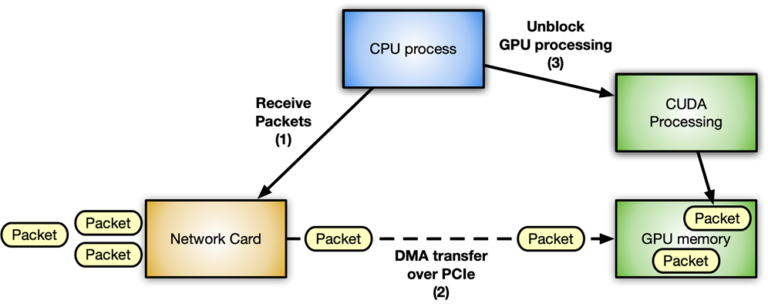
GPU를 사용한 네트워크 패킷의 인라인 처리는 신호 처리, 네트워크 보안, 정보 수집, 입력 재구성 등 다양한 애플리케이션 분야에서 유용한 패킷 분석 기술입니다.
이러한 애플리케이션 유형의 핵심 역할은 수신된 패킷을 최대한 빨리 GPU 메모리로 이동하여 병렬 처리를 실행하는 CUDA 커널을 트리거하는 것입니다.
일반적인 개념은 네트워크 카드에서 GPU 메모리로 패킷을 직접 수신할 수 있는 연속적 비동기 파이프라인을 생성하는 것입니다. 그뿐만 아니라 GPU 및 CPU를 동기화할 필요 없이 CUDA 커널을 사용하여 수신 패킷을 처리합니다.
효과적인 애플리케이션 워크플로우는 개방형 통신 메커니즘을 사용하여 다음과 같은 실행 구성 요소 간에 조율된 연속적 비동기 파이프라인을 생성하는 작업을 포함합니다.
- 네트워크 컨트롤러: 수신된 네트워크 패킷을 GPU 메모리에 공급합니다.
- CPU: 수신된 패킷에 대한 정보를 얻기 위해 네트워크 컨트롤러에 쿼리합니다.
- GPU: 패킷 정보를 수신하고 GPU 메모리에 직접 처리합니다.
그림 1은 NVIDIA GPU와 ConnectX 네트워크 카드를 사용하는 가속화 인라인 패킷 처리 애플리케이션의 일반적인 패킷 워크플로우 시나리오를 보여줍니다.
위와 같은 시나리오에서는 지연 시간이 발생하지 않도록 하는 것이 매우 중요합니다. 다양한 구성 요소 간의 통신이 최적화될수록 처리량이 증가하여 시스템 응답성이 좋아집니다. 모든 단계에서는 필요한 리소스가 제공되는 즉시 대기 중인 다른 구성 요소를 차단하지 않고 인라인으로 처리해야 합니다.
다음 두 가지 흐름을 명확하게 확인할 수 있습니다.
- 데이터 흐름: 최적화된 데이터(네트워크 패킷)를 PCIe 버스를 통해 네트워크 카드와 GPU 간에 교환합니다.
- 제어 흐름: CPU가 GPU와 네트워크 카드를 오케스트레이션합니다.
데이터 흐름
네트워크 컨트롤러와 GPU 간에 최적화된 데이터 이동(패킷 송수신)이 핵심입니다. NVIDIA GPU와 타사 피어 디바이스(예: 네트워크 카드) 간의 직접 데이터 경로를 지원하는 GPUDirect RDMA 기술 및 PCI Express 버스 인터페이스의 표준 기능을 사용하면 최적화된 데이터 이동을 구현할 수 있습니다.
GPUDirect RDMA는 PCI Express 기본 주소 레지스터(BAR) 영역에 디바이스 메모리 일부를 노출하는 NVIDIA GPU 기능을 사용합니다. 자세한 내용은 CUDA 툴킷 설명서에서 GPUDirect RDMA를 사용한 Linux 커널 모듈 개발을 참조하세요. 최신 서버 플랫폼의 GPUDirect RDMA 벤치마킹 게시물에서는 다양한 시스템 토폴로지를 사용하는 표준 IB 동사로 네트워크 작업(송수신)을 수행할 경우의 GPUDirect RDMA 대역폭 및 지연 시간을 더욱 심층적으로 분석합니다.
