
프로덕션 환경에 거대 언어 모델(LLM)을 배포하려면 사용자 상호 작용을 향상시키는 것과 시스템 처리량을 늘리는 것 사이에서 어려운 절충점을 찾아야 하는 경우가 많습니다. 사용자 상호 작용을 향상하려면 첫 번째 토큰에 걸리는 시간(TTFT)을 최소화해야 하지만 처리량을 늘리려면 초당 토큰 수를 늘려야 합니다. 한 측면을 개선하면 다른 측면이 저하되는 경우가 많기 때문에 데이터센터, 클라우드 서비스 제공업체(CSP), AI 애플리케이션 제공업체는 적절한 균형을 찾기가 어렵습니다.
NVIDIA GH200 Grace Hopper 슈퍼칩을 활용하면 이러한 트레이드오프를 최소화할 수 있습니다. 이 포스팅에서는 IT 리더와 인프라 의사 결정권자가 NVIDIA GH200 Grace Hopper 슈퍼칩의 컨버지드 메모리 아키텍처를 활용하여 시스템 처리량에 대한 트레이드오프 없이 인기 있는 Llama 3 70B 모델에서 멀티턴 사용자 상호작용의 TTFT를 x86 기반 NVIDIA H100 서버 대비 최대 2배까지 높일 수 있는 방법을 살펴봅니다.
키-값 캐시 오프로딩
LLM 모델은 질문 답변, 요약, 코드 생성 등 다양한 사용 사례에서 빠르게 채택되고 있습니다. 이러한 모델은 사용자의 프롬프트에 응답하기 전에 입력 시퀀스와 검색 증강 생성(RAG)의 경우와 같이 추론 요청 중에 검색된 추가 정보에 대한 컨텍스트 이해를 구축해야 합니다.
이 프로세스에는 사용자의 프롬프트를 토큰으로 변환한 다음 고밀도 벡터로 변환하고, 프롬프트에 있는 모든 토큰 간의 관계를 수학적 표현으로 구축하기 위해 광범위한 도트 곱 연산을 수행하는 과정이 포함됩니다. 이 작업은 모델의 여러 레이어에서 반복됩니다. 프롬프트의 문맥적 이해를 생성하는 데 필요한 연산량은 입력 시퀀스 길이의 크기에 따라 4제곱으로 증가합니다.
키-값 캐시 또는 KV 캐시를 생성하는 이 컴퓨팅 집약적인 프로세스는 출력 시퀀스의 첫 번째 토큰을 생성하는 동안에만 필요합니다. 그런 다음 해당 값은 나중에 후속 출력 토큰이 생성될 때 재사용할 수 있도록 저장되며 필요에 따라 새 값이 추가됩니다. 이렇게 하면 새 토큰을 생성하는 데 필요한 컴퓨팅 양이 크게 줄어들고 궁극적으로 LLM이 출력을 생성하는 데 걸리는 시간이 단축되어 사용자 경험이 향상됩니다.
KV 캐시를 재사용하면 처음부터 다시 계산할 필요가 없으므로 추론 시간과 컴퓨팅 리소스를 줄일 수 있습니다. 하지만 사용자가 LLM 기반 서비스와 간헐적으로 상호 작용하거나 여러 명의 LLM 사용자가 동일한 KV 캐시와 서로 다른 시간에 상호 작용해야 하는 경우, KV 캐시를 GPU 메모리에 장기간 저장하면 새로 들어오는 사용자 요청을 처리하는 데 더 잘 할당할 수 있는 귀중한 리소스가 낭비되어 전체 시스템 처리량이 감소할 수 있습니다.
이러한 문제를 해결하기 위해 KV 캐시를 GPU 메모리에서 용량이 크고 비용이 저렴한 CPU 메모리로 오프로드한 다음 유휴 사용자가 활동을 재개하거나 새로운 사용자가 동일한 콘텐츠와 상호 작용하면 다시 GPU 메모리로 다시 로드할 수 있습니다. KV 캐시 오프로딩이라고 하는 이 방법을 사용하면 귀중한 GPU 메모리를 사용하지 않고도 KV 캐시를 다시 계산할 필요가 없습니다.
