
이제 NVIDIA는 RTX 및 Jetson 플랫폼에서 Gemma 3n을 공식 지원합니다. 지난달 Google I/O에서 Google DeepMind가 선보인 Gemma는, 멀티모달 온디바이스 환경에 최적화된 두 가지 신규 모델을 포함하고 있습니다.
이번 Gemma에는 기존 3.5 버전에서 제공되던 텍스트와 비전 기능에 더해 오디오 처리 기능이 새롭게 추가되었습니다. 오디오에는 Universal Speech Model, 비전은 MobileNet v4, 텍스트는 MatFormer 가 적용되어 각 기능에 최적화된 연구 기반 모델이 유기적으로 통합되어 있습니다.
가장 주목할 만한 변화는 Per-Lay Embeddings라는 혁신적인 기술의 도입입니다. 이 기술은 모델 파라미터가 차지하는 메모리 사용량을 획기적으로 줄여줍니다. 예를 들어, Gemma 3n E4B 모델은 80억 개의 파라미터를 갖고 있지만, 실제 메모리 소모는 40억 파라미터 모델 수준에 가깝습니다. 덕분에 개발자들은 리소스가 제한된 환경에서도 보다 정밀하고 성능 높은 모델을 활용할 수 있습니다.
| 모델 이름 | 파라미터 수 | 입력 컨텍스트 길이 | 출력 컨텍스트 길이 | 디스크 상의 모델 크기 |
| E2B | 5B | 32K | 32K subtracting request input | 1.55GB |
| E4B | 8B | 32K | 32K subtracting request input | 2.82BB |
표 1: E2B 및 E4B 모델 모두에 적용되는 Gemma 3n 모델 구성 요소
Jetson으로 로보틱스와 엣지 AI 구동
Gemma 시리즈는 차세대 로보틱스와 같은 엣지 애플리케이션에 최적화된 NVIDIA Jetson 디바이스에서 우수한 성능을 발휘합니다. 경량 아키텍처와 이번에 추가된 동적 메모리 사용 기능 덕분에, 제한된 리소스 환경에서도 안정적으로 작동합니다.
Jetson 개발자들은 현재 Kaggle에서 진행 중인 Gemma 3n Impact Challenge에 참여할 수 있습니다. 이 챌린지는 접근성, 교육, 의료, 환경 지속 가능성, 재난 대응 등 다양한 분야에서 기술을 활용해 실질적이고 긍정적인 변화를 이끌어내는 것을 목표로 합니다. 최종 수상작뿐 아니라 Jetson 등 온디바이스 배포에 적합한 기술을 활용한 프로젝트에도 최소 $10,000의 상금을 포함한 다양한 수상 기회가 주어집니다.
참여를 원하신다면, 지난 4월 Gemma 3 Developer Day에서 공개된 텍스트 및 이미지 데모와, Ollama를 활용해 로컬에서 Gemma를 배포할 수 있는 GitHub 리포지토리를 참고해 보시기 바랍니다.
Windows 기반 개발자와 AI 활용 일반 사용자를 위한 NVIDIA RTX
NVIDIA RTX AI PC를 활용하면, 개발자는 Ollama를 통해 Gemma 3n 모델을 손쉽게 배포할 수 있습니다. 일반 사용자들도 AnythingLLM, LM Studio와 같은 선호하는 애플리케이션에서 RTX 가속을 통해 Gemma 3n 모델을 활용할 수 있습니다.
개발자는 RTX와 Jetson 디바이스에 Gemma 3n을 간단한 명령어 몇 줄로 로컬 배포할 수 있습니다. Ollama CLI를 활용한 방법은 다음과 같습니다:
- Windows용 Ollama를 다운로드 및 설치합니다.
- 터미널을 열고 아래 명령어를 실행합니다:
ollama pull gemma3n:e4b
ollama run gemma3n:e4b “Summarize Shakespeare’s Hamlet” NVIDIA는 Ollama와 협력해 RTX GPU에 최적화된 성능 개선을 제공하며, 이를 통해 Gemma 3n과 같은 최신 모델을 빠르게 실행할 수 있도록 지원합니다. 해당 모델은 GGML 라이브러리를 기반으로 한 Ollama 엔진을 백엔드에서 활용해 구동됩니다. RTX GPU에서 최상의 성능을 구현하기 위한 NVIDIA의 GGML 라이브러리 기여 내용도 함께 확인하실 수 있습니다.
NVIDIA NeMo Framework로 데이터에 맞게 Gemma를 커스터마이징하세요
개발자는 Hugging Face에 공개된 Gemma 3n 모델을 오픈소스 NVIDIA NeMo Framework와 함께 사용할 수 있습니다. NeMo는 Llama 기반 모델을 사후 학습(post-training) 방식으로 정교하게 조정해 정확도를 높일 수 있도록 지원하며, 특히 기업 맞춤형 데이터로 파인튜닝(fine-tuning)하는 데 적합한 종합적인 프레임워크를 제공합니다. NeMo의 워크플로우는 데이터 준비부터 효율적인 파인튜닝, 모델 평가까지 전체 과정을 엔드 투 엔드로 지원합니다.
