无论是希望平衡产品分布和优化交通的仓库,工厂装配线检查,还是医院管理,确保员工和护理人员在护理患者时使用个人防护设备( PPE ),高级智能视频分析( IVA )都非常有用。
在基础层,全球各地的城市、体育场馆、工厂和医院部署了数十亿台摄像头和物联网传感器,每天产生数 PB 的数据。随着数据爆炸,使用人工智能来简化和执行有效的 IVA 是非常必要的。
许多公司和开发人员都在努力构建可管理的 IVA 管道,因为这些工作需要人工智能专业知识、高效的硬件、可靠的软件和广泛的资源来大规模部署。 NVIDIA 构建了 DeepStream 软件开发工具包 来消除这些障碍,并使每个人都能够轻松高效地创建基于人工智能的 GPU 加速应用程序,用于视频分析。
DeepStream SDK 是一个可扩展的框架,用于为 edge 构建高性能、可管理的 IVA 应用程序。 DeepStream 使您能够在从智能城市和建筑到零售、制造和医疗保健等各个行业构建人工智能应用程序。
DeepStream 运行时系统通过流水线实现深度学习推理、图像和传感器处理,并在流式应用程序中将见解发送到云端。对于大规模部署,您可以使用容器构建云原生的、深流应用程序,并使用 Kubernetes 平台来协调这些应用程序。在边缘部署时,应用程序可以在物联网设备和云标准消息代理(如 Kafka 和 MQTT )之间进行通信,以进行大规模、广域部署。
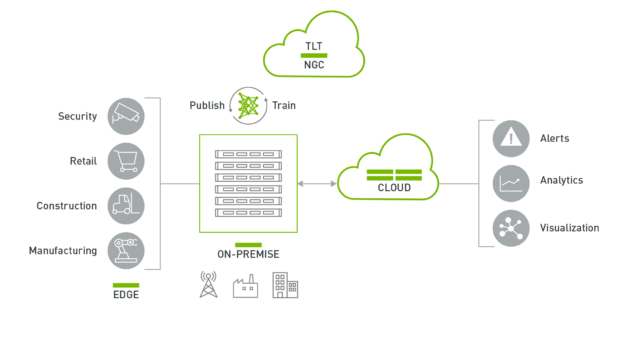
DeepStream 应用程序可以运行在由 NVIDIA Jetson 支持的边缘设备上,也可以运行在由 NVIDIA T4s 支持的本地服务器上。来自边缘的数据可以被发送到云端进行更高层次的分析和可视化。
本文的其余部分将深入探讨 deepstream5 . 0 发布的关键特性。
DeepStream 5 . 0 功能
随着 Deepstream5 . 0 , NVIDIA 使得在边缘构建和部署基于人工智能的 IVA 应用变得比以往任何时候都容易。以下是新功能:
- 支持 NVIDIA Triton ®声波风廓线仪推理服务器
- Python 包
- 应用程序的远程管理和控制
- 安全通信
- 基于 Mask R-CNN 的实例分割
Triton 推断服务器支持
创建人工智能是一个迭代的实验过程,在这个过程中,数据科学家花费大量时间对不同的架构进行实验和原型设计。在这个阶段,他们更关注如何最好地解决问题,而不是人工智能模型的效率。他们希望花费更多的时间来获得用例的高精度,而不是花在优化推理的周期上。他们希望在真实场景中快速建立原型,并查看模型的性能。
过去,使用 DeepStream 执行视频分析需要将模型转换为 NVIDIA TensorRT ,一个推理运行时。从 DeepStream 5 . 0 开始,您可以选择在培训框架中以本机方式运行模型。这使您能够快速原型化端到端系统。。
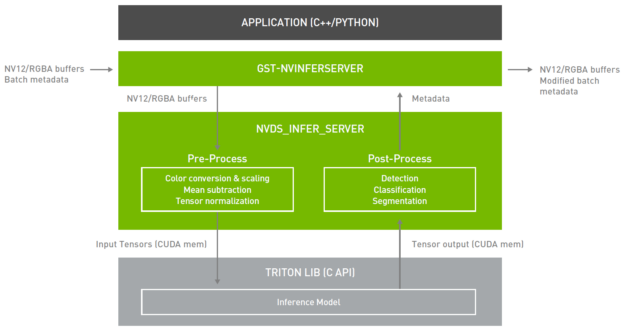
DeepStream 5 . 0 直接从应用程序集成 Triton ®声波风廓线仪服务器。 Triton Server 为您提供了在 DeepStream 中使用任何深度学习框架的灵活性。推理服务通过可用的 API 从 DeepStream 插件( Gst-nvinferserver )本机集成。插件接收 NV12 / RGBA 缓冲区并将其发送到较低级别的库。该库对图像进行预处理并转换为模型可接受的所需张量大小。张量通过 CUDA 共享内存发送到 Triton ®声波风廓线仪服务器库。
推断后, Triton Server 将输出张量返回到共享库,在那里进行后期处理以生成元数据。此元数据将附加回现有元数据并发送到下游。通过集成推理服务器,您可以使用 DeepStream 中的所有构建块来构建一个高效的 IVA 管道,并在您的培训框架上执行本机推理。
TensorRT 仍然由 DeepStream 提供本地支持。如果您正在寻找最高的推理吞吐量,或者资源受限,无法部署完整的框架和大型模型,那么这是首选的路径。如果您正在寻找灵活性,并可以牺牲一些性能换取努力, Triton ®声波风廓线仪服务器是最佳途径。
下表总结了这两种方法的优缺点。
| TensorRT | Triton Server | |
| Pros | Highest throughput | Highest flexibility |
