PyData는 CUDA를 포함하여 정적 언어 세계의 많은 부분을 속도에 활용하기 때문에 언어뿐만 아니라 디바이스, CPU 및 GPU 전반에 걸쳐 프로파일링 및 측정 도구가 필요합니다. Python 에코시스템에는 훌륭한 프로파일링 도구가 많지만 cProfile과 같은 라인 프로파일러와 PySpy/Viztracer와 같은 C 확장자에서 코드 실행을 관찰할 수 있는 프로파일러가 있습니다. Python 프로파일러 중 어느 것도 GPU에서 실행되는 코드를 프로파일링할 수 없습니다. 개발자는 디버그/프로파일링을 지원하고 일반적으로 Python의 GPU에서 일어나는 일을 이해하는 데 도움이 되는 도구가 필요합니다. 다행히 이러한 도구가 존재합니다. NVTX(NVIDIA Tools Extension)와 Nsight Systems는 함께 CPU 및 GPU 성능을 시각화하는 강력한 도구입니다.
NVTX는 Python, C, C++를 포함한 여러 언어로 된 코드를 위한 주석 라이브러리입니다. Nsight Systems를 사용하여 표준 Python 함수, Pandas/NumPy와 같은 PyData 라이브러리, 동일한 PyData 라이브러리의 기본 C/C++ 코드까지 추적할 수 있습니다! Nsight Systems는 또한 개발자에게 디바이스(GPU)에서 일어나는 일에 대한 인사이트를 제공하는 CUDA용 추가 후크와 함께 배송됩니다. 즉, cudaMalloc, cudaMemcpy 등과 같은 CUDA 호출을 “볼” 수 있습니다.
빠른 시작
NVTX는 코드 주석 도구이며 함수 또는 코드 청크를 표시하는 데 사용할 수 있습니다. Python 개발자는 @nvtx.annotate() 데코레이터를 사용하거나 nvtx.annotate(..):가 있는 컨텍스트 관리자를 사용하여 측정할 코드를 표시할 수 있습니다. 예를 들어,
import time
import nvtx
@nvtx.annotate(“f()”, color="purple")
def f():
for i in range(5):
with nvtx.annotate("loop", color="red"):
time.sleep(i)
f()코드에 주석을 추가하는 것만으로는 결과를 얻을 수 없습니다. 주석이 달린 코드에 대한 정보를 얻으려면 일반적으로 NVIDIA Nsight Systems와 같은 타사 애플리케이션과 함께 실행해야 합니다. 위에서는 함수, f, for 루프에 주석을 달았습니다. 그런 다음 Nsight Systems CLI를 사용하여 프로그램을 실행할 수 있습니다.
> nsys profile -t nvtx,osrt --force-overwrite=true --stats=true --output=quickstart python nvtx-quickstart.py-t nvtx,osrt 옵션은 nsys가 캡처해야 할 항목을 정의합니다. 이 경우에는 nvtx 주석 및 OSRT(OS 런타임) 기능(읽기/선택 등)입니다.
nsys와 python 프로그램이 모두 끝나면 qdrep 파일과 sqlite 데이터베이스라는 두 개의 파일이 생성됩니다. Nsight Systems UI(모든 OS에서 사용 가능)로 qdrep 파일을 로드하여 워크플로우의 타임라인을 시각화할 수 있습니다.
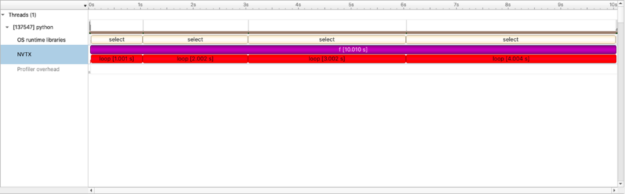
타임라인 뷰의 값
언뜻 보기에 이는 가장 흥미로운 프로필은 아닙니다. 코드 자체는 복잡하지 않습니다. 그러나 다른 프로파일링 도구와 달리 이 뷰는 타임라인입니다. 즉, 루프 또는 f()에서 속도를 높이는 총 시간뿐만 아니라 워크플로우가 진행됨에 따라 엔드 투 엔드 워크플로우를 보다 잘 평가하고 코드를 검토할 수 있습니다. nsys도 이러한 뷰를 제시하고 있습니다.
