비전 트랜스포머(ViT)는 놀라운 정확도, 까다로운 실제 시나리오를 위한 강력한 솔루션, 향상된 일반화 가능성을 제공하면서 컴퓨터 비전에 큰 변화를 가져오고 있습니다. 이 알고리즘은 컴퓨터 비전 애플리케이션을 향상시키는 데 중추적인 역할을 하고 있으며, NVIDIA는 NVIDIA TAO 툴킷 및 NVIDIA L4 GPU를 사용하여 ViT를 애플리케이션에 쉽게 통합할 수 있도록 지원하고 있습니다.
ViT의 차이점
ViT는 원래 자연어 처리를 위해 설계된 트랜스포머 아키텍처를 시각 데이터에 적용하는 머신 러닝 모델입니다. CNN 기반 모델에 비해 몇 가지 장점이 있으며 대규모 입력에 대한 병렬 처리를 수행할 수 있습니다. CNN은 이미지에 대한 글로벌 이해가 부족한 로컬 연산을 사용하는 반면, ViT는 장거리 종속성과 글로벌 컨텍스트를 제공합니다. 이는 이미지를 병렬 및 자체 주의 기반 방식으로 처리하여 모든 이미지 패치 간의 상호 작용을 가능하게 함으로써 효과적으로 수행됩니다.
그림 1은 입력 이미지가 더 작은 고정 크기 패치로 나뉘고, 이를 평평하게 만들어 토큰 시퀀스로 변환하는 ViT 모델에서 이미지를 처리하는 과정을 보여줍니다. 이러한 토큰은 위치 인코딩과 함께 여러 계층의 자기 주의 및 피드 포워드 신경망으로 구성된 트랜스포머 인코더에 공급됩니다.
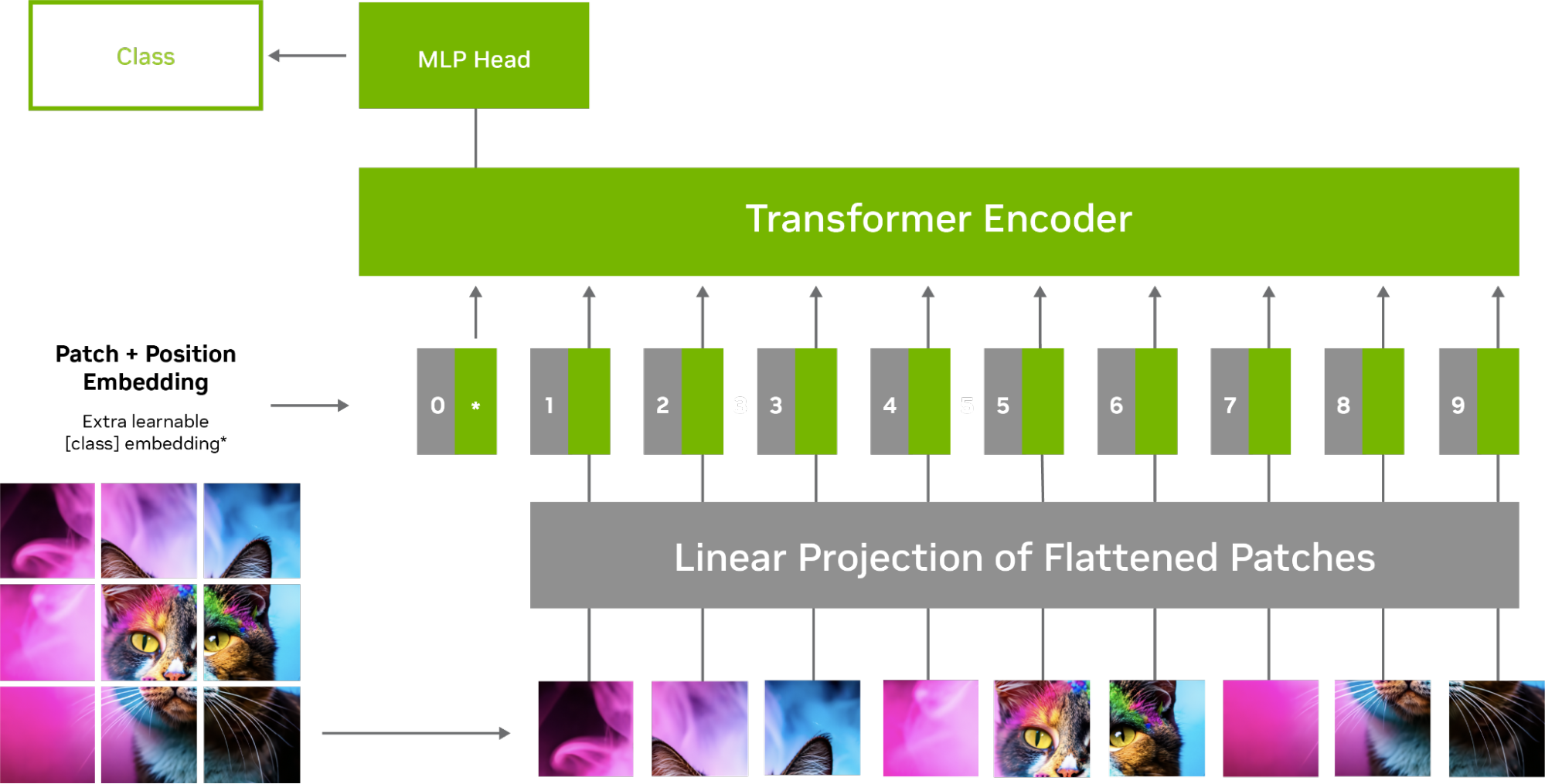
자기 주의 메커니즘을 사용하면 이미지의 각 토큰 또는 패치가 다른 토큰과 상호 작용하여 어떤 토큰이 중요한지 결정합니다. 이를 통해 모델은 토큰 간의 관계와 종속성을 파악하고 어떤 토큰이 다른 토큰보다 중요한지 학습할 수 있습니다.
