
如果您从事数据分析工作,您就会知道数据摄取通常是数据预处理工作流的瓶颈。由于数据量大且常用格式复杂,从存储中获取数据并对其进行解码通常是工作流中最耗时的步骤之一。对从事大型数据集研究的数据科学家来说,优化数据摄取可以大大减少这一瓶颈。
RAPIDS cuDF 通过为数据科学中流行的格式实现 CUDA 加速读取器,大大加快了数据解码速度。
此外, Magnum IO GPUDirect Storage ( GDS )使 cuDF 能够通过将数据直接从存储器加载到设备( GPU )内存来加速输入/输出。通过在 GPU 和兼容存储设备(例如,非易失性存储器 Express ( NVMe )驱动器)之间通过 PCIe 总线提供直接数据路径, GDS 可以实现高达 3 – 4 倍的 cuDF 读取吞吐量,在各种数据配置文件中的平均吞吐量提高 30 – 50% 。
在本文中,我们将概述 GPUDirect 存储以及它如何集成到 cuDF 中。我们介绍了一套用于评估输入/输出性能的基准测试。然后,我们将介绍 cuDF 实现的优化 GDS 读取的技术。我们以基准结果作为结论,并确定使用 GDS 对 cuDF 最有利的案例。
什么是 GPUDirect 存储?
GPUDirect Storage 是一种新技术,可实现本地或远程存储(作为块设备或通过文件系统接口)与 GPU 内存之间的直接数据传输。
换句话说,直接内存访问( DMA )引擎现在可以快速将数据从存储器直接路径移动到 GPU 内存,而不会增加延迟,也不会通过反弹缓冲区对 CPU 进行额外复制。
图 1 显示了没有 GDS 和有 GDS 的数据流模式。使用系统内存反弹缓冲区时,从系统内存到 GPU 的带宽会限制吞吐量。在具有多个 GPU 和 NVMe 驱动器的系统上,此瓶颈更加明显。
然而,由于具有将 GPU 与存储设备直接连接的能力,中介 CPU 从数据路径中移除,所有 CPU 资源都可以用于特征工程或其他预处理任务。
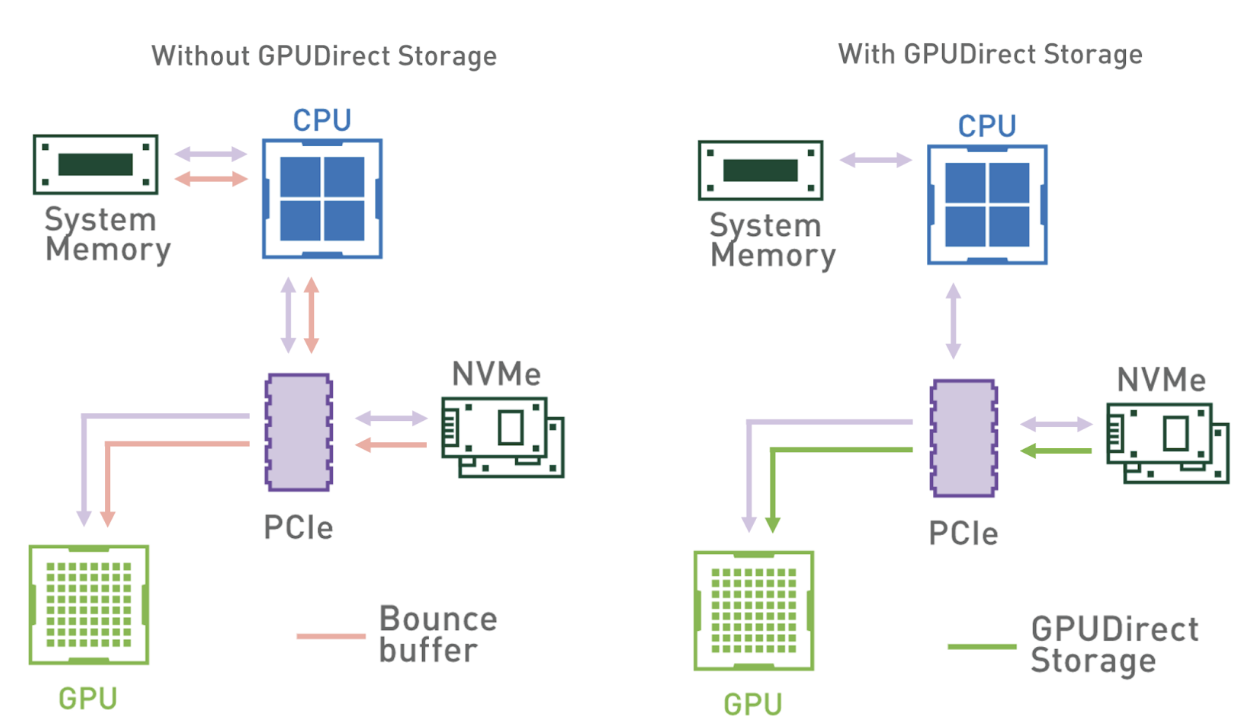
GDS cuFile library 使应用程序和框架能够利用GDS技术来增加带宽并降低延迟。自11.4版起,cuFile作为 CUDA 工具包的一部分提供。
RAPIDS cuDF 如何使用 GPUDirect 存储?
