
양자 컴퓨터에 사용되는 애플리케이션이나 알고리즘을 개발하려면 양자 회로 시뮬레이션이 필수입니다. 양자 컴퓨팅 알고리즘 및 사용 사례의 새로운 특성으로 인해 정부, 기업 및 학계 연구원들은 획기적인 양자 알고리즘을 개발하여 끝없이 커지는 양자 시스템들을 기준으로 벤치마킹에 나서고 있습니다.
이제는 양자 회로 시뮬레이션을 통해 알고리즘을 개발하는 것이 가장 효과적입니다. 양자 회로 시뮬레이션은 계산 집약적이기 때문에 양자 상태를 계산하려면 GPU가 필요해집니다. 대규모 양자 시스템을 시뮬레이션하려면 계산을 다수의 GPU와 노드로 분산시켜 슈퍼컴퓨터의 계산 성능을 최대한 이용해야 하기 때문입니다.
NVIDIA cuQuantum은 GPU를 사용해 양자 회로 시뮬레이션을 손쉽게 가속하고 확장함으로써 양자를 이용할 수 있는 길을 새롭게 열어갈 수 있는 소프트웨어 개발 키트(SDK)입니다.
이 SDK에는 배포를 준비할 수 있는 소프트웨어 컨테이너로 최근에 릴리스되어 멀티-GPU 상태 벡터 시뮬레이션을 지원하는 NVIDIA DGX cuQuantum Appliance도 포함됩니다. 또한 cuStateVec에서 일반화된 멀티-GPU API가 제공되어 어떤 시뮬레이터든 손쉽게 통합할 수 있습니다. 텐서 네트워크 시뮬레이션의 경우에는 cuQuantum cuTensorNet 라이브러리에서 제공되는 슬라이싱 API를 사용해 가속화된 텐서 네트워크 축소 연산을 다수의 GPU 또는 노드로 분산시킬 수 있습니다. 따라서 사용자가 선형에 가까울 정도로 강력한 스케일링을 사용해 DGX A100 시스템을 이용할 수 있습니다.
NVIDIA cuQuantum SDK는 상태 벡터 및 텐서 네트워크 기법에 필요한 라이브러리를 제공합니다. 이번 게시글에서는 멀티-노드 상태 벡터 시뮬레이션에 사용되는 cuStateVec와 DGX cuQuantum Appliance를 살펴보겠습니다. cuTensorNet와 텐서 네트워크 기법에 대해 자세히 알고 싶다면 NVIDIA cuTensorNet를 통한 양자 회로 시뮬레이션 스케일링을 참조하세요.
멀티-노드, 멀티-GPU 상태 벡터 시뮬레이션이 무엇인가요?
노드란 프로세서가 서로 밀접하게 연결되어 데이터를 처리할 수 있도록 최적화된 단일 패키지 유닛을 말하며, 언제든지 랙 장착이 가능한 폼팩터를 유지해야 합니다. 멀티-노드, 멀티-GPU 상태 벡터 시뮬레이션은 싱글 노드 내에서 다수의 GPU를, 혹은 다수의 GPU 노드를 이용해 솔루션 제공을 앞당길 뿐만 아니라, 더욱 큰 규모의 문제까지 해결할 수 있습니다.