예를 들어 새 이미지의 경우, 모델은 배경보다는 눈, 부리, 깃털과 같은 중요한 특징에 더 많은 주의를 기울입니다. 이는 훈련 효율성이 향상되고 이미지 손상 및 노이즈에 대한 견고성이 강화되며 보이지 않는 물체에 대한 일반화 성능이 뛰어나다는 의미로 해석됩니다.
컴퓨터 비전 애플리케이션에 ViT가 중요한 이유
실제 환경에는 다양하고 복잡한 시각적 패턴이 존재합니다. ViT의 확장성과 적응성은 CNN과 달리 작업별 아키텍처를 조정할 필요 없이 다양한 작업을 처리할 수 있게 해줍니다.

그림 2. 다양한 유형의 불완전하고 노이즈가 있는 실제 데이터는 이미지 분석에 어려움을 야기합니다.
다음 비디오에서는 CNN 기반 모델과 ViT 기반 모델에서 실행되는 노이즈가 있는 비디오를 비교합니다. 모든 경우에서 ViT가 CNN 기반 모델보다 성능이 뛰어납니다.
TAO 툴킷 5.0과 ViT 통합하기
비전 AI 모델을 빌드하고 가속화하는 로우코드 AI 툴킷인 TAO를 사용하면 이제 애플리케이션과 AI 워크플로에 ViT를 쉽게 빌드하고 통합할 수 있습니다. 사용자는 모델 아키텍처에 대한 심층적인 지식 없이도 간단한 인터페이스와 구성 파일로 빠르게 ViT를 훈련할 수 있습니다.
TAO 툴킷 5.0에는 다음과 같이 널리 사용되는 컴퓨터 비전 작업을 위한 몇 가지 고급 ViT가 포함되어 있습니다.
완전 주의 네트워크(FAN)
NVIDIA Research의 트랜스포머 기반 백본 제품군인 FAN은 표 1에 강조 표시된 대로 다양한 손상에 대해 SOTA 견고성을 달성합니다. 이 백본 제품군은 새로운 도메인으로 쉽게 일반화할 수 있으며 노이즈와 블러를 방지합니다. 표 1은 깨끗한 버전과 손상된 버전 모두에 대한 ImageNet-1K 데이터 세트의 모든 FAN 모델의 정확도를 보여줍니다.
