
2022년 NVIDIA GTC 키노트 연설에서 CEO 젠슨 황이 새로운 NVIDIA Hopper GPU 아키텍처 기반의 새로운 NVIDIA H100 Tensor 코어 GPU를 소개했습니다. 이 게시물은 새로운 H100 GPU를 자세히 살펴보고 NVIDIA Hopper 아키텍처 GPU의 새롭고 중요한 기능을 설명합니다.
NVIDIA H100 Tensor 코어 GPU 소개
NVIDIA H100 Tensor 코어 GPU는 이전 세대의 NVIDIA A100 Tensor 코어 GPU보다 대규모 AI 및 HPC 성능이 크게 향상된 설계를 적용한 9세대 데이터센터 GPU입니다. H100은 A100의 주요 설계 초점을 이행하여 AI 및 HPC 워크로드를 위한 강력한 확장성을 개선하고 아키텍처 효율성을 크게 향상시켰습니다.

오늘날의 메인스트림 AI 및 HPC 모델에서 InfiniBand 인터커넥트를 탑재한 H100은 A100보다 최대 30배의 성능을 제공합니다. 새로운 NVLink 스위치 시스템 인터커넥트는 여러 GPU 가속 노드 전반에 걸쳐 모델 병렬 처리가 요구되는 가장 크고 가장 까다로운 컴퓨팅 워크로드를 대상으로 합니다. 세대 간의 또 다른 성능 향상을 이어받은 이 워크로드는 때에 따라 InfiniBand를 탑재한 H100의 성능에서 다시 한 번 세 배 더 향상됩니다.
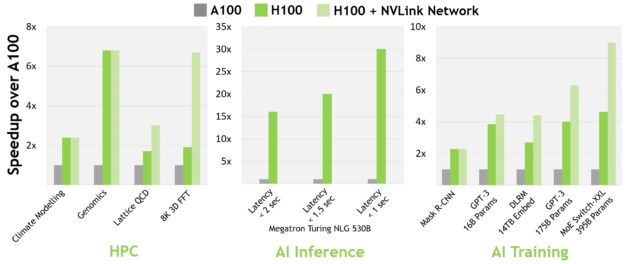
모든 성능 수치는 현재의 예상에 따른 예비 수치이며 실제 제품에서는 다를 수 있습니다. A100 cluster: HDR IB network. H100 cluster: NDR IB network with NVLink Switch System where indicated. # GPUs: Climate Modeling 1K, LQCD 1K, Genomics 8, 3D-FFT 256, MT-NLG 32 (batch sizes: 4 for A100, 60 for H100 at 1 sec, 8 for A100 and 64 for H100 at 1.5 and 2sec), MRCNN 8 (batch 32),GPT-3 16B 512 (batch 256), DLRM 128 (batch 64K), GPT-3 16K (batch 512), MoE 8K (batch 512, one expert per GPU).
GTC Spring 2022에서 새로운 NVIDIA Grace Hopper 슈퍼칩 제품이 발표되었습니다. NVIDIA Hopper H100 Tensor Core GPU는 NVIDIA Grace Hopper 슈퍼칩 CPU+GPU 아키텍처를 지원합니다. 테라바이트 규모의 가속 컴퓨팅을 위해 특별히 제작되었으며, 대규모 모델 AI 및 HPC에서 10배 더 높은 성능을 제공합니다.
NVIDIA Grace Hopper 슈퍼칩은 Arm 아키텍처의 유연성을 활용하여 처음부터 가속화 컴퓨팅을 위해 설계된 CPU 및 서버 아키텍처를 생성합니다. H100과 NVIDIA Grace CPU가 결합되면 초고속 NVIDIA 칩 간 인터커넥트를 통해 PCIe Gen5보다 7배 빠른 900GB/s의 총 대역폭을 제공합니다. 이 혁신적인 설계는 오늘날 가장 가장 빠른 서버들 대비 최대 30배 높은 전체 대역폭과 테라바이트 규모의 데이터를 사용하는 애플리케이션에 대한 최대 10배 높은 성능을 제공합니다.
NVIDIA H100 GPU 핵심 기능 요약
• 새로운 스트리밍 멀티프로세서(SM)의 성능과 효율성이 대폭 향상되었습니다. 새로운 주요 특징은 다음과 같습니다.
o 새로운 4세대 Tensor 코어는 SM당 속도 향상, 늘어난 SM 수, H100의 더 높은 클럭을 갖추고 있어 A100에 비해 칩 간 속도가 최대 6배 더 빠릅니다. SM당 기준으로 Tensor 코어는 이전 세대의 16비트 부동 소수점 옵션과 비교하여 동급 데이터 유형에서 A100 SM의 MMA(Matrix Multiply-Accumulate) 계산 속도의 2배, 새로운 FP8 데이터 유형을 사용하면 A100 속도의 4배를 제공합니다. Sparsity 기능은 딥 러닝 네트워크에서 세분화된 구조적 Sparsity를 이용하여 표준 Tensor 코어 작업 성능을 두 배로 높입니다.
o 새로운 DPX 명령어는 동적 프로그래밍 알고리즘을 A100 GPU보다 최대 7배나 가속화합니다. 두 가지 예로는 유전체학 처리를 위한 스미스-워터맨 알고리즘과 동적인 공간 상에서 수많은 로봇을 위한 최적의 경로를 찾는 데 사용되는 플로이드-워셜 알고리즘이 있습니다.
o SM당 2배 더 빠른 클럭당 성능과 늘어난 SM 수, H100의 더 높은 클럭으로 인해 A100보다 칩 간의 처리 속도가 3배 더 빠른 IEEE FP64 및 FP32.
o 새로운 스레드 블록 클러스터 기능은 단일 단일 SM의 단일 스레드 블록보다 더 큰 단위로, locality를 프로그래밍 방식으로 제어할 수 있는 기능입니다. 이런 기능은 스레드, 스레드 블록, 스레드 블록 클러스터 및 그리드를 포함하도록 프로그래밍 계층 구조에 또 다른 수준을 추가하여 CUDA 프로그래밍 모델을 확장합니다. 클러스터를 사용하면 여러 SM에서 동시에 실행되는 여러 스레드 블록을 사용하여 데이터를 동기화하고 공동 작업으로 가져오고 교환할 수 있습니다.
o 분산 공유 메모리를 사용하면 여러 SM 공유 메모리 블록에서 로드, 저장 및 원자성에 대해 SM과 SM 간의 직접적인 통신을 지원합니다.
o 새로운 비동기 실행 기능에는 글로벌 메모리와 공유 메모리 간에 대용량 데이터를 효율적으로 전송할 수 있는 새로운 Tensor 메모리 가속기(TMA) 장치가 포함됩니다. TMA는 또한 클러스터의 스레드 블록 간의 비동기 복사도 지원합니다. 원자적 데이터 이동 및 동기화를 위한 새로운 비동기 트랜잭션 장벽도 있습니다.
• 새로운 트랜스포머 엔진은 트랜스포머 모델 트레이닝 및 추론을 가속화하도록 특별히 설계된 소프트웨어와 맞춤형 NVIDIA Hopper Tensor 코어 기술을 조합하여 사용합니다. 이 트랜스포머 엔진은 FP8과 16비트 계산 사이에서 지능적으로 관리하고 동적으로 선택해 각 레이어에서 FP8과 16비트 간의 재투사 및 확장을 자동으로 처리하여 이전 세대인 A100에 비해 대형 언어 모델에서 최대 9배 빠른 AI 트레이닝과 최대 30배 빠른 AI 추론 속도를 제공합니다.
• HBM3 메모리 하위 시스템은 이전 세대를 거치며 거의 2배 증가한 대역폭을 제공합니다. H100 SXM5 GPU는 HBM3 메모리를 탑재한 세계 최초의 GPU로 동급 최고인 3TB/s 메모리 대역폭을 제공합니다.
• 50MB L2 캐시 아키텍처는 반복적인 액세스를 위해 모델 및 데이터 세트의 상당 부분을 캐시하므로 HBM3으로의 이동이 줄어듭니다.
• 2세대 MIG(Multi-Instance GPU) 기술은 A100보다 GPU 인스턴스당 약 3배 더 많은 컴퓨팅 용량과 2배에 가까운 메모리 대역폭을 제공합니다. MIG 수준의 TEE를 통해 컨피덴셜 컴퓨팅 기능을 최초로 지원합니다. 최대 7개의 개별 GPU 인스턴스가 지원되며 각 인스턴스마다 전용 NVDEC 및 NVJPG 장치가 있습니다. 이제 각 인스턴스에는 NVIDIA 개발자 도구와 함께 작동하는 자체 성능 모니터 세트가 포함됩니다.
• 새로운 컨피덴셜 컴퓨팅 지원은 사용자 데이터를 보호하고 하드웨어 및 소프트웨어 공격으로부터 방어하며 가상화 및 MIG 환경에서 가상 머신(VM)을 더 우수하게 서로 격리하고 보호합니다. H100은 세계 최초로 네이티브 컨피덴셜 컴퓨팅 GPU를 구현하고 PCIe 최대 회선 속도로 CPU를 사용하여 신뢰할 수 있는 실행 환경(TEE)을 확장합니다.