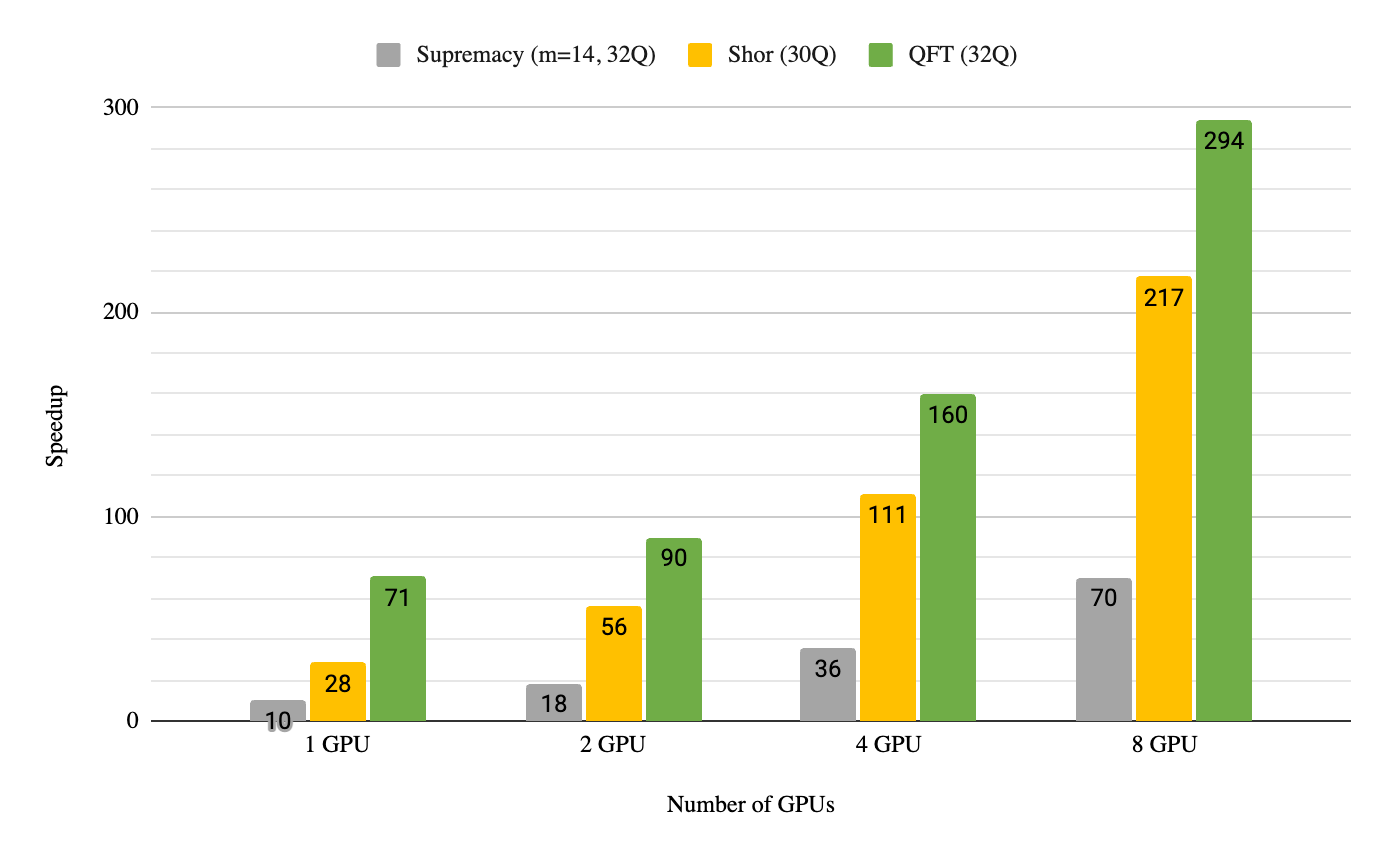
DGX는 사용자가 높은 메모리와 낮은 지연 시간, 그리고 높은 대역폭을 이용할 수 있는 시스템입니다. DGX H100 시스템은 H100 Tensor Core GPU 8개로 구성되며, 4세대 NVLink와 3세대 NVSwitch를 이용합니다. 이 노드는 양자 회로 시뮬레이션에 동력을 공급하는 발전소와 같습니다. GPU 총 8개를 기반으로 NVIDIA 멀티 GPU를 지원하는 DGX cuQuantum Appliance를 사용해 DGX A100에서 실행한 결과, 흔히 사용되는 3가지 양자 컴퓨팅 알고리즘인 양자 푸리에 변환, 쇼어 알고리즘, 시카모어 우월성 회로에 대해 70~290배까지 속도가 빨라져서 듀얼 64코어 AMD EPYC 7742 프로세서를 능가하는 성능을 보여주었습니다. 이에 따라 싱글 DGX A100 노드(GPU 8개)로 전체 상태 벡터 기법을 사용했을 때 최대 36큐비트까지 시뮬레이션할 수 있습니다. 그림 1에 보이는 결과는 최근에 발표했던 벤치마크 이후로 소프트웨어 전용 기능이 새롭게 개선되어 4.4배 더 높습니다.
