Posts by Vinh Nguyen
生成式人工智能/大语言模型
2024年 3月 14日
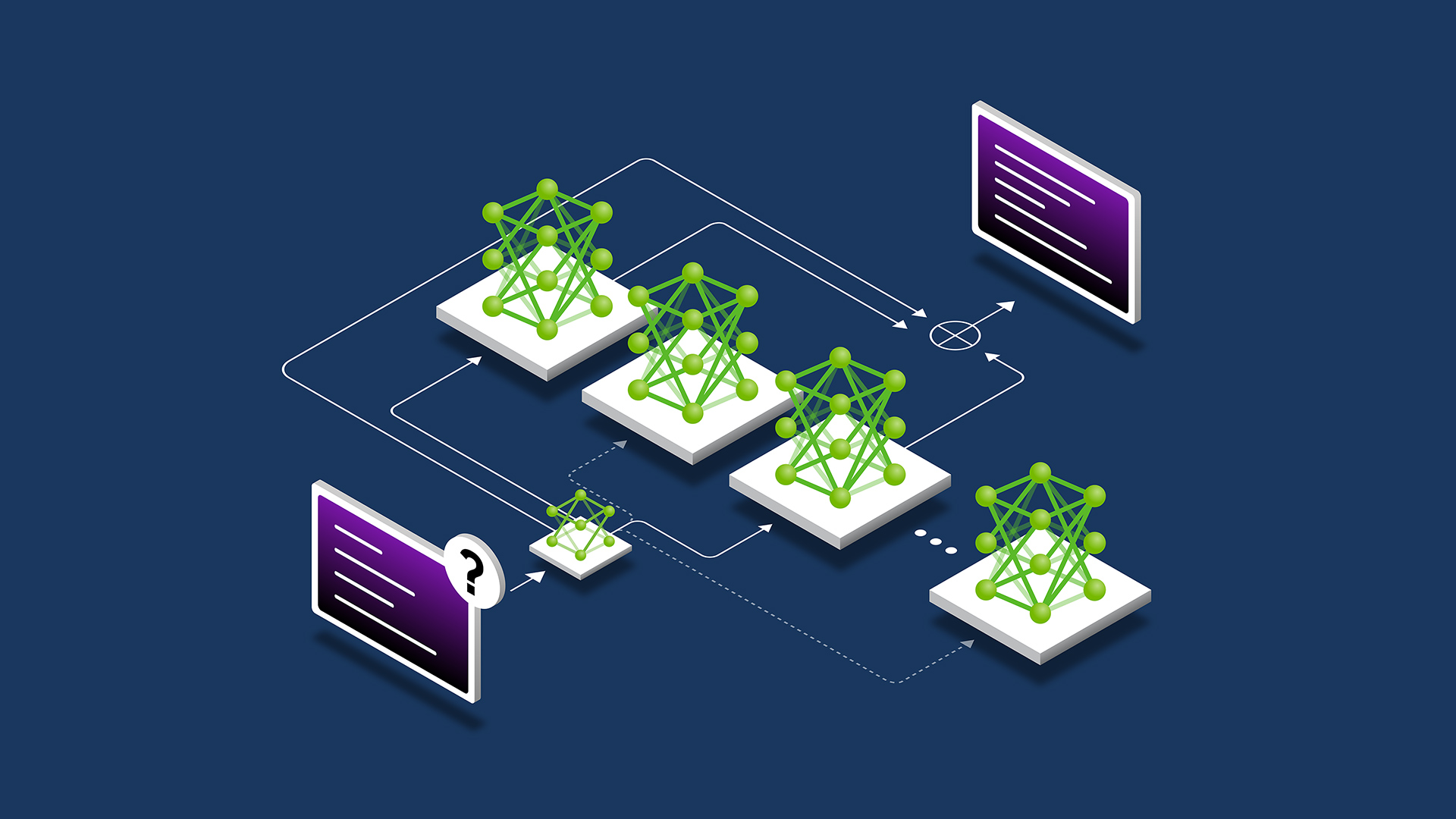
在 LLM 架构中应用多专家模型
多专家模型 (MoE) 大型语言模型 (LLM) 架构最近出现了,无论是在 GPT-4 等专有 LLM 中,还是在开源版本的社区模型中,
3 MIN READ
生成式人工智能/大语言模型
2023年 11月 30日
使用 NVIDIA 检索 QA 嵌入模型构建企业检索增强生成应用