• 4세대 NVIDIA NVLink PCIe Gen 5의 7배 대역폭에서 작동하는 멀티 GPU IO를 위한 총 대역폭은 900GB/s로 이전 세대 NVLink 대비 일반 대역폭은 50% 증가하고 all-reduce 작업에서 3배 증가했습니다.
• 3세대 NVSwitch 기술에는 노드 내부 및 외부에 모두 상주하는 스위치가 포함되어 서버, 클러스터 및 데이터센터 환경에서 여러 GPU를 연결합니다. 노드 내부의 NVSwitch는 각각 멀티 GPU 연결을 가속화하기 위해 4세대 NVLink 링크 포트를 64개 제공합니다. 총 스위치 처리량은 이전 세대의 7.2Tbits/s에서 13.6Tbits/s로 증가했습니다. 새로운 3세대 NVSwitch 기술은 멀티캐스트 및 NVIDIA SHARP 네트워크 내 감소를 사용하여 집합 연산을 위한 하드웨어 가속화도 제공합니다.
• 새로운 NVLink 스위치 시스템 인터커넥트 기술과 3세대 NVSwitch 기술에 기반한 새로운 2세대 NVLink 스위치는 주소 공간 격리와 보호를 도입하여 2:1 테이퍼 형태의 패트 트리(fat tree) 토폴로지에서 NVLink를 통해 최대 32개의 노드 또는 256개의 GPU를 연결할 수 있습니다. 이렇게 연결된 노드는 전체 57.6TB/s의 대역폭을 제공할 수 있으며 놀라운 1엑사플롭의 FP8 Sparsity AI 컴퓨팅을 제공할 수 있습니다.
• Gen 4 PCIe에서 64GB/s였던 총 대역폭(각 방향에서 32GB/s)과 비교하여 PCIe Gen 5의 총 대역폭은 128GB/s(각 방향에서 64GB/s)입니다. H100은 PCIe Gen 5를 통해 최고 성능의 x86 CPU 및 SmartNIC 또는 데이터 처리 장치(DPU)와 인터페이싱할 수 있습니다.
강력한 확장성을 개선하고 지연 시간과 오버헤드를 줄이며 일반적으로 GPU 프로그래밍을 단순화하기 위해 기타 새로운 기능도 많이 포함되어 있습니다.
NVIDIA H100 GPU 아키텍처 심층 분석
새로운 NVIDIA Hopper GPU 아키텍처 기반의 NVIDIA H100 GPU는 여러가지 혁신적인 기능을 갖추고 있습니다.
• 새로운 4세대 Tensor 코어는 더욱 광범위한 AI 및 HPC 작업에서 이전보다 더 빠른 행렬 계산을 수행합니다.
• H100은 새로운 트랜스포머 엔진을 통해 최대 9배 빠른 AI 트레이닝과 최대 30배 빠른 AI를 제공할 수 있습니다. 이전 세대 A100 대비 대형 언어 모델의 추론 속도도 향상되었습니다.
• 새로운 NVLink 네트워크 인터커넥트를 통해 여러 컴퓨팅 노드에 걸쳐 최대 256개의 GPU와 GPU 간 통신이 가능합니다.
• 안전한 MIG는 GPU를 적절한 크기의 격리된 인스턴스로 분할하여 더 작은 워크로드에 대한 서비스 품질(QoS)을 극대화합니다.
수많은 새로운 아키텍처 기능을 통해 많은 애플리케이션에서 최대 3배의 성능 향상을 달성할 수 있습니다.
NVIDIA H100은 최초의 진정한 비동기 GPU입니다. H100은 모든 주소 공간에서 A100의 글로벌 공유 비동기 전송을 확장하고 Tensor 메모리 액세스 패턴에 대한 지원을 추가합니다. 이를 통해 애플리케이션은 데이터를 칩 사이로 이동하는 엔드 투 엔드 비동기 파이프라인을 구축하여 연산을 통해 데이터 이동을 완전히 겹치고 숨길 수 있습니다.
새로운 Tensor 메모리 가속기를 사용하여 H100의 전체 메모리 대역폭을 관리하는 데 필요한 CUDA 스레드는 소수인 반면 대부분의 다른 CUDA 스레드는 새로운 세대의 Tensor 코어를 위한 전처리 및 후처리 데이터와 같은 범용 계산에 주력할 수 있습니다.
H100은 스레드 블록 클러스터라는 새로운 수준으로 CUDA 스레드 그룹 계층 구조를 확장하고 있습니다. 클러스터는 동시 예약이 보장되는 스레드 블록 그룹으로 여러 SM에서 스레드에 대한 효율적인 협력과 데이터 공유를 가능하게 합니다. 또한 클러스터는 Tensor 메모리 가속기 및 Tensor 코어와 같은 비동기 장치도 더욱 효율적으로 협력하여 구동합니다.
증가하는 온-칩 가속기와 다양한 범용 스레드 그룹을 조정하려면 동기화가 필요합니다. 예를 들어 출력을 사용하는 스레드와 가속기는 출력을 생성하는 스레드와 가속기에서 대기해야 합니다.
NVIDIA 비동기 트랜잭션 장벽을 통해 클러스터 내 범용 CUDA 스레드와 온-칩 가속기가 별도의 SM에 상주하더라도 효율적으로 동기화할 수 있습니다. 이 모든 새로운 기능이 합쳐져 모든 사용자와 애플리케이션은 항상 H100 GPU의 모든 장치를 완전히 사용할 수 있으므로 H100은 지금까지 가장 강력하고 프로그래밍 가능하며 전력 효율성이 높은 NVIDIA GPU가 되었습니다.
H100 GPU를 구동하는 전체 GH100 GPU는 800억 개의 트랜지스터, 814mm2의 다이 크기 및 더 높은 주파수 설계로 NVIDIA에 맞춤화된 TSMC 4N 프로세스를 사용하여 제작됩니다.
NVIDIA GH100 GPU는 다중 GPU 처리 클러스터(GPC), 텍스처 처리 클러스터(TPC), 스트리밍 멀티프로세서(SM), L2 캐시, HBM3 메모리 컨트롤러로 구성됩니다.
GH100 GPU의 완전한 구현에는 다음 장치가 포함됩니다.
• 8개의 GPC, 72개의 TPC(GPC당 TPC 9개), TPC당 2개의 SM, 전체 GPU당 144개의 SM
• SM당 128개의 FP32 CUDA 코어, 전체 GPU당 18432개의 FP32 CUDA 코어
• SM당 4개의 4세대 Tensor 코어, 전체 GPU당 576개
• HBM3 또는 HBM2e 스택 6개, 512비트 메모리 컨트롤러 12개
• 60MB L2 캐시
• 4세대 NVLink 및 PCIe Gen 5
SXM5 보드 폼 팩터를 사용한 NVIDIA H100 GPU에는 다음 장치가 포함됩니다.
• 8개의 GPC, 66개의 TPC, TPC당 2개의 SM, GPU당 132개의 SM
• SM당 128개의 FP32 CUDA 코어, 전체 GPU당 16896개의 FP32 CUDA 코어
• SM당 4개의 4세대 Tensor 코어, GPU당 528개
• 80GB HBM3, HBM2e 스택 5개, 512비트 메모리 컨트롤러 10개
• 50MB L2 캐시
• 4세대 NVLink 및 PCIe Gen 5
PCIe Gen 5 보드 폼 팩터를 사용한 NVIDIA H100 GPU에는 다음 장치가 포함됩니다.
• 7개 또는 8개의 GPC, 57개의 TPC, TPC당 2개의 SM, GPU당 114개의 SM
• SM당 128개의 FP32 CUDA 코어, 전체 GPU당 14592개의 FP32 CUDA 코어
• SM당 4개의 4세대 Tensor 코어, GPU당 456개
• 80GB HBM2e, HBM2e 스택 5개, 512비트 메모리 컨트롤러 10개
• 50MB L2 캐시
• 4세대 NVLink 및 PCIe Gen 5
TSMC 4N 제조 프로세스를 사용하면 TSMC 7nm N7 프로세스에 기반한 이전 세대인 GA100 GPU보다 H100 GPU 코어 주파수를 높이고 와트당 성능을 개선하며 더 많은 GPC, TPC, SM을 통합할 수 있습니다.
그림 3은 144개의 SM을 갖춘 GH100 GPU 전체 모습을 보여줍니다. H100 SXM5 GPU에는 132개의 SM이 있으며 PCIe 버전은 114개의 SM이 있습니다. H100 GPU는 주로 AI, HPC, 데이터 분석을 위해 데이터센터 및 엣지 컴퓨팅 워크로드를 실행하도록 제작되었으며 그래픽 처리는 하지 않습니다. SXM5 및 PCIe H100 GPU 모두에서 단 2개의 TPC만이 그래픽 기능(정점, 지오메트리, 픽셀 셰이더 실행 가능)을 지원합니다.