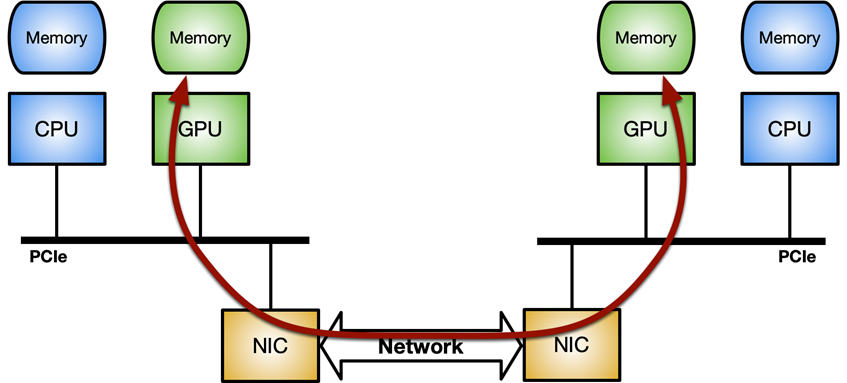
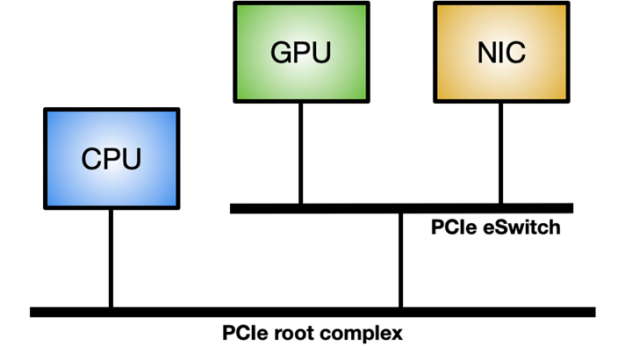
Linux 시스템에서 GPUDirect RDMA를 활성화하려면 nvidia-peermem 모듈(CUDA 11.4 이상에서 사용 가능)이 필요합니다. 그림 3은 GPUDirect RDMA 내부 처리량을 극대화하는 이상적인 시스템 토폴로지 보여줍니다. 즉, 다른 구성 요소와 공유되는 시스템 PCIe 연결을 거치지 않는 GPU와 NIC 간의 전용 PCIe 스위치입니다.
제어 흐름
CPU는 네트워크 컨트롤러와 GPU 간의 동작을 조율하고 동기화하는 주체로서 NIC를 활성화하여 GPU 메모리에 패킷을 수신하고 CUDA 워크로드에 새 패킷을 처리할 수 있음을 알립니다.
GPU를 다룰 때는 CPU와 GPU 간의 비동기성이 매우 중요합니다. 메인 루프에서 다음 세 단계를 실행하는 간단한 애플리케이션을 예로 들 수 있습니다.
- 패킷 수신
- 패킷 처리
- 수정된 패킷 반송
이 게시물에서는 이러한 애플리케이션에서 제어 흐름을 구현하는 4가지 방법을 각각의 장단점과 함께 알아봅니다.
방법 1
그림 4는 가장 쉽지만 가장 효과가 덜한 접근 방법을 보여줍니다. 단일 CPU 스레드는 패킷을 수신하면 CUDA 커널을 실행하여 패킷을 처리하고 CUDA 커널이 완료될 때까지 기다렸다가 수정된 패킷을 네트워크 컨트롤러로 반송하는 역할을 합니다.

패킷 처리가 그다지 집약적이지 않다면 이 접근 방법은 GPU 개입 없이 CPU로 패킷을 처리하는 것보다 덜 효과적일 수도 있습니다. 예를 들어 패킷에서 시간이 많이 소요되는 복잡한 알고리즘을 해결하기 위해 높은 수준의 병렬 처리가 필요할 수도 있습니다.
방법 2
이 접근 방법에서 애플리케이션은 CPU 워크로드를 두 개의 CPU 스레드로 분할합니다. 한쪽은 패킷을 수신하고 GPU 처리를 실행하는 스레드이고, 다른 한쪽은 GPU 처리가 완료될 때까지 대기하고 네트워크를 통해 수정된 패킷을 전송하는 스레드입니다(그림 5).
