基于 NVIDIA Ampere GPU 架构 的 NVIDIA A100 提供了一系列令人兴奋的新功能:第三代张量核心、多实例 GPU ( MIG )和第三代 NVLink 。
安培张量核心引入了一种新的用于人工智能训练的数学模式:张量浮点 -32 ( TF32 )。 TF32 旨在加速 FP32 数据类型的处理, FP32 数据类型通常用于 DL 工作负载。在 NVIDIA A100 张量核心上,以 TF32 格式运行的数学运算的吞吐量比上一代 Volta V100 GPU 上运行的 FP32 高出 10 倍,从而使 DL 工作负载的性能提高了 5 . 7 倍。
每个月, NVIDIA 都会在 NVIDIA NGC 上发布 DL 框架的容器,这些容器都针对 NVIDIA GPUs : TensorFlow 1 、 TensorFlow 2 、 PyTorch 和“ NVIDIA 优化的深度学习框架,由 Apache MXNet 提供支持”。从 20 . 06 版开始,我们在所有深度学习框架容器中增加了对新的 NVIDIA A100 特性、新的 CUDA 11 和 cuDNN 8 库的支持。
在这篇文章中,我们将重点介绍基于 TensorFlow 1 . 15 的容器和支持 TensorFlow GPUs 的 pip 轮子,包括 A100 。我们继续每月发布 NVIDIA TensorFlow 1 . 15 ,以支持仍在使用 NVIDIA 1 . x 的大量 NVIDIA 客户。
20 . 06 版本中的 NVIDIA TensorFlow 1 . 15 . 2 基于上游 TensorFlow 版本 1 . 15 . 2 。通过这个版本,我们在 NVIDIA Ampere 架构 GPUs 上提供了对 TF32 的现成支持,同时也增强了对上一代 GPUs 的支持,例如 Volta 和 Turing 。此版本允许您在 NVIDIA Ampere architecture GPUs 上实现 TF32 的速度优势,而不会对 DL 工作负载进行代码更改。此版本还包括对自动混合精度( AMP )、 XLA 和 TensorFlow – TensorRT 集成的重要更新。
NVIDIA A100 支持的数值精度
深度神经网络( DNNs )通常可以采用混合精度策略进行训练,主要采用 FP16 ,但必要时也可以采用 FP32 精度。这种策略可以显著减少计算、内存和内存带宽需求,同时通常收敛到类似的最终精度。有关更多信息,请参阅 NVIDIA Research 的 混合精度训练 白皮书。
NVIDIA 张量核是 NVIDIA Volta 和新一代 GPUs 上的专用算术单元。它们可以在一个时钟周期内执行一个完整的矩阵乘法和累加运算( MMA )。在 Volta 和 Turing 上,输入是两个尺寸为 4 × 4 的 FP16 格式矩阵,而累加器为 FP32 。
Ampere 上的第三代张量核支持一种新的数学模式: TF32 。 TF32 是一种混合格式,用于以更高的效率处理 FP32 的工作。具体来说,由于使用了 8 位指数, TF32 使用了与 FP16 相同的 10 位尾数,以确保精度,同时与 FP32 具有相同的范围。
当使用 TF32 时,更广泛的可表示范围匹配 FP32 消除了损耗缩放操作的需要,从而简化了混合精度训练工作流程。图 1 显示了各种数字格式之间的比较。