为了提高端到端的读取吞吐量, cuDF 在其数据摄取接口中使用cuFile API ,如read_parquet和read_orc。由于 cuDF 几乎在 GPU 上执行所有解析,因此系统内存中不需要大部分数据,可以直接传输到 GPU 内存。
因此, CPU 只访问输入文件的元数据部分,元数据只占总文件大小的一小部分。这允许 cuDF 数据摄取 API 有效利用 GDS 技术。
自 cuDF 22.02 以来,我们默认启用了 GDS 的使用。如果安装了cuFile并请求从受支持的存储位置读取数据, cuDF 会通过cuFile API 自动执行直接读取。如果 GDS 不适用于输入文件,或者如果用户禁用 GDS ,则数据将遵循跳出缓冲区路径,并通过分页系统内存缓冲区进行复制。
cuDF 中的基准数据摄取
为了应对数据科学数据集的多样性,我们组装了一个针对关键数据和文件属性的基准套件。先前的输入/输出基准测试示例使用了数据样本,如 纽约出租车出行记录 、 Yelp 评论数据集 或 Zillow 住房数据 ,以表示一般用例。然而,我们发现,对数据和文件属性的特定组合进行基准测试对于性能分析和故障排除至关重要。
涵盖数据和文件属性的组合
表 1 显示了我们在二进制格式基准测试中改变的参数。我们生成了一系列受支持数据类型的伪随机数据,并为每组相关类型收集了基准测试。我们还独立地改变了数据的运行长度和基数,以对目标格式进行运行长度编码和字典编码。
最后,我们改变了生成的文件中的压缩类型,用于前面属性的所有值。我们目前支持两种选择:使用 Snappy 或保持数据未压缩。
| Data Property | Description |
| File format | Parquet, ORC |
