
레스토랑에서 주문을 받고 음식을 제공하는 것부터 함께 포커를 플레이하는 것까지, 서비스 로봇은 점점 더 보편화되고 있습니다. 전 세계의 병원, 공항 및 소매점에서 이러한 서비스 로봇을 찾을 수 있습니다.
Gartner에 따르면, 지능, 사회적 상호 작용, 인간 증강 기능에서의 스마트 로봇 발전으로 인해 2030년까지 인간의 80%가 매일 스마트 로봇과 교류하게 될 것이며, 이는 현재의 10% 미만에서 현격히 증가한 수치입니다.
인간을 빠르게 이해하고 인간의 말을 모방할 수 있는 정확한 음성 AI 또는 음성 AI 인터페이스는 서비스 로봇의 사용 편의성에서 매우 중요합니다. 개발자는 자동 음성 인식(ASR) 및 텍스트 음성 변환(TTS)을 서비스 로봇과 통합하여 자연어로 인간의 질문을 이해하고 그에 응답하는 것과 같은 필수 기술을 지원하고 있습니다. 이러한 음성 기반 기술이 음성 AI를 구성합니다.
이 게시물에서는 서비스 로봇 애플리케이션에서 ASR 및 TTS를 사용하는 방법을 설명합니다. 음성 AI 소프트웨어 도구를 사용하여 로봇이 배포되는 위치에 따라 업계별 전문 용어, 언어 및 방언에 대해 맞춤 설정하는 방법을 상세히 설명합니다.
서비스 로봇 애플리케이션에 음성 AI를 추가하는 이유는 무엇입니까?
서비스 로봇은 물리적 세계에서 작동한다는 점을 제외하면 메타버스의 디지털 인간과 같습니다. 이러한 서비스 로봇은 창고 근로자를 지원하고, 인간의 지시에 따라 위험한 작업을 수행하고, 비대면 서비스가 필요한 활동을 지원할 수 있습니다. 예를 들어, 서비스업에서의 서비스 로봇은 손님을 맞이하고, 가방을 들어 주고, 주문을 받을 수 있습니다.
이러한 모든 서비스 로봇이 인간과 같은 방식으로 이해하고 대응하려면 개발자는 실시간으로 실행되는 매우 정확한 음성 AI를 통합해야 합니다.
음성 AI 지원 서비스 로봇 애플리케이션의 예시
오늘날 서비스 로봇은 다양한 업계에서 사용되고 있습니다.
식당
온라인 음식 배달 서비스는 전 세계적으로 인기가 높아지고 있습니다. 증가하는 고객 수요를 품질 저하 없이 처리하기 위해 서비스 로봇은 고객을 대면하여 주문을 받거나 음식을 배달하는 등 직원들의 작업을 지원할 수 있습니다.
병원
병원에서 서비스 로봇은 환자 관련 작업을 처리하여 환자 치료 팀을 지원하고 역량을 강화할 수 있습니다. 예를 들어, 음성 AI 지원 서비스 로봇은 환자와 공감대를 형성하여 친구가 되어 주거나 정신 건강 상태를 개선하는 데 도움을 줄 수 있습니다.
주변 보조 생활(ASL)
주변 보조 생활 환경에서 기술은 노인 또는 취약 계층 성인의 독립과 안전을 지원하는 데 주로 사용됩니다. 서비스 로봇은 한 위치에서 다른 위치로 음식 트레이를 운반하거나 스마트 로봇 알약 디스펜서를 사용하여 약물을 적시에 관리하는 등의 일상 활동을 지원할 수 있습니다. 음성 AI 기술을 사용하면 서비스 로봇은 정서적 지원도 제공할 수 있습니다.
서비스 로봇 레퍼런스 아키텍처
서비스 로봇은 다양한 방법으로 기업이 품질 보증을 개선하고 생산성을 높일 수 있도록 지원합니다.
- 레스토랑이나 제조 환경에서 일상적인 반복 작업을 수행하여 일선 근로자 지원
- 소매점에서 고객이 원하는 품목을 찾을 수 있도록 지원
- 병원에서 환자 헬스케어 서비스를 제공하는 의사와 간호사 지원
이러한 환경에서는 로봇이 사용자가 전달하는 내용을 정확하게 처리하고 이해할 수 있어야 합니다. 특히 병원과 같이 위험하거나 심각한 피해가 발생할 수 있는 상황에서는 더욱 그렇습니다. 인간과 자연스럽게 대화할 수 있는 서비스 로봇은 애플리케이션에 대한 긍정적인 사용자 경험에도 기여합니다.
