
智能城市代表了城市生活的未来。然而,它们可能会给城市规划者带来各种挑战,尤其是在交通领域。为了取得成功,城市的各个方面——从环境和基础设施到商业和教育——必须在功能上进行整合。
这可能很困难,因为单独管理交通流量是一个复杂的问题,充满了拥堵、事故应急响应和排放等挑战。
为了应对这些挑战,开发人员正在开发具有现场可编程性和灵活性的人工智能软件。这些软件定义的物联网解决方案可以应用于实时环境,如交通管理,车牌识别,智能停车和事故检测等。
尽管如此,建立有效的人工智能模型说起来容易做起来难。遗漏值、重复示例、错误标签和错误特征值是训练数据的常见问题,这些问题可能导致模型不准确。在自动驾驶汽车的情况下,不准确的结果可能是危险的,也可能导致交通系统效率低下或城市规划不佳。
实时城市交通的数字孪生
端到端人工智能工程公司 SmartCow,作为 NVIDIA Metropolis 的合作伙伴,已在 数字孪生技术上创建了交通场景,这些场景在 NVIDIA Omniverse 中进行模拟。这些数字孪生技术可以用于设置并验证 AI 模型的性能,使用的是 合成数据。
该团队正在使用 NVIDIA Omniverse Replicator。
所有 Omniverse 扩展的基础是被称为 OpenUSD 的 Universal Scene Description (USD)。USD 是一个功能强大的交换平台,具有高度可扩展的属性,虚拟世界就是在其上构建的。智能城市的数字孪生依赖于 USD 的高度可扩展和可互操作的功能,用于精确模拟真实世界的大型高保真场景。
Omniverse Replicator 是 Omniverse 平台的核心扩展,使开发人员能够以编程方式生成带注释的合成数据,以引导人工智能模型感知的训练。当真实数据集有限或难以获得时,合成数据尤其有用。
通过使用数字孪生, SmartCow 团队生成了准确表示真实世界交通场景和违规行为的合成数据。这些合成数据集有助于验证人工智能模型并优化人工智能训练管道。
建设车牌检测分机
智能交通管理系统面临的最重大挑战之一是车牌识别。开发一个适用于具有不同规则、法规和环境的各种国家和市镇的模型需要多样化和稳健的培训数据。为了为模型提供足够和多样化的训练数据, SmartCow 在 Omniverse 中开发了一个扩展,以生成合成数据。
Omniverse 中的扩展是可重复使用的组件或工具,它们提供强大的功能以增强管道和工作流。在Omniverse Kit中构建扩展后,开发人员可以轻松地将其分发给客户,以便在Omniverse USD Composer,Omniverse USD Presenter和其他应用程序中使用。
SmartCow 的扩展名为车牌合成生成器( LP-SDG ),使用环境随机化器和物理随机化器使合成数据集更加多样化和逼真。
环境随机化器模拟数字孪生环境中的照明、天气和其他因素的变化,如雨、雪、雾或灰尘。物理随机发生器模拟可能影响模型识别车牌号码能力的划痕、污垢、凹痕和变色。
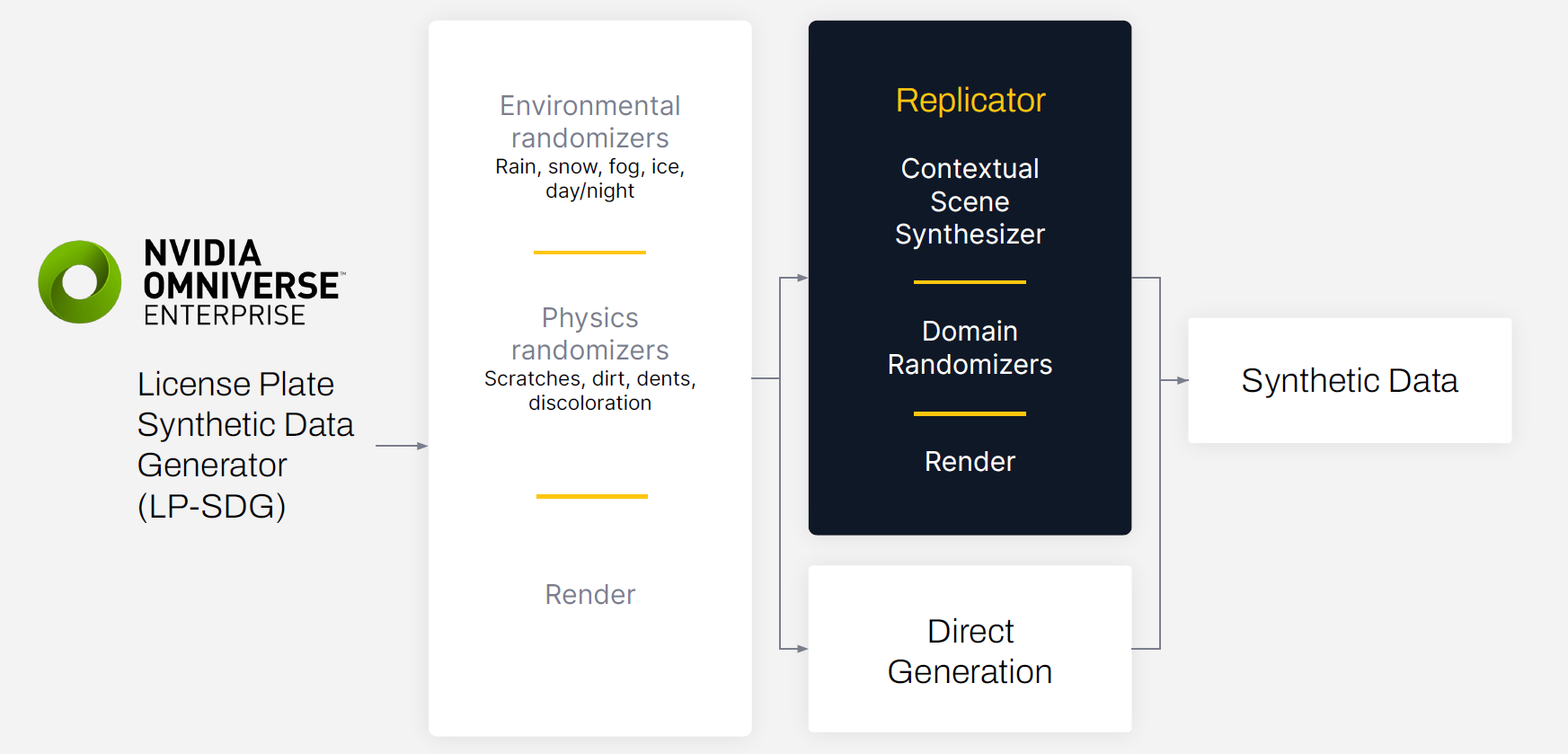
使用 NVIDIA Omniverse Replicator 生成合成数据
数据生成过程从 Omniverse 中创建 3D 环境开始。 Omniverse 中的数字孪生可以用于许多模拟场景,包括生成合成数据。最初的 3D 场景是由 SmartCow 的内部技术艺术家构建的,确保了数字孪生的匹配现实尽可能好。