| Cons | Custom layers require writing plugins | Less performant than a TensorRT solution |
以下是使用 DeepStream 的 Triton ®声波风廓线仪服务器的主要功能:
- 支持以下模型格式:
- Jetson 、 TensorFlow GraphDef 和 SavedModel ,以及 TensorFlow 和 T4 上的 TensorFlow – TensorRT 模型
- ONNX , PyTorch 和 Caffe2 NetDef 仅在 T4 上
- 多个模型(或同一模型的多个实例)可以在同一个 GPU 上同时运行。
为了开始使用带有 DeepStream 的 Triton 服务器,我们提供了几个示例配置文件和一个用于检索开放源代码模型的脚本。有运行 TensorRT 和 TensorFlow 模型的例子。对于本文,我们将 DeepStream 安装目录称为 $DEEPSTREAM_DIR 。实际的安装目录取决于您使用的是裸机版本还是容器。
如果您正在 x86 平台上的 NVIDIA GPU 上运行,请从 NVIDIA NGC 中拉出 nvcr.io/nvidia/deepstream:5.0-20.04-triton 容器。 Triton Server with DeepStream on x86 仅适用于 -triton 容器。如果您在 Jetson 上运行, Triton Server –共享库作为 DeepStream 的一部分预装。这可用于任何 Jetson 容器。
转到/ samples 目录:
cd $DEEPSTREAM_DIR/deepstream-5.0/samples
在这个目录中执行 bash 脚本。这个脚本下载所有必需的开源模型,并将提供的 Caffe 和 UFF 模型转换为一个 TensorRT 引擎文件。此步骤将所有模型转换为引擎文件,因此可能需要几分钟或更长时间。
生成的引擎文件的最大批处理大小在 bash 脚本中指定。要修改默认批处理大小,必须修改此脚本。这也下载了 TensorFlow ssd-inception_v2 模型。
./prepare_ds_trtis_model_repo.sh
模型在 /trtis_model_repo 目录中生成或复制。下面是如何运行 ssd-inception_v2 模型。首先进入 /trtis_model_repo/ssd_inception_v2_coco_2018_01_28 目录并找到 config.pbtxt 文件。如果 bash 脚本成功运行,您还应该看到 1/model.graphdef 。这是 TensorFlow 冰冻石墨。
下面是模型回购中提供的示例 config.pbtxt 文件。首先,使用 platform 关键字指定深度学习框架。可用选项如下:
tensorrt_plantensorflow_graphdeftensorflow_savedmodelcaffe2_netdefonnxruntime_onnxpytorch_libtorchcustom
接下来,指定输入维度、数据类型和数据格式。然后,指定所有输出张量的所有输出维度和数据类型。有关配置文件中所有选项的详细信息,请参阅 模型配置 。
name: "ssd_inception_v2_coco_2018_01_28"
platform: "tensorflow_graphdef"
max_batch_size: 128
input [
{
name: "image_tensor"
data_type: TYPE_UINT8
format: FORMAT_NHWC
dims: [ 300, 300, 3 ]
}
]
output [
{
name: "detection_boxes"
data_type: TYPE_FP32
dims: [ 100, 4]
reshape { shape: [100,4] }
},
{
name: "detection_classes"
data_type: TYPE_FP32
dims: [ 100 ]
},
{
name: "detection_scores"
data_type: TYPE_FP32
dims: [ 100 ]
},
{
name: "num_detections"
data_type: TYPE_FP32
dims: [ 1 ]
reshape { shape: [] }
