近年来,随着大语言模型 (LLMs)例如 GPT-3、Megatron-Turing、Chinchilla、PaLM-2、Falcon 和 Lama 2 在自然语言生成方面取得了显著进展。然而,尽管这些 LLM 能够生成类似人类的文本,但它们可能无法提供符合用户偏好的有用且细致入微的响应。
当前改进大语言模型 (LLM) 的方法包括监督精调 (SFT),然后是从人类反馈中进行强化学习 (RLHF)。虽然 RLHF 可以提高性能,但它有一些局限性,包括训练复杂性和缺乏用户控制。
NVIDIA 研究团队为了克服这些挑战,开发并发布了 SteerLM,这是一种新的四步技术,可以简化 LLM 的自定义,并根据您指定的属性动态转向模型输出,作为 NVIDIA NeMo 的一部分。本文将深入探讨 SteerLM 的工作原理,为什么它标志着一个显著的进步,以及如何训练 SteerLM 模型。
语言模型带来前景和潜在陷阱
通过对海量文本语料库进行预训练,LLM 可以获得广泛的语言能力和世界知识。研究人员已经成功地将 大语言模型应用于多种自然语言处理 (NLP) 任务,例如翻译、问答和文本生成。但是,这些模型通常无法遵循用户提供的指示,而是会生成通用、重复或无意义的文本。获取人工反馈对于自定义 LLM 至关重要。
现有方法带来的机遇
SFT 增强了模型功能,但导致响应变得简短而机械。RLHF 通过优先考虑人类偏好的响应而不是替代方案来进一步优化模型。但是,RLHF 需要极其复杂的训练基础设施,阻碍了广泛采用。
隆重推出 SteerLM
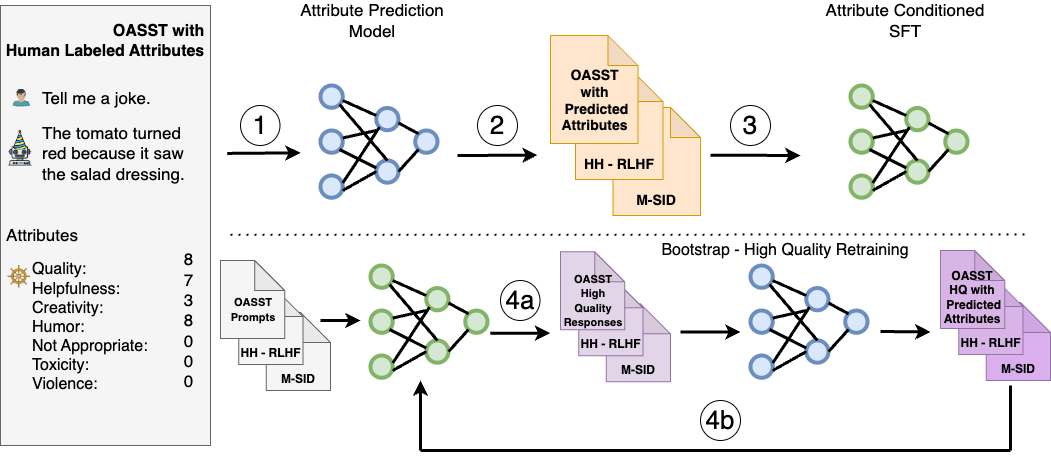
SteerLM 利用监督式微调方法,使您能够在推理期间控制响应。它克服了先前比对技术的限制,包含四个关键步骤:
- 在人工标注的数据集上训练属性预测模型,以评估有用性、幽默性和创造力等任意数量属性的响应质量。
- 使用第 1 步中的模型来丰富模型可用数据的多样性,通过预测不同数据集的属性分数来对其进行标注。
- 通过训练 LLM 以根据指定的属性组合(例如用户感知的质量和有用性)生成响应,执行属性条件 SFT.
