
생성형 AI 도입의 증가는 놀랍습니다. 2022년 OpenAI의 ChatGPT 출시로 촉발된 이 새로운 기술은 몇 달 만에 1억 명 이상의 사용자를 확보했으며, 거의 모든 산업에서 개발 활동이 급증했습니다.
2023년에는 개발자들이 Meta, Mistral, Stability 등의 API와 오픈 소스 커뮤니티 모델을 사용하여 POC를 시작했습니다.
2024년에 접어들면서 조직들은 AI 모델을 기존 엔터프라이즈 인프라에 연결하고, 시스템 지연 시간과 처리량, 로깅, 모니터링, 보안 등을 최적화하는 등 본격적인 프로덕션 배포로 초점을 옮기고 있습니다. 프로덕션으로 가는 이 과정은 복잡하고 시간이 많이 소요되며, 특히 대규모의 경우 전문 기술, 플랫폼 및 프로세스가 필요합니다.
NVIDIA AI Enterprise의 일부인 NVIDIA NIM은 AI 기반 엔터프라이즈 애플리케이션을 개발하고 프로덕션에 AI 모델을 배포하기 위한 간소화된 프로세스를 제공합니다.
NIM은 클라우드, 데이터센터, GPU 가속 워크스테이션 등 어디서나 출시 시간을 단축하고 생성형 AI 모델의 배포를 간소화하도록 설계된 최적화된 클라우드 네이티브 마이크로서비스의 집합입니다. 업계 표준 API를 사용하여 AI 모델 개발 및 프로덕션용 패키징의 복잡성을 추상화하여 개발자 풀을 확장합니다.
최적화된 AI 추론을 위한 NVIDIA NIM
NVIDIA NIM은 복잡한 AI 개발 세계와 기업 환경의 운영 요구 사항 사이의 격차를 해소하도록 설계되어 10~100배 더 많은 엔터프라이즈 애플리케이션 개발자가 기업의 AI 혁신에 기여할 수 있도록 지원합니다.
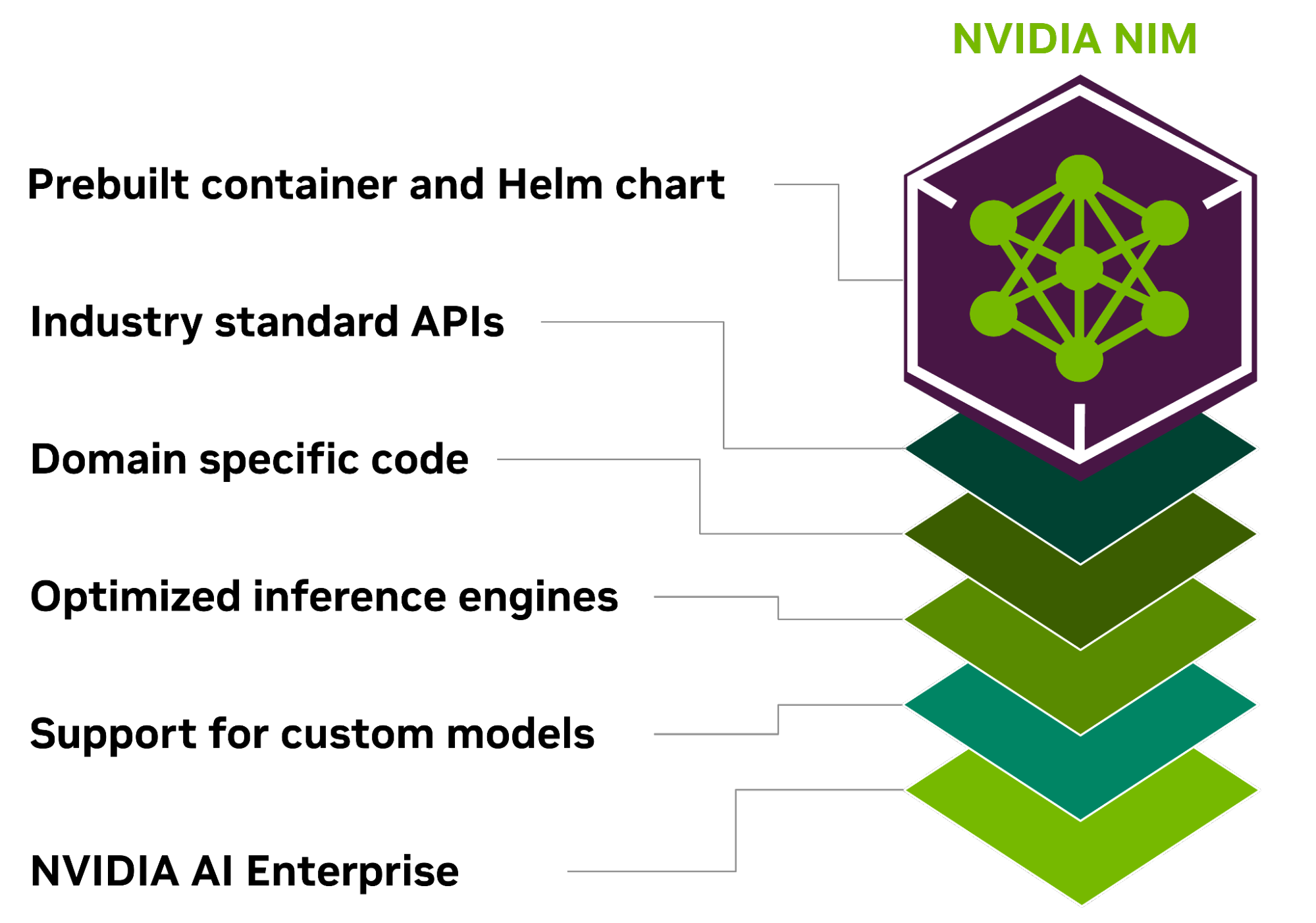
NIM의 핵심 이점은 다음과 같습니다.