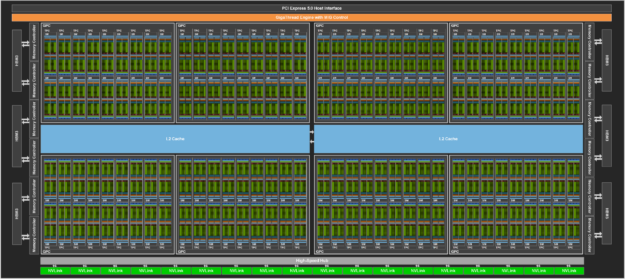
H100 SM 아키텍처
NVIDIA A100 Tensor 코어 GPU SM 아키텍처를 기반으로 빌드된 H100 SM은 FP8의 도입으로 SM당 A100의 최대 부동 소수점 연산 능력을 4배, 이전의 모든 Tensor 코어, FP32 및 FP64 데이터 유형, 클럭마다 A100의 본래 SM 컴퓨팅 성능은 두 배가 되었습니다.
NVIDIA Hopper FP8 Tensor 코어와 결합된 새로운 트랜스포머 엔진은 이전 세대 A100에 비해 대형 언어 모델에서 AI 추론 속도가 30배, AI 트레이닝이 최대 9배 더 빨라집니다. 새로운 NVIDIA Hopper DPX 명령어는 유전체학 및 단백질 염기서열 분석을 위한 스미스-워터맨 알고리즘을 최대 7배 빠르게 처리할 수 있습니다.
새로운 NVIDIA Hopper 4세대 Tensor 코어, Tensor 메모리 가속기 및 기타 여러가지 새로운 SM 및 일반적인 H100 아키텍처 개선 사항으로 대부분의 경우에서 최대 3배 빠른 HPC 및 AI 성능을 제공합니다.
| NVIDIA H100 SXM51 | NVIDIA H100 PCIe1 | |
| 최고 FP641 | 30TFLOPS | 24TFLOPS |
| 최고 FP64 Tensor 코어1 | 60TFLOPS | 48TFLOPS |
| 최고 FP321 | 60TFLOPS | 48TFLOPS |
| 최고 FP161 | 120TFLOPS | 96TFLOPS |
| 최고 BF161 | 120TFLOPS | 96TFLOPS |
| 최고 TF32 Tensor 코어1 | 500TFLOPS | 1000TFLOPS2 | 400TFLOPS | 800TFLOPS2 |
| 최고 FP16 Tensor 코어1 | 1000TFLOPS | 2000TFLOPS2 | 800TFLOPS | 1600TFLOPS2 |
| 최고 BF16 Tensor 코어1 | 1000TFLOPS | 2000TFLOPS2 | 800TFLOPS | 1600TFLOPS2 |
| 최고 FP8 Tensor 코어1 | 2000TFLOPS | 4000TFLOPS2 | 1600TFLOPS | 3200TFLOPS2 |
| 최고 INT8 Tensor 코어1 | 2000TOPS | 4000TOPS2 | 1600TOPS | 3200TOPS2 |
1. H100의 예비 성능 추정치는 현재의 예상에 의거한 수치이며 실제 배송된 제품에서는 다를 수 있습니다.
2. Sparsity 기능을 사용한 실질적인 TFLOPS 및 TOPS입니다.
H100 SM 핵심 기능 요약
• 4세대 Tensor 코어
o SM당 속도 향상, 늘어난 SM 수, H100의 더 높은 클럭을 갖추고 있어 A100에 비해 칩 간 속도가 최대 6배 더 빠릅니다.
o SM당 기준으로 Tensor 코어는 이전 세대의 16비트 부동 소수점 옵션과 비교하여 동급 데이터 유형에서 A100 SM의 MMA(Matrix Multiply-Accumulate) 계산 속도의 2배, 새로운 FP8 데이터 유형을 사용하면 A100 속도의 4배를 제공합니다.
o Sparsity 기능은 딥 러닝 네트워크에서 세분화된 구조적 Sparsity를 이용하여 표준 Tensor 코어 작업 성능을 두 배로 높입니다.
• 새로운 DPX 명령어는 동적 프로그래밍 알고리즘을 A100 GPU보다 최대 7배나 가속화합니다. 두 가지 예로는 유전체학 처리를 위한 스미스-워터맨 알고리즘과 동적인 창고 환경 사이로 수많은 로봇을 위한 최적의 경로를 찾는 데 사용되는 플로이드-워셜 알고리즘이 있습니다.
• SM당 2배 더 빠른 클럭당 성능과 늘어난 SM 수, H100의 더 높은 클럭으로 인해 A100보다 칩 간의 처리 속도가 3배 더 빠른 IEEE FP64 및 FP32.
• A100보다 1.33배 더 커진 256KB의 결합 공유 메모리와 L1 데이터 캐시.
• 새로운 비동기 실행 기능에는 글로벌 메모리와 공유 메모리 간에 대용량 데이터를 효율적으로 전송할 수 있는 새로운 Tensor 메모리 가속기(TMA) 장치가 포함됩니다. TMA는 또한 클러스터의 스레드 블록 간의 비동기 복사도 지원합니다. 원자적 데이터 이동 및 동기화를 위한 새로운 비동기 트랜잭션 장벽도 있습니다.
• 새로운 스레드 블록 클러스터 기능을 통해 여러 SM에서 로컬성을 제어할 수 있습니다.
• 분산 공유 메모리는 여러 SM 공유 메모리 블록에서 로드, 저장 및 원자성에 대해 SM과 SM 간의 직접적인 통신을 가능하게 합니다.
H100 Tensor 코어 아키텍처
Tensor 코어는 AI 및 HPC 애플리케이션에 획기적인 성능을 제공하는 행렬 곱셈 및 누산(MMA) 수학 연산에 전문화된 고성능 컴퓨팅 코어입니다. NVIDIA GPU 한 개에서 SM 간에 병렬로 작동하는 Tensor 코어는 표준 부동 소수점(FP), 정수(INT), 융합 곱셈 누산(FMA) 연산에 비해 처리량과 효율성이 대폭 증가했습니다.
Tensor 코어는 NVIDIA V100 GPU에 처음 도입되었고 새로운 NVIDIA GPU 아키텍처 세대마다 매번 향상되었습니다.
H100의 새로운 4세대 Tensor 코어 아키텍처는 클럭당 원시 고밀도 및 Sparsity한 행렬 수학 처리량에서 A100에 비해 SM당 2배 더 높으며 GPU 부스트 클럭 또한 A100보다 H100이 더 높다는 것을 고려할 때 처리량은 더 증가합니다. 지원되는 데이터 유형은 FP8, FP16, BF16, TF32, FP64, INT8 MMA입니다. 또한 새로운 Tensor 코어는 더 효율적인 데이터 관리 기능을 갖추고 있으며 피연산자 전달 전력을 최대 30% 절약할 수 있습니다.
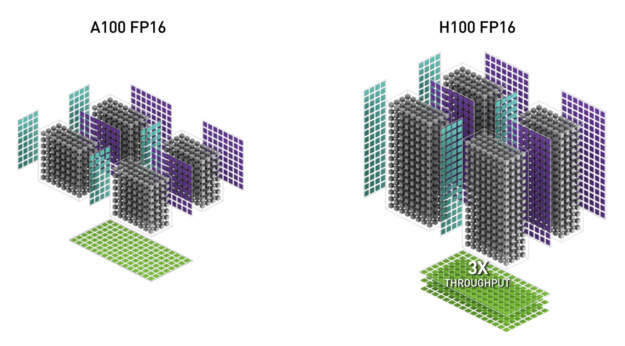
NVIDIA Hopper FP8 데이터 형식
H100 GPU에 FP8 Tensor 코어를 추가하여 AI 트레이닝과 추론을 모두 가속화합니다. 그림 6에서 보듯이 FP8 Tensor 코어는 FP32 및 FP16 누산기와 다음의 새로운 FP8 입력 유형 두 가지를 지원합니다.
• E4M3(지수 4비트, 가수 3비트)와 1개의 부호 비트
• E5M2(지수 5비트, 가수 2비트)와 1개의 부호 비트
E4M3는 좁은 동적 범위와 높은 정밀도를 지원하는 반면 E5M2는 넓은 동적 범위와 낮은 정밀도를 가집니다. FP8은 FP16 또는 BF16에 비해 데이터 스토리지 요구 사항을 절반으로 줄이고 처리량을 두 배로 늘립니다.
이 게시물의 후반부에 설명할 새로운 트랜스포머 엔진은 FP8 및 FP16 정밀도를 모두 사용하여 메모리 사용량을 줄이고 성능을 높이면서도 대형 언어 모델을 비롯한 기타 모델의 정확도를 유지합니다.