}
]
接下来,使用 ssd_inception_v2 模型运行 deepstream 应用程序。 Triton ®声波风廓线仪服务器的示例配置文件在 /configs/deepstream-app-trtis 中。运行 deepstream-app 通常需要两个或多个配置文件。一个是顶层配置文件,它为整个管道设置参数,其他文件是用于推理的配置文件。
为了便于使用和简化,每个推理引擎都需要一个唯一的配置文件。如果级联多个推断,则需要多个配置文件。对于本例,请使用以下文件:
source1_primary_detector.txtconfig_infer_primary_detector_ssd_inception_v2_coco_2018_01_28.txt
[primary-gie] enable=1 (0): nvinfer; (1): nvinferserver plugin-type=1 infer-raw-output-dir=trtis-output batch-size=1 interval=0 gie-unique-id=1 config-file=config_infer_primary_detector_ssd_inception_v2_coco_2018_01_28.txt
source1_primary_detector.txt 文件是顶级配置文件。如果您使用本机 TensorRT 或 Triton ®声波风廓线仪服务器进行推断,这是很常见的。在这个配置文件中,将 [primary-gie] 下的插件类型更改为 1 ,以使用推理服务器。
config_infer_primary_detector_ssd_inception_v2_coco_2018_01_28.txt 文件用于指定推理选项,如预处理、后处理和模型恢复。有关不同选项的更多信息,请参阅 NVIDIA DeepStream SDK 快速入门指南 和 NVIDIA DeepStream 插件手册 。
对于将张量数据后处理到边界框中,此示例使用名为 NvDsInferParseCustomTfSSD 的自定义边界框解析器,如配置文件中的 custom_parse_bbox_func 键指定的那样。此自定义函数在以下配置文件的 custom_lib 部分下指定的库中编译。 $DEEPSTREAM_DIR/sources/libs/nvdsinfer_customparser/ 中提供了 NvDsInferParseCustomTfSSD 的源代码。
infer_config {
unique_id: 5
gpu_ids: [0]
max_batch_size: 4
backend {
trt_is {
model_name: "ssd_inception_v2_coco_2018_01_28"
version: -1
model_repo {
root: "../../trtis_model_repo"
log_level: 2
tf_gpu_memory_fraction: 0.6
tf_disable_soft_placement: 0
}
}
}
preprocess {
network_format: IMAGE_FORMAT_RGB
tensor_order: TENSOR_ORDER_NONE
maintain_aspect_ratio: 0
normalize {
scale_factor: 1.0
channel_offsets: [0, 0, 0]
}
}
postprocess {
labelfile_path: "../../trtis_model_repo/ssd_inception_v2_coco_2018_01_28/labels.txt"
detection {
num_detected_classes: 91
custom_parse_bbox_func: "NvDsInferParseCustomTfSSD"
nms {
confidence_threshold: 0.3
iou_threshold: 0.4
topk : 20
}
}
}
extra {
copy_input_to_host_buffers: false
}
custom_lib {
path: "/opt/nvidia/deepstream/deepstream-5.0/lib/libnvds_infercustomparser.so"
}
}