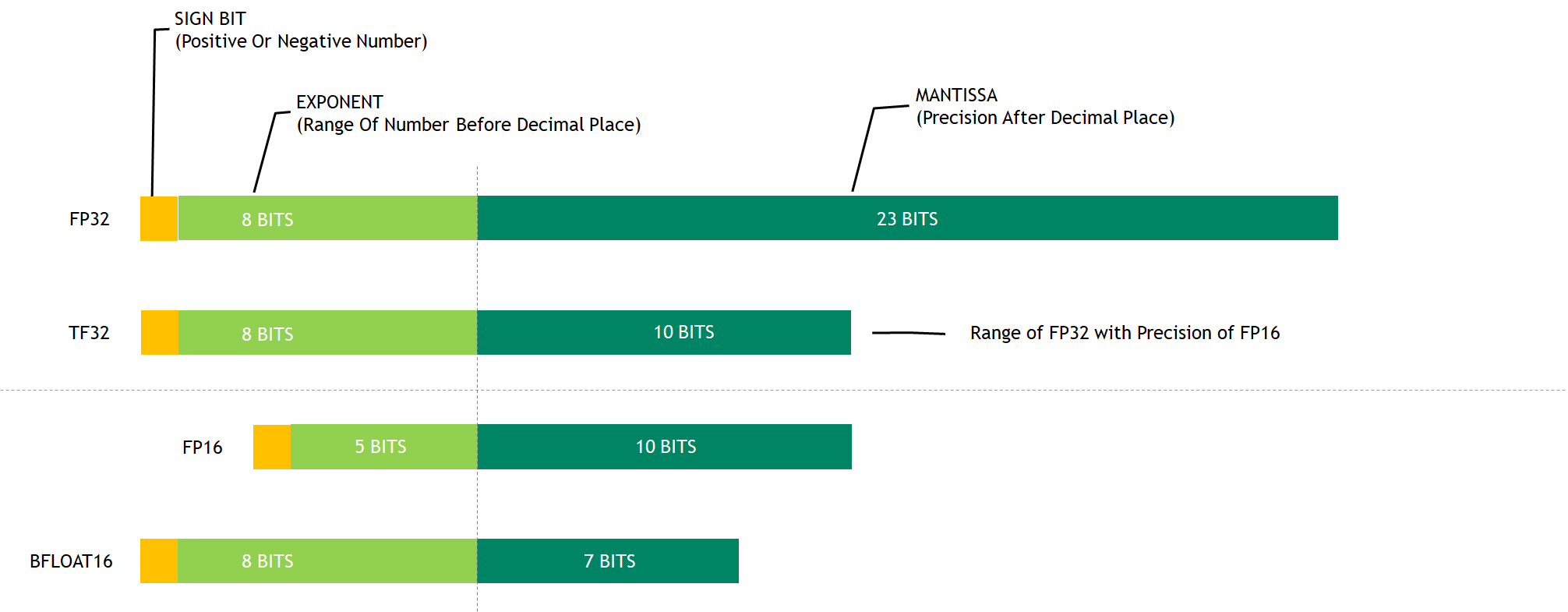
在安培张量核心上, TF32 是 DL 工作负载的默认数学模式,与 Volta / Turing GPUs 上的 FP32 相反。在内部,当在 TF32 模式下工作时,安培张量核心接受两个 FP32 矩阵作为输入,但在内部以 TF32 格式执行矩阵乘法。结果累加在 FP32 矩阵中。
在 FP16 / BF16 模式下工作时,安培张量核接受 FP16 / BF16 矩阵,并累加到 FP32 矩阵中。与 TF32 相比, FP16 / BF16 安培模式提供了 2 倍的吞吐量。图 2 显示了这些操作模式。
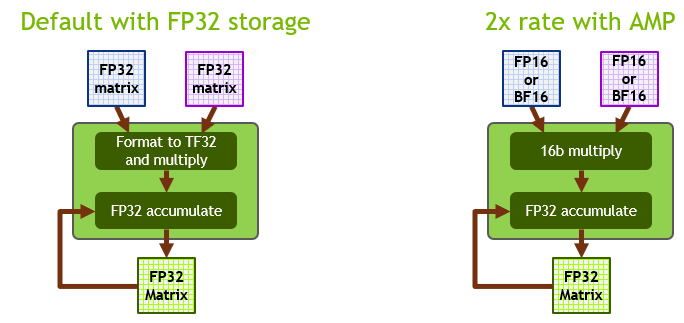
TF32 旨在将 NVIDIA 张量核心技术的处理能力带到所有 DL 工作负载中,而无需任何必需的代码更改。对于希望获得最高吞吐量的更精明的开发人员来说,使用 FP16 进行 AMP 培训仍然是最具性能的选项,而且可以轻松启用,而无需更改代码(使用 NVIDIA NGC TensorFlow 容器时)或只需一行额外的代码。
我们在广泛的网络体系结构上进行的大量实验表明,任何能够成功地训练成与 FP16 / BF16 上的 AMP 融合的网络也可以训练成与 TF32 融合。在这种情况下,最终 TF32 训练的模型精度与使用 FP32 训练的模型精度相当。
TensorFlow 1 . 15 . 2 的增强功能
TensorFlow 1 . 15 . 2 提供了以下增强:
- TF32 支持
- AMP
- XLA
- TensorFlow – TensorRT 集成
TF32 支持
NVIDIA TensorFlow 20 . 06 版本的 1 . 15 . 2 使用现成的安培 TF32 功能来加速所有 DL 训练工作负载。这是默认选项,不需要开发人员更改代码。在 pre-Ampere GPU 架构中, FP32 仍然是默认精度。
您还可以通过设置环境变量将默认数学模式更改为安培 GPUs 上的 FP32 :
export NVIDIA_TF32_OVERRIDE=0
不建议使用此选项。主要用于调试目的。
自动混合精度训练
带 FP16 的 AMP 培训仍然是 DL 培训中最具性能的选项。对于 TensorFlow , AMP 培训是在 TensorFlow 1 . 14 之后集成的,允许从业者轻松地进行混合精度训练,无论是编程还是通过设置环境变量。
使用单个 API 调用包装优化器:
opt = tf.train.experimental.enable_mixed_precision_graph_rewrite(opt)
这个改变将自动损耗比例应用到您的模型中,并使自动铸造达到半精度,如 CNN 混合精度训练 示例所示。
使用以下命令启用 NVIDIA NGC TensorFlow 1 个集装箱 中的环境变量:
export TF_ENABLE_AUTO_MIXED_PRECISION=1
这会自动对所有 TensorFlow 工作负载应用混合精度训练。有关执行手动混合精度训练的详细信息,请参阅 张量核心数学 。
XLA
XLA 是 TensorFlow 的 DL 图形编译器。在 native TensorFlow 中,网络的每一层都是独立处理的。相比之下, XLA 可以将网络的一部分聚类成可以优化和编译的“子图”。这会以一些编译开销为代价提供性能优势。图 3 显示了 XLA 的工作流。