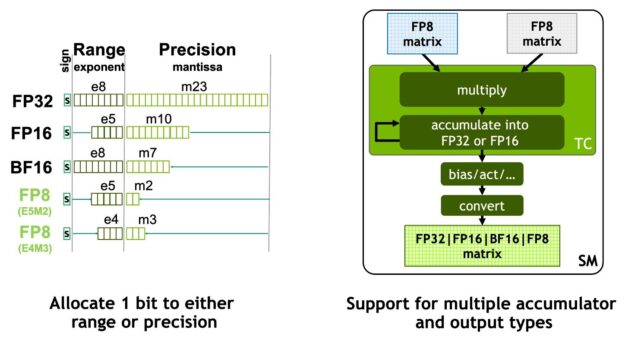
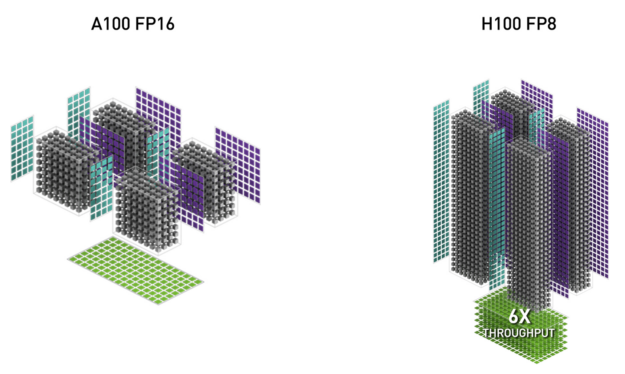
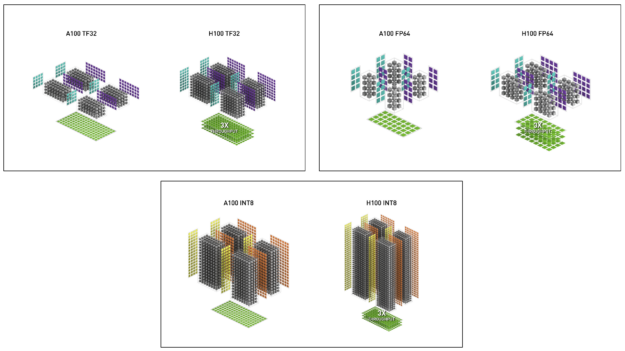
표 2는 여러 데이터 유형에 대해 A100보다 향상된 H100 성능을 보여줍니다.
| (TFLOPS 단위 측정) | A100 | A100 Sparsity | H100 SXM51 | H100 SXM51 Sparsity | H100 SXM51 속도 향상(A100 대비) |
| FP8 Tensor 코어 | 2000 | 4000 | 6.4배(A100 FP16 대비) | ||
| FP16 | 78 | 120 | 1.5배 | ||
| FP16 Tensor 코어 | 312 | 624 | 1000 | 2000 | 3.2배 |
| BF16 Tensor 코어 | 312 | 624 | 1000 | 2000 | 3.2배 |
| FP32 | 19.5 | 60 | 3.1배 | ||
| TF32 Tensor 코어 | 156 | 312 | 500 | 1000 | 3.2배 |
| FP64 | 9.7 | 30 | 3.1배 | ||
| FP64 Tensor 코어 | 19.5 | 60 | 3.1배 | ||
| INT8 Tensor 코어 | 624TOPS | 1248TOPS | 2000 | 4000 | 3.2배 |
모든 성능 수치는 예상치이며 실제 제품에서는 다를 수 있습니다.
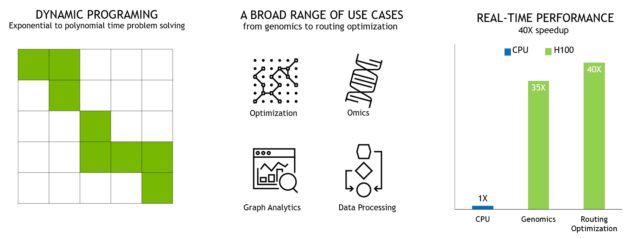
가속화 동적 프로그래밍을 위한 새로운 DPX 명령어
무차별 대입 최적화 알고리즘의 상당수는 더 큰 문제를 해결할 때 하위 문제 솔루션을 여러 번 재사용한다는 속성이 있습니다. 동적 프로그래밍(DP)은 복잡한 재귀 문제를 더 단순한 하위 문제로 세분화하여 해결하는 알고리즘 기술입니다. 다시 계산할 필요 없이 하위 문제의 결과를 저장함으로써 DP 알고리즘은 문제 세트의 기하급수적인 계산 복잡성을 선형 정도로 줄입니다.
DP는 일반적으로 광범위한 최적화, 데이터 처리 및 유전체학 알고리즘에 사용됩니다.
• 빠르게 성장하는 유전자 서열 분야에서 쓰이고 있는 스미스-워터맨 DP 알고리즘은 가장 중요한 방법 중 하나입니다.
• 로보틱스 분야에서 플로이드-워셜 알고리즘은 동적인 창고 환경 사이로 수많은 로봇을 위한 실시간 최적의 경로를 찾는 데 사용되는 핵심 알고리즘입니다.
H100은 DPX 명령어를 도입하여 NVIDIA Ampere GPU 대비 DP 알고리즘 성능을 최대 7배까지 가속화합니다. 이 새로운 명령어는 많은 DP 알고리즘의 내부 루프에 대한 고급 융합 피연산자를 지원합니다. 이를 통해 질병 진단, 물류 라우팅 최적화뿐 아니라 그래프 분석에서 솔루션까지 시간을 획기적으로 단축할 수 있습니다.
H100 컴퓨팅 성능 요약
전반적으로 H100은 H100의 모든 새로운 컴퓨팅 기술 발전을 고려할 때 A100보다 약 6배 향상된 컴퓨팅 성능을 제공합니다. 그림 10은 H100의 개선 사항을 계단식으로 요약한 것입니다.
• A100의 SM 108개보다 22% 증가한 132개의 SM
• 새로운 4세대 Tensor 코어 덕분에 각각의 H100 SM 속도는 2배 더 빠릅니다.
• 각 Tensor 코어 내에서 새로운 FP8 형식 및 관련 트랜스포머 엔진은 또 다른 2배 개선을 이루었습니다.
• 또한 H100의 클럭 주파수 증가로 성능이 약 1.3배 향상되었습니다.
전체적으로 이러한 개선 사항을 통해 H100의 최대 컴퓨팅 처리량은 A100보다 6배 증가했으며 이는 전 세계에서 컴퓨팅이 가장 많이 필요한 워크로드를 위한 큰 도약입니다.
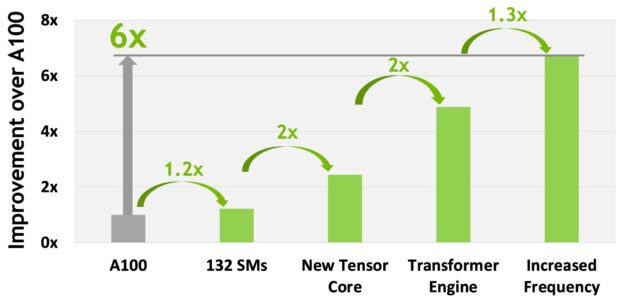
그림 10. H100 컴퓨팅 개선 사항 요약
H100은 전 세계에서 컴퓨팅이 가장 많이 필요한 워크로드를 위해 6배 증가한 처리량을 제공합니다.
H100 GPU 계층 구조 및 비동기 개선 사항
병렬 프로그램에서 고성능을 달성하기 위해 필수적인 두 가지 핵심은 데이터 로컬성과 비동기 실행입니다. 프로그래머 입장에서 프로그램 데이터가 실행 장치에 최대한 가깝게 이동하면 로컬 데이터에 액세스하는 지연 시간이 줄어들고 더 넓은 대역폭도 활용할 수 있습니다. 비동기 실행에는 메모리 전송 및 기타 처리와 중첩할 수 있는 독립적인 작업을 찾는 것이 포함됩니다. 목표는 GPU의 모든 장치를 완전히 사용하는 것입니다.
다음 섹션에서는 단일 SM에서 단일 스레드 블록보다 큰 규모로 로컬성을 제공하는 NVIDIA Hopper의 GPU 프로그래밍 계층 구조에 추가된 중요한 새로운 티어를 살펴봅니다. 또한 성능을 개선하고 동기화 오버헤드를 줄이는 새로운 비동기 실행 기능에 대해서도 설명합니다.
스레드 블록 클러스터
CUDA 프로그래밍 모델은 여러 스레드 블록을 포함하는 그리드를 사용하여 프로그램의 로컬성을 활용하는 GPU 컴퓨팅 아키텍처에 오랫동안 의존해 왔습니다. 스레드 블록에는 단일 SM에서 동시에 실행되는 여러 스레드가 포함되어 있으며 이 블록에서 스레드는 빠른 장벽과 동기화하고 SM의 공유 메모리를 사용하여 데이터를 교환할 수 있습니다. 그러나 GPU의 SM이 100개 이상으로 늘어나고 컴퓨팅 프로그램이 더 복잡해지면서 프로그래밍 모델에서 표현되는 유일한 로컬성 장치인 스레드 블록은 실행 효율성을 극대화하기에 충분하지 않습니다.
H100은 단일 SM의 단일 스레드 블록보다 큰 단위에서 로컬성을 제어하는 새로운 스레드 블록 클러스터 아키텍처를 도입했습니다. 스레드 블록 클러스터는 스레드, 스레드 블록, 스레드 블록 클러스터, 그리드를 포함하도록 GPU의 물리적 프로그래밍 계층 구조에 또 다른 수준을 추가하고 CUDA 프로그래밍 모델을 확장했습니다.
클러스터는 SM 그룹에 동시 예약이 보장되는 스레드 블록 그룹으로 여러 SM에서 스레드의 효율적인 협력을 가능하게 하는 것이 목표입니다. H100의 클러스터는 GPC 내 SM에서 동시에 실행됩니다.