input_control {
process_mode: PROCESS_MODE_FULL_FRAME
interval: 0
}
现在,使用以下命令运行应用程序:
deepstream-app -c source1_primary_detector.txt
一个弹出窗口应该打开,播放视频样本,显示行人、汽车和自行车周围的边界框。
应用程序需要几分钟时间来构建 TensorFlow 图。如果应用程序无法运行并返回“ Killed ”,则很可能是系统内存不足。检查系统内存使用情况以确认问题。如果是内存问题,则根据模型修改 config_infer_primary_detector_ssd_inception_v2_coco_2018_01_28.txt 中 infer_config 下的 tf_gpu_memory_fraction 参数,或根据模型修改任何其他 nvinferserver 配置文件。此参数为 TF 模型分配每个进程的 GPU 内存部分。将其更改为 0 . 4 MIG ht 帮助。有关如何使用此参数的更多信息,请参阅 DS 插件手册 -Gst inferserver 。
该模型可检测多达 91 个类别,包括各种动物、食物和体育器材。有关可以检测到的类的更多信息,请参阅 trtis-model-repo/ssd_inception_v2_coco_2018_01_28/labels.txt 文件。
尝试用其他视频运行这个应用程序,看看模型是否可以检测到其他类。要将 Triton Server 与您的自定义 DeepStream 管道一起使用,请查看 $DEEPSTREAM_DIR/sources/apps/sample-apps/deepstream-app 下 deepstream-app 的源代码。
Python 包
Python 易于使用,在创建 AI 模型时被数据科学家和深度学习专家广泛采用。 NVIDIA 引入了 Python 绑定来帮助您使用 Python 构建高性能的 AI 应用程序。 DeepStream 管道可以使用 Gst Python 构建, GStreamer 框架的 Python 绑定。
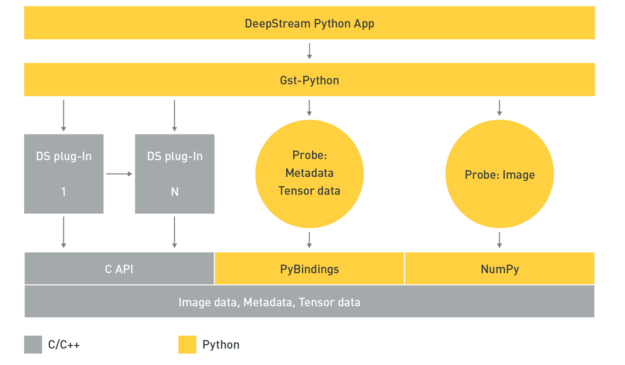
DeepStream Python 应用程序使用 Gst Python API 操作构造管道,并使用探测函数访问管道中各个点的数据。这些数据类型都是用本机 C 编写的,需要通过 PyBindings 或 NumPy 使用一个填充层才能从 Python 应用程序访问它们。张量数据是经过推断得出的原始张量输出。如果您试图检测一个对象,这个张量数据需要通过解析和聚类算法进行后处理,以在检测到的对象周围创建边界框。
利用张量数据的可用性,您可以在 Python 应用程序中创建解析算法。这一点很重要,因为张量数据的大小和维度以及解析数据所需的解析和聚类算法都取决于人工智能模型的类型。如果你想为 DeepStream 带来新的模型或新的后处理技术,你会发现这非常有用。
另一个可以访问的有用数据源是图像数据。这可以用来捕捉异常,在那里人工智能模型拿起一个对象,你想保存图像以备将来参考。现在应用程序支持访问此帧。
DeepStream 元数据的 Python 绑定以及示例应用程序一起可用,以演示它们的使用情况。 Python 示例应用程序可以从 GitHub repo NVIDIA-AI-IOT/deepstream_python_apps 下载。 Python 绑定模块现在作为 DeepStreamSDK 包的一部分提供。
远程管理和控制应用程序
将元数据从边缘发送到云是有用的,但是能够接收和控制从云到边缘的消息也很重要。
DeepStream 5 . 0 现在支持双向通信来发送和接收云到设备的消息。这对于各种用例尤其重要,例如触发应用程序以记录重要事件、更改操作参数和应用程序配置、空中传送( OTA )更新或请求系统日志和其他重要信息。
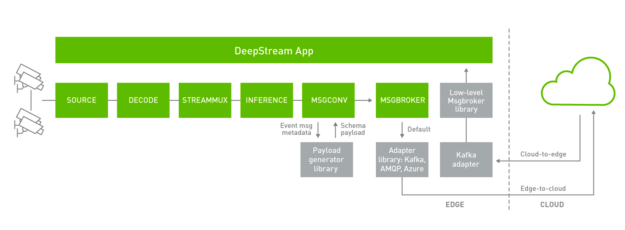
DeepStream 应用程序可以订阅 ApacheKafka 主题来接收来自云端的消息。设备到云消息传递目前通过 Gstnvmsgbroker ( MSGBROKER )插件进行。默认情况下, Gstnvmsgbroker 插件使用适当的协议调用较低级别的适配器库。您可以在 Kafka 、 AMQP 、 MQTT 或 Azure IoT 之间进行选择,甚至可以创建自定义适配器。 DeepStream 5 . 0 引入了一个新的低级 msgbroker 库,为跨各种协议的双向消息传递提供了一个统一的接口。 Gstnvmsgbroker 插件可以选择与这个新库接口,而不是直接调用协议适配器库,这是通过配置选项控制的。