멀티턴 사용자 인터랙션의 문제 해결
KV 캐시 오프로딩은 여러 사용자가 뉴스 기사 요약과 같은 동일한 콘텐츠와 상호 작용할 수 있도록 함으로써 생성형 AI 기능을 플랫폼에 통합하는 콘텐츠 제공업체가 새로운 사용자마다 KV 캐시를 다시 계산하지 않아도 된다는 이점이 있습니다. 뉴스 기사에 대한 KV 캐시를 한 번 계산하여 CPU 메모리에 캐싱한 다음 여러 사용자에게 재사용함으로써 비용과 사용자 경험을 크게 최적화할 수 있습니다.
이 기술은 코드 생성 사용 사례, 특히 LLM 기능이 통합된 통합 개발 환경(IDE)에서도 유용합니다. 이 시나리오에서는 한 명 이상의 개발자가 장시간에 걸쳐 단일 코드 스크립트와 상호 작용하는 여러 프롬프트를 제출할 수 있습니다. 초기 KV 캐시 계산을 CPU 메모리로 오프로드한 다음 후속 상호 작용을 위해 다시 로드하면 반복적인 재계산을 피할 수 있고 귀중한 GPU 및 인프라 리소스를 절약할 수 있습니다. KV 캐시 오프로드 및 재사용에 대한 자세한 방법 안내는 NVIDIA TensorRT-LLM 설명서를 확인하세요.
PCIe를 통해 x86 호스트 프로세서에 연결된 NVIDIA H100 Tensor 코어 GPU가 탑재된 서버에서 실행되는 Llama 3 70B 모델의 경우, KV 캐시 오프로딩을 통해 TTFT를 최대 14배까지 가속화할 수 있습니다. 따라서 긍정적인 사용자 경험을 유지하면서 LLM을 비용 효율적으로 제공하고자 하는 데이터센터, CSP 및 애플리케이션 제공업체에게 매력적인 배포 전략이 될 수 있습니다.

NVIDIA GH200 컨버지드 CPU-GPU 메모리로 KV 캐시 오프로딩 가속화
기존 x86 기반 GPU 서버에서 KV 캐시 오프로딩은 128GB/s PCIe 연결을 통해 이루어집니다. 여러 번의 멀티턴 사용자 프롬프트가 포함된 대규모 배치의 경우, 느린 PCIe 인터페이스는 성능을 저해하여 일반적으로 실시간 사용자 환경과 관련된 300ms – 500ms 임계값을 초과하는 TTFT를 발생시킬 수 있습니다.
NVIDIA GH200 Grace Hopper 슈퍼칩은 저속 PCIe 인터페이스의 문제를 극복합니다. NVIDIA GH200은 NVLink-C2C 인터커넥트 기술을 사용하여 Arm 기반 NVIDIA Grace CPU와 NVIDIA Hopper GPU 아키텍처를 결합한 새로운 클래스의 슈퍼칩입니다. NVLink-C2C는 CPU와 GPU 간에 최대 900GB/s의 총 대역폭을 제공합니다. 이는 기존 x86 기반 GPU 서버의 표준 PCIe Gen5 레인보다 7배 더 높은 대역폭입니다. 또한 GH200에서는 CPU와 GPU가 단일 프로세스별 페이지 테이블을 공유하므로 모든 CPU 및 GPU 스레드가 물리적 CPU 또는 GPU 메모리에 상주할 수 있는 모든 시스템 할당 메모리에 액세스할 수 있습니다.