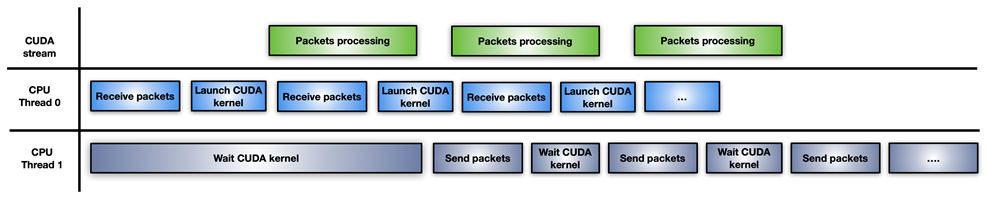
이 접근 방법은 누적된 패킷의 버스트마다 새 CUDA 커널을 실행한다는 단점이 있습니다. CPU에서는 반복 작업마다 CUDA 커널의 실행 지연 시간이 발생합니다. GPU가 과부하되면 패킷 처리가 즉시 실행되지 않아 지연이 발생할 수도 있습니다.
방법 3
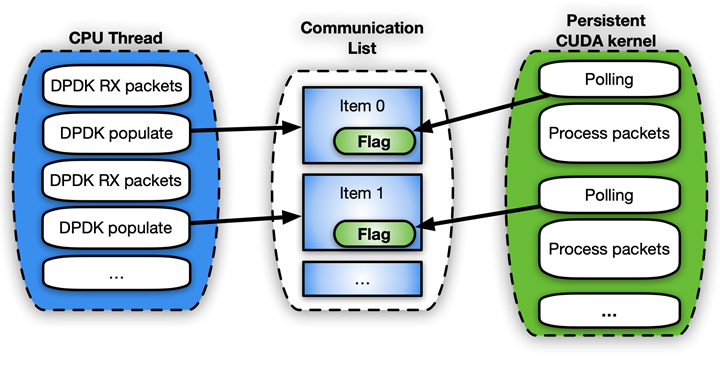
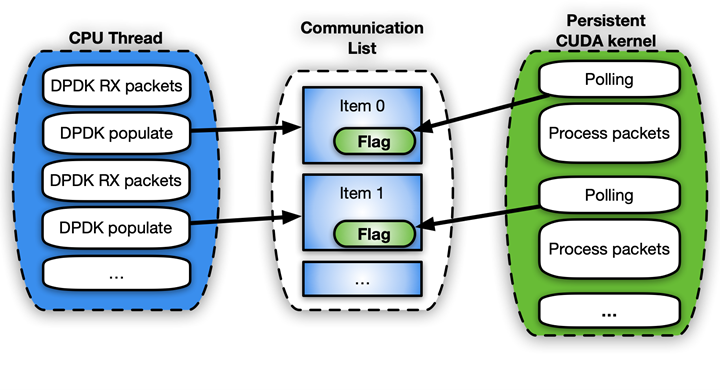
그림 6은 CUDA 영구 커널을 사용하는 세 번째 접근 방법을 보여줍니다.
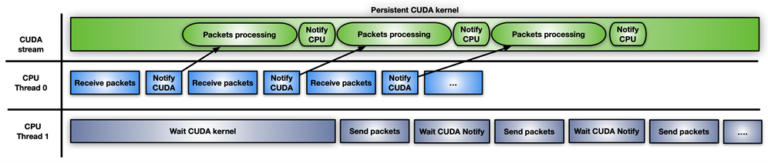
CUDA 영구 커널은 CPU 알림을 기다리느라 바쁜 사전 실행된 커널입니다. 여기서 CPU 알림이란 새 패킷이 도착했고 처리할 준비가 되었다는 알림입니다. 패킷이 준비되면 커널은 패킷 전송을 진행할 수 있음을 두 번째 CPU 스레드에 알립니다.