对于云到边缘消息传递, DeepStream 5 . 0 中支持的协议是 Kafka ,它使用新的低层 msgbroker 库,直接与 DeepStream 应用程序交互。
DeepStream 5 . 0 支持多个其他物联网功能,可与双向消息传递结合使用。 DeepStream 现在提供了一个 API ,用于根据异常情况或“可能到设备”消息进行智能记录。此外, DeepStream 还支持在应用程序运行时对 AI 模型进行 OTA 更新。
智能视频录制
通常需要基于事件的视频录制。智能录制可以节省宝贵的磁盘空间,并提供更快的搜索速度,而不是连续记录内容。
智能记录仅在满足特定规则或条件时记录事件。发出记录信号的触发器可以来自本地应用程序、运行在边缘的某些服务或来自云端。
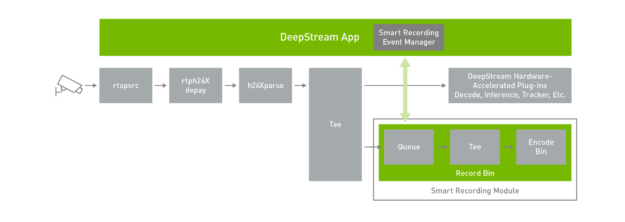
提供了丰富的 api 来构建智能记录事件管理器。这些操作可用于随时启动和停止录制。当必须记录事件时,在触发器之前开始保存剪辑是很有用的。使用智能记录 API 操作,可以将其配置为在事件发生之前记录时间。这是非常有用的,因为当异常被检测和触发时,在异常发生时和记录事件管理器启动记录之间有一些延迟。在记录开始提供事件的整个序列之前,记录一段有限的时间。
为了演示这个特性, deepstream-test5 应用程序内置了一个智能记录事件管理器。智能录制模块保持视频缓存,以便录制的视频不仅在事件生成后具有帧,还可以在事件发生之前具有帧。这个大小的视频缓存可以配置为每个用例。事件管理器启动智能记录模块的启动和停止选项。
从云端接收到的 JSON 消息可以触发录制。报文格式如下:
{
command: string // <start-recording / stop-recording>
start: string // "2020-05-18T20:02:00.051Z"
end: string // "2020-05-18T20:02:02.851Z",
sensor: {
id: string
}
}
deepstream-test5 示例应用程序演示了从云端接收和处理此类消息的过程。这是目前支持卡夫卡。要激活此功能,请在应用程序配置文件中填充并启用以下块:
Configure this group to enable cloud message consumer. [message-consumer0] enable=1 proto-lib=/opt/nvidia/deepstream/deepstream-5.0/lib/libnvds_kafka_proto.so conn-str=; config-file= subscribe-topic-list=;; Use this option if message has sensor name as id instead of index (0,1,2 etc.). sensor-list-file=dstest5_msgconv_sample_config.txt
当应用程序运行时,使用 Kafka 代理在 subscribe-topic-list 中发布关于主题的上述 JSON 消息,以启动和停止录制。
有关如何在应用程序中使用此功能的更多信息,请参阅 NVIDIA DeepStream 插件手册 的 智能视频录制 部分。 deepstream-test5 的源代码可以在以下目录中找到:
$DEEPSTREAM_DIR/sources/apps/sample_apps/deepstream-test5/
智能记录事件管理器的实现可在以下文件中找到:
$DEEPSTREAM_DIR/sources/apps/apps-common/src/deepstream_source_bin.c
OTA 模型更新
edge IVA 应用程序的一个理想需求是在 AI 模型得到增强以获得更高的精度时动态地修改或更新它们。使用 DeepStream 5 . 0 ,您现在可以在应用程序运行时更新模型。这意味着模型可以在零停机时间内更新。这对于不能接受任何延迟的任务关键型应用程序非常重要。