NVIDIA cuStateVec 팀은 싱글 노드에서 멀티 GPU를 이용하는 것 외에도 멀티 노드를 이용해 성능을 높일 수 있는 방법을 집중적으로 연구했습니다. 대부분 게이트 애플리케이션은 병렬 연산을 완벽하게 지원하기 때문에 노드 내 GPU와 노드 간 GPU도 오케스트레이션을 통한 분할 정복이 가능합니다.
시뮬레이션 과정에서 상태 벡터가 분할되어 GPU로 분산되고, 각 GPU는 게이트를 자신의 상태 벡터에 병렬 방식으로 적용할 수 있습니다. 대부분 이렇게 로컬에서 처리되지만 큐비트가 높은 게이트 애플리케이션은 분산된 상태 벡터 사이에서 통신이 필요합니다.
일반적으로 먼저 큐비트 순서를 조정한 후 다른 GPU 또는 노드에 액세스할 필요 없이 각 GPU에 게이트를 적용하는 방법이 있습니다. 이렇게 순서를 조정하려면 디바이스 간 데이터 전송이 필요합니다. 따라서 데이터 전송 효율을 높이려면 상호연결 대역폭이 반드시 높아야 합니다. 하지만 다수의 노드에서 이러한 병렬 처리 효율을 높이는 일은 쉽지 않습니다.
멀티-노드 DGX cuQuantum Appliance 도입
상태 벡터 기반 양자 회로 시뮬레이션을 원하는 대로 스케일링하여 성능을 높이고 싶다면 여기 해답이 있습니다. NVIDIA는 새로운 DGX cuQuantum Appliance에서 지원되는 멀티-노드, 멀티-GPU 기능을 발표했습니다. 이에 따라 cuQuantum 사용자들은 다음 릴리스부터 IBM Qiskit 프론트엔드를 빠르고 쉽게 이용하여 세계 최대 규모의 NVIDIA 시스템에서 양자 회로를 시뮬레이션할 수 있습니다.
cuQuantum은 최대한 많은 사용자들이 양자 회로 시뮬레이션을 손쉽게 가속하고 스케일링할 수 있도록 지원하는 데 목적이 있습니다. 이를 위해 cuQuantum 팀은 NVIDIA 멀티-노드 접근법을 API로 상용화하기 위해 노력하고 있으며, 내년 초에 정식 출시될 예정입니다. 이에 따라 앞으로 NVIDIA GPU 기반 시스템을 더욱 광범위하게 이용하여 상태 벡터 기반 양자 회로 시뮬레이션을 스케일링할 수 있을 것으로 기대됩니다.
NVIDIA 멀티-노드 DGX cuQuantum Appliance는 현재 최종 개발 단계에 있으며, 곧 NVIDIA DGX SuperPOD 시스템을 통해 동급 최고의 성능을 이용할 수 있을 것으로 보입니다. NGC-호스팅 컨테이너 이미지로 제공되어 Docker를 사용해 코드 몇 줄만 작성하면 빠르게 배포할 수 있습니다.
DGX 시스템 중에서 가장 빠른 I/O 아키텍처를 자랑하는 NVIDIA DGX H100은 확장 가능한 AI를 위한 엔터프라이즈 블루프린트인 NVIDIA DGX SuperPOD 같은 대규모 AI 클러스터와 오늘날 양자 회로 시뮬레이션 인프라를 위한 기본 빌딩 블록입니다. DGX H100에 탑재되는 NVIDIA H100 GPU 8개는 새로운 고성능 4세대 NVLink 기술을 바탕으로 3세대 NVSwitch 4개를 통해 서로 연결됩니다.
4세대 NVLink 기술은 이전 세대와 비교해서 통신 대역폭이 1.5배 빠르고, PCIe Gen5와 비교하면 최대 7배 빠릅니다. GPU 간 총 처리량도 최대 7.2TB/초로 이전 세대인 DGX A100 대비 1.5배 높습니다.