어디서나 배포
NIM은 이동성과 제어를 위해 구축되어 로컬 워크스테이션부터 클라우드, 온프레미스 데이터센터에 이르기까지 다양한 인프라에 걸쳐 모델을 배포할 수 있습니다. 여기에는 NVIDIA DGX, NVIDIA DGX Cloud, NVIDIA 인증 시스템, NVIDIA RTX 워크스테이션 및 PC가 포함됩니다.
최적화된 모델로 패키징된 사전 빌드된 컨테이너와 헬름 차트는 다양한 NVIDIA 하드웨어 플랫폼, 클라우드 서비스 제공업체 및 Kubernetes 배포판에서 엄격한 검증과 벤치마킹을 거쳤습니다. 따라서 모든 NVIDIA 기반 환경에서 지원이 가능하며, 조직은 애플리케이션과 처리하는 데이터를 완벽하게 제어하면서 어디서나 생성형 AI 애플리케이션을 배포할 수 있습니다.
업계 표준 API로 개발
개발자는 각 도메인에 대한 업계 표준을 준수하는 API를 통해 AI 모델에 액세스하여 AI 애플리케이션 개발을 간소화할 수 있습니다. 이러한 API는 에코시스템 내의 표준 배포 프로세스와 호환되므로 개발자는 단 3줄의 코드만으로 AI 애플리케이션을 신속하게 업데이트할 수 있습니다. 이러한 원활한 통합과 사용 편의성 덕분에 엔터프라이즈 환경 내에서 AI 솔루션을 신속하게 배포하고 확장할 수 있습니다.
도메인별 모델 활용
NIM은 또한 몇 가지 주요 기능을 통해 도메인별 솔루션과 최적화된 성능에 대한 필요성을 해결합니다. 언어, 음성, 비디오 처리, 의료 등 다양한 도메인에 맞춘 도메인별 NVIDIA CUDA 라이브러리와 전문 코드를 패키지로 제공합니다. 이러한 접근 방식을 통해 애플리케이션이 특정 사용 사례와 정확하고 관련성이 높은지 확인할 수 있습니다.
최적화된 추론 엔진에서 실행
NIM은 각 모델과 하드웨어 설정에 최적화된 추론 엔진을 활용하여 가속화된 인프라에서 최상의 지연 시간과 처리량을 제공합니다. 이를 통해 추론 워크로드의 확장에 따른 실행 비용을 절감하고 최종 사용자 경험을 개선할 수 있습니다. 최적화된 커뮤니티 모델을 지원할 뿐만 아니라, 개발자는 데이터 센터의 경계를 벗어나지 않는 독점 데이터 소스로 모델을 조정하고 미세 조정하여 정확도와 성능을 더욱 향상시킬 수 있습니다.
엔터프라이즈급 AI 지원
NVIDIA AI Enterprise의 일부인 NIM은 엔터프라이즈급 기본 컨테이너로 구축되어 기능 브랜치, 엄격한 검증, 서비스 수준 계약을 통한 엔터프라이즈 지원, CVE에 대한 정기적인 보안 업데이트를 통해 엔터프라이즈 AI 소프트웨어를 위한 견고한 기반을 제공합니다. 포괄적인 지원 구조와 최적화 기능은 효율적이고 확장 가능한 맞춤형 AI 애플리케이션을 프로덕션에 배포하는 데 있어 중추적인 도구로서 NIM의 역할을 강조합니다.
배포 준비가 완료된 가속화된 AI 모델
커뮤니티 모델, NVIDIA AI 파운데이션 모델, NVIDIA 파트너가 제공하는 맞춤형 AI 모델 등 다양한 AI 모델을 지원하는 NIM은 여러 도메인에 걸쳐 AI 사용 사례를 지원합니다. 여기에는 거대 언어 모델(LLM), 비전 언어 모델(VLM), 음성, 이미지, 비디오, 3D, 약물 발견, 의료 이미징 등을 위한 모델이 포함됩니다.