- 通过模型采样通过生成以最大质量为条件的不同响应来引导训练(图 1,4a),然后对其进行微调以进一步改进对齐方式(图 1,4b)。
与 RLHF 相比,SteerLM 仅依赖于标准语言建模目标,简化了对齐。它支持您在推理时调整属性,从而支持用户可操控的 AI.这使得开发者能够定义与应用程序相关的首选项,这与需要使用预定义偏好的其他技术不同。
借助用户指导解锁可定制的 AI
SteerLM 的一项关键创新是,用户可以在查询模型时在推理时指定所需的属性(例如幽默水平和耐毒性)。您可以从使用 SteerLM 运行一个自定义,转向在推理时提供多个用例。
SteerLM 支持一系列应用,包括:
- 游戏:适用于游戏场景的各种非玩家角色对话。如需了解详情,请参阅NVIDIA ACE 通过 NeMo SteerLM 为 AI 驱动的 NPC 添加情感。
- 教育:为学生保留正式且有用的角色。
- 企业:通过个性化功能为组织中的多个团队提供服务。
- 可访问性:通过控制敏感属性,可以抑制不希望出现的模型偏差。
这种灵活性有望解锁针对个人需求量身打造的新一代定制 AI 系统。
通过简化的训练普及先进的定制技术
与其他高级自定义技术所需的专用基础设施相比,SteerLM 的简单训练方案使开发者更容易获得先进的自定义功能。其性能清楚地表明,增强学习等技术对于稳健的指令调整是不需要的。
利用 SFT 等标准技术可简化复杂性,尽可能减少对基础设施和代码的更改。通过有限的超参数优化,可以实现合理的结果。
总体而言,这带来了一种简单实用的方法来获得高度准确的定制 LLM.在我们的实验中,SteerLM 43B 在 Vicuna 基准测试中实现了先进的性能,优于现有的 RLHF 模型(如 LLaMA 30B RLHF)。具体来说,SteerLM 43B 在 Vicuna 自动评估中的平均分为 655.75,而 Guanaco 65B 和 LLaMA 30B RLHF 的平均分分别为 646.25 和 612.75.
这些结果突出表明,SteerLM 的简单训练过程可以实现与更复杂的 RLHF 技术同等准确的定制 LLM.通过简化训练,SteerLM 使开发者更容易实现如此高的准确性,从而更容易实现自定义的大众化。
如需了解更多详情,请参阅我们的论文 SteerLM: Attribute Conditioned SFT as an (User-Steerable) Alternative to RLHF。您还可以了解如何使用 SteerLM 方法自定义 Llama 2 13B model。
如何训练 SteerLM 模型
本节是一个分步教程,将指导您如何使用 2B NeMo LLM 模型在 OASST 数据上运行完整的 SteerLM 工作流。它包括以下内容:
- 数据清理和预处理
- 训练属性预测(值模型)
- 训练属性条件 SFT (SteerLM 模型)
- 对具有不同属性值的 SteerLM 模型进行推理
第 1 步:安装要求
首先安装必要的 Python 库:
pip install fire langchain==0.0.133
第 2 步:下载并设置数据子集
本教程使用 OASST 数据集的一小部分。OASST 包含具有 13 种不同质量属性的人工标注的开放领域对话。
首先下载并对其进行子集:
mkdir -p data cd data wget https://huggingface.co/datasets/OpenAssistant/oasst1/resolve/main/2023-04-12_oasst_all.trees.jsonl.gz gunzip -f 2023-04-12_oasst_all.trees.jsonl.gz mv 2023-04-12_oasst_all.trees.jsonl data.jsonl head -5000 data.jsonl > subset_data.jsonl cd -
第 3 步:下载 Lama 2 LLM 模型和分词器并转换
下载 Llama 2 7B LLM model 和 tokenizer。
然后将 Lama 2 LLM 转换为 .nemo 格式:
python NeMo/scripts/nlp_language_modeling/convert_hf_llama_to_nemo.py --in-file /path/to/llama --out-file /output_path/llama7b.nemo
解压缩 .nemo 文件以获取 NeMo 格式的分词器:
tar <path-to-model>/llama7b.nemo mv ba4632640484461f8ae9d61f6dfe0d0b_tokenizer.model tokenizer.model
提取时,分词器的前缀会有所不同。请确保在运行上述命令时使用正确的分词器文件。
第 4 步:预处理 OASST 数据
使用 NeMo 预处理脚本,然后创建单独的文本到值和值到文本版本:
python scripts/nlp_language_modeling/sft/preprocessing.py \
--input_file=data/subset_data.jsonl \
--output_file_prefix=data/subset_data_output \
--mask_role=User \
--type=TEXT_TO_VALUE \
--split_ratio=0.95 \
--seed=10
python scripts/nlp_language_modeling/sft/preprocessing.py \
--input_file=data/subset_data.jsonl \
--output_file_prefix=data/subset_data_output_v2t \
--mask_role=User \
--type=VALUE_TO_TEXT \
--split_ratio=0.95 \
--seed=10
第 5 步:清理文本转值数据
如果由于按序列长度截断而屏蔽了所有标记,则运行以下脚本将删除这些记录。
python scripts/nlp_language_modeling/sft/data_clean.py \
--dataset_file=data/subset_data_output_train.jsonl \
--output_file=data/subset_data_output_train_clean.jsonl \
--library sentencepiece \