DGX H100 시스템은 기본 제공되는 NVIDIA ConnectX-7 InfiniBand / Ethernet 어댑터 8개가 각각 400GB/초로 실행되면서 강력한 고속 패브릭을 제공하여 다수의 노드로 분산된 상태 벡터 사이에서 전역 통신에 따른 오버헤드를 줄일 수 있습니다. 또한 멀티-노드, 멀티-GPU cuQuantum와 최신 네트워킹 하드웨어 및 소프트웨어 최적화 기술을 이용하는 대규모 GPU 가속 컴퓨팅이 결합되어 노드를 수백 개 또는 수천 개까지 확장할 수 있기 때문에 50큐비트가 넘는 전체 상태 양자 회로 시뮬레이션도 스케일링하는 등 아무리 까다로운 문제라고 해도 해결할 수 있습니다.
이러한 벤치마킹을 위해 멀티-노드 DGX cuQuantum Appliance는 NVIDIA DGX SuperPOD 시스템 참조 아키텍처인 NVIDIA Selene 슈퍼컴퓨터에서 실행됩니다. Selene는 2022년 6월을 기준으로 High Performance Linpack(HPL) 벤치마크에서 63.5페타플롭을 기록하며 슈퍼 컴퓨팅 시스템 TOP500 순위에서 8위를 기록했습니다. 또한 Green500 순위에서는 24.0기가플롭/와트로 22위에 오르기도 했습니다.
NVIDIA는 멀티-노드 DGX cuQuantum Appliance를 이용해 Quantum Volume, Quantum Approximate Optimization Algorithm(QAOA) 및 Quantum Phase Estimation 벤치마크를 실행했습니다. Quantum Volume 회로의 깊이는 10과 30이었습니다. 대체로 QAOA는 단기 양자 컴퓨터에서 조합 최적화 문제를 해결할 목적으로 많이 사용되는 알고리즘입니다. 우리는 두 가지 파라미터를 가지고 실행했습니다.
앞서 언급한 세 가지 알고리즘에서 약(weak) 스케일링과 강(strong) 스케일링이 모두 증명됩니다. 이로써 NVIDIA DGX SuperPOD 같은 슈퍼컴퓨터로 확장한다면 해를 구하는 시간이 빨라질 뿐만 아니라 연구원들이 상태 벡터 양자 회로 시뮬레이션 기법으로 탐색할 수 있는 위상 공간이 커진다는 점에서 매우 가치가 있는 것은 분명합니다.
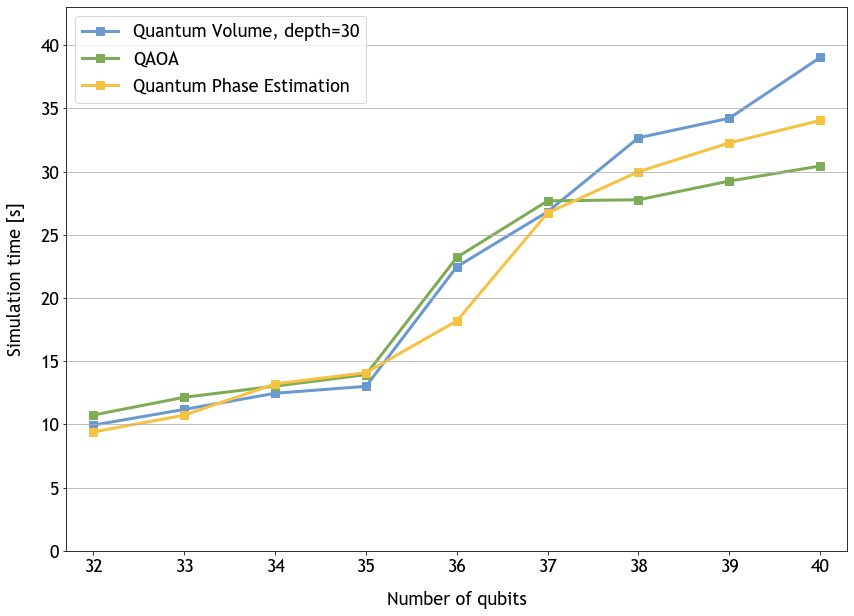
우리는 사용자들이 새로운 DGX cuQuantum Appliance를 사용해 스케일을 달성할 수 있도록 계속해서 지원하고 있습니다. 멀티-노드 기능을 도입한 결과 사용자들은 단일 GPU에서 32큐비트를, 그리고 단일 NVIDIA Ampere Architecture 노드에서 36큐비트를 넘어설 수 있습니다. NVIDIA는 DGX A100 노드 32개를 사용해 총 40큐비트를 시뮬레이션합니다. 이제 소프트웨어 한계인 56큐비트 또는 수백만 개의 DGX A100 노드를 사용해 시스템 구성에 따라 더욱 강력한 스케일아웃을 수행할 수 있습니다. 그 밖에 NVIDIA Hopper GPU에 대한 예비 테스트 결과에서 이러한 수치는 앞으로 차세대 아키텍처를 기반으로 더욱 향상될 것으로 기대됩니다.