NVTX Push-Pop 범위 통계(나노초)
| 시간(%) | 총 시간. | 인스턴스 | 평균 | 최소 | 최대 범위 |
| 50.0 | 10009044198 | 1 | 10009044198.0 | 10009044198 | 10009044198 f |
| 50.0 | 10008769086 | 5 | 2001753817.2 | 4293 | 4002451694 루프 |
py-spy와 마찬가지로 NVTX도 여러 프로세스와 스레드에 걸쳐 프로파일링할 수 있습니다.
@nvtx.annotate("mean", color="blue")
def compute_mean(x):
return x.mean()
@nvtx.annotate("mock generate data", color="red")
def read_data(size):
return np.random.random((size, size))
def big_computation(size):
time.sleep(0.5) # mock warmup
data = read_data(size)
return compute_mean(data)
@nvtx.annotate("main")
def main():
ctx = multiprocessing.get_context("spawn")
sizes = [4096, 1024]
procs = [
ctx.Process(name="calculate", target=big_computation, args=[sizes[i]])
for i in range(2)
]
for proc in procs:
proc.start()
for proc in procs:
proc.join()그런 다음 Nsight Systems CLI를 사용하여 프로그램을 실행할 수 있습니다.
> MKL_NUM_THREADS=1 OPENBLAS_NUM_THREADS=1 OMP_NUM_THREADS=1 nsys profile -t nvtx,osrt,cuda --stats=true --force-overwrite=true --output=multiprocessing python nvtx-multiprocess.py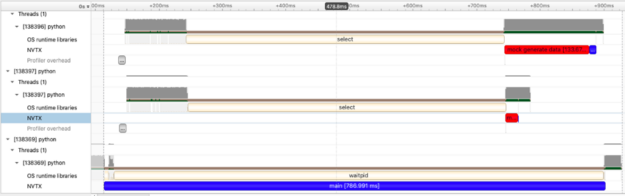
이 예제에서는 두 개의 프로세스를 생성하여 많은 양의 데이터를 생성하고 평균을 계산합니다. 첫 번째 프로세스에서는 랜덤 데이터의 4096×4096 행렬을 구축하고, 두 번째 프로세스에서는 랜덤 데이터의 1024×1024 행렬을 구축합니다. 시각화에서 볼 수 있는 것은 빨간색 막대(데이터 생성 시간을 나타냄) 2개와 파란색 막대(작은 빨간색 데이터 생성 작업에 연결된 파란색 막대는 보기 어려움) 3개입니다. 여기서 두 가지 매우 유익한 정보를 볼 수 있는데, 이는 소요된 시간만 측정하는 도구에서는 캡처하기 어려울 수 있습니다.
- 프로세스는 시간적으로 겹치고 두 행렬의 데이터 생성이 동시에 발생하는 것을 볼 수 있습니다!
- 데이터 생성 비용은 0이 아니며 대형 4096×4096 행렬에는 평균 계산과 마찬가지로 훨씬 더 많은 시간이 소요됩니다.
GPU 간 주석(Cuda 전용)
“NVTX 범위 보호”라는 Nsight Systems의 기능을 통해 사용자는 여러 디바이스, 특히 NVIDIA GPU에 주석을 달 수 있습니다. 즉, GPU 자체에서 발생하는 일(cudaMalloc, 컴퓨팅 시간, 동기화)에 대한 깊은 이해를 발전시킬 수 있을 뿐만 아니라 다양하고 복잡한 멀티 스레드, 멀티 프로세스, 멀티 라이브러리 환경에서 Python의 GPU를 활용할 수 있습니다. 다시 쉽게 설명해 보겠습니다.