이 알림 시스템을 구현하는 가장 쉬운 방법은 바쁜 플래그 대기 업데이트 메커니즘을 사용하여 CPU와 GPU 간에 일부 메모리를 공유하는 것입니다. GPUDirect RDMA는 타사 디바이스에서 GPU 메모리에 직접 액세스하는 데 사용되지만, 동일한 API를 사용하여 GPU 메모리의 유효한 CPU 매핑을 완벽하게 생성할 수 있습니다. CPU 기반 복사본은 관련된 오버헤드가 작다는 장점이 있습니다. 이 기능은 지금 GDRCopy 라이브러리를 통해 활성화할 수 있습니다.
신호를 나타내기 위해 GPU 메모리를 직접 매핑하면 CPU에서 메모리를 수정할 수 있으며 폴링 중 GPU에서 메모리 지연 시간이 감소합니다. GPU에서 볼 수 있는 CPU 고정 메모리에 해당 플래그를 넣을 수도 있지만, CPU 메모리 플래그의 CUDA 커널 폴링은 더 많은 PCIe 대역폭이 필요하고 전체 지연 시간도 증가시킵니다.
이 빠른 솔루션이 지닌 문제점은 CUDA 프로그래밍 모델에서 지원되지 않으며 위험하다는 것입니다. GPU 커널을 선점할 수는 없습니다. 올바르게 작성되지 않으면 영구 커널이 무한 반복될 수도 있습니다. 또한 영구 커널을 오래 실행하면 다른 CUDA 커널, CPU 동작, 메모리 할당 상태 등과 관련된 동기화를 잃을 수도 있습니다.
또한 GPU가 다른 작업으로 매우 바쁠 경우에 차선책으로 사용할 수 있는 GPU 리소스(예: 스트리밍 멀티프로세서)도 보유합니다. CUDA 영구 커널을 사용하는 경우 애플리케이션에 매우 능숙해야 합니다.
방법 4
마지막 접근 방법은 앞서 다룬 방법이 결합된 하이브리드 솔루션입니다. CUDA 스트림 메모리 작업을 사용하여 알림 플래그를 기다리거나 업데이트하고 CUDA 스트림에서 수신한 패킷 세트당 하나의 CUDA 커널을 사전 실행합니다.
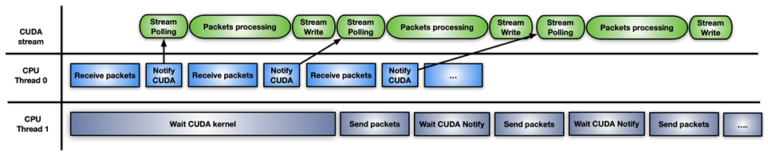
이 접근 방법은 GPU 하드웨어가 GPU 스트리밍 멀티프로세서를 차단하는 대신 메모리 플래그에서 폴링(cuStreamWaitValue 사용)하며 패킷의 처리 커널은 패킷이 준비될 때만 트리거된다는 차이점이 있습니다.
이와 유사하게, 처리 커널이 종료되면 cuStreamWriteValue는 패킷이 처리되었음을 전송용 CPU 스레드에 알립니다.
이 접근 방법은 더 많은 패킷을 처리할 준비가 되지 않은 빈 스트림으로 실행 시간을 낭비하지 않기 위해 애플리케이션이 때때로 cuStreamWaitValue + CUDA 커널 + cuStreamWriteValue 형식의 새로운 시퀀스를 사용하여 GPU를 다시 채워야 한다는 단점이 있습니다. 이럴 때는 CUDA 그래프가 스트림에 다시 게시하기 위한 유용한 접근 방법일 수 있습니다.
애플리케이션 패턴에 따라 접근 방법이 다르게 적용됩니다.
DPDK와 GPUdev
데이터 플레인 개발 키트(DPDK)는 다양한 CPU 아키텍처와 여러 디바이스에서 실행되는 패킷 처리 워크로드의 가속화를 지원하는 라이브러리 세트입니다.
DPDK 21.11에서 NVIDIA는 DPDK와 관련하여 GPU 개념을 도입하고 CPU, 네트워크 카드, GPU 간의 통신을 개선하기 위해 GPUdev라는 새로운 라이브러리를 적용했습니다. GPUdev는 DPDK 22.03에서 더 많은 기능으로 확장되었습니다.