大型语言模型 (LLM) 对人类语言和编程语言的深刻理解正在改变 AI 格局。对于新一代企业生产力应用程序而言,它们至关重要,
3 MIN READ


对话式人工智能/自然语言处理
2022年 10月 28日
为新语言创建的 NVIDIA Riva ASR 服务
Speech AI 是智能系统使用语音接口与用户进行通信的能力,语音接口在日常生活中已变得无处不在。人们经常通过语音与智能家居设备、
3 MIN READ
对话式人工智能/自然语言处理
2022年 8月 3日
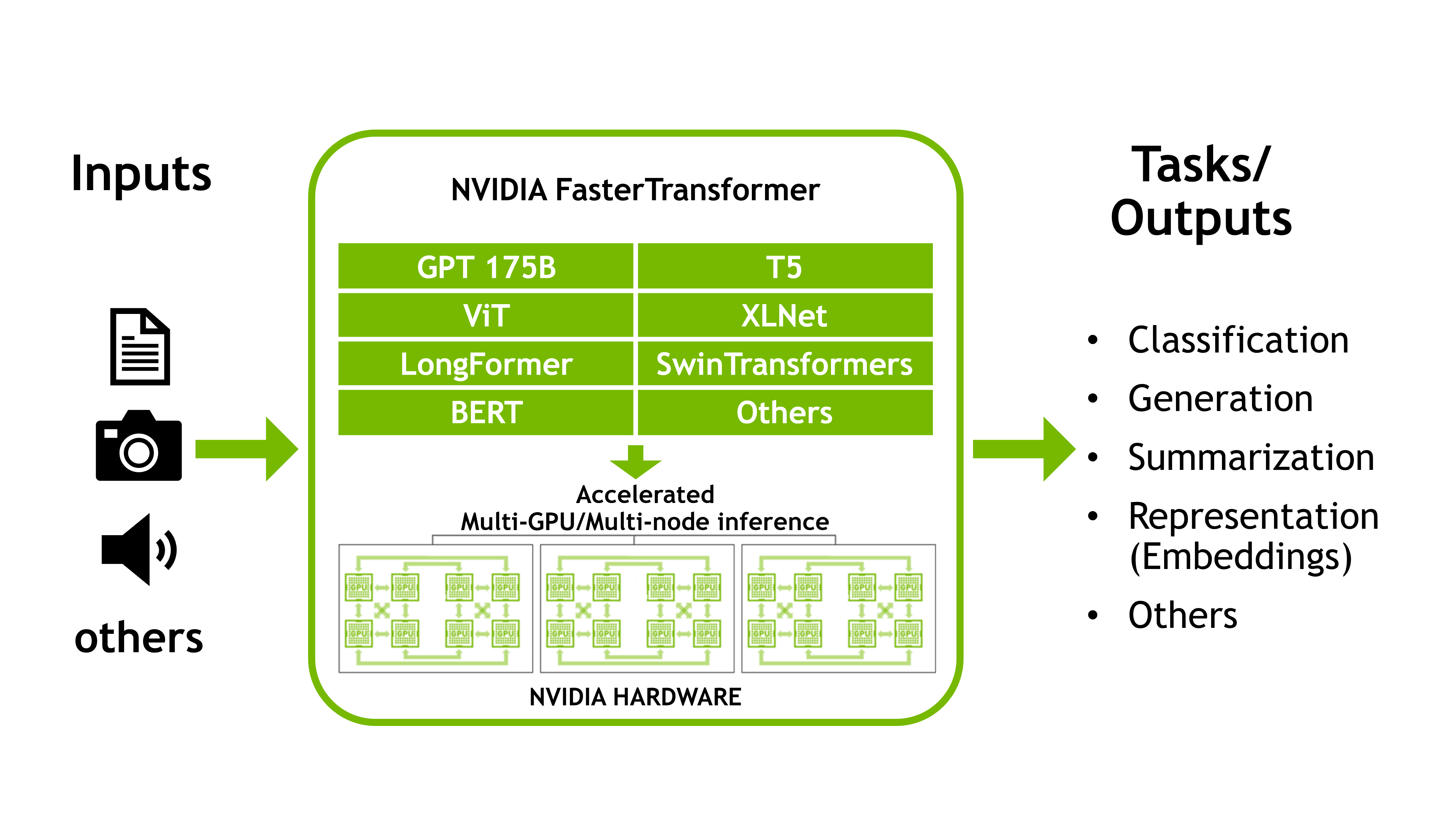