with nvtx.annotate("data generation", color="purple"):
imgs = [cupy.random.random((1024, 1024)) for i in range(100)] 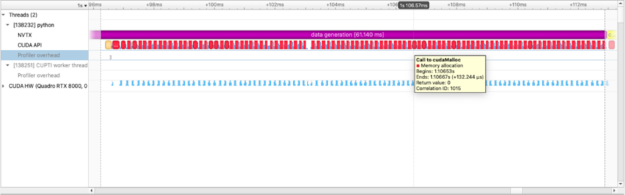
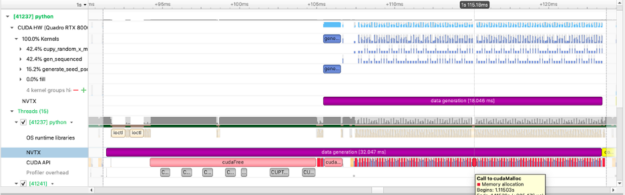
GPU를 대상으로 하는 NumPy 유사 라이브러리인 CuPy를 사용하여 NumPy 데이터와 마찬가지로 데이터를 처리합니다. 위의 그림은 GPU에 데이터를 할당하는 데 소비한 시간을 캡처합니다. 또한 개별 cupy 커널(cupy_random, gen_sequence, generate_seed)의 실행을 볼 수 있을 뿐만 아니라 다른 작업과 관련하여 커널이 실행되는 위치와 시기도 볼 수 있습니다. 아래 예제에서는 두 행렬 간의 제곱 차이를 계산하고 이 계산을 수행하는 데 소요된 시간을 측정합니다.
def squared_diff(x, y):
return (x - y) * (x - y)
with nvtx.annotate("compute", color="yellow"):
squares = [squared_diff(arr_x, arr_y) for arr_x, arr_y in list(zip(imgs, imgs[1:]))]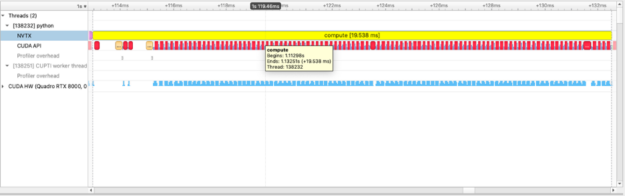
성능을 위해 풀 할당자 사용
이 정보를 통해 이제 GPU가 시간을 보내는 방법과 위치를 시각적으로 이해할 수 있습니다. 다음으로, 더 잘할 수 있습니까?라고 물어볼 수 있습니다. 답은 예입니다! cudaMalloc은 0이 아닌 시간 작업이며 많은 GPU 할당을 생성하면 성능에 부정적인 영향을 미칠 수 있습니다. 대신 RAPIDS RMM 풀 할당자를 사용하여 대규모 사전 GPU 메모리 할당을 생성하고 훨씬 빠른 속도로 하위 할당을 수행할 수 있습니다.
cupy.cuda.set_allocator(rmm.rmm_cupy_allocator)
rmm.reinitialize(pool_allocator=True, initial_pool_size=2 ** 32) # 4GBs
with nvtx.annotate("data generation w pool", color="purple"):
imgs = [cupy.random.random((1024, 1024)) for i in range(100)]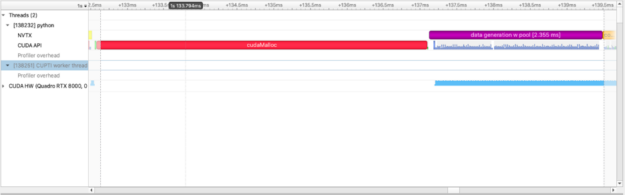
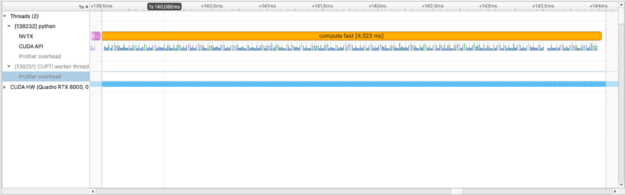
이 특정 연산인 squared_difference의 경우 cupy.fuse를 사용하여 요소별 커널을 최적화할 수 있습니다. 이는 일반적인 GPU 최적화입니다.