GPC는 항상 물리적으로 근접하게 함께 있는 하드웨어 계층 구조의 SM 그룹입니다. 클러스터에는 하드웨어 가속화 장벽과 다음 섹션에서 설명할 새로운 메모리 액세스 협업 기능이 있습니다. GPC의 SM과 SM 간의 전용 네트워크는 클러스터의 스레드 사이에서 빠르게 데이터를 공유합니다.
CUDA에서 그리드의 스레드 블록은 그림 11에서 볼 수 있듯이 커널 시작 시 클러스터로 임의 그룹화할 수 있으며 클러스터 기능은 CUDA cooperative_groups API에서 활용될 수 있습니다.
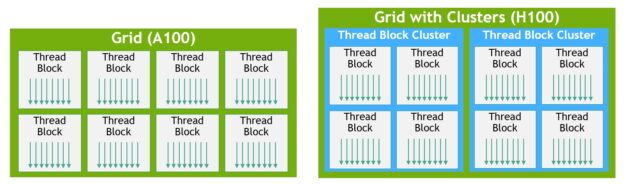
그림 11. 스레드 블록 클러스터와 클러스터가 있는 그리드
그리드는 다이어그램의 왼쪽에 보이는 A100에서처럼 레거시 CUDA 프로그래밍 모델의 스레드 블록으로 구성됩니다. NVIDIA Hopper 아키텍처는 다이어그램의 오른쪽에 보이는 클러스터 계층 구조 옵션을 추가합니다.
분산 공유 메모리
클러스터를 사용하면 모든 스레드가 로드, 저장, 원자적 연산을 통해 다른 SM의 공유 메모리에 직접 액세스할 수 있습니다. 이 기능은 공유 메모리 가상 주소 공간이 클러스터의 모든 블록에 논리적으로 분산되므로 분산 공유 메모리(DSMEM)이라고 합니다.
DSMEM을 사용하면 더 이상 글로벌 메모리에서 데이터를 작성하고 읽지 않아도 되기 때문에 SM 간에 더 효율적인 데이터 교환이 가능합니다. 클러스터 전용 SM과 SM 간의 네트워크는 원격 DSMEM에 대해 빠르고 짧은 지연 시간 액세스를 보장합니다. DSMEM은 글로벌 메모리를 사용할 때와 비교해 스레드 블록 간 데이터 교환을 약 7배 가속화합니다.
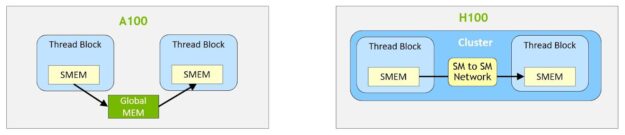
그림 12. 스레드 블록과 스레드 블록 간의 데이터 교환(A100과 클러스터가 있는 H100 비교)
CUDA 수준에서 클러스터에 포함된 모든 스레드 블록의 모든 DSMEM 세그먼트는 각 스레드의 일반 주소 공간에 매핑되어 모든 DSMEM을 간단한 포인터로 직접 참조할 수 있습니다. CUDA 사용자는 cooperative_groups API를 활용하여 클러스터의 모든 스레드 블록에 대한 일반 포인터를 구성할 수 있습니다. 또한 DSMEM 전송은 완료 추적을 위한 공유 메모리 기반 장벽과 동기화된 비동기 복사 작업으로 표시될 수도 있습니다.
그림 13은 다른 알고리즘에서 클러스터를 사용할 때의 성능 이점을 보여줍니다. 클러스터는 단일 SM보다 GPU의 더 많은 부분을 직접 제어할 수 있도록 하여 성능을 개선합니다. 클러스터는 더 많은 수의 스레드와 협력 실행을 가능하게 하며 단일 스레드 블록으로 가능한 것보다 더 큰 공유 메모리 풀에 액세스할 수 있습니다.
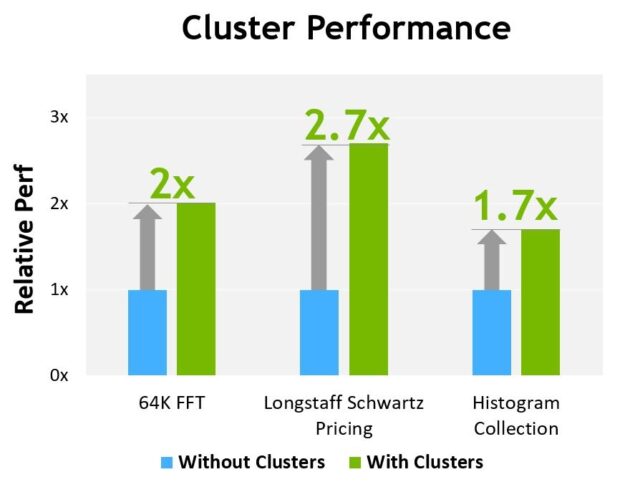
H100의 예비 성능 추정치는 현재의 기대에 의거한 수치이며 실제 배송 제품에서는 다를 수 있습니다.
비동기 실행
차세대 NVIDIA GPU마다 성능, 프로그래밍 기능, 전력 효율성, GPU 사용률, 기타 여러 요인을 개선하기 위한 수많은 아키텍처 개선 사항이 포함되어 있습니다. 최근 NVIDIA GPU 세대에는 데이터 이동, 컴퓨팅, 동기화가 더 많이 중첩되도록 하기 위해 비동기 실행 기능이 포함되어 있습니다.
NVIDIA Hopper 아키텍처는 동기화 지점을 최소화하하면서도 비동기 실행을 개선하고 컴퓨팅 및 기타 독립 작업과 메모리 복사본을 더 많이 중첩할 수 있도록 하는 새로운 기능을 제공합니다. Tensor 메모리 가속기(TMA)라고 하는 새로운 비동기 메모리 복사 장치와 새로운 비동기 트랜잭션 장벽을 설명합니다.
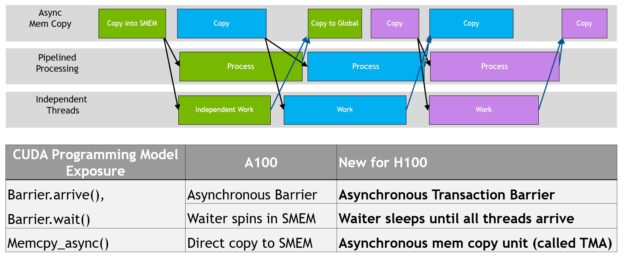
데이터 이동, 계산, 동기화가 프로그래밍 방식으로 중첩됩니다. 비동기 동시성과 동기화 지점 최소화는 성능의 핵심입니다.
Tensor 메모리 가속기
강력하고 새로운 H100 Tensor 코어의 피드를 돕기 위해 새로운 Tensor 메모리 가속기(TMA)로 데이터 가져오기 효율성이 개선되었습니다. 이 TMA는 대규모 데이터 블록과 다차원 Tensor를 글로벌 메모리에서 공유 메모리로 다시 전송할 수 있습니다.
TMA 작업은 요소별 주소 지정 대신 Tensor 차원 및 블록 좌표를 사용하여 데이터 전송을 지정하는 디스크립터 복사를 사용하여 시작됩니다(그림 15). 대용량 데이터 블록을 최대 공유 메모리 용량까지 지정하고 글로벌 메모리에서 공유 메모리로 로드하거나 공유 메모리에서 글로벌 메모리로 다시 저장할 수 있습니다. TMA는 다양한 텐서 레이아웃(1D ~ 5D Tensor), 서로 다른 메모리 액세스 모드, 감소 및 기타 기능을 지원하여 주소 지정 오버헤드를 크게 줄이고 효율성을 개선합니다.
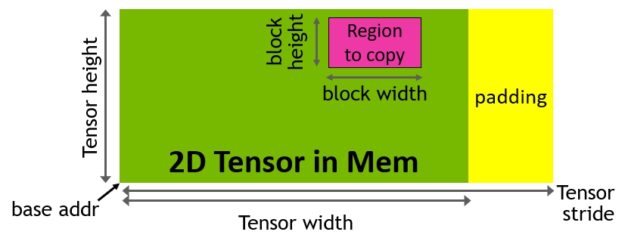
TMA 작업은 비동기식이며 A100에 도입되었던 공유 메모리 기반 비동기 장벽을 활용합니다. 또한 TMA 프로그래밍 모델은 단일 스레드이며 비동기 TMA 작업(cuda:memcpy_async)을 실행하여 Tensor를 복사하도록 워프의 단일 스레드가 선택됩니다. 그 결과 여러 스레드는 cuda:장벽에서 데이터 전송이 완료되기를 기다릴 수 있습니다. 이러한 비동기 장벽 대기 작업을 가속화하는 하드웨어를 H100 SM에 추가하여 성능을 더욱 개선할 수 있습니다.
TMA의 주요 장점은 스레드를 자유롭게 하여 다른 독립적인 작업을 실행할 수 있다는 것입니다. A100(그림 16의 왼쪽)에서 비동기 메모리 복사는 특수 LoadGlobalStoreShared 명령어를 사용하여 실행되었으므로 스레드는 모든 주소를 생성하고 전체 복사 영역에 걸쳐 작업을 반복했습니다.