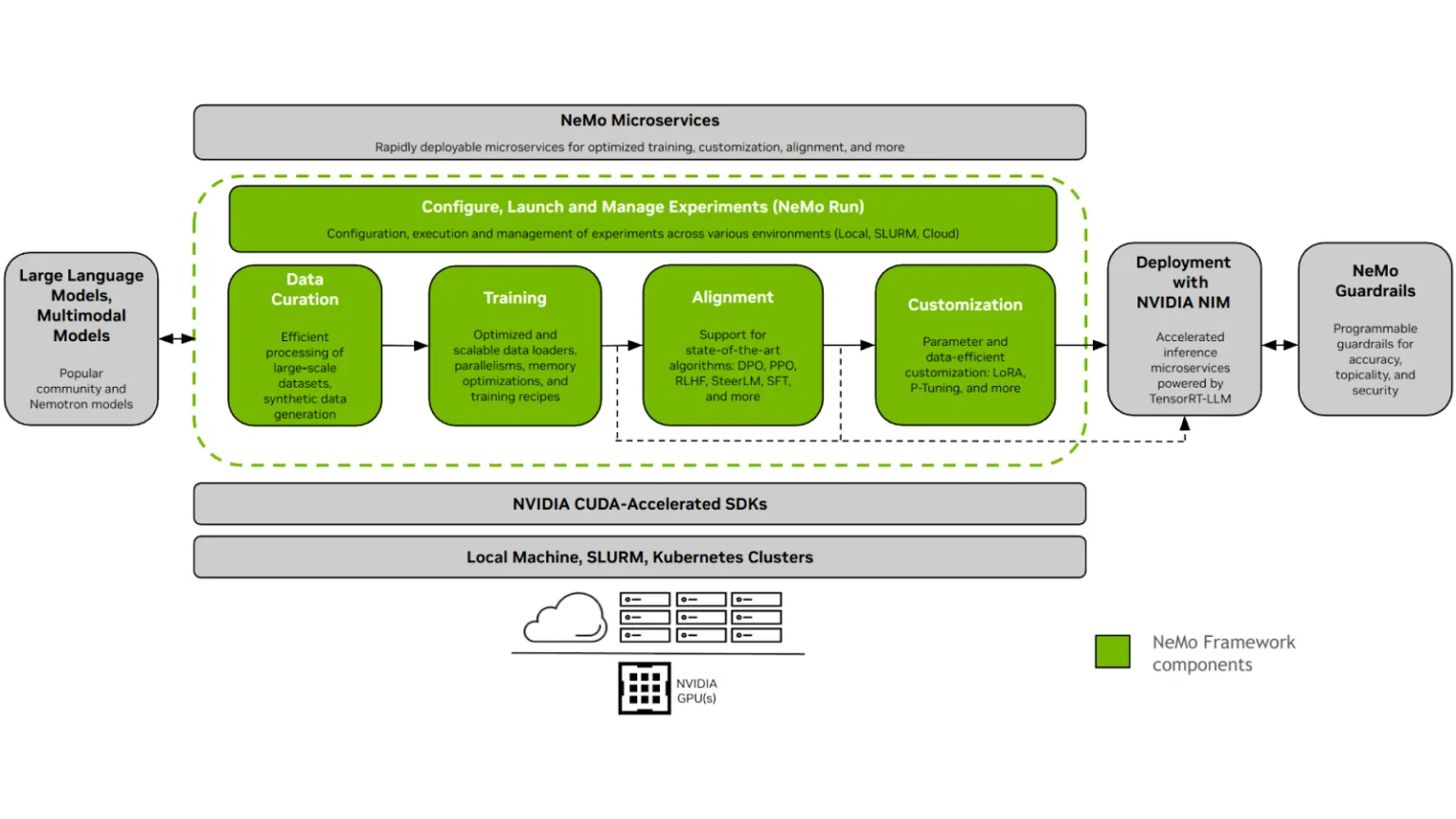
NeMo의 워크플로우는 다음과 같은 단계로 구성되어 있습니다:
- 데이터 정제 (NeMo Curator): Curator는 대규모의 정형 및 비정형 데이터를 추출, 필터링, 중복 제거할 수 있는 도구를 제공하여, 사전 학습 또는 파인튜닝에 적합한 고품질 데이터셋을 준비합니다. 이를 통해 모델 입력 데이터의 품질을 보장합니다.
- 파인튜닝 (NeMo): 데이터 정제가 완료되면, NeMo를 통해 Llama 모델을 효율적으로 파인튜닝할 수 있습니다. 이 과정에서는 LoRA(Low-Rank Adaptation), PEFT(Parameter-Efficient Fine-Tuning), 전체 파라미터 튜닝 등 다양한 최적화 기법을 지원하여 모델을 정교하게 커스터마이징할 수 있습니다.
- 모델 평가 (NeMo Evaluator): 파인튜닝 이후에는 NeMo Evaluator를 활용해 사용자 정의 테스트 및 벤치마크를 기반으로 모델 성능을 평가합니다.
이러한 통합적인 워크플로우를 통해 NeMo는 커뮤니티 기반 모델의 발전과 협업을 적극적으로 촉진합니다.
NVIDIA는 오픈소스 생태계에 활발히 기여하고 있으며, 수백 개에 달하는 프로젝트를 오픈소스 라이선스로 공개해왔습니다. Gemma와 같이 AI의 투명성을 강화하고, 안전성과 회복탄력성에 관한 연구 결과를 널리 공유할 수 있는 오픈 모델에 대한 지원도 지속하고 있습니다.
지금 바로 시작해보세요
여러분의 데이터를 활용해, NVIDIA API 카탈로그에서 NVIDIA 가속 플랫폼 기반의 Gemma 3n E4B를 직접 체험해보시기 바랍니다.
관련 리소스
- DLI 과정: Jetson Nano에서 AI 시작하기
- GTC 세션: NVIDIA Jetson 및 AWS IoT Greengrass를 통해 엣지에서 생성형 AI 마이크로서비스 활용하기
- GTC 세션: RTX PC 및 워크스테이션을 위한 디지털 휴먼, 비주얼 에이전트 및 생성형 AI 팟캐스트 생성하기
- GTC 세션: Google AI: 연구, 발전 및 광고의 미래
- NGC 컨테이너: DLI Jetson Nano에서 AI 시작하기
- SDK: NVIDIA Dynamo