当需要连续交换模型时,此功能也很有用。一个例子是基于一天中的时间交换模型。一般来说,一种型号的 MIG ht 在白天光线充足的情况下工作得很好,但另一种型号在光线较暗的环境下工作得更好。在这种情况下,需要根据一天中的时间轻松地交换模型,而无需重新启动应用程序。假设正在更新的模型应该具有相同的网络参数。
在示例应用程序中,模型更新由修改配置文件的用户启动。 DeepStream 应用程序监视配置文件中所做的更改并对其进行验证。在更改被验证后, DeepStream OTA 处理程序交换到新模型,完成了这个过程。
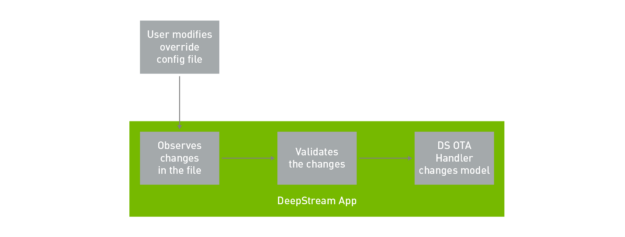
这个特性在 deepstream-test5 应用程序中进行了演示,并提供了源代码。要运行 OTA 模型更新,请运行带有 -o 选项的应用程序。这是 OTA 覆盖文件。如果要交换模型,请使用新的模型引擎文件更新此文件。
deepstream-test5 -c <DS config> -o <OTA override>
更新后的模型需要是一个 TensorRT 引擎文件,这是在更改 OTA 覆盖文件之前离线完成的。要创建 TensorRT 引擎文件,请运行 trtexec :
trtexec --model= --maxBatch= --saveEngine= --deploy= --buildOnly
模型生成后,更新 OTA 覆盖文件。当应用程序检测到此更改时,它会自动启动模型更新过程。在实际环境中,您需要在边缘上有一个守护进程或服务来更新边缘上的文件或从云端更新文件。
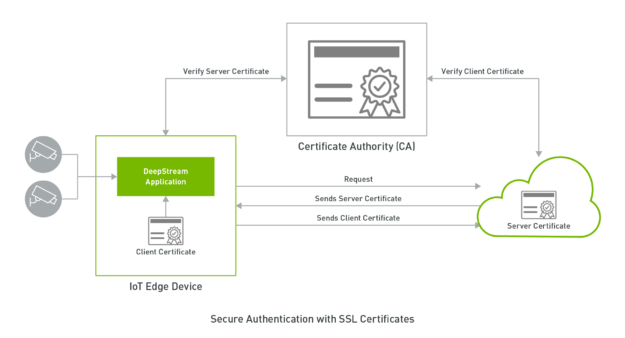
安全通信
为了在规模上成功部署物联网设备,最重要和被忽视的一个方面是安全性:能够在边缘设备和云之间安全地通信。对于公司来说,确保物联网设备的安全以及在可信位置收发敏感数据至关重要。
在 DeepStream 5 . 0 中, Kafka 适配器支持使用基于 TLS 的加密的安全通信,从而确保数据的机密性。 TLS (传输层安全性)是 SSL 的继承者,但这两个术语在文献中仍然可以互换使用。 TLS / SSL 通常用于在连接到 web 上的服务器(例如 HTTPS )时进行安全通信。 TLS 使用公钥加密技术来建立会话密钥, DeepStream 应用程序和代理程序对称使用这些密钥来加密会话期间传输的数据,因此即使在公共网络上发送数据,也要对其保密。
DeepStream 5 . 0 支持两种形式的客户端身份验证:基于 SSL 证书的双向 TLS 身份验证和基于用户名/密码机制的 SASL / Plain 身份验证。客户端身份验证使代理能够验证连接到它们的客户端,并根据其身份选择性地提供访问控制。虽然 SASL / Plain 使用了熟悉的密码身份验证隐喻,并且更容易设置,但是双向 TLS 使用客户端证书进行身份验证,并且提供了一些优势,可以实现健壮的安全机制。
有关实现安全连接的更多信息,请参阅 NVIDIA DeepStream 插件手册 。
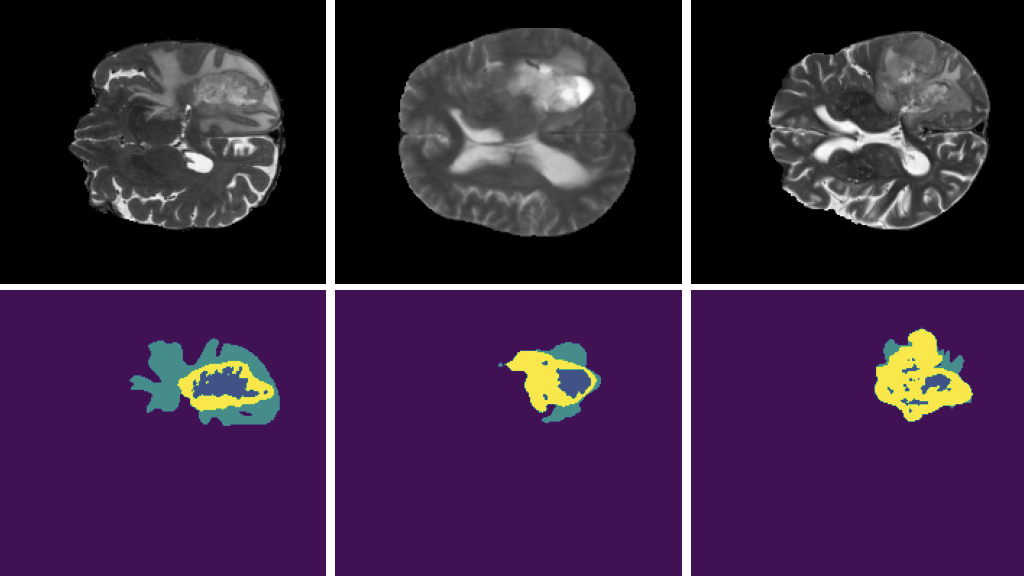
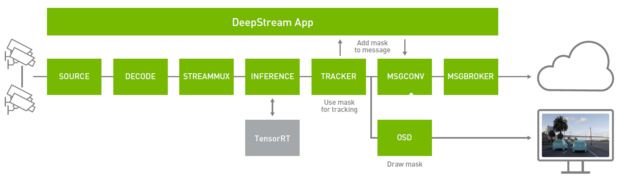
基于 Mask R-CNN 的实例分割
为了感知像素,从而产生可操作的洞察力,计算机视觉依赖于深度学习来提供对环境的理解。目标检测是一种常用的技术来识别帧中的单个对象,如人或汽车。虽然对象检测对于某些应用程序是有益的,但是当您希望在像素级理解对象时,它就不够了。。
实例分割在识别对象时提供像素级的精度。分割对于需要在对象及其背景之间进行描绘的应用程序非常有用,例如在 AI 驱动的绿色屏幕中,您希望模糊或更改帧的背景,或者分割帧中的道路或天空。它还可以用于使用输出的实例掩码来提高跟踪器的精度。
DeepStream 通过一个新的自定义解析器(用于后处理)、屏幕显示( OSD )中用于呈现分段掩码的掩码覆盖函数、用于掩码的新元数据类型以及用于标识消息转换器中多边形的新消息模式,实现了管道中的实例分段。您可以使用跟踪器中的掩码元数据来改进跟踪,在屏幕上呈现掩码,或者通过 MessageBroker 发送掩码元数据以进行脱机分析。
要开始使用 Mask R-CNN ,请从 NVIDIA-AI-IOT/deepstream_tlt_apps#tlt-models GitHub repo 下载一个经过预训练的模型。该模型在 NVIDIA 内部汽车仪表盘图像数据集上训练,以识别汽车。有关详细信息,请参见 使用 NVIDIA 迁移学习工具箱的 MaskRCNN 实例分割训练模型 。