라이브러리의 목표는 다음과 같습니다.
- DPDK 일반 라이브러리에서 관리되는 GPU 디바이스의 개념을 도입합니다.
- 기본 GPU 메모리 상호 작용을 구현하고 GPU 관련 구현 세부 정보를 숨깁니다.
- 네트워크 카드, GPU 디바이스, CPU 간의 간격을 줄여 통신을 향상합니다.
- GPU 애플리케이션으로의 DPDK 통합을 간소화합니다.
- 일반 레이어를 통해 GPU 드라이버 관련 기능을 표시합니다.
NVIDIA 전용 GPU의 경우 CUDA 드라이버 DPDK 라이브러리를 통해 DPDK 드라이버 수준에서 GPUdev 라이브러리 기능을 구현합니다. NVIDIA GPU에 사용 가능한 모든 gpudev 기능을 활성화하려면 CUDA 라이브러리와 GDRCopy를 갖춘 시스템에 DPDK를 빌드해야 합니다.
이 새로운 라이브러리에서 제공하는 기능을 사용하면 데이터 흐름과 제어 흐름을 모두 처리하는 GPU를 통해 인라인 패킷 처리를 쉽게 구현할 수 있습니다.
DPDK는 연속적 메모리 청크인 메모리 풀에서 패킷을 수신합니다. 다음의 명령어 시퀀스를 사용하면 GPU 메모리에 메모리 풀을 할당하도록 GPUDirect RDMA를 활성화하고 디바이스 네트워크에 등록할 수 있습니다.
struct rte_pktmbuf_extmem gpu_mem;
gpu_mem.buf_ptr = rte_gpu_mem_alloc(gpu_id, gpu_mem.buf_len, alignment));
/* Make the GPU memory visible to DPDK */
rte_extmem_register(gpu_mem.buf_ptr, gpu_mem.buf_len,
NULL, gpu_mem.buf_iova, NV_GPU_PAGE_SIZE);
/* Create DMA mappings on the NIC */
rte_dev_dma_map(rte_eth_devices[PORT_ID].device, gpu_mem.buf_ptr,
gpu_mem.buf_iova, gpu_mem.buf_len));
/* Create the actual mempool */
struct rte_mempool *mpool = rte_pktmbuf_pool_create_extbuf(... , &gpu_mem, ...);그림 8은 메모리 풀의 구조를 보여줍니다.
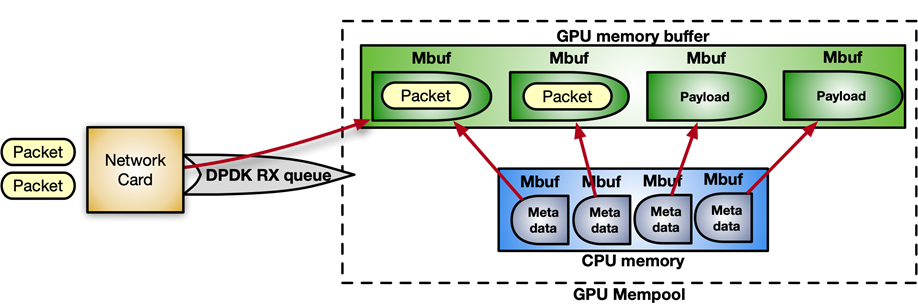
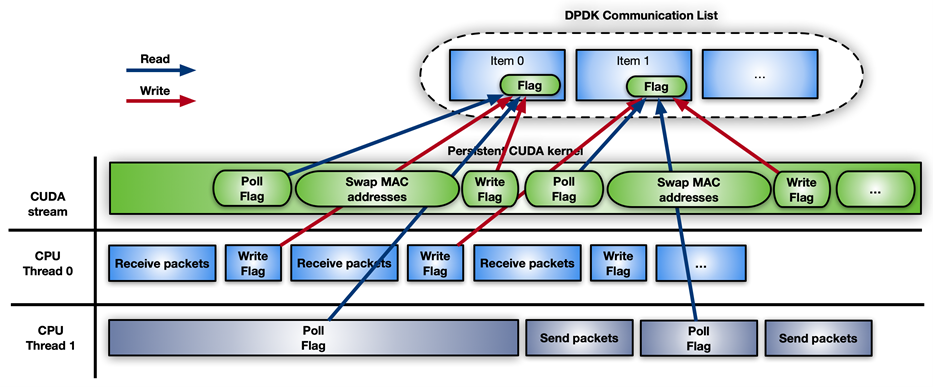
제어 흐름의 경우 CPU와 GPU 간의 알림 메커니즘을 활성화하려면 CPU 메모리와 CUDA 커널 간의 공유 메모리 구조인 gpudev 통신 리스트를 사용하면 됩니다. 리스트의 각 항목은 수신된 패킷(mbufs)의 주소, 그리고 해당 항목의 처리 상태(패킷 준비, 처리 완료 등)를 업데이트하는 플래그를 포함할 수 있습니다.
