
데이터 라벨링과 모델 트레이닝은 AI/ML 인프라를 구축할 때 팀이 직면하는 가장 중요한 과제로 꾸준히 꼽히고 있습니다. 두 가지 모두 ML 애플리케이션 개발 프로세스에서 필수적인 단계이며, 올바르게 수행하지 않으면 부정확한 결과와 성능 저하로 이어질 수 있습니다. 자세한 내용은 AI 인프라 얼라이언스의 2022년 AI 인프라 생태계 보고서를 참조하세요.
데이터 라벨링은 전체 데이터 세트에 완전히 레이블을 지정하는 모든 형태의 지도 학습에 필수적입니다. 또한 라벨링된 데이터의 작은 집합을 나머지 데이터 집합의 라벨링을 프로그래밍 방식으로 자동화하도록 설계된 알고리즘과 결합하는 준지도 학습의 핵심 요소이기도 합니다. 라벨링은 머신 러닝의 가장 발전된 분야 중 하나인 컴퓨터 비전에 필수적입니다. 그 중요성에도 불구하고 라벨링은 분산된 인력 팀을 확장해야 하기 때문에 속도가 느립니다.
모델 학습은 라벨링과 함께 머신 러닝의 또 다른 주요 병목 현상입니다. 훈련은 기계가 복잡한 계산을 완료할 때까지 기다려야 하기 때문에 속도가 느립니다. 따라서 팀원들은 네트워킹, 분산 시스템, 스토리지, 특수 프로세서(GPU 또는 TPU), 클라우드 관리 시스템(Kubernetes 및 Docker)에 대해 잘 알고 있어야 합니다.
NVIDIA TAO 툴킷이 포함된 슈퍼브 AI 제품군
Superb AI는 컴퓨터 비전 팀이 고품질 트레이닝 데이터세트를 제공하는 데 걸리는 시간을 획기적으로 단축할 수 있는 새로운 방법을 도입했습니다. 이제 팀은 데이터 준비 워크플로우의 대부분을 사람의 라벨러에 의존하는 대신 Superb AI Suite를 사용하여 훨씬 더 시간과 비용 효율적인 파이프라인을 구현할 수 있습니다.
TensorFlow와 PyTorch를 기반으로 구축된 NVIDIA TAO 툴킷은 프레임워크 복잡성을 추상화하여 모델 개발 프로세스를 가속화하는 TAO 프레임워크의 로우코드 버전입니다. TAO 툴킷을 사용하면 전이 학습의 강력한 기능을 사용하여 자체 데이터로 NVIDIA 사전 학습 모델을 미세 조정하고 추론에 최적화할 수 있습니다.
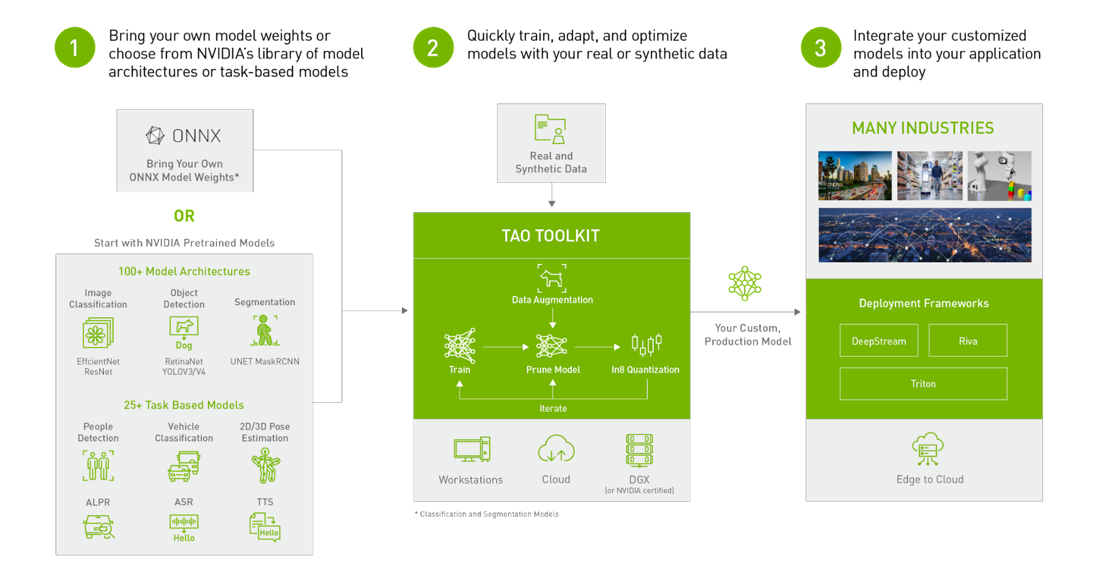
컴퓨터 비전 엔지니어는 Superb AI Suite와 TAO 툴킷을 함께 사용하여 데이터 레이블링 및 모델 트레이닝의 과제를 해결할 수 있습니다. 보다 구체적으로, Suite에서 라벨링된 데이터를 빠르게 생성하고 TAO로 모델을 훈련하여 분류, 감지 또는 세분화 등 특정 컴퓨터 비전 작업을 수행할 수 있습니다.