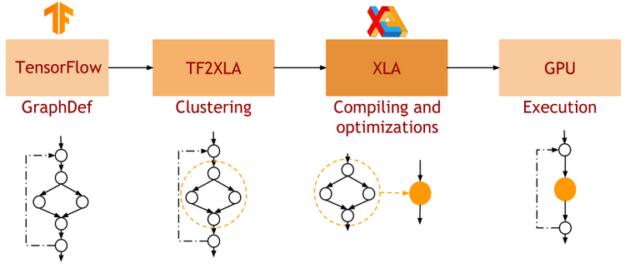
在 GPU 上执行时, XLA 会执行如下优化:
- 核聚变: 具有消费者/生产者关系的带宽受限内核被垂直和水平地融合到单个 CUDA 内核中。这通过减少对全局内存的访问来提高性能,并提供了观察到的大部分性能好处。
- 对优化库内核的调用: XLA- GPU 针对经过高度优化和性能优化的 cuDNN / cuBLAS 内核,并将多个运算符组合到一个优化的 cuDNN / cuBLAS 内核中。
有关 XLA : GPU 的更多信息,请参阅深度学习框架文档中的 XLA 最佳实践 。
TensorFlow – TensorRT 集成
NVIDIA TensorRT 是一个用于高性能 DL 推理的 SDK 。它包括 DL 推理优化器和运行时,为 DL 推理应用程序提供低延迟和高吞吐量。
TensorRT 与 TensorFlow 1 紧密结合。我们称之为 TensorFlow – TensorRT 集成( TF-TRT ) 。在 TF 版本 1 . 15 中,它是 TensorFlow 的一部分。 python .编译器包裹。通过一个简单的 API 调用,一个经过训练的神经网络可以很容易地转换为 TF-TRT 模型,如下面的代码块所示。
from tensorflow.python.compiler.tensorrt import trt_convert as trt converter = trt.TrtGraphConverter( input_saved_model_dir=input_saved_model_dir, precision_mode=trt.TrtPrecisionMode. ) converter.convert() converter.save(output_saved_model_dir)
TF-TRT 可以将模型转换为不同的精度: FP32 、 FP16 和 INT8 。在 INT8 的情况下,一个小的校准数据集需要通过网络来确定最佳量化参数。当您将一个模型从 FP32 转换为 INT8 时, TF-TRT 在图灵生成 T4 GPU 上提供了高达 11 倍的推理加速。有关 TF-TRT 的更多信息,请参见 GTC 2020 : TensorRT 用 TensorFlow 2 . 0 推断 。
当您将模型转换为安培上的 FP32 时, TF-TRT 采用的内部数学模式是 TF32 ,不需要任何代码干预。
TensorFlow 1 . 15 . 2 入门
NVIDIA TensorFlow 1.15.2 从 20.06 版开始提供,可以作为 NGC Docker 映像或通过 pip wheel 包提供
拉出 NGC Docker 映像
NVIDIA TensorFlow 版本可以通过拖动 NGC Docker 容器映像轻松访问。使用以下命令:
docker pull nvcr.io/nvidia/tensorflow:20.06-tf1-py3
此 Docker 容器映像包含所有必需的 TensorFlow – GPU 依赖项,例如 CUDA 、 cuDNN 和 TensorRT 。它还包括用于多节点训练的 NCCL 和 Horovod 库,以及用于加速数据预处理和加载的 NVIDIA DALI 。