使用 FasterTransformer 和 Triton 推理服务器加速大型 Transformer 模型的推理
这是讨论 NVIDIA FasterTransformer 库的两部分系列的第一部分,
3 MIN READ
对话式人工智能/自然语言处理
2022年 8月 3日
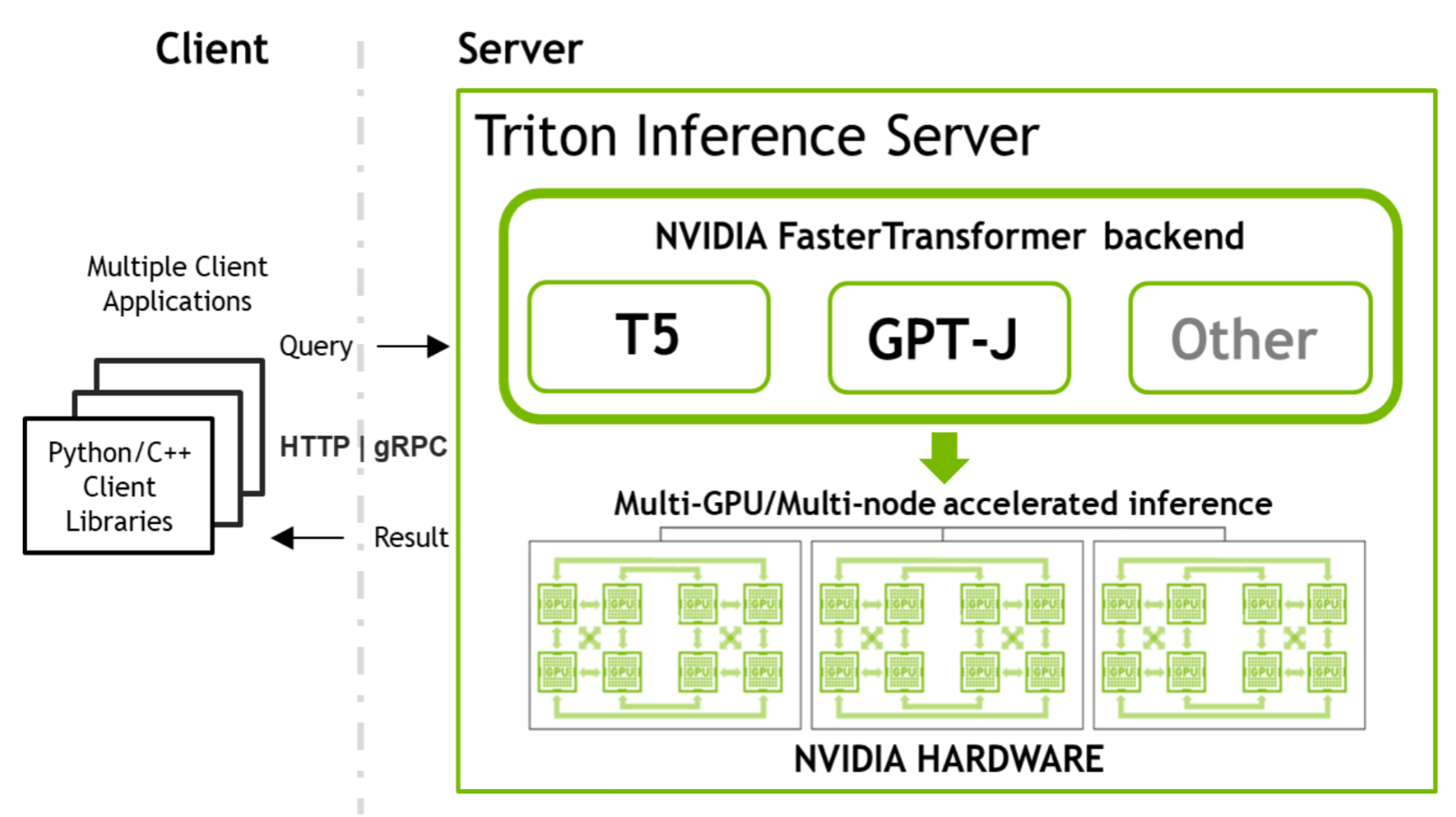
使用 FasterTransformer 和 Triton 推理服务器部署 GPT-J 和 T5
这是关于 NVIDIA 工具的两部分系列的第二部分,这些工具允许您运行大型Transformer模型以加速推理。
5 MIN READ