在生成场景后,我们使用域随机化来改变光源、纹理、摄像机位置和材质。这整个过程都是通过使用内置的Omniverse Replicator APIs来完成的。
生成的数据导出时带有边界框注释和训练所需的其他输出变量。
模型培训
最初的模型是在 3000 张真实图像上训练的。目标是了解基准模型性能,并验证正确的边界框尺寸和光线变化等方面。
接下来,该团队进行了实验,在 3000 个样本、 30000 个样本和 300000 个样本的合成数据集上比较基准。

SmartCow 的软件工程师 Natalia Mallia 说:“通过 Omniverse 获得的真实感,在合成数据上训练的模型偶尔会优于在真实数据上训练。”。“使用合成数据实际上消除了真实图像训练数据集中自然存在的偏见。”
为了提供准确的基准测试和比较,该团队在对三种大小的合成数据集进行训练时,将数据随机分配到一致的参数中,如一天中的时间、划痕和视角。为了保持相对准确性,真实世界的数据没有与用于训练的合成数据混合。每个模型都是根据大约 1000 幅真实图像的数据集进行验证的。
SmartCow 的团队将 Omniverse LP-SDG 扩展的训练数据与 NVIDIA TAO,一个低代码的人工智能模型训练工具包,结合使用,并利用迁移学习的力量对模型进行微调。
该团队使用了 NGC 目录,并利用 TAO 对 NVIDIA DGX A100 系统进行了微调。
NVIDIA 的模型部署〔 DeepStream 〕
然后,人工智能模型将被部署到自定义边缘设备上,使用 NVIDIA DeepStream SDK。
然后,他们实现了一个连续学习循环,包括从边缘设备收集漂移数据,将数据反馈到 Omniverse Replicator ,并合成可重新训练的数据集,这些数据集通过自动标记工具传递并反馈到 TAO 进行训练。
这种闭环管道有助于创建准确有效的人工智能模型,用于自动检测每条车道上的交通方向以及任何停滞异常时间的车辆。
开始使用合成数据、数字孪生和人工智能智慧城市交通管理
生成合成数据集和验证人工智能模型性能的数字双工作流是在智能城市中为交通构建更有效的人工智能模型的重要一步。使用合成数据集有助于克服有限数据集的挑战,并提供准确有效的人工智能模型,从而实现高效的交通系统和更好的城市规划。
如果您希望直接采用此解决方案,请查看SmartCow RoadMaster和SmartCow PlateReader的解决方案。
如果您是一名对构建自己的合成数据生成解决方案感兴趣的开发人员,可以免费下载 NVIDIA Omniverse 并尝试 Omniverse Code 中的 Replicator API。欢迎加入NVIDIA 开发者论坛的讨论。
参加NVIDIA at SIGGRAPH 2023,了解图形、Open USD 和 AI 的最新进展。记得保存会议日期,并查看“利用通用场景描述加速自动驾驶汽车和机器人的开发”的演讲。
下载标准许可证,开始使用NVIDIA Omniverse,或学习如何Omniverse 企业可以连接您的团队。如果你是一名开发人员,开始使用 Omniverse 资源。通过订阅新闻稿、 Twitch ,以及YouTube通道。