NVIDIA Hopper에서는 TMA가 모든 것을 처리합니다. 단일 스레드는 TMA를 시작하기 전에 디스크립터 복사를 생성하고 그로부터 주소 생성과 데이터 이동은 하드웨어에서 처리됩니다. TMA는 Tensor의 세그먼트를 복사할 때 스트라이드, 오프셋, 경계 계산을 컴퓨팅하는 작업을 대신하기 때문에 훨씬 간단한 프로그래밍 모델을 제공합니다.
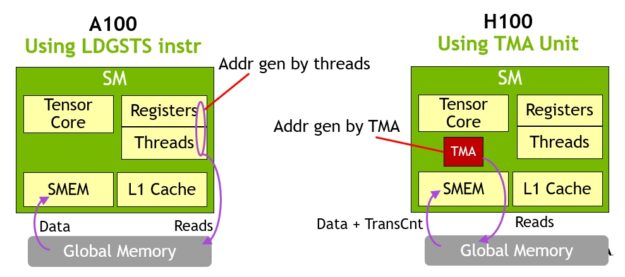
그림 16. A100의 LDGSTS를 사용한 비동기 메모리 복사와 H100의 TMA를 사용한 비동기 메모리 복사
비동기 트랜잭션 장벽
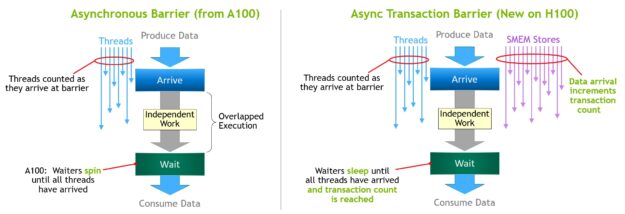
비동기 장벽은 원래 NVIDIA Ampere 아키텍처에 도입되었습니다(그림 17의 왼쪽). 스레드 세트가 장벽 이후로는 모두 소비하는 데이터를 생성하는 예를 생각해 봅시다. 비동기 장벽은 동기화 프로세스를 두 단계로 분할합니다.
• 먼저 스레드는 공유 데이터의 일부 생성이 완료되면 도착 신호를 내보냅니다. 이 도착 신호는 스레드가 다른 독립적인 작업을 자유롭게 실행할 수 있도록, 차단되지 않습니다.
• 결국 스레드는 다른 모든 스레드에서 생성된 데이터를 필요로 합니다. 이 때 모든 스레드가 도착신호를 보낼 때까지 대기하며 차단합니다.
비동기 장벽의 장점은 일찍 도착한 스레드가 대기 하는 동안 독립적인 작업을 실행할 수 있습니다. 이 중첩이 추가 성능의 원천입니다. 모든 스레드에 대해 독립 작업이 충분하다면 모든 스레드가 이미 도착했다는 뜻이고 대기 명령어를 즉시 폐기할 수 있기 때문에 장벽이 효과적으로 자유로워집니다.
NVIDIA Hopper의 새로운 기능은 다른 모든 스레드가 도착할 때까지 스레드를 대기시키는 기능입니다. 이전 칩에서는 대기 스레드가 공유 메모리의 장벽 개체에서 돌고 있었습니다.
비동기 장벽은 여전히 NVIDIA Hopper 프로그래밍 모델의 일부분으로 남아있지만 비동기 트랜잭션 장벽이라는 새로운 형태의 장벽을 추가했습니다. 비동기 트랜잭션 장벽은 비동기 장벽과 유사합니다(그림 17의 오른쪽). 이 또한 분할 장벽이지만 스레드 도착만 계산하는게 아니라 트랜잭션도 계산합니다.
NVIDIA Hopper에는 기록할 데이터와 트랜잭션 수를 모두 전달하는 공유 메모리 쓰기 위한 새로운 명령어가 포함되어 있습니다. 트랜잭션 수는 기본적으로 바이트 수입니다. 비동기 트랜잭션 장벽은 모든 생산자 스레드가 도착하고 모든 트랜잭션 수의 합이 예상 값에 도달할 때까지 대기 명령에서 스레드를 차단합니다.
비동기 트랜잭션 장벽은 비동기 메모리 복사 또는 데이터 교환을 위한 강력하고 새로운 기초 요소입니다. 앞서 언급했듯이 클러스터는 암묵적 동기화를 통해 데이터 교환을 위한 스레드 블록 간 통신을 할 수 있으며 해당 클러스터 기능은 비동기 트랜잭션 장벽 위에 구축됩니다.
H100 HBM 및 L2 캐시 메모리 아키텍처
GPU의 메모리 아키텍처와 계층 구조의 설계는 애플리케이션 성능에 매우 중요하며 GPU 크기, 비용, 전력 사용량, 프로그래밍 기능에 영향을 미칩니다. 오프칩 DRAM(프레임 버퍼) 장치 메모리의 대규모 보완과 다양한 레벨 및 유형의 온-칩 메모리부터 SM에서 계산에 사용되는 레지스터 파일에 이르기까지 많은 메모리 하위 시스템이 GPU에 존재합니다.
H100 HBM3 및 HBM2e DRAM 하위 시스템
HPC, AI 및 데이터 분석 데이터 세트의 크기가 계속 증가하고 컴퓨팅 문제는 점점 더 복잡해짐에 따라 더 큰 GPU 메모리 용량과 대역폭은 필수가 되었습니다.
• NVIDIA P100은 고대역폭 HBM2 메모리 기술을 지원하는 세계 최초의 GPU 아키텍처입니다.
• NVIDIA V100은 훨씬 더 빠르고 효율적이며 더 높은 용량의 HBM2를 구현했습니다.
• NVIDIA A100 GPU는 HBM2의 성능과 용량을 더욱 향상시켰습니다.
H100 SXM5 GPU는 80GB(5개의 스택)의 고속 HBM3 메모리를 지원하고 3TB/s 이상의 메모리 대역폭을 제공하여 그 기준을 한층 끌어 올렸으며 불과 2년 전에 출시된 A100의 메모리 대역폭보다 사실상 2배 더 증가했습니다. PCIe H100은 2TB/s 이상의 메모리 대역폭과 80GB의 고속 HBM2e를 제공합니다.
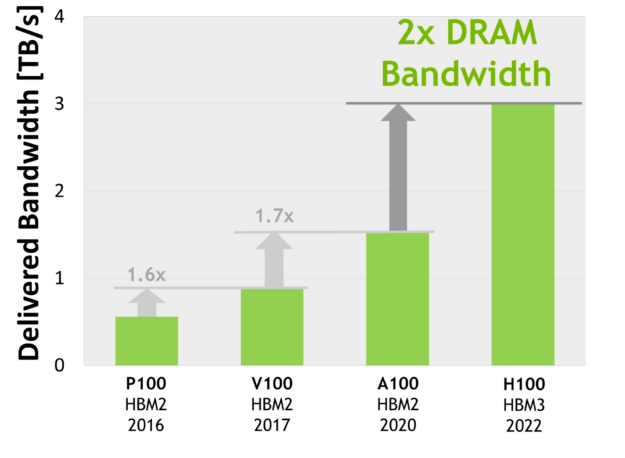
메모리 데이터 속도는 최종 확정되지 않았으며 최종 제품과 다를 수 있습니다.
H100 L2 캐시
H100은 A100 40MB L2 캐시에서 1.25배 늘어난 50MB L2 캐시를 가졌습니다. 늘어난 L2 캐시는 모델 및 데이터 세트의 더 큰 부분을 캐싱하여 반복적인 액세스를 가능하게 하고 HBM3 또는 HBM2e DRAM으로의 이동이 줄어들며 성능 또한 개선됩니다.
분할된 크로스바 구조를 사용하여 L2 캐시는 파티션에 직접 연결된 GPC에서 SM에서 메모리 액세스를 위해 데이터를 로컬화하고 캐싱합니다. L2 캐시 상주 제어는 용량 활용을 최적화하여 캐시에 남아 있거나 제거해야 하는 데이터를 선택적으로 관리할 수 있도록 지원합니다.
