
인간이 눈으로 정보를 수집하는 것처럼 자율주행 자동차는 센서를 사용하여 정보를 수집합니다.센서는 방대한 양의 데이터를 수집하며, 이를 위해서는 차량이 도로 상황에 빠르게 반응할 수 있도록 효율적인 온보드 데이터 처리가 필요합니다.이 기능은 자율주행 자동차 안전에 매우 중요하며 가상 드라이버를 더 스마트하게 만드는 데 필수적입니다.
다양한 중복 센서와 컴퓨팅 시스템이 필요하므로 처리 파이프라인을 설계하고 최적화하는 것은 어렵습니다.이 게시물에서는 Pony.ai의 차량 내 센서 데이터 처리 파이프라인의 진화를 제시합니다.
Pony.ai의 센서 구성에는 여러 개의 카메라, LiDAR 및 레이더가 포함됩니다. 업스트림 모듈은 센서를 동기화하고, 데이터를 메시지 조각으로 캡슐화하며, 이를 사용하여 개체를 세분화, 분류 및 감지하는 다운스트림 모듈로 전송합니다.
각 유형의 센서 데이터에는 여러 모듈이 있을 수 있으며 사용자 알고리즘은 기존 또는 뉴럴 네트워크 기반일 수 있습니다.
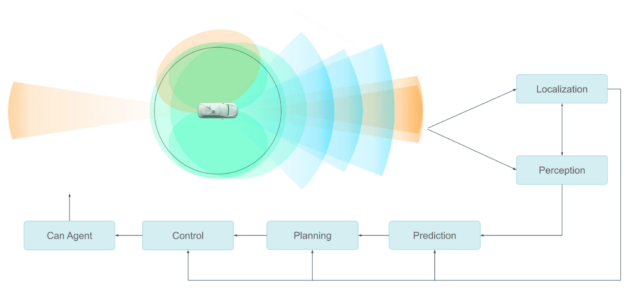
이러한 전체 파이프라인은 최고 수준의 효율성으로 실행되어야 합니다. 승객의 안전이 최우선 과제입니다. 센서 데이터 처리 시스템은 두 가지 측면에서 안전에 영향을 줍니다.
첫째, 안전에 결정적인 요소 중 하나는 자율주행 시스템이 센서 데이터를 처리하는 속도입니다. 인식 및 현지화 알고리즘이 수백 밀리초의 지연 속에서 센서 데이터를 얻으면 자동차의 결정이 너무 늦어질 것입니다.
둘째, 장기적인 성공을 위해서는 전체 HW/SW 시스템이 안정적이어야 합니다. 소비자는 제조 후 몇 달 만에 문제가 생기는 자율주행 차량을 구매하거나 탑승하려 하지 않을 것입니다. 이는 양산 단계에서 매우 중요합니다.
센서 데이터의 효율적 처리
Easing the b센서 처리 파이프라인의 병목 현상을 완화하려면 센서, GPU 아키텍처 및 GPU 메모리를 고려한 다중 접근 방식이 필요했습니다.
센서에서 GPU로
Pony.ai 설립 당시 NVIDIA의 원래 센서 설정은 기성품 구성 요소로 이뤄졌습니다. 저희는 차량 내 컴퓨터에 직접 연결된 카메라용 USB 및 이더넷 기반 모델을 사용했으며 CPU는 USB/이더넷 인터페이스에서 데이터를 읽는 역할을 했습니다.
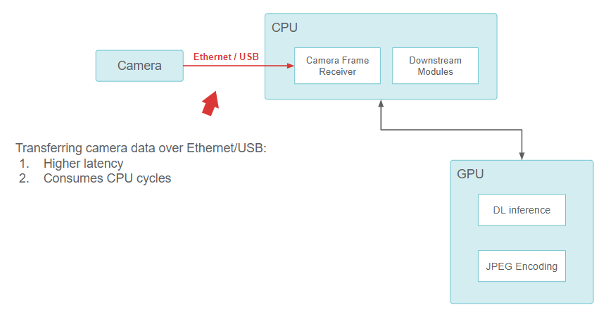
이더넷/USB를 통해 카메라 데이터를 전송하면 레이턴시가 더 높아지지만 CPU 사이클을 소모합니다.