컴퓨터 비전 데이터 세트 준비하기
이 게시물에서는 Superb AI Suite를 사용하여 TAO Toolkit과 호환되는 고품질 컴퓨터 비전 데이터 세트를 준비하는 방법을 설명합니다. 데이터 세트 다운로드, Suite에서 새 프로젝트 생성, Suite SDK를 통해 프로젝트에 데이터 업로드, Superb AI의 자동 라벨 기능을 사용하여 데이터 세트에 빠르게 라벨 지정, 라벨이 지정된 데이터 세트 내보내기, 데이터 사용을 위한 TAO 툴킷 구성 설정 등의 과정을 안내합니다.
1단계: Suite SDK 시작하기
먼저, superb-ai.com으로 이동하여 계정을 만듭니다. 그런 다음 빠른 시작 가이드에 따라 Suite CLI를 설치하고 인증합니다. 최신 버전의 spb-cli를 설치하고 인증을 위한 Suite 계정 이름/액세스 키를 검색할 수 있어야 합니다.
2단계: 데이터 세트 다운로드
이 튜토리얼에서는 컴퓨터 비전 연구 커뮤니티에서 널리 사용되는 대규모 객체 감지, 분할 및 캡션 데이터 세트인 COCO 데이터 세트를 사용합니다.
이 코드 스니펫을 사용하여 데이터 세트를 다운로드할 수 있습니다. 다운로드-coco.sh라는 파일에 저장하고 터미널에서 bash download-coco.sh를 실행합니다. 이렇게 하면 COCO 데이터세트를 저장하는 데이터/디렉토리가 생성됩니다.
다음 단계는 COCO 유효성 검사 2017 데이터 세트에서 가장 빈번하게 사용되는 5개의 클래스를 샘플링하기 위해 COCO를 Suite SDK 포맷으로 변환하는 것입니다. 이 튜토리얼에서는 바운딩 박스 주석만 처리하지만, Suite는 다각형과 키 포인트도 처리할 수 있습니다.
이 코드 스니펫을 사용하여 변환을 수행할 수 있습니다. convert.py라는 파일에 저장하고 터미널에서 python convert.py를 실행합니다. 이렇게 하면 이미지 이름과 주석에 대한 정보를 저장하는 upload-info.json 파일이 생성됩니다.
3단계: Suite SDK에서 프로젝트 만들기
Suite SDK를 통해 프로젝트를 만드는 것은 진행 중인 작업입니다. 이 튜토리얼에서는 프로젝트 생성을 위한 Superb AI 가이드를 사용하여 웹에서 프로젝트를 만듭니다. 아래 제시된 구성을 따르세요.
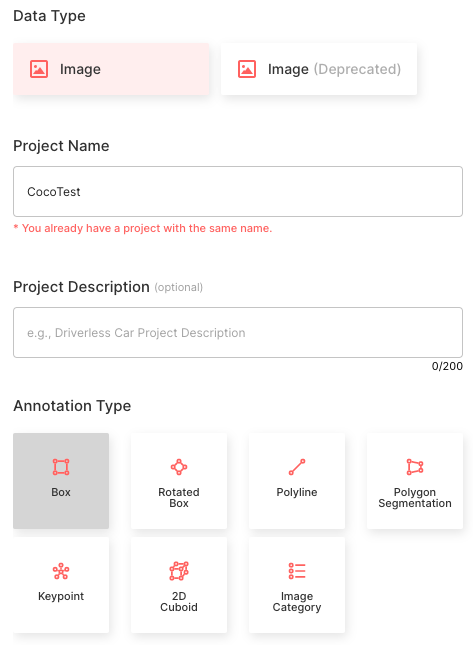
- 이미지 데이터 유형을 선택합니다.
- 프로젝트 이름을 CocoTest로 설정
- 주석 유형을 Bounding Box로 선택
- COCO 클래스 이름과 일치하는 개체 클래스 5개를 생성합니다: [‘person’, ‘car’, ‘chair’, ‘book’, ‘bottle’].