--model_file tokenizer.model \
--seq_len 4096
python scripts/nlp_language_modeling/sft/data_clean.py \
--dataset_file=data/subset_data_output_val.jsonl \
--output_file=data/subset_data_output_val_clean.jsonl \
--library sentencepiece \
--model_file tokenizer.model \
--seq_len 4096
第 6 步:使用经过清理的 OASST 数据训练值模型
在本教程中,针对 1K 步长训练值模型。请注意,我们建议对更多数据进行更长时间的训练,以获得良好的值模型。
python examples/nlp/language_modeling/tuning/megatron_gpt_sft.py \
++trainer.limit_val_batches=10 \
trainer.num_nodes=1 \
trainer.devices=2 \
trainer.max_epochs=null \
trainer.max_steps=1000 \
trainer.val_check_interval=100 \
trainer.precision=bf16 \
model.megatron_amp_O2=False \
model.restore_from_path=/model/llama7b.nemo \
model.tensor_model_parallel_size=2 \
model.pipeline_model_parallel_size=1 \
model.optim.lr=5e-6 \
model.optim.name=distributed_fused_adam \
model.optim.weight_decay=0.01 \
model.answer_only_loss=True \
model.activations_checkpoint_granularity=selective \
model.activations_checkpoint_method=uniform \
model.data.chat=True \
model.data.train_ds.max_seq_length=4096 \
model.data.train_ds.micro_batch_size=1 \
model.data.train_ds.global_batch_size=1 \
model.data.train_ds.file_names=[data/subset_data_output_train_clean.jsonl] \
model.data.train_ds.concat_sampling_probabilities=[1.0] \
model.data.train_ds.num_workers=0 \
model.data.train_ds.hf_dataset=True \
model.data.train_ds.prompt_template='\{input\}\{output\}' \
model.data.train_ds.add_eos=False \
model.data.validation_ds.max_seq_length=4096 \
model.data.validation_ds.file_names=[data/subset_data_output_val_clean.jsonl] \
model.data.validation_ds.names=["oasst"] \
model.data.validation_ds.micro_batch_size=1 \
model.data.validation_ds.global_batch_size=1 \
model.data.validation_ds.num_workers=0 \
model.data.validation_ds.metric.name=loss \
model.data.validation_ds.index_mapping_dir=/indexmap_dir \
model.data.validation_ds.hf_dataset=True \
model.data.validation_ds.prompt_template='\{input\}\{output\}' \
model.data.validation_ds.add_eos=False \
model.data.test_ds.max_seq_length=4096 \
model.data.test_ds.file_names=[data/subset_data_output_val_clean.jsonl] \
model.data.test_ds.names=["oasst"] \
model.data.test_ds.micro_batch_size=1 \
model.data.test_ds.global_batch_size=1 \
model.data.test_ds.num_workers=0 \
model.data.test_ds.metric.name=loss \
model.data.test_ds.hf_dataset=True \
model.data.test_ds.prompt_template='\{input\}\{output\}' \
model.data.test_ds.add_eos=False \
exp_manager.explicit_log_dir="/home/value_model/" \
exp_manager.create_checkpoint_callback=True \
exp_manager.checkpoint_callback_params.monitor=val_loss \
exp_manager.checkpoint_callback_params.mode=min
第 7 步:生成标注
要生成标注,请在后台运行以下命令以运行推理服务器:
python examples/nlp/language_modeling/megatron_gpt_eval.py \
gpt_model_file=/models/<TRAINED_ATTR_PREDICTION_MODEL.nemo> \
pipeline_model_parallel_split_rank=0 \