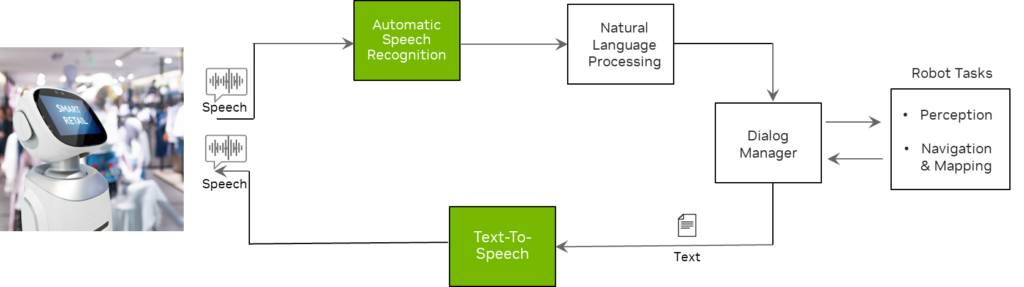
그림 1은 서비스 로봇이 음성 인식을 사용하여 사용자의 말을 이해하고 TTS를 통해 합성 음성으로 사용자에게 응답하는 것을 보여줍니다. NLP 및 대화 관리자와 같은 다른 구성 요소는 서비스 로봇이 컨텍스트를 이해하고 사용자 질문에 대한 적절한 답변을 생성하는 데 사용됩니다.
또한 인지, 탐색 및 매핑과 같은 로봇 작업에서 모듈은 로봇이 물리적 환경을 이해하고 올바른 방향으로 움직이도록 지원합니다.
서비스 로봇에 대한 음성 사용자 인터페이스
음성 사용자 인터페이스에는 자동 음성 인식과 텍스트 음성 변환이라는 두 가지 주요 구성 요소가 포함됩니다. 음성 텍스트 변환이라고도 하는 자동 음성 인식은 원시 음성을 텍스트로 변환하는 과정입니다. 음성 합성이라고도 하는 텍스트 음성 변환은 텍스트를 인간이 말하는 것 같은 음성으로 변환하는 과정입니다.
음성 AI 파이프라인 개발에는 어려움이 존재합니다. 예를 들어, 서비스 로봇이 레스토랑에 배치되면 말차, 카푸치노, 리스트레토 같은 단어를 이해할 수 있어야 합니다. 게다가 이러한 애플리케이션과 상호 작용하는 사람들 대부분이 개방된 공간에 있기 때문에 시끄러운 환경에서도 전사할 수 있어야 합니다.
로봇은 말하는 내용을 이해하는 데서 그치지 않고 이러한 단어를 올바르게 말할 수 있어야 합니다. 또한 각 업계에는 자체 용어가 존재하는데, 로봇은 여기에도 실시간으로 이해하고 대응해야 합니다.
자동 음성 인식
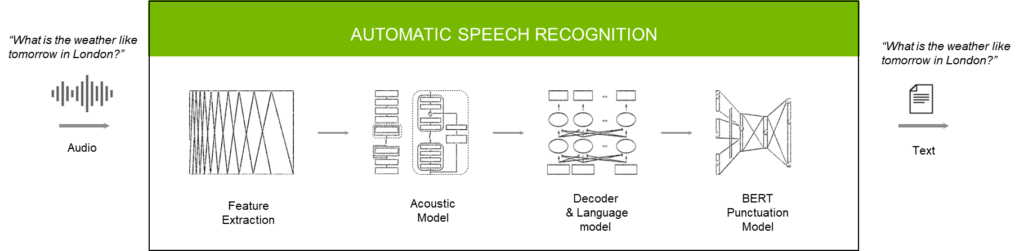
ASR 파이프라인에서 각 모델 또는 모듈의 역할은 다음과 같습니다.
- 특성 추출기는 원시 오디오를 스펙트로그램 또는 멜 스펙트로그램으로 변환합니다.
- 음향 모델은 이러한 스펙트로그램으로 각 시간 단계마다 문자 또는 단어의 확률을 가진 행렬을 생성합니다.
- 디코더와 언어 모델은 이러한 문자/단어를 트랜스크립트에 결합합니다.
- 구두점 및 대문자 사용 모델은 올바른 위치에 쉼표, 마침표, 물음표 등의 항목을 적용하여 가독성을 높입니다.
텍스트 음성 변환
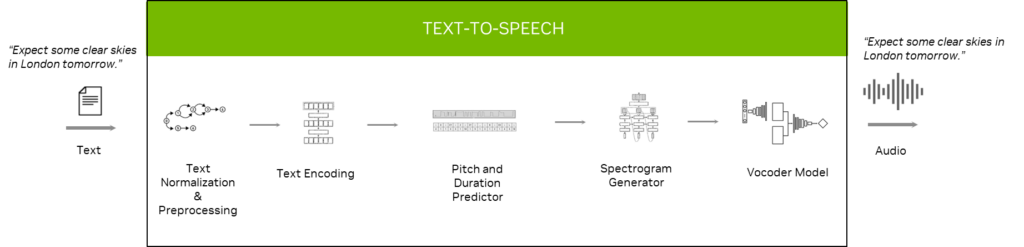
TTS 파이프라인에서 각 모델 또는 모듈의 역할은 다음과 같습니다.
- 텍스트 정규화 및 사전 처리 단계에서 텍스트는 구두화된 형태로 변환됩니다. 예: “10:00에” -> “10시에”
- 텍스트 인코딩 모듈은 텍스트를 인코딩된 벡터로 변환합니다.
- 높낮이 예측은 특정 단어의 높낮이 정도를 예측하고 지속 시간 예측은 문자나 단어를 발음하는 데 걸리는 시간을 예측합니다.
- 스펙트로그램 생성기는 인코딩된 벡터 및 기타 지원 벡터를 입력으로 사용하여 스펙트로그램을 생성합니다.
- 보코더 모델은 스펙트로그램을 입력으로 받아들여 인간이 말하는 것 같은 음성을 출력합니다.
음성 AI 소프트웨어 제품군
NVIDIA는 엔드 투 엔드 음성 AI 파이프라인을 구축하는 데 도움이 되는 다양한 데이터세트, 도구 및 SDK를 제공합니다. 업계별 전문 어휘, 언어 및 방언에 맞게 파이프라인을 맞춤 설정하고 밀리초 단위로 실행하여 자연스럽고 매력적인 상호 작용을 할 수 있습니다.
데이터세트
NVIDIA는 음성 AI 기술을 대중화하고 다양화하기 위해 Mozilla Common Voice(MCV)와 협업을 진행했습니다. MCV는 자원자가 음성 지원 기술을 교육하는 데 사용할 수 있는 공공 데이터세트에 음성 데이터를 기부하는 크라우드 소싱 프로젝트입니다. MCV에서 다양한 언어 오디오 데이터세트를 다운로드하여 ASR 및 TTS 모델을 개발할 수 있습니다.
또한 NVIDIA는 교육 데이터의 원스톱 숍인 Defined.ai와 협업을 진행했습니다. 음성 AI 모델에 사용하기 위해 여러 분야, 언어 및 억양의 오디오 및 음성 교육 데이터를 다운로드할 수 있습니다.
사전 학습된 모델
NGC는 다양한 개방형 및 독점 데이터세트에 대해 트레이닝을 거친 여러 사전 학습된 모델을 제공합니다. 모든 모델은 수십만 시간 동안 NVIDIA DGX 서버에서 최적화 및 트레이닝되었습니다.
정확도가 높고 사전 학습된 모델을 관련 데이터세트에서 미세 조정하여 정확도를 더욱 높일 수 있습니다.
오픈 소스 도구
오픈 소스 도구를 찾고 있는 경우 NVIDIA에서는 최첨단 AI 음성 및 언어 모델을 구축하고 트레이닝하는 오픈 소스 프레임워크인 NeMo를 제공합니다. NeMo는 PyTorch 및 PyTorch Lightning을 기반으로 구축되어 이미 익숙한 모듈을 간편하게 개발하고 통합할 수 있습니다.
음성 AI SDK
무료 GPU 가속 음성 AI SDK인 NVIDIA Riva를 사용하여 완전한 맞춤 설정이 가능한 실시간 AI 파이프라인을 구축 및 배포하세요. Riva는 NGC를 통해 고도로 정확하며 사전 학습된 최첨단 모델을 다음 언어로 제공합니다.
- 영어
- 스페인어
- 중국어
- 힌디어
- 러시아어
- 한국어
- 독일어
- 프랑스어
- 포르투갈어
일본어, 아랍어, 이탈리아어가 곧 출시됩니다.
NeMo를 사용하면 실시간 실행을 위하여 업계별 전문 용어, 언어, 방언 및 억양에 대해 사전 학습된 모델과 최적화된 음성 AI 기술을 미세 조정할 수 있습니다.