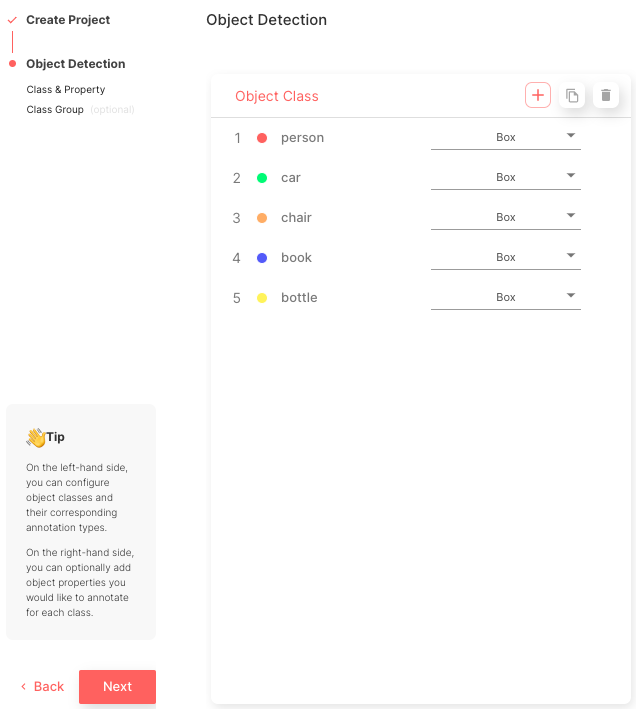
이 과정이 완료되면 그림 5와 같이 메인 프로젝트 페이지를 볼 수 있습니다.
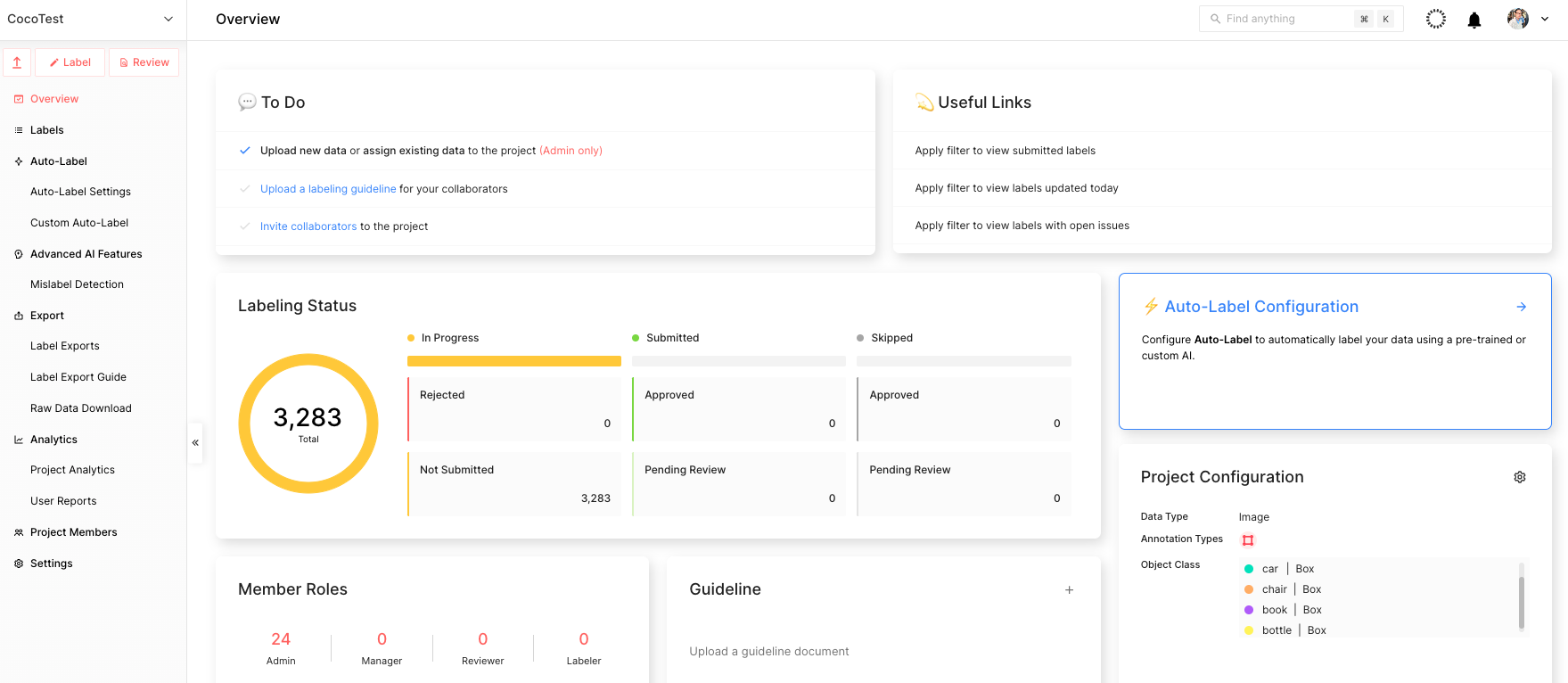
4단계: Suite SDK를 사용하여 데이터 업로드하기
프로젝트 생성을 완료한 후 데이터 업로드를 시작합니다. 이 코드 스니펫을 사용하여 데이터를 업로드할 수 있습니다. upload.py라는 파일에 저장하고 터미널에서 python upload.py --project CocoTest --dataset coco-dataset을 실행합니다.
즉, CocoTest는 프로젝트 이름이고 coco-dataset은 데이터 세트 이름입니다. 그러면 업로드 프로세스가 시작되며, 기기의 처리 능력에 따라 완료하는 데 몇 시간이 걸릴 수 있습니다.