struct rte_pktmbuf_extmem gpu_mem;
gpu_mem.buf_ptr = rte_gpu_mem_alloc(gpu_id, gpu_mem.buf_len, alignment));
/* Make the GPU memory visible to DPDK */
rte_extmem_register(gpu_mem.buf_ptr, gpu_mem.buf_len,
NULL, gpu_mem.buf_iova, NV_GPU_PAGE_SIZE);
/* Create DMA mappings on the NIC */
rte_dev_dma_map(rte_eth_devices[PORT_ID].device, gpu_mem.buf_ptr,
gpu_mem.buf_iova, gpu_mem.buf_len));
/* Create the actual mempool */
struct rte_mempool *mpool = rte_pktmbuf_pool_create_extbuf(... , &gpu_mem, ...);다음은 유사 코드 예시입니다.
struct rte_mbuf * rx_mbufs[MAX_MBUFS];
int item_index = 0;
struct rte_gpu_comm_list *comm_list = rte_gpu_comm_create_list(gpu_id, NUM_ITEMS);
while(exit_condition) {
...
// Receive and accumulate enough packets
nb_rx += rte_eth_rx_burst(port_id, queue_id, &(rx_mbufs[0]), rx_pkts);
// Populate next item in the communication list.
rte_gpu_comm_populate_list_pkts(&(p_v->comm_list[index]), rx_mbufs, nb_rx);
...
index++;
}간단히 살펴보기 위해 애플리케이션이 CUDA 영구 커널 시나리오를 따른다고 가정하면 CUDA 커널의 폴링 쪽은 다음 코드 예시와 유사하게 보일 것입니다.
__global__ void cuda_persistent_kernel(struct rte_gpu_comm_list *comm_list, int comm_list_entries)
{
int item_index = 0;
uint32_t wait_status;
/* GPU kernel keeps checking exit condition as it can’t be preempted. */
while (!exit_condition()) {
wait_status = RTE_GPU_VOLATILE(comm_list[item_index].status_d[0]);
if (wait_status != RTE_GPU_COMM_LIST_READY)
continue;
if (threadIdx.x < comm_list[item_index]->num_pkts) {
/* Each CUDA thread processes a different packet. */
packet_processing(comm_list[item_index]->addr, comm_list[item_index]->size, ..);
}
__syncthreads();
/* Notify packets in the items have been processed */
if (threadIdx.x == 0) {
RTE_GPU_VOLATILE(comm_list[item_index].status_d[0]) = RTE_GPU_COMM_LIST_DONE;
__threadfence_system();
}
/* Wait for new packets on the next communication list entry. */
item_index = (item_index+1) % comm_list_entries;
}
}{kind=link}
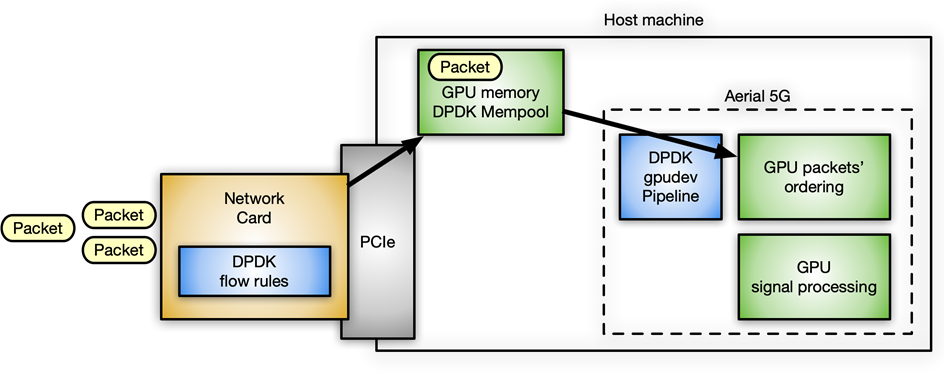
인라인 패킷 처리를 위해 DPDK gpudev 라이브러리를 사용하는 NVIDIA의 구체적인 사용 사례는 소프트웨어 정의 고성능 5G 애플리케이션을 빌드하기 위한 Aerial 애플리케이션 프레임워크에 있습니다. 이 사례에서 패킷은 GPU 메모리에 수신되고 5G 관련 패킷 헤더에 따라 재정렬되어야 하며, 재정렬된 페이로드에서 신호 처리를 시작할 수 있는 효과가 있습니다.