server=True \
tensor_model_parallel_size=1 \
pipeline_model_parallel_size=1 \
trainer.precision=bf16 \
trainer.devices=1 \
trainer.num_nodes=1 \
web_server=False \
port=1424
现在执行:
python scripts/nlp_language_modeling/sft/attribute_annotate.py --batch_size=1 --host=localhost --input_file_name=data/subset_data_output_v2t_train.jsonl --output_file_name=data/subset_data_v2t_train_value_output.jsonl --port_num=1424 python scripts/nlp_language_modeling/sft/attribute_annotate.py --batch_size=1 --host=localhost --input_file_name=data/subset_data_output_v2t_val.jsonl --output_file_name=data/subset_data_v2t_val_value_output.jsonl --port_num=1424
第 8 步:清理从值到文本的数据
如果在按序列长度截断后对所有标记进行了遮罩,则删除记录:
python scripts/data_clean.py \
--dataset_file=data/subset_data_v2t_train_value_output.jsonl \
--output_file=data/subset_data_v2t_train_value_output_clean.jsonl \
--library sentencepiece \
--model_file tokenizer.model \
--seq_len 4096
python scripts/data_clean.py \
--dataset_file=data/subset_data_v2t_val_value_output.jsonl \
--output_file=data/subset_data_v2t_val_value_output_clean.jsonl \
--library sentencepiece \
--model_file tokenizer.model \
--seq_len 4096
第 9 步:训练 SteerLM 模型
出于本教程的目的,SteerLM 模型经过 1K 步长的训练。请注意,我们建议使用更多数据进行更长时间的训练,以获得经过良好调优的模型。
python examples/nlp/language_modeling/tuning/megatron_gpt_sft.py \
++trainer.limit_val_batches=10 \
trainer.num_nodes=1 \
trainer.devices=2 \
trainer.max_epochs=null \
trainer.max_steps=1000 \
trainer.val_check_interval=100 \
trainer.precision=bf16 \
model.megatron_amp_O2=False \
model.restore_from_path=/model/llama7b.nemo \
model.tensor_model_parallel_size=2 \
model.pipeline_model_parallel_size=1 \
model.optim.lr=5e-6 \
model.optim.name=distributed_fused_adam \
model.optim.weight_decay=0.01 \
model.answer_only_loss=True \
model.activations_checkpoint_granularity=selective \
model.activations_checkpoint_method=uniform \
model.data.chat=True \
model.data.train_ds.max_seq_length=4096 \
model.data.train_ds.micro_batch_size=1 \
model.data.train_ds.global_batch_size=1 \
model.data.train_ds.file_names=[data/subset_data_v2t_train_value_output_clean.jsonl] \
model.data.train_ds.concat_sampling_probabilities=[1.0] \
model.data.train_ds.num_workers=0 \
model.data.train_ds.prompt_template='\{input\}\{output\}' \
model.data.train_ds.add_eos=False \
model.data.validation_ds.max_seq_length=4096 \
model.data.validation_ds.file_names=[data/subset_data_v2t_val_value_output_clean.jsonl] \
model.data.validation_ds.names=["oasst"] \
model.data.validation_ds.micro_batch_size=1 \
model.data.validation_ds.global_batch_size=1 \
model.data.validation_ds.num_workers=0 \
model.data.validation_ds.metric.name=loss \
model.data.validation_ds.index_mapping_dir=/indexmap_dir \
model.data.validation_ds.prompt_template='\{input\}\{output\}' \
model.data.validation_ds.add_eos=False \