업로드된 데이터 세트는 그림 6과 같이 Suite 웹 페이지를 통해 실시간으로 확인할 수 있습니다.
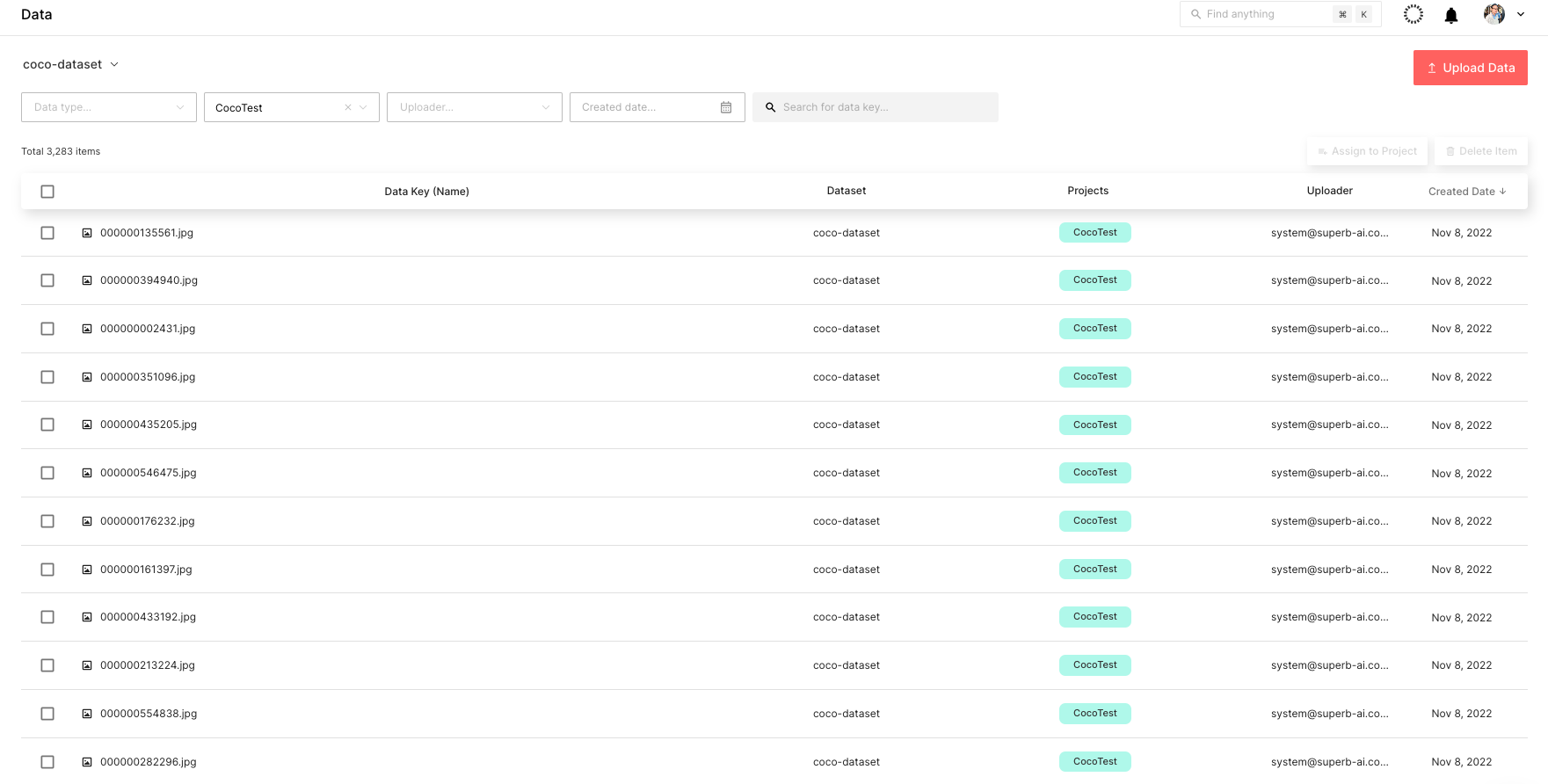
5단계: 데이터 세트에 라벨 지정
다음 단계는 COCO 데이터 세트에 라벨을 붙이는 것입니다. 이 작업을 신속하게 수행하려면 Suite의 강력한 자동화된 라벨링 기능을 사용하면 됩니다. 특히 자동 라벨과 사용자 지정 자동 라벨은 개체를 자동으로 감지하고 라벨을 지정하여 라벨링 효율성을 높일 수 있는 강력한 도구입니다.
자동 라벨은 Superb AI가 개발한 사전 학습된 모델로 100개 이상의 일반적인 개체를 감지하고 라벨을 지정하는 반면, 사용자 지정 자동 라벨은 틈새 개체를 감지하고 라벨을 지정하는 자체 데이터를 사용하여 학습된 모델입니다.