그림 10. Aerial 5G 소프트웨어에서 DPDK gpudev를 사용한 인라인 패킷 처리 사용 사례
{kind=link}
l2fwd-nv 애플리케이션
인라인 패킷 처리를 구현하고 DPDK gpudev 라이브러리를 사용하는 방법에 대한 실용적인 예시를 제공하기 위해 l2fwd-nv 샘플 코드가 /NVIDIA/l2fwd-nv GitHub 리포지토리에 릴리스되었습니다. 이 샘플 코드는 GPU 기능으로 향상된 바닐라 DPDK l2fwd 예시의 확장 버전입니다. 애플리케이션 레이아웃은 패킷을 수신하고, 패킷마다 MAC 주소(소스 및 대상)를 교체하며, 수정된 패킷을 전송하는 데 사용됩니다.
L2fwd-nv는 비교를 위해 이 게시물에서 다룬 다음의 모든 접근 방법에 대한 구현 예시를 제공합니다.
- CPU만 사용
- 패킷 세트당 CUDA 커널
- CUDA 영구 커널
- CUDA 그래프
예를 들어 그림 11은 DPDK gpudev 개체가 있는 CUDA 영구 커널의 타임라인을 보여줍니다.
DPDK testpmd 패킷 생성기와 비교하여 l2fwd-nv 성능을 측정하기 위해 그림 12에서 연속으로 연결된 2개의 Gigabyte 서버가 Intel Xeon Gold 6240R, PCIe Gen3 전용 스위치, Ubuntu 20.04, MOFED 5.4, CUDA 11.4 등의 CPU와 함께 사용되었습니다.
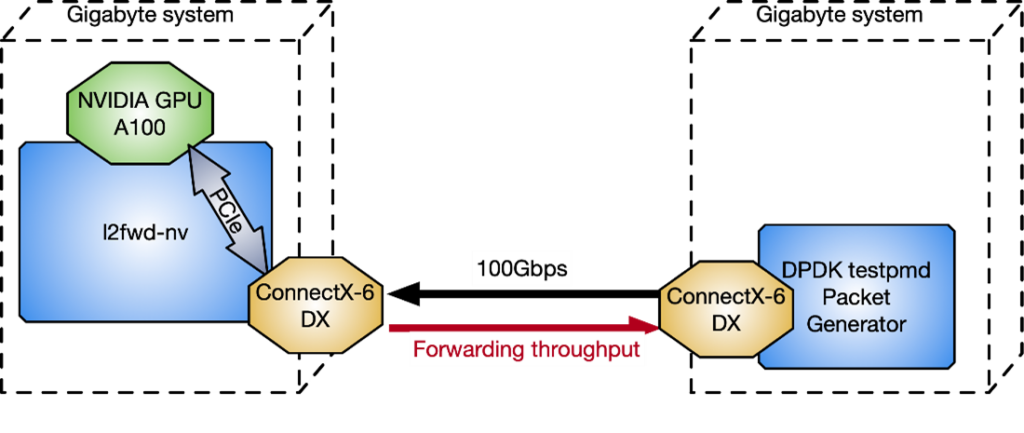
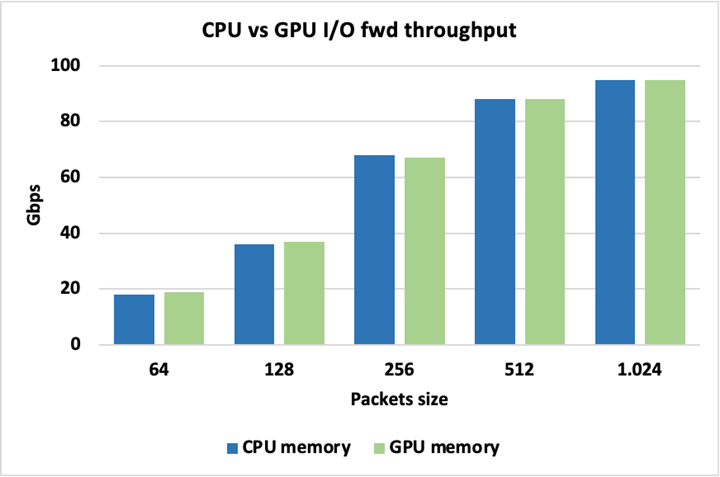
그림 13은 패킷에 CPU 또는 GPU 메모리를 사용할 때 최대 I/O 처리량이 동일하기에 둘 중 어느 것을 사용해도 내재된 불이익이 없음을 보여줍니다. 여기서 패킷은 수정되지 않은 채 전달됩니다.