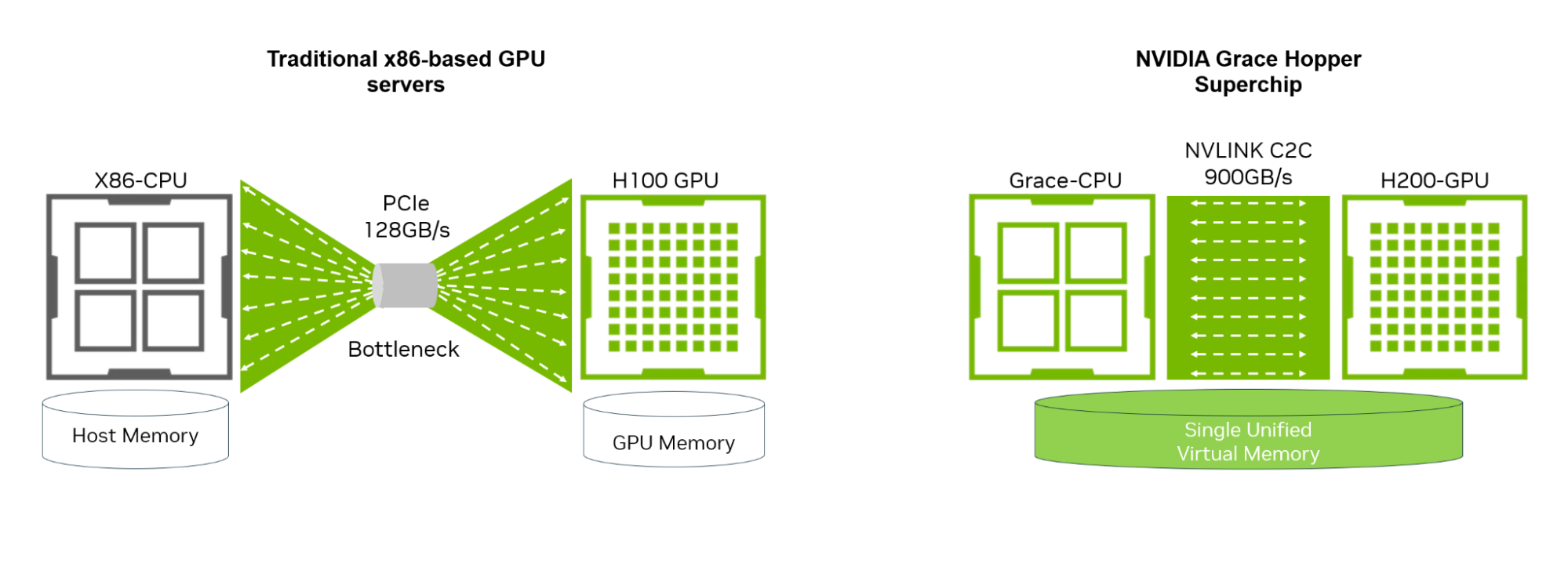
GH200에서 Llama 3 70B 모델의 KV 캐시를 오프로드하면 멀티턴 시나리오에서 x86-H100에서 오프로드하는 것보다 최대 2배 더 빠른 TTFT 속도를 제공합니다. 따라서 멀티턴 사용자 상호 작용이 빈번한 곳에 LLM을 배포하는 조직은 전체 시스템 처리량에 영향을 주지 않으면서도 사용자 상호 작용을 향상시킬 수 있습니다.

NVIDIA Grace Hopper 및 NVLink-C2C를 사용한 Llama 3의 뛰어난 추론 성능
KV 캐시 오프로딩은 전체 시스템 처리량을 저하시키지 않고 멀티턴 사용자 인터랙션에서 TTFT를 개선할 수 있기 때문에 CSP, 데이터센터 및 AI 애플리케이션 제공업체들 사이에서 주목을 받고 있습니다. NVIDIA GH200 슈퍼칩의 900GB/s NVLink-C2C를 활용하면 시스템 처리량 저하 없이 인기 있는 Llama 3 모델에서 추론 속도를 최대 2배까지 가속화할 수 있습니다. 이를 통해 조직은 추가적인 인프라 투자 없이도 사용자 경험을 개선할 수 있습니다.
현재 NVIDIA GH200은 전 세계 9대의 슈퍼컴퓨터를 구동하고 있으며, 다양한 시스템 제조업체에서 제공하고 있으며 Vultr, Lambda, CoreWeave와 같은 클라우드 제공업체에서 온디맨드 방식으로 액세스할 수 있습니다. NVIDIA LaunchPad를 통해 GH200을 무료로 테스트할 수 있습니다.
관련 리소스
- GTC 세션: Grace Hopper 슈퍼칩 아키텍처 및 딥 러닝 애플리케이션을 위한 성능 최적화
- GTC 세션: FlashAttention: IO 인식을 통한 빠르고 메모리 효율적인 정확한 어텐션
- GTC 세션: NeMo, TensorRT-LLM 및 Triton 추론 서버에서 가속화된 LLM 모델 정렬 및 배포
- NGC 컨테이너: Llama-3-Swallow-70B-Instruct-v0.1
- NGC 컨테이너: Llama-3.1-405b-instruct
- 웨비나: 데이터 인사이트 활용