이 튜토리얼의 COCO 데이터는 자동 라벨링이 라벨을 지정할 수 있는 5개의 일반적인 개체로 구성되어 있습니다. 가이드에 따라 자동 라벨을 구성하세요. 기억해야 할 중요한 사항은 자동 라벨링 AI로 MSCOCO Box CAL을 선택하고 개체 이름을 각각의 적용된 개체에 매핑해야 한다는 것입니다. COCO 데이터 세트의 3,283개 라벨을 모두 처리하는 데 약 1시간이 소요될 수 있습니다.
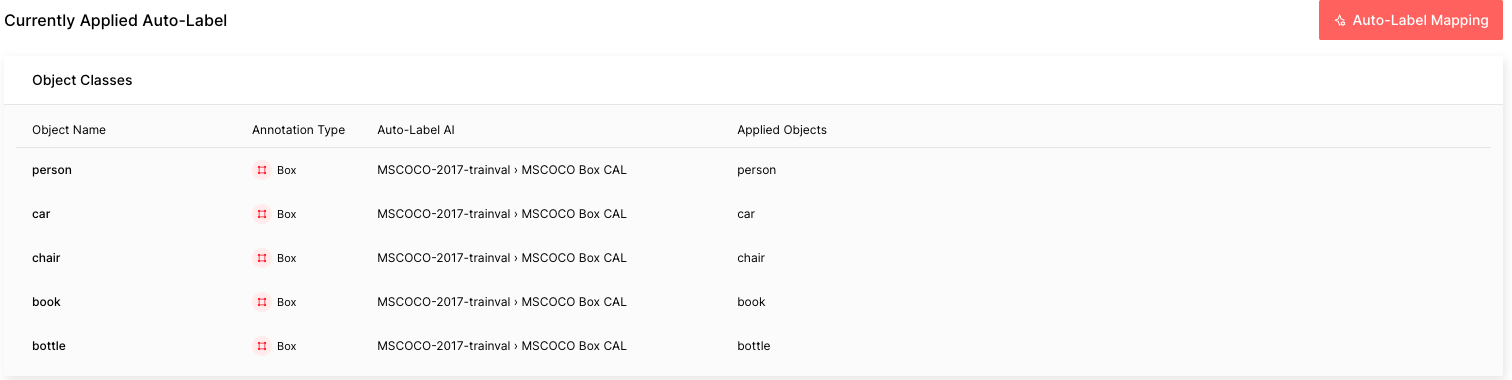
자동 라벨 실행이 완료되면 각 자동 라벨링 작업의 난이도를 빨간색은 어려움, 노란색은 보통, 녹색은 쉬움으로 확인할 수 있습니다. 난이도가 높을수록 자동 라벨링이 해당 이미지에 라벨을 잘못 지정했을 가능성이 높습니다.
이 난이도 또는 예상 불확실성은 작은 물체 크기, 열악한 조명 조건, 복잡한 장면 등과 같은 요소를 기반으로 계산됩니다. 실제 상황에서는 레이블을 난이도별로 쉽게 정렬하고 필터링하여 오류 가능성이 높은 레이블을 우선적으로 검토할 수 있습니다.
6단계: Suite에서 레이블이 지정된 데이터 세트 내보내기
레이블이 지정된 데이터세트를 얻은 후, 레이블을 내보내고 다운로드합니다. 라벨에는 주석 정보만 있는 것이 아닙니다. ML 모델 학습에 라벨을 완전히 사용하려면 프로젝트 구성 및 원시 데이터에 대한 메타 정보와 같은 추가 정보를 알고 있어야 합니다. 이 모든 정보를 주석 파일과 함께 다운로드하려면 먼저 내보내기를 요청하여 Suite 시스템에서 다운로드용 zip 파일을 생성할 수 있도록 합니다. Suite에서 레이블을 내보내고 다운로드하려면 가이드를 따르세요.
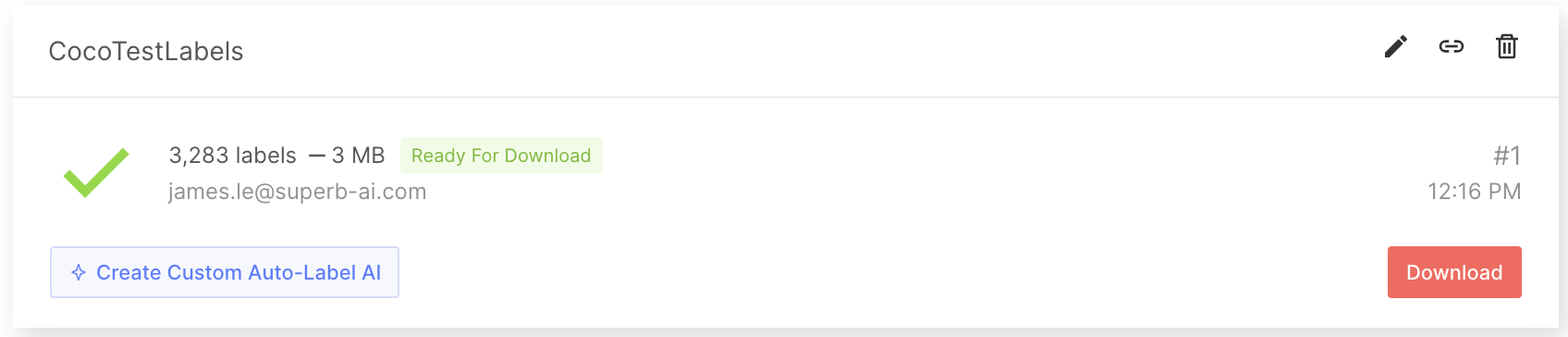
레이블을 내보내면 다운로드할 수 있도록 압축된 zip 파일이 생성됩니다. 내보내기 결과 폴더에는 프로젝트 전체에 대한 일반 정보, 각 라벨에 대한 주석 정보 및 각 데이터 자산에 대한 메타데이터가 포함됩니다. 자세한 내용은 내보내기 결과 형식 설명서를 참조하세요.