다양한 GPU 패킷 처리 방법 간의 차이를 강조하기 위해 그림 14는 방법 2(패킷 세트당 CUDA 커널)와 방법 3(CUDA 영구 커널) 간의 처리량 비교 결과를 보여줍니다. 두 방법 모두 패킷 크기를 1,024바이트로 유지하면서 누적된 패킷 수를 변경한 다음에 GPU 작업을 트리거하여 패킷의 MAC 주소를 교환합니다.
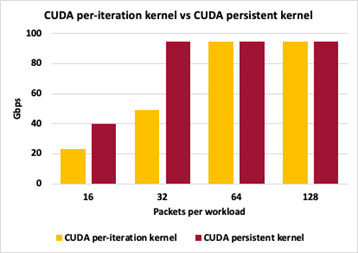
두 접근 방법 모두 반복 작업당 16개의 패킷으로 인해 제어 플레인에서 너무 많은 상호 작용을 유발하며 최대 처리량을 달성하지 못합니다. 반복 작업당 32개의 패킷을 사용하는 영구 커널은 최대 처리량을 따라갈 수 있지만, 반복 작업당 개별 실행은 여전히 제어 플레인 오버헤드가 너무 많습니다. 반복 작업당 64개 및 128개 패킷의 경우 두 접근 방법 모두 최대 I/O 처리량에 도달할 수 있습니다. 여기서 처리량 측정은 패킷 무손실 측정이 아닙니다.
결론
이 게시물에서는 GPU를 사용하여 인라인 패킷 처리를 최적화하는 몇 가지 접근 방법을 다뤘습니다. 애플리케이션 요구 사항에 따라 몇 가지 워크플로우 모델을 적용하면 지연 시간이 감소하여 성능이 향상될 수 있습니다. 또한 DPDK gpudev 라이브러리는 코딩 작업을 간소화하여 최단 시간 안에 최적의 결과를 얻도록 해줍니다.
애플리케이션에 따라 고려해야 할 다른 요인으로는 패킷 처리를 트리거하기 전에 수신 측에서 충분한 패킷을 누적하는 데 걸리는 시간, 다른 작업 간의 병렬 처리를 최대한 향상하기 위해 사용할 수 있는 스레드 수, 작업 실행 시 커널이 영구적이어야 하는 시간 등이 있습니다.
이 블로그에 열거된 SDK의 대부분의 독점 액세스, 얼리 액세스, 기술 세션, 데모, 교육 과정, 리소스는 NVIDIA 개발자 프로그램 회원은 무료로 혜택을 받으실 수 있습니다. 지금 무료로 가입하여 NVIDIA의 기술 플랫폼에서 구축하는 데 필요한 도구와 교육에 액세스하시고 여러분의 성공을 가속화 하세요.