| 모델 번호 | 매개변수 | 정확도(클린/손상) |
| FAN-Tiny-Hybrid | 7.4M | 80.1/57.4 |
| FAN-Small-Hybrid | 26.3M | 83.5/64.7 |
| FAN-Base-Hybrid | 50.4M | 83.9/66.4 |
| FAN-Large-Hybrid | 76.8M | 84.3/68.3 |
글로벌 컨텍스트 비전 트랜스포머(GC-ViT)
GC-ViT는 매우 높은 정확도와 컴퓨팅 효율성을 달성하는 NVIDIA Research의 새로운 아키텍처입니다. 이 아키텍처는 비전 트랜스포머의 유도 바이어스 부족 문제를 해결합니다. 또한 로컬 셀프 어텐션과 글로벌 셀프 어텐션을 결합하여 훨씬 더 나은 로컬 및 글로벌 공간 상호 작용을 제공할 수 있는 로컬 셀프 어텐션을 사용하여 더 적은 수의 파라미터로 ImageNet에서 더 나은 결과를 얻을 수 있습니다.
| 모델 | 매개변수 | 정확도 |
| GC-ViT-xxTiny | 12M | 79.9 |
| GC-ViT-xTiny | 20M | 82.0 |
| GC-ViT-Tiny | 28M | 83.5 |
| GC-ViT-Small | 51M | 84.3 |
| GC-ViT-Base | 90M | 85.0 |
| GC-ViT-Large | 201M | 85.7 |
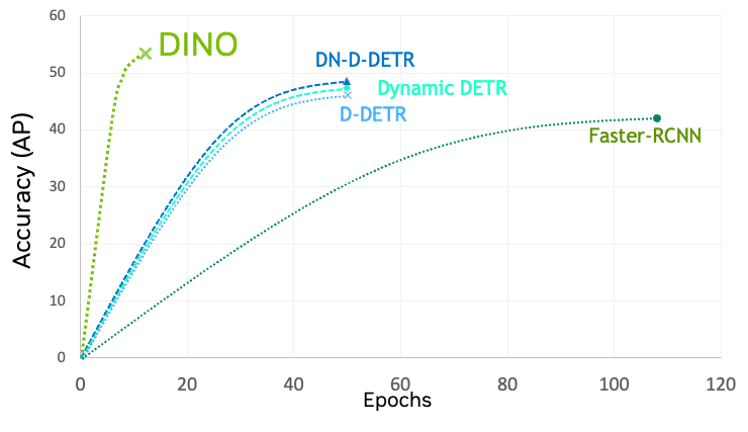
노이즈 제거 앵커가 개선된 감지 변압기(DINO)
DINO는 다른 ViT 및 CNN에 비해 훈련 수렴 속도가 더 빠른 최신 세대의 검출 변환기(DETR)입니다. TAO 툴킷의 DINO는 유연성이 뛰어나며 ResNets와 같은 기존 CNN의 다양한 백본과 FAN 및 GC-ViT와 같은 트랜스포머 기반 백본과 결합할 수 있습니다
세그포머(Segformer)
세그포머는 가볍고 강력한 트랜스포머 기반의 시맨틱 세그먼테이션입니다. 디코더는 경량 멀티헤드 인식 레이어로 구성되어 있습니다. 주로 트랜스포머에서 사용되는 위치 인코딩을 사용하지 않으므로 다양한 해상도에서 효율적으로 추론할 수 있습니다.
NVIDIA L4 GPU로 효율적인 트랜스포머 구동
NVIDIA L4 GPU는 차세대 비전 AI 워크로드를 위해 제작되었습니다. 혁신적인 AI 기술을 가속화하도록 설계된 NVIDIA Ada 러브레이스 아키텍처를 기반으로 합니다.
L4 GPU는 희소성을 갖춘 FP8 485 TFLOPs의 높은 컴퓨팅 성능으로 ViT 워크로드를 실행하는 데 적합합니다. FP8은 더 큰 정밀도에 비해 메모리 부담을 줄이고 AI 처리량을 획기적으로 가속화합니다.
단일 슬롯, 로우 프로파일 폼 팩터의 다기능성과 에너지 효율적인 L4는 엣지 위치를 포함한 비전 AI 배포에 이상적입니다.
이 메트로폴리스 개발자 밋업 온디맨드를 시청하여 ViT, NVIDIA TAO 툴킷 5.0 및 L4 GPU에 대해 자세히 알아보세요.