7단계: 출력을 COCO 형식으로 변환하기
다음으로, 레이블이 지정된 데이터를 COCO 형식과 같이 TAO 툴킷에 입력할 수 있는 형식으로 변환하는 스크립트를 만듭니다. 이 자습서에서는 COCO 데이터 집합을 사용하므로 데이터는 이미 COCO 형식으로 되어 있습니다. 예를 들어, 아래에서 무작위로 내보낸 레이블의 JSON 파일을 찾을 수 있습니다:
{
"objects": [
{
"id": "7e9fe8ee-50c7-4d4f-9e2c-145d894a8a26",
"class_id": "7b8205ef-b251-450c-b628-e6b9cac1a457",
"class_name": "person",
"annotation_type": "box",
"annotation": {
"multiple": false,
"coord": {
"x": 275.47,
"y": 49.27,
"width": 86.39999999999998,
"height": 102.25
},
"meta": {},
"difficulty": 0,
"uncertainty": 0.0045
},
"properties": []
},
{
"id": "70257635-801f-4cad-856a-ef0fdbfdf613",
"class_id": "7b8205ef-b251-450c-b628-e6b9cac1a457",
"class_name": "person",
"annotation_type": "box",
"annotation": {
"multiple": false,
"coord": {
"x": 155.64,
"y": 40.61,
"width": 98.34,
"height": 113.05
},
"meta": {},
"difficulty": 0,
"uncertainty": 0.0127
},
"properties": []
}
],
"categories": {
"properties": []
},
"difficulty": 1
}8단계: 모델 학습을 위해 레이블이 지정된 데이터 준비하기
다음으로, SuiteDataset을 사용해 Suite에서 COCO 데이터를 모델 개발로 가져옵니다. SuiteDataset은 Suite 내에서 내보낸 데이터 세트를 PyTorch 데이터 파이프라인을 통해 액세스할 수 있게 해줍니다. 아래 코드 스니펫은 훈련 세트에 대한 SuiteDataset 객체 클래스를 인스턴스화합니다.
class SuiteDataset(Dataset):
"""
Instantiate the SuiteDataset object class for training set
"""
def __init__(
self,
team_name: str,
access_key: str,
project_name: str,
export_name: str,
train: bool,
caching_image: bool = True,
transforms: Optional[List[Callable]] = None,
category_names: Optional[List[str]] = None,
):
"""Function to initialize the object class"""
super().__init__()
# Get project setting and export information through the SDK
# Initialize the Python Client
client = spb.sdk.Client(team_name=team_name, access_key=access_key, project_name=project_name)
# Use get_export
export_info = call_with_retry(client.get_export, name=export_name)
# Download the export compressed file through download_url in Export
export_data = call_with_retry(urlopen, export_info.download_url).read()
# Load the export compressed file into memory
with ZipFile(BytesIO(export_data), 'r') as export:
label_files = [f for f in export.namelist() if f.startswith('labels/')]
label_interface = json.loads(export.open('project.json', 'r').read())
category_infos = label_interface.get('object_detection', {}).get('object_classes', [])
cache_dir = None
if caching_image:
cache_dir = f'/tmp/{team_name}/{project_name}'
os.makedirs(cache_dir, exist_ok=True)
self.client = client
self.export_data = export_data
self.categories = [
{'id': i + 1, 'name': cat['name'], 'type': cat['annotation_type']}
for i, cat in enumerate(category_infos)
]
self.category_id_map = {cat['id']: i + 1 for i, cat in enumerate(category_infos)}
self.transforms = build_transforms(train, self.categories, transforms, category_names)
self.cache_dir = cache_dir
# Convert label_files to numpy array and use
self.label_files = np.array(label_files).astype(np.string_)
def __len__(self):
"""Function to return the number of label files"""
return len(self.label_files)
def __getitem__(self, idx):
"""Function to get an item"""
idx = idx if idx >= 0 else len(self) + idx
if idx < 0 or idx >= len(self):
raise IndexError(f'index out of range')
image_id = idx + 1
label_file = self.label_files[idx].decode('ascii')
# Load label information corresponding to idx from the export compressed file into memory
with ZipFile(BytesIO(self.export_data), 'r') as export:
label = load_label(export, label_file, self.category_id_map, image_id)
# Download the image through the Suite sdk based on label_id
try:
image = load_image(self.client, label['label_id'], self.cache_dir)
# Download data in real time using get_data from Suite sdk
except Exception as e:
print(f'Failed to load the {idx}-th image due to {repr(e)}, getting {idx + 1}-th data instead')
return self.__getitem__(idx + 1)
target = {
'image_id': image_id,
'label_id': label['label_id'],
'annotations': label['annotations'],
}
if self.transforms is not None:
image, target = self.transforms(image, target)
return image, target테스트 세트도 비슷한 방식으로 처리합니다. 아래 코드 스니펫은 테스트 세트에 대한 SuiteCocoDataset 객체 클래스를 인스턴스화하여 SuiteDataset을 래핑하여 Torchvision COCOEvaluator와 호환되도록 합니다.