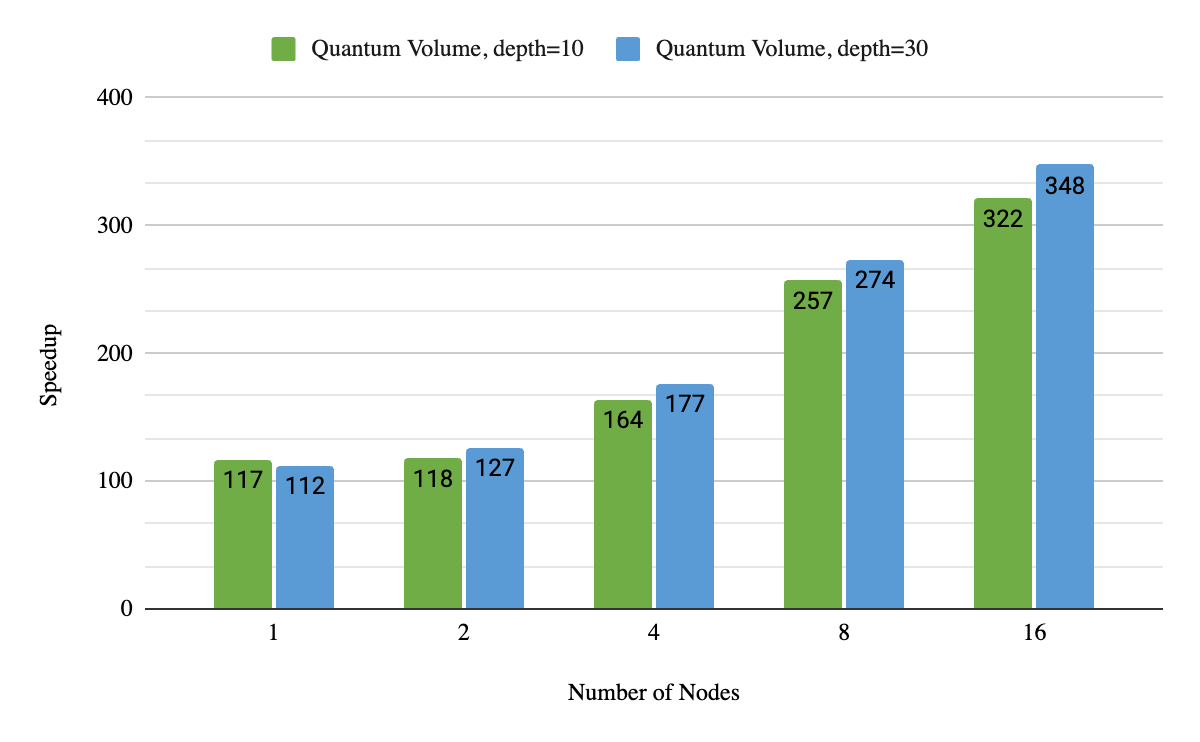
NVIDIA는 멀티-노드 기능의 강 스케일링도 측정했습니다. 여기에서는 간편성을 고려하여 Quantum Volume에 초점을 맞추었습니다. 그림 3은 여러 차례 GPU 수를 변경하면서 동일한 문제를 해결했을 때 성능을 설명한 것입니다. DGX A100 노드 16개를 사용했을 때 최신 듀얼 소켓 서버 CPU와 비교해 320배에서 340배까지 속도가 빨라졌습니다. 또한 앞서 구현한 최신 양자 볼륨(DGX A100 노드 2개만으로 36큐비트일 때 깊이=10)과 비교하면 3.5배 더 빠릅니다. 노드 2개를 더 추가할 경우 속도가 훨씬 빨라집니다.