| Data type | Integer (signed and unsigned) Float (32-, 64-bit) String (90% ASCII, 10% Unicode) Timestamp (day, s, ms, us, ns) Decimal (32-, 64-, 128-bit) List (nesting depth 2, int32 elements) |
| Run-length | Average data value repetition (1x or 32x) |
| Cardinality | Unique data values (unlimited or 1000) |
| Compression | Lossless compression type (Snappy or none) |
对于所有独立更改的属性,我们有大量不同的情况:每个文件格式( ORC 和 Parquet )有 48 个情况。为了确保案例之间的公平比较,我们针对内存中固定的数据帧大小和列计数,默认大小为 512 MiB 。在这篇文章中,我们引入了一个额外的参数来控制目标内存数据帧大小从 64 到 4096 MiB 。
完整的 cuDF 基准测试套件可在 开源 cuDF 存储库 . 为了关注 I / O 的影响,本文只包括 cuDF 中的输入基准,而不是读卡器选项或行/列选择基准。
优化 cuDF + GDS 文件读取吞吐量
ORC 和 Parquet 等格式的数据存储在独立的块中,我们在单独的操作中读取这些数据。我们发现,当在单个线程中执行这些操作时,读取带宽不会饱和,无论 GDS 的使用情况如何,都会导致次优性能。