class SuiteCocoDataset(C.CocoDetection):
"""
Instantiate the SuiteCocoDataset object class for test set
(by wrapping SuiteDataset to make compatible with torchvision's official COCOEvaluator)
"""
def __init__(
self,
team_name: str,
access_key: str,
project_name: str,
export_name: str,
train: bool,
caching_image: bool = True,
transforms: Optional[List[Callable]] = None,
category_names: Optional[List[str]] = None,
num_init_workers: int = 20,
):
"""Function to initialize the object class"""
super().__init__(img_folder='', ann_file=None, transforms=None)
# Call the SuiteDataset class
dataset = SuiteDataset(
team_name, access_key, project_name, export_name,
train=False, transforms=[],
caching_image=caching_image, category_names=category_names,
)
self.client = dataset.client
self.cache_dir = dataset.cache_dir
self.coco = build_coco_dataset(dataset, num_init_workers)
self.ids = list(sorted(self.coco.imgs.keys()))
self._transforms = build_transforms(train, dataset.categories, transforms, category_names)
def _load_image(self, id: int):
"""Function to load an image"""
label_id = self.coco.loadImgs(id)[0]['label_id']
image = load_image(self.client, label_id, self.cache_dir)
return image
def __getitem__(self, idx):
"""Function to get an item"""
try:
return super().__getitem__(idx)
except Exception as e:
print(f'Failed to load the {idx}-th image due to {repr(e)}, getting {idx + 1}-th data instead')
return self.__getitem__(idx + 1)그런 다음 SuiteDataset 및 SuiteCocoDataset을 트레이닝 코드에 사용할 수 있습니다. 아래 코드 스니펫은 사용 방법을 보여줍니다. 모델 개발 중에 train_loader로 훈련하고 test_loader로 평가합니다.
train_dataset = SuiteDataset(
team_name=args.team_name,
access_key=args.access_key,
project_name=args.project_name,
export_name=args.train_export_name,
caching_image=args.caching_image,
train=True,
)
test_dataset = SuiteCocoDataset(
team_name=args.team_name,
access_key=args.access_key,
project_name=args.project_name,
export_name=args.test_export_name,
caching_image=args.caching_image,
train=False,
num_init_workers=args.workers,
)
train_loader = DataLoader(
train_dataset, num_workers=args.workers,
batch_sampler=G.GroupedBatchSampler(
RandomSampler(train_dataset),
G.create_aspect_ratio_groups(train_dataset, k=3),
args.batch_size,
),
collate_fn=collate_fn,
)
test_loader = DataLoader(
test_dataset, num_workers=args.workers,
sampler=SequentialSampler(test_dataset), batch_size=1,
collate_fn=collate_fn,
)9단계: NVIDIA TAO 툴킷으로 모델 훈련하기
이제 Suite로 주석이 추가된 데이터를 사용하여 물체 감지 모델을 훈련할 수 있습니다. TAO 툴킷을 사용하면 널리 사용되는 네트워크 아키텍처와 백본을 데이터에 맞게 조정하여 배포를 위해 고도로 최적화되고 정확한 컴퓨터 비전 모델을 훈련, 미세 조정, 정리 및 내보낼 수 있습니다. 이 튜토리얼에서는 TAO에 포함된 객체 감지 모델인 YOLO v4를 선택할 수 있습니다.
먼저 TAO 툴킷 빠른 시작에서 노트북 샘플을 다운로드합니다.
pip3 install nvidia-tao
wget --content-disposition https://api.ngc.nvidia.com/v2/resources/nvidia/tao/tao-getting-started/versions/4.0.1/zip -O getting_started_v4.0.1.zip
$ unzip -u getting_started_v4.0.1.zip -d ./getting_started_v4.0.1 && rm -rf getting_started_v4.0.1.zip && cd ./getting_started_v4.0.1그런 다음, 아래 코드를 사용해 노트북을 시작합니다:
$ jupyter notebook --ip 0.0.0.0 --port 8888 --allow-root로컬 호스트에서 인터넷 브라우저를 열고 URL로 이동합니다:
http://0.0.0.0:8888YOLOv4 모델을 만들려면 notebooks/tao_launcher_starter_kit/yolo_v4/yolo_v4.ipynb를 열고 노트북 지침에 따라 모델을 훈련합니다.