安装 pip 车轮组件
NVIDIA TensorFlow 1 . 15 . 2 从 20 . 06 版本开始也可以通过一个车轮组件安装。当你使用这种安装方法时, NVIDIA TensorFlow 只需要 Ubuntu 的裸机环境,比如 Ubuntu18 . 04 ,或者一个最小的 Docker 容器,比如 ubuntu : 18 . 04 。此外, NVIDIA 图形驱动程序也必须可用,您应该能够调用 nvidia-smi 来检查 GPU 的状态。 20 . 06 版本中 NVIDIA TensorFlow 1 . 15 . 2 所需的所有其他依赖项都由车轮组件安装。
要安装的基本软件
无论您是在裸金属上还是在容器中,您可能需要执行以下操作:
apt update apt install -y python3-dev python3-pip git pip3 install --upgrade pip setuptools requests
虚拟环境
有些人使用虚拟环境来隔离 pip 包与冲突,概念上,它类似于 Docker 映像,但本质上是一个带有目标搜索路径的独立安装目录。
要设置虚拟环境:
pip install -U virtualenv virtualenv --system-site-packages -p python3 /venv
要启动虚拟环境:
source /venv/bin/activate
安装 TensorFlow 车轮的索引
需要安装此索引,以便 pip 知道可以访问 NVIDIA 网站获取车轮。否则, pip 默认为 PyPI . org 网站. 使用以下命令:
pip install nvidia-pyindex
安装 TensorFlow 车轮
使用本软件即表示您同意遵守软件附带的许可协议的条款。如果您不同意许可协议的条款,请不要使用本软件。
使用以下命令:
pip install nvidia-tensorflow[horovod]
验证是否安装了软件包:
pip list | grep nvidia
输出如下:
nvidia-cublas 11.1.0.213 nvidia-cuda-cupti 11.0.167 nvidia-cuda-nvcc 11.0.167 nvidia-cuda-nvrtc 11.0.167 nvidia-cuda-runtime 11.0.167 nvidia-cudnn 8.0.1.13 nvidia-cufft 10.1.3.191 nvidia-curand 10.2.0.191 nvidia-cusolver 10.4.0.191 nvidia-cusparse 11.0.0.191 nvidia-dali 0.22.0 nvidia-dali-tf-plugin 0.22.0 nvidia-horovod 0.19.1 nvidia-nccl 2.7.5 nvidia-pyindex 1.0.0 nvidia-tensorflow 1.15.2+nv20.6 nvidia-tensorrt 7.1.2.8
验证 TensorFlow 加载:
python -c 'import tensorflow as tf; print(tf.__version__)'
输出应为:
1.15.2
验证 TensorFlow 是否看到 GPU :
python -c "import tensorflow as tf; print('Num GPUs Available: ', len(tf.config.experimental.list_physical_devices('GPU')))"
输出应如下所示:
2020-05-16 22:03:35.428277: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1639] Found device 0 with properties: name: Tesla V100-SXM2-16GB major: 7 minor: 0 memoryClockRate(GHz): 1.53
绩效基准
在这一节中,我们将讨论 TF32 在 NVIDIA A100 上的准确性和性能,并与 FP32 和 AMP 混合精度训练进行比较,在 NVIDIA TensorFlow 1 . 15 . 2 NGC 容器中运行。
TF32 精度
对于使用 FP16 或 BF16 混合精度成功训练的任何网络, TF32 匹配 FP32 结果。我们已经尝试了大量的网络体系结构,但是还没有看到例外。
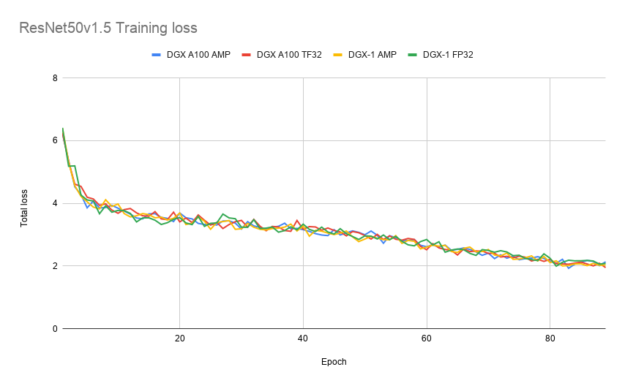
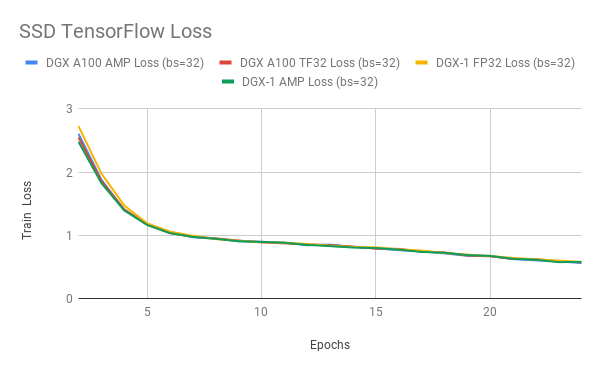
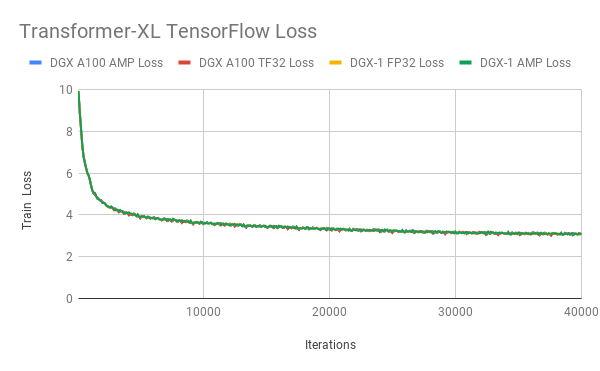
图 4-6 显示了使用 TF32 、 FP32 和 AMP 进行训练时 ResNet50 、 SSD 和 Transformer XL 的训练损耗曲线。 TF32 在稳定性和最终精度方面产生了可比的训练曲线。这些结果可以使用 NVIDIA 深度学习示例 上的模型脚本重现。
性能: TF32 on NVIDIA A100
图 7 显示了在 A100 上使用 TF32 进行培训时观察到的加速情况,而 V100 上的 FP32 则是在各种网络架构上进行的。我们观察到,典型的吞吐量加速高达 6X ,同时收敛到相同的最终精度。
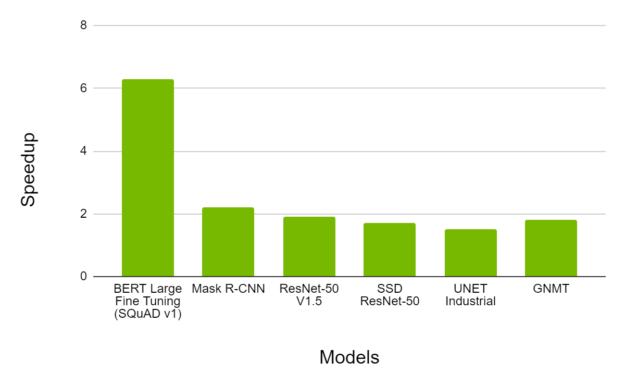
性能: FP16 on NVIDIA A100
带 FP16 的 AMP 仍然是 A100 上 DL 培训的最具性能的选项。图 8 显示,对于各种型号, A100 上的 AMP 提供了比 V100 上的 AMP 高 4 . 5 倍的吞吐量加速,同时收敛到相同的最终精度。
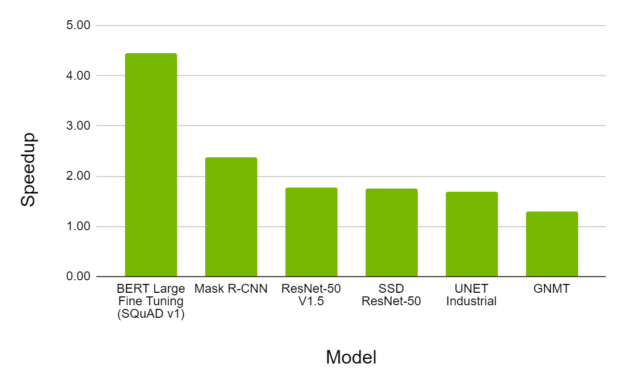
行动号召
NVIDIA A100 GPU 具有先进的功能,为所有 DL 培训工作负载提供了健康的加速。
您可以尝试使用 NVIDIA 深度学习示例 从 20 . 06 开始的 NVIDIA TensorFlow 1 . 15 . 2 ,体验一下 TF32 、 XLA 和 TensorFlow – TensorRT 集成在安培发生器 NVIDIA A100 GPU 上的好处。 NVIDIA TensorFlow 可从 T ensorFlow NGC 容器 版本 20 . 06 获得,并在 https://github.com/NVIDIA/tensorflow 上作为开放源代码发布。