并行发出多个 GDS 读取调用可以使多个存储重叠到 – GPU 拷贝,从而提高吞吐量并可能使读取带宽饱和。从版本 1.2.1.4 开始,cuFile调用是同步的,因此并行性需要下游用户的多线程处理。
控制并行级别
由于我们没有控制文件布局和数据块的数量,因此为每个读取操作创建单独的线程可能会产生过多的线程,从而导致性能开销。另一方面,如果我们只有几个大型读取调用,我们可能没有足够的线程来有效地饱和存储硬件的读取带宽。
为了控制并行级别,我们使用了一个线程池,并将较大的读取调用分割为可以并行执行的较小读取。
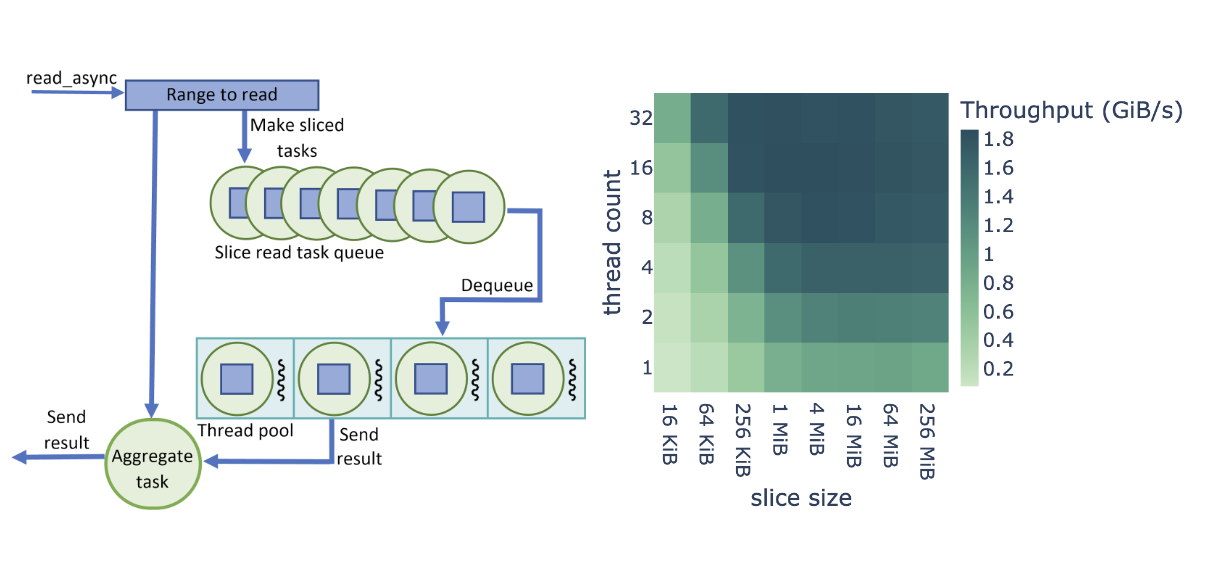
当我们开始使用 GDS 读取文件时,我们基于 Brock 大学 Barak Shoshany 的 thread-pool 工作创建了一个数据摄取管道。如图 2 所示,我们将 cuDF 读取器中的每个文件读取操作(read_async调用)拆分为固定大小的cuFile调用,但在大多数情况下,最后一个片段除外。
不是直接调用cuFile来读取数据,而是为每个片创建一个任务并将其放置在队列中。read_async调用返回一个任务,该任务等待所有切片任务完成。在需要继续请求数据之后,调用方可以执行其他工作并等待聚合任务。如果可用,池中的线程将任务出列,并进行同步cuFile调用。
完成后,线程将任务设置为已完成,并可用于执行队列中的下一个任务。由于大多数任务读取相同数量的数据, cuFile 读取在线程之间实现了有效的负载平衡。给定的read_async调用的所有任务完成后,聚合任务完成,调用方代码可以继续,因为请求的数据范围已上载到 GPU 内存。
最佳并行级别