with nvtx.annotate("compute fast", color="orange"):
squares = [
cupy.fuse(squared_diff(arr_x, arr_y))
for arr_x, arr_y in list(zip(imgs, imgs[1:]))
]
개발자 및 사용자에게 도움이 되는 NVTX
주석 자체는 최소한의 오버헤드를 가지며 nsys로 실행될 때만 정보를 캡처합니다. 프로파일링 코드는 사용자와 개발자에게 숨겨진 유용한 정보를 제공하고 시간이 소요되는 위치와 이유에 대한 많은 부분을 제시합니다. 라이브러리 작성자가 NVTX로 주석을 추가하기로 선택하면 사용자는 엔드 투 엔드 워크플로우를 보다 완전하게 이해할 수 있습니다. 예를 들어 GPU Dataframe 라이브러리인 RAPIDS cuDF를 사용하면 커널은 종종 그룹별 집계의 일부로 메모리를 할당해야 합니다. 앞서 살펴보았듯이 RMM 풀 할당자를 사용하면 GPU 메모리 생성에 소요되는 시간을 줄일 수 있습니다.
rmm.reinitialize(pool_allocator=True, initial_pool_size=2 ** 32) # 4GBs
gcdf1 = cdf1.groupby("id").mean().reset_index()
gcdf2 = cdf2.groupby("id").mean().reset_index()
gcdf2.join(gcdf1, on=["id"], lsuffix="_l")또한 선택한 경로에 따라 일부 동등한 작업이 다른 작업보다 빠른 이유도 빠르게 알 수 있습니다. 여러 groupby-aggregation(groupby().mean(), groupby().count(), …)을 수행할 때 각각을 개별적으로 수행하거나 agg 연산자를 사용할 수 있습니다. agg를 사용하면 groupby 작업을 한 번만 수행합니다.
with nvtx.annotate("agg-all", color="blue"):
cdf.groupby("name").agg(["count", "mean", "sum"])
with nvtx.annotate("split-agg", color="red"):
cdf.groupby("name").count(), cdf.groupby("name").mean(), cdf.groupby("name").count()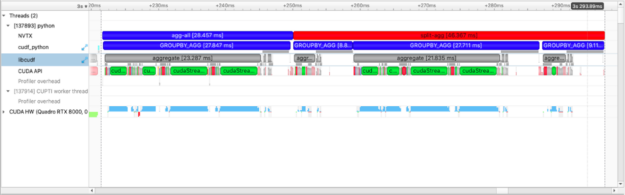
위의 도표에서 agg-all 및 split-agg 주석보다 더 많은 것을 볼 수 있습니다. cuDF 개발자가 삽입한 주석을 볼 수 있으며 agg([“count”, “mean”, “sum”])에 대한 group-agg 호출 1개와 count(), mean(), sum()에 대한 group-agg 호출 3개를 명확하게 볼 수 있습니다.
다음 단계
현재 패키지 내에서 함수에 주석을 추가하려면 사용자가 해당 패키지를 수정하거나 패키지의 일부에 주석을 달도록 유지 관리자를 설득해야 합니다. 소스 코드를 수정하지 않고 함수에 주석을 달 수 있으면 편리할 것입니다. 이를 달성하는 방법은 즉시 명확하지 않습니다.
잠재적으로 유용한 또 다른 기능은 실행 스레드에 주석을 다는 것입니다. 현재 실행의 서로 다른 스레드는 스레드 0, 스레드 1 등으로 명명되어 유용하지 않을 수 있습니다. 이는 이미 C 계층에서는 가능하지만 현재 Python 계층에서는 노출되지 않습니다.
이는 몇 가지 생각일 뿐이며, 커뮤니티의 제안을 환영합니다. C, C++, Python 바인딩이 포함된 GitHub 리포지토리를 유지 관리하며 문제 추적기의 문제를 환영합니다. 누락된 사항이 있는 경우 PR을 환영하며 기꺼이 검토하겠습니다. 또한 편하게 방문할 수 있는 Slack 채널도 운영하고 있습니다.
결론
pip 또는 conda를 사용하여 NVTX를 쉽게 다운로드할 수 있습니다.
ython -m pip install nvtx또는
tconda install -c conda-forge nvtx이 블로그 게시물(및 기타 몇 가지)의 예시는 이 GitHub 저장소에서 확인할 수 있습니다.
이 블로그에 열거된 SDK의 대부분의 독점 액세스, 얼리 액세스, 기술 세션, 데모, 교육 과정, 리소스는 NVIDIA 개발자 프로그램 회원은 무료로 혜택을 받으실 수 있습니다. 지금 무료로 가입하여 NVIDIA의 기술 플랫폼에서 구축하는 데 필요한 도구와 교육에 액세스하시고 여러분의 성공을 가속화 하세요.