DeepStream SDK 包含两个示例应用程序,演示如何使用预训练掩码 R-CNN 模型。 Mask R-CNN 模型可以从 deepstream-app 调用。以下目录中提供了配置管道和模型的配置:
$DEEPSTREAM_DIR/samples/configs/tlt_pretrained_models/
以下是要为 Mask R-CNN 模型运行的关键配置文件:
$DEEPSTREAM_DIR/samples/configs/tlt_pretrained_models/deepstream_app_source1_mrcnn.txt $DEEPSTREAM_DIR/samples/configs/tlt_pretrained_models/config_infer_primary_mrcnn.txt
/deepstream_app_source1_mrcnn.txt 是 deepstream-app 使用的主配置文件,它为整个视频分析管道配置参数。有关详细信息,请参见 引用应用程序配置 。以下是必须根据模型修改的关键参数。在 [OSD] 下,将 display-mask 选项更改为 1 ,这将在对象上覆盖遮罩。
[osd] enable=1 gpu-id=0 border-width=3 text-size=15 text-color=1;1;1;1; text-bg-color=0.3;0.3;0.3;1 font=Serif display-mask=1 display-bbox=0 display-text=0
/config_infer_primary_mrcnn.txt 文件是一个推理配置文件,用于设置掩码 R-CNN 推理的参数。此文件由 [primary-gie] 节下的主 deepstream_app_source1_mrcnn.txt 配置引用。以下是运行 Mask R-CNN 所需的关键参数:
[property] gpu-id=0 net-scale-factor=0.017507 offsets=123.675;116.280;103.53 model-color-format=0 tlt-model-key= tlt-encoded-model= output-blob-names=generate_detections;mask_head/mask_fcn_logits/BiasAdd parse-bbox-instance-mask-func-name=NvDsInferParseCustomMrcnnTLT custom-lib-path=/opt/nvidia/deepstream/deepstream-5.0/lib/libnvds_infercustomparser.so network-type=3 ## 3 is for instance segmentation network labelfile-path= int8-calib-file= infer-dims= num-detected-classes=<# of classes if different than default> uff-input-blob-name=Input batch-size=1 0=FP32, 1=INT8, 2=FP16 mode network-mode=2 interval=0 gie-unique-id=1 no cluster 0=Group Rectangles, 1=DBSCAN, 2=NMS, 3= DBSCAN+NMS Hybrid, 4 = None(No clustering) MRCNN supports only cluster-mode=4; Clustering is done by the model itself cluster-mode=4 output-instance-mask=1
parse-bbox-instance-mask-func-name 选项设置自定义后处理函数来解析推理的输出。此函数内置于 custom-lib-path 指定的. so 文件中。此库的源在以下目录中提供:
$DEEPSTREAM_DIR/sources/libs/nvdsinfer_customparser/nvdsinfer_custombboxparser.cpp.