线程池和读取片的大小极大地影响了同时执行的 GDS 读取调用的数量。为了最大化吞吐量,我们对这些参数的一系列不同值进行了实验,并确定了提供最高吞吐量的配置。
图 2 显示了对 cuDF + GDS 数据摄取的性能优化研究,其中包含线程数和切片大小的可调参数。在本研究中,我们将端到端读取吞吐量定义为二进制格式文件大小除以总摄取时间( I / O 加上解析和解码)。
图 2 所示的吞吐量是整个基准测试套件的平均吞吐量,基于 512 MiB 的数据帧大小。我们发现, Parquet 和 ORC 二进制格式在参数范围内共享相同的优化行为,如图 2 所示。由于读取任务的数量较多,较小的片大小会导致较高的开销,而较大的片大小会导致线程池的利用率较低。
此外,较低的线程数不能提供足够的并行性来饱和 NVMe 读取带宽,而较高的线程数会导致线程开销。我们发现,最高的端到端读取吞吐量是针对 8-32 个线程和 1-16 个 MiB 片大小。
根据用例的不同,您可能会发现具有不同值的最佳性能。这就是为什么从 22.04 开始,默认线程池大小为 16 ,切片大小为 4 MiB 可以通过环境变量进行配置,如 GPUDirect 存储集成 中所述。
GDS 对 cuDF 数据摄取的影响
我们使用前面描述的基准套件评估了 GDS 的使用对一些 cuDF 数据摄取 API 性能的影响。为了隔离 GDS 的影响,我们使用默认配置(使用 GDS )运行同一组基准测试,并通过环境变量手动禁用 GDS 。
为了使用 cuDF 基准进行准确的 I / O 基准测试,必须在每次新的读取操作之前清除文件系统缓存。基准测试测量执行read_orc或read_parquet调用的总时间(读取时间),这些是我们用于比较的值。计算每个基准案例文件的 GDS 加速比,即通过反弹缓冲区的读取时间除以通过直接数据路径的总摄取时间。
