出色的 AI 性能需要高效的并行计算架构、高效的工具堆栈和深度优化的算法。NVIDIA 发布了 NVIDIA TensorRT-LLM,它包括专为 NVIDIA RTX GPU 设计的优化,以及针对 NVIDIA Hopper 架构 的优化,这些架构是 NVIDIA H100 Tensor Core GPU 的核心,位于 NVIDIA Omniverse 中。这些优化使得如 Lama 2 70B 等模型能够在 H100 GPU 上利用加速的 FP8 运算进行执行,同时保持推理准确性。
在最近的一次发布活动中,AMD 谈到了 H100 GPU 与其 MI300X 芯片相比的推理性能。分享的结果没有使用经过优化的软件,如果基准测试正确,H100 的速度会提高 2 倍。
以下是在 Llama 2 70B 模型上搭载 8 个 NVIDIA H100 GPU 的单个 NVIDIA DGX H100 服务器的实际测量性能。这包括“Batch-1”(一次处理一个推理请求)的结果,以及使用固定响应时间处理的结果。
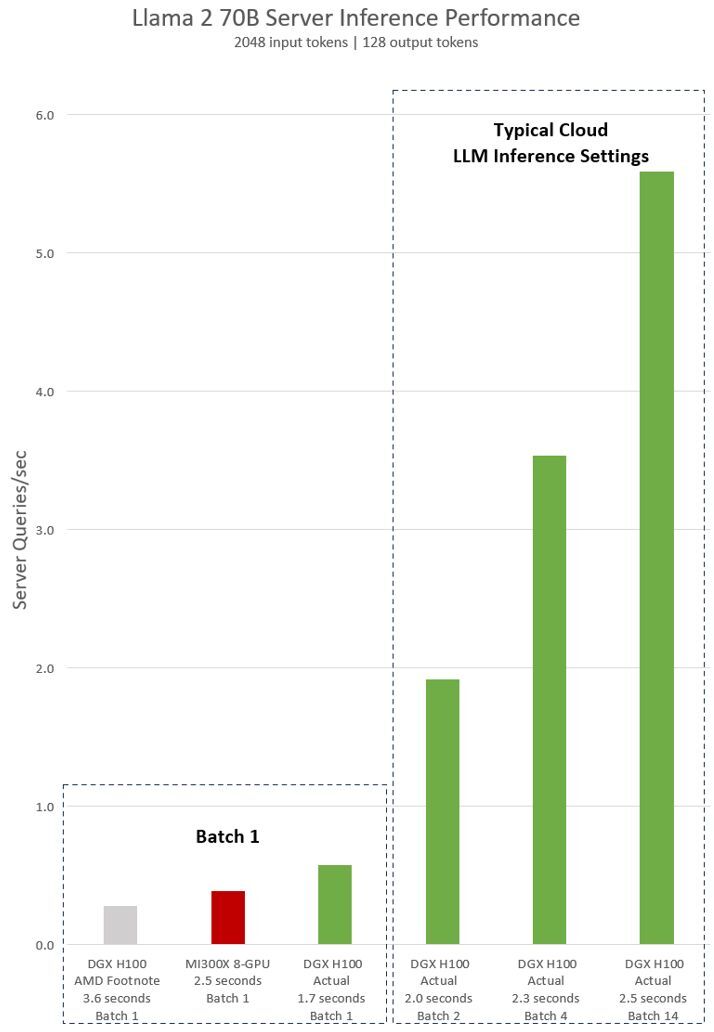 图 1.Lama 2 70B 服务器每秒查询的推理性能,具有“Batch 1”的 2048 个输入令牌和 128 个输出令牌,以及各种固定响应时间设置
图 1.Lama 2 70B 服务器每秒查询的推理性能,具有“Batch 1”的 2048 个输入令牌和 128 个输出令牌,以及各种固定响应时间设置AMD 对 H100 的隐含声明基于 AMD 发布演示脚注#MI300-38 中的配置进行衡量。使用配备 NVIDIA DGX H100 系统的 vLLM v.02.2.2 推理软件,Llama 2 70B 查询的输入序列长度为 2048,输出序列长度为 128.他们声称与配备 8 块 GPU MI300X 系统的 DGX H100 相比,性能相对较好。
对于 NVIDIA 测量数据,DGX H100 配备 8 块 NVIDIA H100 Tensor Core GPU,搭载 80 GB HBM3 和公开发布的 NVIDIA TensorRT-LLM,v0.5.0 用于Batch 1,v0.6.1 用于延迟值测量。工作负载详细信息与脚注#MI300-38 相同。
DGX H100 可以在 1.7 秒内处理单个推理,而批量大小为 1 (换言之,一次一个推理请求)。批量大小为 1 的结果可实现更快的模型响应时间。为了优化响应时间和数据中心吞吐量,云服务为特定服务设置固定的响应时间。这使他们能够将多个推理请求组合成更大的“批量”,并增加服务器每秒的总体推理次数。MLPerf 等行业标准基准测试也使用这个固定的响应时间指标来衡量性能。
在响应时间方面进行细微的权衡会产生服务器可以实时处理的推理请求数量的 x 系数。使用固定的 2.5 秒响应时间预算,8 GPU DGX H100 服务器每秒可处理超过 5 次 Llama 2 70B 推理,而在批量 1 中,每秒可处理的推理不到 1 次。
AI 正在飞速发展,NVIDIA CUDA 生态系统让我们能够快速且持续地优化整个技术栈。我们期待每次软件更新都能进一步提升 AI 性能,因此请确保查看我们的性能页面以及GitHub 页面以获取最新信息。
如何重现这些 AI 推理结果
DGX H100 AMD 脚注由 NVIDIA 在 vLLM 中根据 AMD 在其脚注中提供的配置进行测量,并提供了vLLM 和基准测试脚本,使用以下命令行:
$ python benchmarks/benchmark_latency.py --model "meta-llama/Llama-2-70b-hf" --input-len 2048 --output-len 128 --batch-size 1 -tp 8
MI300X 8 芯片系统是基于 AMD 声称的DGX H100 AMD 脚注测量 vLLM 结果。
测量的 DGX H100 由 NVIDIA 使用公开可用的 TensorRT-LLM 版本进行测量,详情请见 GitHub,并使用 TensorRT-LLM 基准测试中列出的命令行,参考 Llama 2 指南。
// Build TensorRT optimized Llama-2-70b for H100 fp8 tensorcore
$ python examples/llama/build.py --remove_input_padding --enable_context_fmha --parallel_build --output_dir DTYPE.float16_TP.8_BS.14_ISL.2048_OSL.128 --dtype float16 --use_gpt_attention_plugin float16 --world_size 8 --tp_size 8 --pp_size 1 --max_batch_size 14 --max_input_len 2048 --max_output_len 128 --enable_fp8 --fp8_kv_cache --strongly_typed --n_head 64 --n_kv_head 8 --n_embd 8192 --inter_size 28672 --vocab_size 32000 --n_positions 4096 --hidden_act silu --ffn_dim_multiplier 1.3 --multiple_of 4096 --n_layer 80
// Benchmark Llama-70B
$ mpirun -n 8 --allow-run-as-root --oversubscribe ./cpp/build/benchmarks/gptSessionBenchmark --model llama_70b --engine_dir DTYPE.float16_TP.8_BS.14_ISL.2048_OSL.128 --warm_up 1 --batch_size 14 --duration 0 --num_runs 5 --input_output_len 2048,1;2048,128