개발자는 NVIDIA API 카탈로그에서 NVIDIA 관리형 클라우드 API를 사용하여 최신 생성형 AI 모델을 테스트할 수 있습니다. 또는 NIM을 다운로드하여 모델을 자체 호스팅하고 주요 클라우드 제공업체 또는 온프레미스에서 Kubernetes를 사용하여 신속하게 배포하여 개발 시간, 복잡성 및 비용을 절감할 수 있습니다.
NIM 마이크로서비스는 알고리즘, 시스템 및 런타임 최적화를 패키징하고 업계 표준 API를 추가하여 AI 모델 배포 프로세스를 간소화합니다. 따라서 개발자는 광범위한 사용자 지정이나 전문 지식 없이도 기존 애플리케이션과 인프라에 NIM을 통합할 수 있습니다.
기업은 NIM을 사용하여 AI 모델 개발의 복잡성과 컨테이너화에 대한 걱정 없이 효율성과 비용 효과를 극대화하기 위해 AI 인프라를 최적화할 수 있습니다. NIM은 가속화된 AI 인프라 외에도 하드웨어 및 운영 비용을 절감하면서 성능과 확장성을 지원합니다.
엔터프라이즈 애플리케이션에 맞게 모델을 맞춤화하고자 하는 기업을 위해 NVIDIA는 다양한 도메인에서 모델 커스터마이징을 위한 마이크로 서비스를 제공합니다. NVIDIA NeMo는 LLM, 음성 AI 및 멀티모달 모델을 위한 독점 데이터를 사용하여 미세 조정 기능을 제공합니다. NVIDIA BioNeMo는 생성 생물학 화학 및 분자 예측을 위한 모델 컬렉션을 늘려 신약 발견을 가속화합니다. NVIDIA Picasso는 Edify 모델을 통해 더 빠른 창작 워크플로우를 지원합니다. 이러한 모델은 시각 콘텐츠 제공업체의 라이선스 라이브러리에서 학습되어 시각 콘텐츠 제작을 위한 맞춤형 생성형 AI 모델을 배포할 수 있습니다.
NVIDIA NIM 시작하기
NVIDIA NIM은 쉽고 간단하게 시작할 수 있습니다. 개발자는 NVIDIA API 카탈로그 내에서 자체 AI 애플리케이션을 빌드하고 배포하는 데 사용할 수 있는 광범위한 AI 모델에 액세스할 수 있습니다.
그래픽 사용자 인터페이스를 사용하여 카탈로그에서 직접 프로토타이핑을 시작하거나 무료로 API와 직접 상호 작용할 수 있습니다. 인프라에 마이크로서비스를 배포하려면 NVIDIA AI Enterprise 90일 평가판 라이선스에 가입하고 다음 단계를 따르기만 하면 됩니다.
1. NVIDIA NGC에서 배포하려는 모델을 다운로드합니다. 이 예제에서는 단일 A100 GPU용으로 제작된 Llama-2 7B 모델 버전을 다운로드합니다.
ngc registry model download-version "ohlfw0olaadg/ea-participants/llama-2-7b:LLAMA-2-7B-4K-FP16-1-A100.24.01"다른 GPU를 사용하는 경우, 사용 가능한 모델 버전을 ngc 레지스트리 모델 목록 “ohlfw0olaadg/ea-participants/llama-2-7b:*”로 나열할 수 있습니다.
2. 다운로드한 아티팩트를 모델 저장소에 압축을 풉니다:
tar -xzf llama-2-7b_vLLAMA-2-7B-4K-FP16-1-A100.24.01/LLAMA-2-7B-4K-FP16-1-A100.24.01.tar.gz3. 원하는 모델로 NIM 컨테이너를 실행합니다:
docker run --gpus all --shm-size 1G -v $(pwd)/model-store:/model-store --net=host nvcr.io/ohlfw0olaadg/ea-participants/nemollm-inference-ms:24.01 nemollm_inference_ms --model llama-2-7b --num_gpus=14. NIM이 배포되면 표준 REST API를 사용하여 요청을 시작할 수 있습니다:
import requests
endpoint = 'http://localhost:9999/v1/completions'
headers = {
'accept': 'application/json',
'Content-Type': 'application/json'
}
data = {
'model': 'llama-2-7b',
'prompt': "The capital of France is called",
'max_tokens': 100,
'temperature': 0.7,
'n': 1,
'stream': False,
'stop': 'string',
'frequency_penalty': 0.0
}
response = requests.post(endpoint, headers=headers, json=data)
print(response.json())NVIDIA NIM은 조직이 프로덕션 AI로의 여정을 가속화할 수 있도록 지원하는 강력한 도구입니다. 지금 바로 AI 여정을 시작하세요.
관련 리소스
- DLI 과정: 프로덕션 규모에서 추론을 위한 모델 배포하기
- GTC 세션: 엔터프라이즈 가속화: 차세대 생성형 AI 배포를 위한 도구 및 기법
- GTC 세션: LLM 추론 스케일: 엔드투엔드 추론 시스템 벤치마킹하기
- SDK: Triton 관리 서비스
- SDK: Triton 추론 서버
- SDK: NeMo 추론 마이크로서비스