为了比较 GDS 性能,我们使用了 NVIDIA DGX-2 , V100 GPU 和 NVMe SSD 连接在 RAID 0 配置中。所有基准测试都使用单个 GPU 并从两个 3.84 TB NVMe SSD 的单个 RAID 0 读取。
文件越大,速度越快
图 3 显示了内存数据帧大小为 4096 MiB 的各种文件的 GDS 加速。我们观察到,性能改进的幅度很大,在主机路径上的增幅介于 10% 到 270% 之间。
一些差异是由于数据解码的差异造成的。例如,由于解析复杂度较高,列表类型显示的加速比较小,而 ORC 中的十进制类型显示的加速比较小,因为与拼花地板相比,定点解码的开销较小。
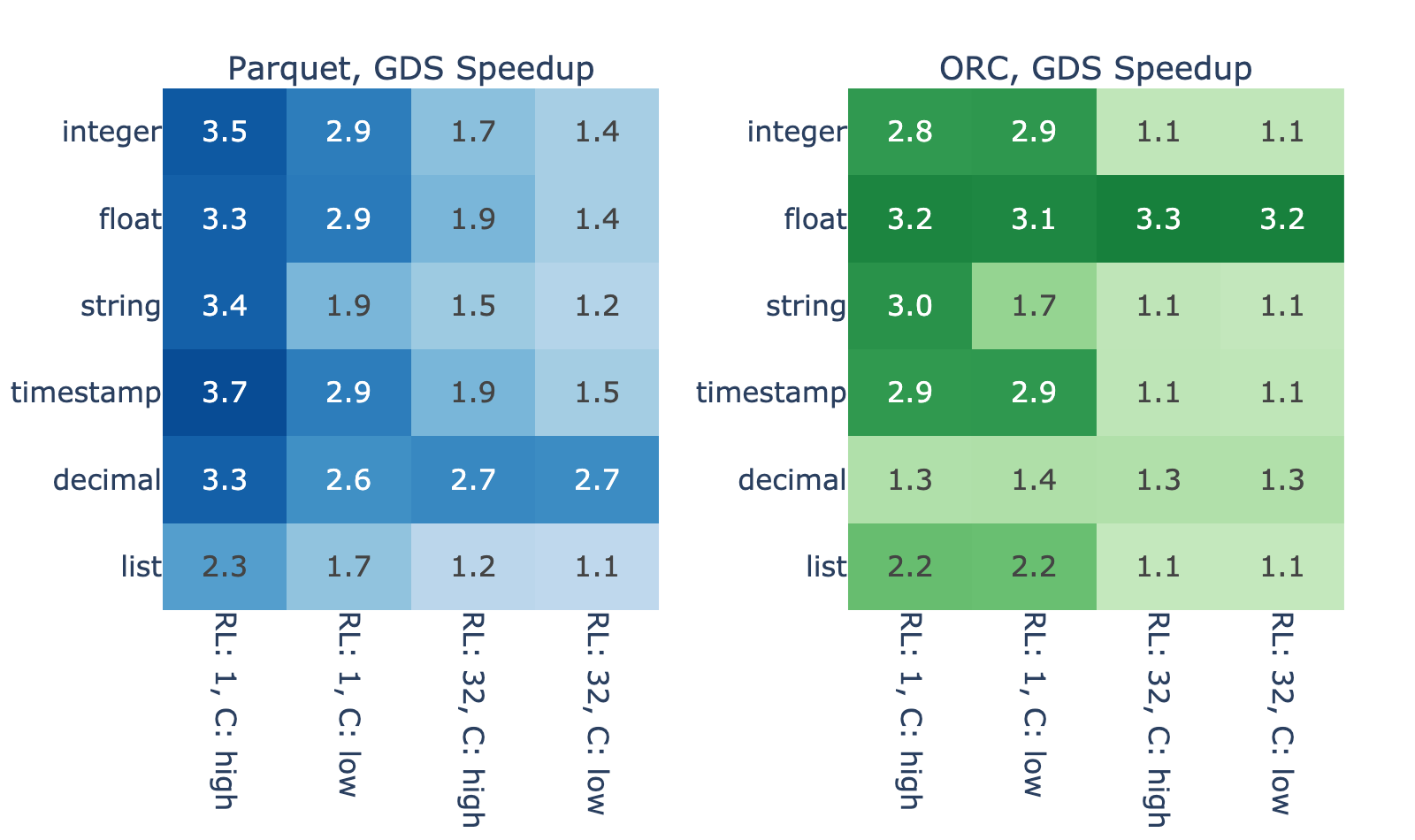
然而,解码过程不能解释结果中的大部分方差。由于 ORC 和拼花地板的结果之间的高度相关性,您可以合理地怀疑运行长度和基数等属性起着主要作用。这两个属性都会影响数据的压缩/编码程度,因此下面介绍了文件大小与这些属性的关系,以及通过代理与 GDS 加速的关系。
图 4 显示了数据的内在属性对存储固定内存数据大小所需的二进制文件大小的影响程度。对于 4096 个 MiB 内存中的数据,在没有 Snappy 压缩的基准情况下,文件大小从 0.1 GB 到 5.8 GB 不等。正如预期的那样,最大的文件大小通常对应较短的运行长度和较高的基数,因为使用此配置文件的数据很难有效编码。
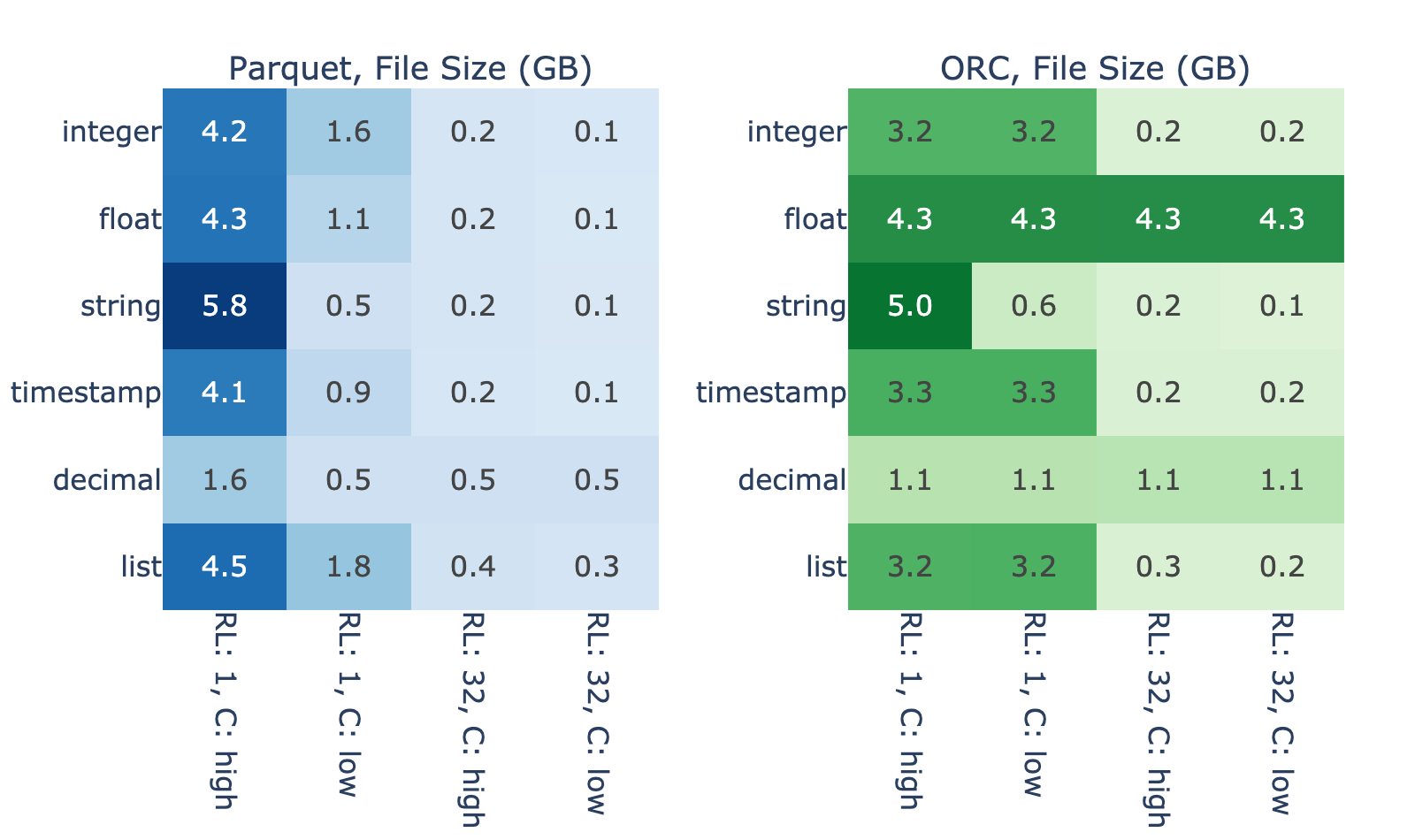