모든 클라우드, 온프레미스, 엣지 및 임베디드 디바이스에서 스트리밍 또는 오프라인으로 Riva 기술을 배포할 수 있습니다.
로보틱스 애플리케이션용 임베디드에서 Riva 음성 AI 기술 실행
이 섹션에서는 임베디드 디바이스에서 Riva를 통해 즉시 ASR 및 TTS 기술을 실행하는 방법을 확인할 수 있습니다. Riva를 사용하면 정확도와 성능을 향상하기 위해 도메인별 데이터세트에서 모델을 맞춤 설정하거나 미세 조정할 수도 있습니다.
스트리밍 및 오프라인 모드 모두에서 Riva 음성 AI 기술을 실행할 수 있습니다. 먼저 임베디드에서 Riva 서버를 설정하고 실행합니다.
전제 조건
- NGC 액세스.
- 명령줄 인터페이스(CLI)에서 모든 단계를 수행하여 ngc 명령을 실행합니다.
- NVIDIA Jetson Orin, NVIDIA Jetson AGX Xavier 또는 NVIDIA Jetson NX Xavier 액세스.
- Jetson 플랫폼 NVIDIA JetPack 버전 5.0.2.
자세한 내용은 지원 사항을 참조하세요.
서버 설정
다음 명령을 실행하여 NGC에서 스크립트를 다운로드합니다.
ngc registry resource download-version nvidia/riva/riva_quickstart_arm64:2.7.0Riva 서버 초기화:
bash riva_init.shRiva 서버 시작:
bash riva_start.sh최신 단계에 대한 자세한 내용은 빠른 시작 가이드를 참조하세요.
C++ ASR 클라이언트 실행
임베디드용 Riva 서버는 추론을 수행하는 데 원활하게 사용할 수 있는 샘플 클라이언트와 함께 제공됩니다.
ASR 스트리밍에 대해 다음 명령을 실행합니다.
riva_streaming_asr_client --audio_file=/opt/riva/wav/en-US_sample.wav업계별 전문 용어, 언어, 방언 및 억양에 대해 Riva ASR 모델 및 파이프라인을 맞춤 설정하는 것에 대한 자세한 내용은 Riva 문서에서 모델 개요 지침을 참조하세요.
C++ TTS 클라이언트 실행
임베디드 Riva TTS 클라이언트의 경우 다음 명령을 실행하여 오디오 파일을 합성합니다.
riva_tts_client --voice_name=English-US.Female-1 \
--text="Hello, this is a speech synthesizer." \
--audio_file=/opt/riva/wav/output.wav도메인별 데이터세트에서 TTS 모델 및 파이프라인을 맞춤 설정하는 것에 대한 자세한 내용은 Riva 사용 설명서의 모델 개요를 참조하세요.
음성 AI 애플리케이션 개발용 리소스
음성 AI는 서비스 로봇 및 기타 인터랙티브 애플리케이션이 미묘한 인간의 언어를 이해하고 쉽게 반응할 수 있도록 지원합니다.
콜센터에서 근무하는 실제 사람부터 모든 업계의 서비스 로봇에 이르기까지 모든 존재의 역량을 강화하고 있습니다. 음성 AI 기술이 실제로 음료를 가져올 수 있는 로봇 개와 어떻게 통합되었는지 이해하려면 음성 AI 로보틱스를 위한 로우 코드 구성 요소를 참조하세요.
또는 음성 AI 게시물을 검색하여 음성 AI 개념, 음성 인식 배포 문제와 팁, 고유한 ASR 애플리케이션에 대해 알아보세요.
또한 엔드 투 엔드 음성 AI 파이프라인 등의 개발자 E-Book에 액세스하여 음성 AI 파이프라인 및 음성 AI 애플리케이션 구축 모델과 모듈에 대해 자세히 알아보고 애플리케이션을 위한 실시간 음성 AI 파이프라인을 구축하고 배포하는 방법에 대한 인사이트를 얻을 수 있습니다.
이 블로그에 열거된 SDK의 대부분의 독점 액세스, 얼리 액세스, 기술 세션, 데모, 교육 과정, 리소스는 NVIDIA 개발자 프로그램 회원은 무료로 혜택을 받으실 수 있습니다. 지금 무료로 가입하여 NVIDIA의 기술 플랫폼에서 구축하는 데 필요한 도구와 교육에 액세스하시고 여러분의 성공을 가속화 하세요.