최대 규모의 NVIDIA 시스템을 통한 양자 회로 시뮬레이션 및 스케일링
NVIDIA의 cuQuantum 팀은 상태 벡터 시뮬레이션을 멀티-노드, 멀티-GPU로 스케일업하고 있습니다. 따라서 최종 사용자들은 전체 상태 벡터에 대한 양자 회로 시뮬레이션을 대규모로 실행할 수 있습니다. cuQuantum은 다수의 노드에서 약 스케일링과 강 스케일링을 모두 증명했다는 점에서 규모는 물론이고 성능까지 보장합니다.
그 밖에도 cuQuantum은 cuQuantum 기반 IBM Qiskit 이미지를 처음으로 도입했습니다. 이에 따라 다음 릴리스에서는 이 이미지 컨테이너를 가져와 인기 있는 프레임워크에 따라 양자 회로 시뮬레이션을 더욱 쉽고 빠르게 스케일업할 수 있습니다.
멀티-노드 DGX cuQuantum Appliance가 현재 비공개 베타 테스트 중이지만 NVIDIA는 앞으로 수개월 이내에 정식 출시될 것으로 기대하고 있습니다. cuQuantum 팀은 2023년 봄까지 멀티-노드 API를 cuStateVec 라이브러리에 릴리스할 예정입니다.
DGX cuQuantum Appliance 시작하기
멀티-노드 DGX cuQuantum Appliance가 올해 후반기에 정식 출시되면 Docker 이미지를 NGC 컨테이너 카탈로그에서 가져올 수 있습니다.
궁금한 사항은 양자 컴퓨팅 포럼을 통해 cuQuantum 팀에게 문의할 수 있습니다. 기능을 요청하거나 버그를 보고하고 싶다면 NVIDIA/cuQuantum GitHub 리포지토리를 통해 연락하시기 바랍니다.
자세한 내용은 다음 리소스를 참조하세요.
- cuQuantum (includes cuTensorNet)
- cuQuantum documentation
- NVIDIA/cuQuantum GitHub repo
- DGX cuQuantum Appliance
- What Is Quantum Computing?
- Lightning Fast simulations with Pennylane and the NVIDIA cuQuantum SDK
- Orquestra Integration with NVIDIA cuQuantum
- NVIDIA cuQuantum and QODA Adoption Accelerates
GTC 2022와 cuQuantum
이번 GTC 2022 세션에 참가하여 NVIDIA cuQuantum을 비롯한 기타 혁신 기술에 대해 자세히 알아보세요.
- GTC 2022 Keynote
- A Deep Dive into the Latest HPC Software
- Defining the Quantum-Accelerated Supercomputer
- Scaling Quantum Circuit Simulations with cuQuantum for Quantum Algorithms
- Quantum Computing Simulation in Pharmaceuticals Research
- Accelerating Quantum Computing Research with GPUs
- AI for Science: Heralding Scientific Breakthroughs through AI
이 블로그에 열거된 SDK의 대부분의 독점 액세스, 얼리 액세스, 기술 세션, 데모, 교육 과정, 리소스는 NVIDIA 개발자 프로그램 회원은 무료로 혜택을 받으실 수 있습니다. 지금 무료로 가입하여 NVIDIA의 기술 플랫폼에서 구축하는 데 필요한 도구와 교육에 액세스하시고 여러분의 성공을 가속화 하세요.