图 3 和图 4 显示了文件大小与 GDS 性能优势之间的密切关系。我们假设这是因为,当读取一个高效编码的文件时,与解码相比, I / O 花费的时间更少,因此 GDS 的改进空间很小。另一方面,结果表明,读取编码不好的文件在 I / O 上会遇到瓶颈。
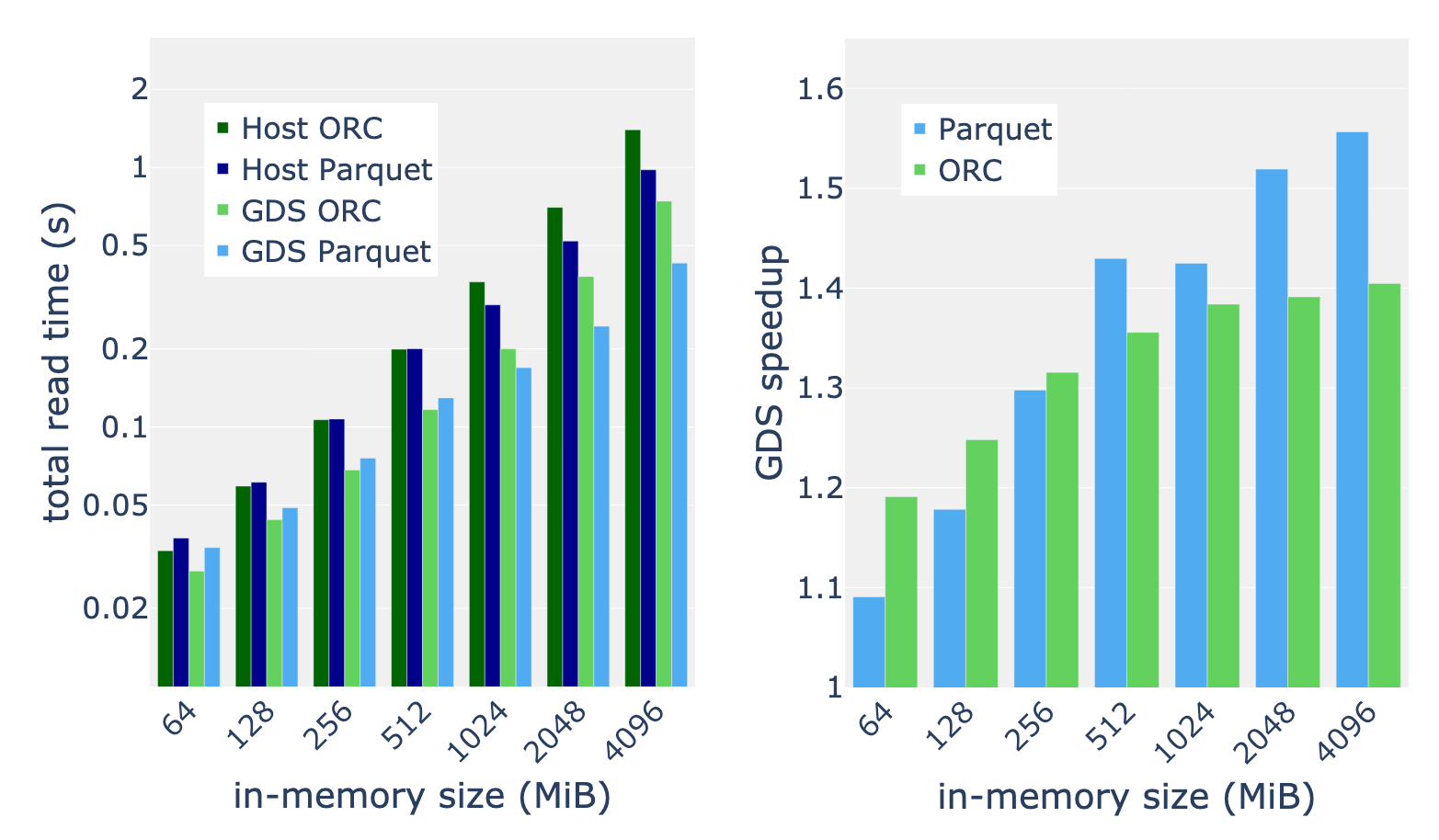
数据越大,速度越快
我们将表 1 中描述的完整基准测试套件应用于内存大小在 64 到 4096 MiB 之间的输入。以基准测试套件的平均加速比为例,我们发现 GDS 的加速比通常会随着数据大小的增加而增加。我们测量 512 MiB 和更大内存数据大小的一致加速比为 30-50% 。对于最大的数据集,我们发现拼花地板阅读器比 ORC 阅读器从 GDS 中受益更多。
总结
GPUDirect 存储提供了到 GPU 的直接数据路径,减少了延迟并提高了 I / O 操作的吞吐量。 RAPIDS cuDF 在其数据摄取 API 中利用 GDS 来解锁存储硬件的完整读取带宽。
GDS 使您能够将 cuDF 数据摄取工作负载的速度提高到 3 倍,从而显著提高工作流的端到端性能。
应用您的知识
如果您还没有为数据处理工作负载试用过 cuDF ,我们鼓励您测试我们最新的 22.04 版本。我们为我们的发行版和夜间构建提供了 Docker containers 。 Conda 软件包也可用于简化测试和部署。如果你想的话 RAPIDS cuDF 入门 ,您可以这样做。
如果您已经在使用 cuDF ,我们建议您尝试一下 GPUDirect 存储。利用高容量和高性能 NVMe 驱动器比以往任何时候都更容易。如果您已经有了硬件,那么距离解锁数据摄取的峰值性能还有几步之遥。请继续关注即将发布的 cuDF 。
有关存储 I / O 加速的更多信息,请参阅以下参考资料:




