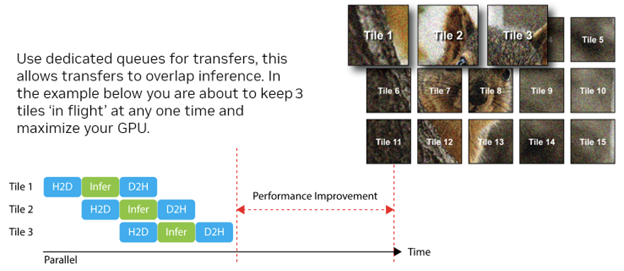
- 您可以控制何时进行转账。
- 您可以与其他计算工作并行执行传输。
DirectX 12 的存储器接口是灵活的,可以以各种方式使用以执行传输。在执行数据传输方面,为您提供最大粒度的方法是自己暂存内存。

- 为暂存内存创建专用队列:
- 类型: D3D12 _ COMMAND _ LIST _ type _ COPY
- 创建两个 ID3D12Resource 对象:
- D3D12 _ HEAP _ TYPE _ UPLOAD :从主机可见。
- D3D12 _ HEAP _ TYPE _ DEFAULT : GPU 的本地。
- 使用已提交或已放置的资源:
- 提交的资源: DX12 为您创建和管理堆。
- 放置的资源:您提供堆。用于子分配。
- 创建一个命令列表并发送一个复制命令。这将执行从主机到设备的复制。
在 GPU 上获得数据后,创建一个引用它的视图对象和一个绑定到此内存的 Ort-Value 对象。然而,您并没有将原始传输的数据按原样输入到模型中,因为还有一个更重要的步骤需要执行。
更快的预处理
现在,您可以控制数据何时以及如何传输到 GPU 。现在,您还可以了解如何将预处理和后处理移动到 GPU 。
在大多数计算机视觉应用程序中,以整数格式(如 RGB8 )提供一些输入,并将其转换为缩放和偏置的浮点表示是很常见的。
如果您使用开箱即用的 ONNX Runtime 和 DML ,则很难在 GPU 上执行此操作,因为数据在 CPU 上开始和结束其行程。现在,您可以自己执行这些传输,从而可以控制内存的生命周期。您还可以将此预处理和后处理转移到自定义计算过程中,并将其作为端到端推理管道的一部分运行。
您必须做的是在转移到 GPU 之后但在运行推理之前插入一个计算步骤。本例中的计算步骤获取传输到 GPU 的 RGB8 整数数据,并将其传递给执行缩放和偏移的计算内核(着色器)。在这样做的同时,它还将数据转换为模型所需精度的浮点值。为了获得最佳性能这里应该使用 FP16.
必须对数据执行的所有操作都是就地操作,因为输入中的每个像素都对其执行了相同的操作,并且不依赖于其任何邻居。这种类型的工作很容易并行执行,因此它是利用 GPU 的力量的绝佳候选者。
要使用 DirectX 12 运行计算着色器,请创建所谓的管道状态对象。对于图形渲染来说,这可能是一个相当复杂的过程,但对于计算处理来说,它要简单得多。
管道状态对象本质上预编译在 GPU 上执行某些工作所需的所有状态,包括运行的着色器字节码和要使用的资源的绑定。
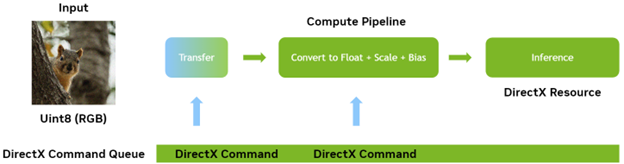
首先创建一个名为根签名,这与函数签名类似,因为它描述了管道的属性和输出。然后,您可以使用这个根签名来创建管道状态对象本身,为输入和输出提供实际的缓冲区绑定。
创建管道后,创建一个命令缓冲区并记录运行计算着色器所需的命令。有关详细信息,请参阅代码示例.
同步和利用更多并行性
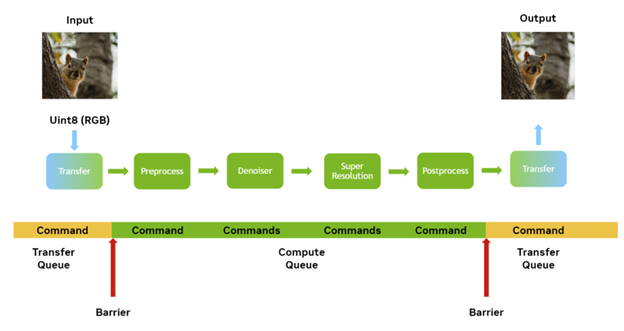
NVIDIA 硬件可以并行执行一些不同的任务,在执行任何计算工作的同时,显著地执行与 GPU 的并行传输。当 DML 模型在 GPU 上执行时,它是计算工作。
我建议您设置端到端管道,以便一批推理工作(例如瓦片)可以执行推理,而下一批推理任务则转移到 GPU ,以便它可以下一步运行。事实上,如果 GPU 上有足够的可用资源,甚至可以并行运行多个瓦片的实际计算或推理部分。
为了在处理中发生这些重叠,计算或传输工作必须在它们自己的队列中执行,其中一些队列可以相互并行运行。这就提出了同步。如果在某些数据的一个队列中运行传输,而在另一个队列上运行推理,则必须确保在必须运行任何计算或推理步骤时数据已完成传输。
同步可以通过多种方式从 CPU 侧和 GPU 侧执行,但您希望 CPU ‘尽可能少地进行交互。使用资源壁垒这导致队列等待,直到满足由屏障设置的条件为止。您使用两个障碍:
资源转换障碍
请记住,您正在将数据从主机传输到设备。传输数据时,目标缓冲区处于可以从 CPU 向其传输数据的状态。当绑定到管道时,这可能不是它所处的最佳状态,因此必须提供转换。
这一要求取决于硬件平台,但需要转换才能使 DirectX12 的使用有效。
UAV 屏障
这种类型的屏障只是阻塞队列,直到所有数据都完成传输。通过以这种方式使用屏障,您可以让 GPU 等待,而 CPU 根本不会参与并提高性能。
CD3DX12_RESOURCE_BARRIER barrier2 = CD3DX12_RESOURCE_BARRIER::UAV(
m_ort_input_buffer->GetD3DResource().Get()
);
创建两个屏障后,一步将它们添加到命令列表中。
CD3DX12_RESOURCE_BARRIER barriers[2] = {barrier1, barrier2};
m_cmd_list_stage_input->ResourceBarrier(2, barriers);
你现在可以把所有的部分放在一起了。您已经看到,您不仅可以创建和管理可用于调度传输和计算工作的资源,还可以创建并管理这些资源的调度时间。
现在您只需要两个队列:
- 传输队列:用于调度传输命令。
- 计算队列:用于调度预处理和后处理命令以及实际 ONNX 运行时会话本身。
您还需要为每个记录命令的命令列表。
传输和计算之间必须有一些同步,以确保在传输数据的工作开始之前传输已经完成。这里有一个优化的机会。
NVIDIA 硬件完全是并行的,它可以同时执行传输和计算等操作。当您处理单个作业时,几乎没有机会将转移与计算重叠,因为您必须等待转移完成后才能开始计算。
通常,在图像处理作业的情况下,您会将作业拆分为瓦片。对于大型图像,很可能没有足够的设备内存来在一次运行中执行工作。通过将每个瓦片视为要执行的一系列任务来使用这种并行性。然后,您可以在任何时候“飞行”几个瓦片,每个关键阶段之间都有一个同步点:
- 第一个磁贴:将数据复制回 CPU 内存。
- 第二个磁贴:运行推理和计算工作。
- 第三个瓦片:正在将数据复制到 GPU 内存。
这三项任务都可以并行进行。甚至可能存在这样的情况,即如果没有使 GPU 饱和,则可以在一定程度的重叠的情况下进行一个以上的计算工作。
结论
我在这篇文章中涵盖了很多内容。要想实际理解这些方法的机制,唯一的方法就是动手。我鼓励你们花时间试验example code,使用从导出的 ONNX NVIDIA DL Designer.
有关执行过程中发生的事情的更多信息,请参阅代码注释。