要运行应用程序,请运行以下命令:
deepstream-app -c deepstream_app_source1_mrcnn.txt
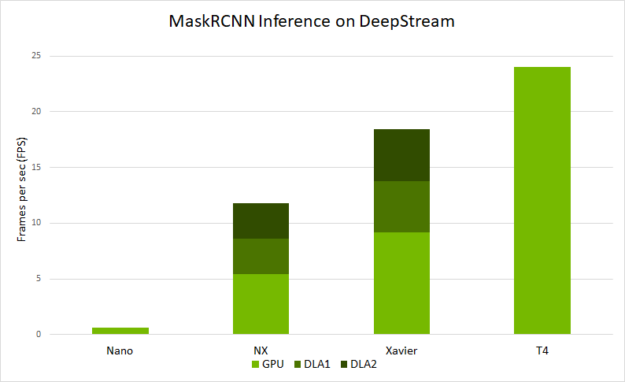
它在 SDK 中提供的剪辑上运行。要尝试自己的源代码,请在 /deepstream_app_source1_mrcnn.txt 中修改 [source0] 。图 9 显示了在不同平台上使用 deepstream-app 可以预期的端到端性能。性能以 deepstream-app 处理的每秒帧数( FPS )度量:
- 在 Jetson Nano 和 DLAs 上,它的批处理大小为 1 。
- 在 Jetson AGX Xavier 和 Xavier NX 上,运行的批处理大小为 2 。
- 在 T4 上,它以批大小 4 运行。
虽然直观地看到输出是很好的,但真正的用例可能是将元数据发送到不同的进程或云。这些信息可以由边缘或云端的不同应用程序使用,以进行进一步的分析。
使用 DeepStream ,您可以使用支持的 messagebroker 协议之一(如 Kafka 或 MQTT )使用为 mask polygon 定义的模式来发送 mask 元数据。 DeepStream 船舶具有 MaskRCNN 模型的边缘到云示例。有关如何使用 message broker 准备事件元数据和发送掩码信息的更多信息,请参阅以下应用程序:
$DEEPSTREAM_DIR/sources/apps/sample_apps/deepstream-mrcnn-app
要部署的生成
DeepStream 5 . 0 提供了许多很好的特性,使开发用于边缘部署的 AI 应用程序变得容易。您可以使用 Python API actions 和 Triton 服务器,以最小的工作量快速原型化和创建 IVA 管道。
AI 模型可以通过 Triton Server 在培训框架中进行本地部署,以增加灵活性。您可以使用大量的物联网特性来创建可管理的 IVA 应用程序。可以使用双向 TLS 身份验证将消息从边缘安全地发送到云。边缘和云之间的双向通信提供了更好的应用程序可管理性。这可以用来更新边缘的人工智能模型,记录感兴趣的事件,或者使用它从设备中检索信息。
下载 深水 5 . 0 立即开始。有关更多信息,请参阅以下资源:
- DeepStream 软件开发工具包
- 使用 NVIDIA 转移学习工具包使用定制的预训练模型进行培训 岗位
- 迁移学习工具包
- DeepStream 开发人员论坛 或 TLT 开发者论坛 用于提问或反馈
- 了解有关使用 DeepStream 和 TLT 的 Jetson 开发者社区项目 的更多信息