결과를 바탕으로 지표 목표를 달성할 때까지 모델을 미세 조정합니다. 원하는 경우 이 단계에서 자신만의 능동 학습 루프를 만들 수 있습니다. 실제 시나리오에서는 실패한 예측의 샘플을 쿼리하고, 새로운 샘플 데이터 배치에 주석을 달 수 있는 라벨러를 지정하고, 새로 라벨링된 학습 데이터로 모델을 보완합니다. Superb AI Suite는 모델 성능을 반복적으로 개선할 때 후속 모델 개발 라운드에서 데이터 수집 및 주석을 추가하는 데 도움을 줄 수 있습니다.
최근 출시된 TAO 툴킷 4.0을 사용하면 AI 전문 지식이 없어도 더욱 쉽게 시작하고 정확도 높은 모델을 만들 수 있습니다. AutoML로 하이퍼파라미터를 자동으로 미세 조정하고, 다양한 클라우드 서비스에 TAO 툴킷을 턴키 방식으로 배포하고, 타사 MLOP 서비스와 TAO 툴킷을 통합하고, 새로운 트랜스포머 기반 비전 모델(CitySemSegformer, Peoplenet Transformer)을 살펴볼 수 있습니다.
결론
컴퓨터 비전의 데이터 라벨링에는 여러 가지 고유한 문제가 발생할 수 있습니다. 라벨링이 필요한 데이터의 양이 많기 때문에 프로세스가 어렵고 비용이 많이 들 수 있습니다. 또한 이 프로세스는 주관적일 수 있으므로 대규모 데이터 세트에서 일관된 고품질의 라벨링된 결과물을 얻기가 어렵습니다.
많은 알고리즘과 하이퍼파라미터에 튜닝과 최적화가 필요하기 때문에 모델 학습도 어려울 수 있습니다. 이 프로세스에는 데이터와 모델에 대한 깊은 이해와 최상의 결과를 얻기 위한 상당한 실험이 필요합니다. 또한 컴퓨터 비전 모델은 훈련에 대규모 컴퓨팅 성능이 필요한 경향이 있어 제한된 예산과 일정으로 훈련하기가 어렵습니다.
Superb AI Suite를 사용하면 고품질 컴퓨터 비전 데이터세트를 수집하고 레이블을 지정할 수 있습니다. NVIDIA TAO 툴킷을 사용하면 사전 훈련된 컴퓨터 비전 모델을 최적화할 수 있습니다. 이 두 가지를 함께 사용하면 품질 저하 없이 컴퓨터 비전 애플리케이션 개발 시간을 크게 단축할 수 있습니다.
더 자세한 정보를 원하시나요? 확인해 보세요:
Superb AI 소개
Superb AI는 컴퓨터 비전 데이터 세트를 그 어느 때보다 빠르고 쉽게 구축, 관리 및 큐레이션할 수 있는 학습 데이터 플랫폼을 제공합니다. 라벨링 및 품질 보증을 위한 적응형 자동화 모델에 특화된 이 솔루션은 기업이 컴퓨터 비전 모델을 위한 데이터 파이프라인을 구축하는 데 드는 시간과 비용을 대폭 절감할 수 있도록 지원합니다. 컴퓨터 비전 및 딥 러닝 분야에서 수십 년의 경험을 쌓은 연구원과 엔지니어(25개 이상의 논문 발표, 7,300회 이상의 인용, 100개 이상의 특허 포함)가 2018년에 출시한 Superb AI의 비전은 모든 단계의 기업이 그 어느 때보다 빠르게 컴퓨터 비전 애플리케이션을 개발할 수 있도록 지원하는 것입니다.
Superb AI는 또한 NVIDIA 스타트업 Inception 프로그램을 통해 NVIDIA와 협력하고 있습니다. 이 프로그램은 전 세계 최첨단 스타트업의 개발을 육성하는 데 도움이 되며, 이들에게 NVIDIA 기술 및 전문가에 대한 액세스, 벤처 캐피탈리스트와의 연결 기회, 가시성을 높이기 위한 공동 마케팅 지원을 제공합니다.
이 블로그에 열거된 SDK의 대부분의 독점 액세스, 얼리 액세스, 기술 세션, 데모, 교육 과정, 리소스는 NVIDIA 개발자 프로그램 회원은 무료로 혜택을 받으실 수 있습니다. 지금 무료로 가입하여 NVIDIA의 기술 플랫폼에서 구축하는 데 필요한 도구와 교육에 액세스하시고 여러분의 성공을 가속화 하세요.