model.data.test_ds.max_seq_length=4096 \
model.data.test_ds.file_names=[data/subset_data_v2t_val_value_output_clean.jsonl] \
model.data.test_ds.names=["oasst"] \
model.data.test_ds.micro_batch_size=1 \
model.data.test_ds.global_batch_size=1 \
model.data.test_ds.num_workers=0 \
model.data.test_ds.metric.name=loss \
model.data.test_ds.prompt_template='\{input\}\{output\}' \
model.data.test_ds.add_eos=False \
exp_manager.explicit_log_dir="/home/steerlm_model/" \
exp_manager.create_checkpoint_callback=True \
exp_manager.checkpoint_callback_params.monitor=val_loss \
exp_manager.checkpoint_callback_params.mode=min
第 10 步:推理
要开始推理,请使用以下命令在后台运行推理服务器:
python examples/nlp/language_modeling/megatron_gpt_eval.py \
gpt_model_file=/models/<TRAINED_STEERLM_MODEL.nemo> \
pipeline_model_parallel_split_rank=0 \
server=True \
tensor_model_parallel_size=1 \
pipeline_model_parallel_size=1 \
trainer.precision=bf16 \
trainer.devices=1 \
trainer.num_nodes=1 \
web_server=False \
port=1427
接下来,创建 Python 辅助函数:
def get_answer(question, max_tokens, values, eval_port='1427'):
prompt = f"""<extra_id_0>System
A chat between a curious user and an artificial intelligence assistant.
The assistant gives helpful, detailed, and polite answers to the user's questions.
<extra_id_1>User
{question}
<extra_id_1>Assistant
<extra_id_2>{values}
"""
prompts = [prompt]
data = {
"sentences": prompts,
"tokens_to_generate": max_tokens,
"top_k": 1,
'greedy': True,
'end_strings': ["<extra_id_1>", "quality:", "quality:4", "quality:0"]
}
url = f"http://localhost:{eval_port}/generate"
response = requests.put(url, json=data)
json_response = response.json()
response_sentence = json_response['sentences'][0][len(prompt):]
return response_sentence
def encode_labels(labels):
items = []
for key in labels:
value = labels[key]
items.append(f'{key}:{value}')
return ','.join(items)
接下来,更改以下值以指导语言模型:
values = OrderedDict([
('quality', 4),
('toxicity', 0),
('humor', 0),
('creativity', 0),
('violence', 0),
('helpfulness', 4),
('not_appropriate', 0),
('hate_speech', 0),
('sexual_content', 0),
('fails_task', 0),
('political_content', 0),
('moral_judgement', 0),
])
values = encode_labels(values)
最后,提出问题并生成回复:
question = """Where and when did techno music originate?"""
print (get_answer(question, 4096, values))
SteerLM 用户可以使用本教程中提到的脚本和实用程序执行其他引导步骤。此步骤有助于进一步提高不同基准测试中的模型准确性。
借助 SteerLM 实现 AI 的未来
SteerLM 提供了一种新技术,用于以可控的方式实现符合人类偏好的新一代 AI 系统。其概念简单、性能提升和可定制性凸显了用户可操控 AI 的变革性可能性。SteerLM 现已作为开源软件提供,可通过NVIDIA/NeMo 的 GitHub 存储库获取。您还可以获取有关如何尝试使用Llama 2 13B model 进行 SteerLM 方法自定义的信息。
为了获得全面的企业安全和支持,SteerLM 将被集成到NVIDIA NeMo,这是一个用于构建、自定义和部署大型生成式 AI 模型的丰富框架。SteerLM 方法适用于 NeMo 支持的所有模型,包括流行的社区构建的预训练 LLM,例如 Llama 2、Falcon LLM 和 MPT。我们希望我们的工作能够促进进一步的研究,以开发能够为用户提供动力而不是约束他们的模型。借助 SteerLM,AI 的未来是可操控的。
致谢
我们要感谢 Xianchao Wu 和 Oleksii Kuchaiev 为这篇博文以及 SteerLM 的创立所做的贡献。