HBM3 또는 HBM2e DRAM, L2 캐시 하위 시스템은 모두 데이터 압축 및 압축 해제 기술을 지원하며 메모리와 캐시의 사용량, 성능을 모두 최적화합니다.
| GPU 기능 | NVIDIA A100 | NVIDIA H100 SXM51 | NVIDIA H100 PCIe1 |
| GPU 아키텍처 | NVIDIA Ampere | NVIDIA Hopper | NVIDIA Hopper |
| GPU 보드 폼 팩터 | SXM4 | SXM5 | PCIe Gen 5 |
| SM | 108 | 132 | 114 |
| TPC | 54 | 66 | 57 |
| SM당 FP32 코어 수 | 64 | 128 | 128 |
| GPU당 FP32 코어 수 | 6912 | 16896 | 14592 |
| SM당 FP64 코어 수(Tensor 제외) | 32 | 64 | 64 |
| CPU당 FP64 코어 수(Tensor 제외) | 3456 | 8448 | 7296 |
| SM당 INT32 코어 수 | 64 | 64 | 64 |
| GPU당 INT32 코어 수 | 6912 | 8448 | 7296 |
| SM당 Tensor 코어 수 | 4 | 4 | 4 |
| GPU당 Tensor 코어 수 | 432 | 528 | 456 |
| GPU 부스트 클럭 (H100의 경우 최종 확정되지 않음)3 | 1410MHz | 최종 확정되지 않음 | 최종 확정되지 않음 |
| 최대 FP8 Tensor TFLOPS(FP16 누산 포함)1 | 해당 없음 | 2000/40002 | 1600/32002 |
| 최대 FP8 Tensor TFLOPS(FP32 누산 포함)1 | 해당 없음 | 2000/40002 | 1600/32002 |
| 최대 FP16 Tensor TFLOPS(FP16 누산 포함)1 | 312/6242 | 1000/20002 | 800/16002 |
| 최대 FP16 Tensor TFLOPS(FP32 누산 포함)1 | 312/6242 | 1000/20002 | 800/16002 |
| 최대 BF16 Tensor TFLOPS(FP32 누산 포함)1 | 312/6242 | 1000/20002 | 800/16002 |
| 최대 TF32 Tensor TFLOPS1 | 156/3122 | 500/10002 | 400/8002 |
| 최대 FP64 Tensor TFLOPS1 | 19.5 | 60 | 48 |
| 최대 INT8 Tensor TOPS1 | 624/12482 | 2000/40002 | 1600/32002 |
| 최대 FP16 TFLOPS(Tensor 외)1 | 78 | 120 | 96 |
| 최대 BP16 TFLOPS(Tensor 외)1 | 39 | 120 | 96 |
| 최대 FP32 TFLOPS(Tensor 외)1 | 19.5 | 60 | 48 |
| 최대 FP64 TFLOPS(Tensor 외)1 | 9.7 | 30 | 24 |
| 최대 INT32 TOPS1 | 19.5 | 30 | 24 |
| 텍스처 유닛 | 432 | 528 | 456 |
| 메모리 인터페이스 | 5120비트 HBM2 | 5120비트 HBM3 | 5120비트 HBM2e |
| 메모리 크기 | 40GB | 80GB | 80GB |
| 메모리 데이터 속도 (H100의 경우 최종 확정되지 않음) 1 | 1215MHz DDR | 최종 확정되지 않음 | 최종 확정되지 않음 |
| 메모리 대역폭1 | 1555GB/sec | 3000GB/sec | 2000GB/sec |
| L2 캐시 크기 | 40MB | 50MB | 50MB |
| SM당 공유 메모리 크기 | 최대 164KB 구성 가능 | 최대 228KB 구성 가능 | 최대 228KB 구성 가능 |
| SM당 레지스터 파일 크기 | 256KB | 256KB | 256KB |
| GPU당 레지스터 파일 크기 | 27648KB | 33792KB | 29184KB |
| TDP1 | 400W | 700W | 350W |
| 트랜지스터 | 542억 개 | 800억 개 | 800억 개 |
| GPU 다이 크기 | 826mm2 | 814mm2 | 814mm2 |
| TSMC 제조 프로세스 | 7nm N7 | NVIDIA에 맞춤화된 4N | NVIDIA에 맞춤화된 4N |
1. H100의 예비 사양은 현재의 예상에 의거한 수치이며 실제 배송된 제품에서는 다를 수 있습니다.
2. Sparsity 기능을 사용한 효과적인 TFLOPS 및 TOPS입니다.
3. NVIDIA 데이터센터 GPU의 경우 GPU 최대 클럭과 GPU 부스트 클럭은 같은 뜻을 갖습니다.
H100 및 A100 Tensor 코어 GPU는 AI 및 HPC 컴퓨팅 워크로드를 구동할 목적으로 고성능 서버 및 데이터센터 랙에 설치되도록 설계되었기 때문에 디스플레이 커넥터, 레이 트레이싱 가속화를 위한 NVIDIA RT 코어 또는 NVENC 인코더가 포함되어 있지 않습니다.
컴퓨팅 성능
H100 GPU는 새로운 컴퓨팅 성능 9.0을 지원합니다. 표 4는 NVIDIA GPU 아키텍처에 대해 다양한 컴퓨팅 성능의 매개변수를 비교합니다.
| 데이터센터 GPU | NVIDIA V100 | NVIDIA A100 | NVIDIA H100 |
| GPU 아키텍처 | NVIDIA Volta | NVIDIA Ampere | NVIDIA Hopper |
| 컴퓨팅 성능 | 7.0 | 8.0 | 9.0 |
| 워프당 스레드 | 32 | 32 | 32 |
| SM당 최대 워프 | 64 | 64 | 64 |
| SM당 최대 스레드 | 2048 | 2048 | 2048 |
| SM당 최대 스레드 블록(CTA) | 32 | 32 | 32 |
| 스레드 블록 클러스터당 최대 스레드 블록 | 해당 없음 | 해당 없음 | 16 |
| SM당 최대 32비트 레지스터 | 65536 | 65536 | 65536 |
| 스레드 블록(CTA)당 최대 레지스터 | 65536 | 65536 | 65536 |
| 스레드당 최대 레지스터 | 255 | 255 | 255 |
| 최대 스레드 블록 크기(스레드 수) | 1024 | 1024 | 1024 |
| SM당 FP32 코어 수 | 64 | 64 | 128 |
| FP32 코어에 대한 SM 레지스터의 비율 | 1024 | 1024 | 512 |
| SM당 공유 메모리 크기 | 최대 96KB 구성 가능 | 최대 164KB 구성 가능 | 최대 228KB 구성 가능 |
트랜스포머 엔진
트랜스포머 모델은 BERT에서 GPT-3에 이르기까지 오늘날 널리 사용되는 언어 모델의 근간이며 엄청난 컴퓨팅 리소스를 필요로 합니다. 처음에는 자연어 처리(NLP)용으로 개발된 트랜스포머는 컴퓨터 비전, 신약 개발 등과 같은 다양한 분야에서 점점 더 많이 적용되고 있습니다.
그 크기 또한 기하급수적으로 계속 증가하여 지금은 수조 개의 매개변수에 도달했고 트레이닝 시간이 수개월로 늘어났습니다. 이는 대규모 컴퓨팅 요구 사항으로 인해 비즈니스적인 면에서 트랜스포머는 현실적이지 않습니다. 예를 들어 Megatron Turing NLG(MT-NLG)에는 트레이닝을 위해 2048개의 NVIDIA A100 GPU가 8주 동안 실행되어야 합니다. 전반적으로 트랜스포머 모델은 지난 5년 동안 2년마다 275배씩 다른 대부분의 AI 모델보다 훨씬 빠르게 성장하고 있습니다(그림 19).
H100에는 소프트웨어와 맞춤형 NVIDIA Hopper Tensor 코어 기술을 사용하여 트랜스포머의 AI 계산을 대폭 가속화하는 새로운 트랜스포머 엔진이 포함되어 있습니다.
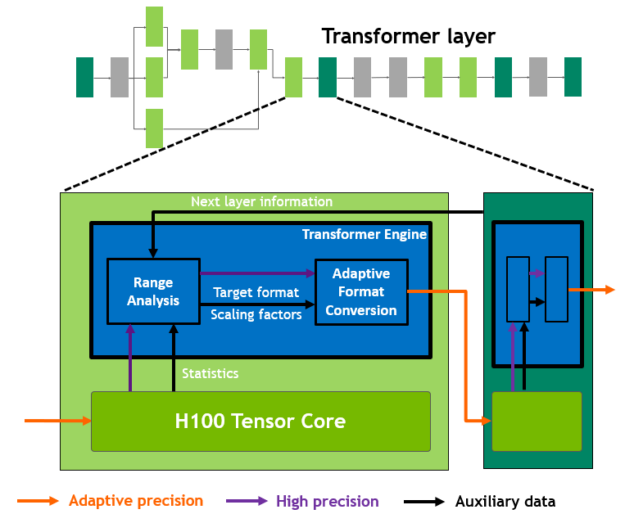
혼합 정밀도의 목표는 정밀도를 지능적으로 관리하여 정확도를 유지하면서도 더 작고 빠른 수치 형식의 성능을 얻는 것입니다. 트랜스포머 모델의 각 레이어에서 트랜스포머 엔진은 Tensor 코어에서 생성된 출력 값의 통계를 분석합니다.
다음에 어떤 유형의 신경망 계층이 오고 그것이 요구하는 정밀도에 대한 지식을 바탕으로 트랜스포머 엔진은 Tensor를 메모리에 저장하기 전에 어떤 대상 형식으로 변환할 것인지도 결정합니다. FP8은 다른 숫자 형식보다 범위가 한정되어 있습니다.
사용 가능한 범위를 최적으로 사용하기 위해 트랜스포머 엔진은 Tensor 통계에서 계산된 계수 인자를 사용하여 Tensor 데이터를 표현 가능한 범위에 맞게 동적으로 조정합니다. 따라서 모든 레이어는 정확히 필요한 범위로 작동하며 최적의 방식으로 가속화됩니다.
4세대 NVLink 및 NVLink 네트워크
슈퍼 휴먼 대화형 AI와 같은 작업을 위해 최근 떠오르고 있는 엑사스케일 HPC 및 조 단위 매개 변수의 AI 모델은 슈퍼컴퓨터에서도 트레이닝하는 데 몇 개월이 걸립니다. 이러한 트레이닝 시간을 몇 개월에서 며칠로 단축하여 비즈니스에 더 유용하게 활용하려면 서버 클러스터의 모든 GPU 간에 원활한 고속 통신이 필요합니다. PCIe는 제한된 대역폭으로 병목 현상을 일으킵니다. 가장 강력한 엔드 투 엔드 컴퓨팅 플랫폼을 구축하려면 속도와 확장성이 더욱 향상된 NVLink 상호 연결이 필요합니다.
NVLink는 데이터의 성공적인 전송을 보장하는 링크 수준 오류 감지 및 패킷 재생 메커니즘과 같은 복원 기능을 포함하는 NVIDIA 고대역폭, 에너지 효율, 저지연, 무손실 GPU와 GPU 간의 인터커넥트입니다. H100 GPU에 구현된 새로운 4세대 NVLink는 NVIDIA A100 Tensor 코어 GPU에 사용된 이전 3세대 NVLink 비해 1.5배 향상된 통신 대역폭을 제공합니다.
멀티 GPU I/O 및 공유 메모리 액세스를 위해 총 900GB/s의 대역폭으로 작동하는 새로운 NVLink는 PCIe Gen 5 대역폭보다 7배 향상되었습니다. A100 GPU의 3세대 NVLink는 각 방향에서 4개의 차동 쌍(레인)을 사용하여 각 방향마다 25GB/s의 유효한 대역폭을 가진 단일 링크를 생성합니다. 대조적으로 4세대 NVLink는 각 방향에서 단 두 개의 고속 차동 쌍만 사용하여 각 방향마다 25GB/s의 유효한 대역폭을 가진 단일 링크를 생성합니다.
• H100에는 18개의 4세대 NVLink 링크가 포함되어 있고 총 900GB/s 대역폭을 제공합니다.
• AH100에는 12개의 3세대 NVLink 링크가 포함되어 있고 총 600GB/s 대역폭을 제공합니다.
H100은 4세대 NVLink 외에도 여러 컴퓨팅 노드에서 최대 256개의 GPU와 GPU 간 통신을 지원하는 확장 가능한 새로운 NVLink 버전인 NVLink 네트워크 인터커넥트도 도입했습니다.
모든 GPU가 공통 주소 공간을 공유하고 요청이 발생하면 GPU의 물리적 주소를 사용하여 직접 라우팅하는 일반 NVLink와 달리 NVLink 네트워크는 새로운 네트워크 주소 공간을 사용합니다. H100의 새로운 주소 번역 하드웨어에서 지원하며 모든 GPU 주소 공간을 서로 분리하고 네트워크 주소 공간으로도 분리합니다. 이를 통해 NVLink 네트워크는 더 많은 GPU로 안전하게 확장할 수 있습니다.
NVLink 네트워크 엔드포인트는 공통 메모리 주소 공간을 공유하지 않으므로 NVLink 네트워크 연결이 전체 시스템에서 자동으로 정립되지는 않습니다. 대신, InfiniBand와 같은 다른 네트워킹 인터페이스와 유사하게 사용자 소프트웨어는 필요에 따라 엔드포인트 간 연결을 명시적으로 정립해야 합니다.
3세대 NVSwitch
새로운 3세대 NVSwitch 기술에는 노드 내부 및 외부에 모두 상주하는 스위치가 포함되어 서버, 클러스터 및 데이터센터 환경에서 여러 GPU를 연결합니다. 노드 내부의 새로운 NVSwitch는 각각 멀티 GPU 연결을 가속화하기 위해 4세대 NVLink 링크 포트를 64개 제공합니다. 총 스위치 처리량은 이전 세대의 7.2Tbits/s에서 13.6Tbits/s로 증가했습니다.
또한 새로운 3세대 NVSwitch는 멀티캐스트 및 NVIDIA SHARP 네트워크 내 감소를 사용하여 집합 연산의 하드웨어 가속화도 제공합니다. 가속화된 collective연산으로는 write broadcast(all_gather), reduce_scatter, broadcast atomics 연산이 포함됩니다. 구조적으로 멀티캐스트 및 감소를 사용하면 A100에서 NVIDIA Collective Communications Library(NCCL)를 사용하는 것보다 작은 블록 크기의 집합체에 대한 지연 시간을 크게 줄이면서도 처리량이 최대 2배 증가합니다. 집합체의 NVSwitch 가속화로 집합 통신을 위한 SM의 부하가 크게 줄어듭니다.
새로운 NVLink 스위치 시스템
NVIDIA는 새로운 NVLINK 네트워크 기술과 새로운 3세대 NVSwitch를 결합하여 전례 없는 수준의 통신 대역폭을 갖춘 대규모 NVLink 스위치 시스템 네트워크를 구축하고 있습니다. 각 GPU 노드는 노드에 있는 GPU가 가진 모든 NVLink 대역폭의 2:1 테이퍼 레벨을 보여줍니다. 노드는 컴퓨팅 노드 외부에 상주하며 여러 노드를 연결하는 NVLink 스위치 모듈에 포함된 두 번째 수준의 NVSwitch를 통해 함께 연결됩니다.
NVLink 스위치 시스템은 최대 256개의 GPU를 지원합니다. 연결된 노드는 전체 57.6TB의 대역폭을 제공할 수 있으며 놀라운 1엑사플롭의 FP8 Sparsity AI 컴퓨팅을 제공할 수 있습니다.
그림 21은 A100과 H100 기반의 32노드, 256개의 GPU DGX SuperPOD를 비교한 것입니다. H100 기반의 SuperPOD는 선택적으로 새로운 NVLink 스위치를 사용하여 DGX 노드를 상호 연결합니다.
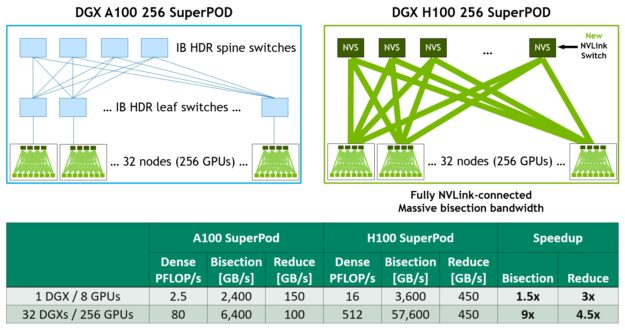
DGX H100 SuperPOD는 3세대 NVSwitch 기술을 기반으로 하는 새로운 NVLink 스위치를 사용하여 NVLink 스위치 시스템을 통해 완전히 연결되어 최대 256개의 GPU에 퍼져 있을 수 있습니다.
2:1 테이퍼 패트 트리 토폴로지에서의 NVLink 네트워크 인터커넥트는 전체 교환을 예로 들면 이등분 대역폭을 9배나 증가시키며 이전 세대 InfiniBand 시스템 대비 전체 감소 처리량을 4.5배 증가시킵니다. DGX H100 SuperPOD에는 NVLINK 스위치 시스템을 옵션으로 선택할 수 있습니다.
PCIe Gen 5
H100은 PCI Express Gen 5 16레인 인터페이스를 통합하여 A100에 사용되었던 Gen 4 PCIe에서 64GB/s였던 총 대역폭(각 방향에서 32GB/s)과 비교하여 총 대역폭은 128GB/s(각 방향에서 64GB/s)를 지원합니다.
H100은 PCIe Gen 5 인터페이스를 사용하여 최고 성능의 x86 CPU, SmartNIC, 데이터 처리 장치(DPU)와 인터페이싱할 수 있습니다. H100은 안전한 HPC 및 AI 워크로드를 위한 400Gb/s 이더넷 또는 NDR(Next Data Rate) 400Gb/s InfiniBand 네트워킹 가속화를 지원하는 NVIDIA BlueField-3 DPU와의 최적의 연결을 위해 설계되었습니다.
H100은 32비트 및 64비트 데이터 유형에 대한 원자적 CAS, 원자적 교환 및 원자적 가져오기와 같은 기본 PCIe 원자적 연산에 대한 지원을 추가하여 CPU와 GPU 간의 동기화 및 원자적 연산을 가속화합니다. H100은 또한 다중 프로세스 또는 VM을 위해 단일 PCIe에 연결된 GPU를 공유 및 가상화할 수 있는 단일 루트 IO 가상화(SR-IOV)를 지원합니다. H100을 사용하면 단일 SR-IOV PCIe에 연결된 GPU의 가상 함수(VF) 또는 물리적 함수(PF)가 NVLink 통해 피어 GPU에 액세스할 수 있습니다.
요약
애플리케이션 성능을 향상시키는 기타 새롭고 개선된 H100 기능에 대한 자세한 내용은 NVIDIA H100 Tensor 코어 GPU 아키텍처 백서를 참조하십시오.
도움 주신 분들
이 게시물에 도움을 주신 Stephen Jones, Manindra Parhy, Atul Kalambur, Harry Petty, Joe DeLaere, Jack Choquette, Mark Hummel, Naveen Cherukuri, Brandon Bell, Jonah Alben, 그리고 다른 많은 NVIDIA GPU 건축가 및 엔지니어에게 감사드립니다.