이 기능은 잘 작동했지만 디자인에 근본적인 문제가 있었습니다. USB와 이더넷 카메라 인터페이스(GigE-camera)가 CPU를 소모했습니다. 점점 더 높은 해상도의 카메라가 추가되면서 CPU는 빠르게 압도되어 모든 I/O 작업을 수행할 수 없게 되었습니다. 충분히 낮은 레이턴시를 유지하면서 이 설계를 확장하기는 어려웠습니다.
저희는 카메라와 LiDAR용 FPGA 기반 센서 게이트웨이를 추가하여 문제를 해결했습니다.
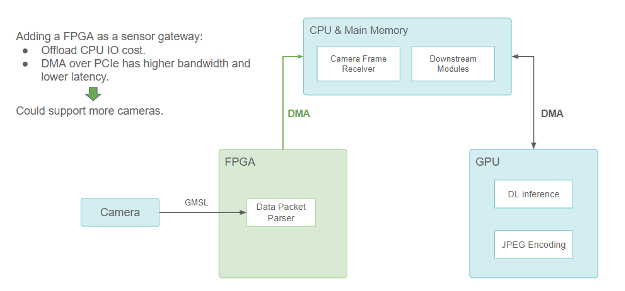
센서 게이트웨이로 FPGA를 추가하면 CPU I/O 비용이 오프로드되지만 PCIe를 통한 DMA는 대역폭이 높고 레이턴시가 짧기 때문에 더 많은 카메라를 지원할 수 있습니다.
FPGA는 카메라 트리거 및 동기화 로직을 처리하여 더 나은 센서 융합을 제공합니다. 하나 이상의 카메라 데이터 패킷이 준비되면 PCIe 버스를 통해 FPGA에서 주 메모리로 데이터를 복사하기 위해 DMA 전송이 트리거됩니다. DMA 엔진은 FPGA에서 이를 수행하며 CPU가 해제됩니다. CPU의 I/O 리소스를 개방할 뿐만 아니라 데이터 전송 레이턴시도 줄여서 보다 확장 가능한 센서 설정을 제공합니다.
카메라 데이터는 GPU에서 실행되는 많은 신경망 모델에 의해 사용되므로 FPGA에서 CPU로 DMA를 통해 전송된 후에도 GPU 메모리로 복사되어야 합니다. 따라서 어딘가에 CUDA HostToDevice 메모리 사본이 필요하며, FHD 카메라 이미지의 프레임 하나당 최대 1.5ms가 소요됩니다.
하지만 저희는 이 레이턴시를 더욱 줄이고자 했습니다. 이상적으로, 카메라 데이터는 CPU를 통해 라우팅되지 않고 GPU 메모리로 직접 전송되어야 합니다.
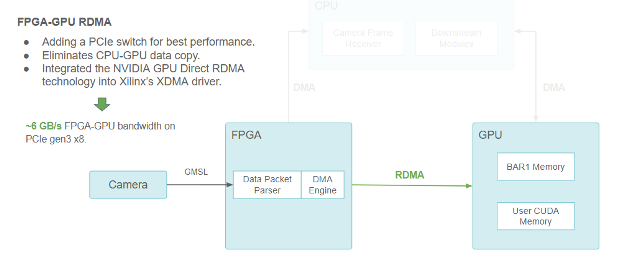
최고의 성능을 위해 FPGA-GPU RDMA를 사용하여 PCIe 스위치를 추가했습니다. 이 솔루션으로 CPU-GPU 데이터 카피가 제거되었습니다. 또한 저희는 NVIDIA GPU Direct RDMA 기술을 Xilinx의 XDMA 드라이버에 통합하여 PCIe Gen3 8개에서 FPGA-GPU 대역폭 최대 6GB/s를 기록했습니다.
NVIDIA GPU Direct RDMA를 사용하여 이 목표를 달성했습니다.GPU Direct RDMA를 사용하면 PCIe BAR(PCIe 주소 공간의 선형 창을 정의하는 기본 주소 레지스터)을 통해 PCIe 피어가 액세스할 수 있는 CUDA 메모리 청크를 사전 예약할 수 있습니다.
또한 타사 장치 드라이버가 GPU 메모리 물리적 주소를 얻을 수 있도록 일련의 커널 공간 API를 제공합니다. 이러한 API는 타사 장치의 DMA 엔진이 주 메모리로 데이터를 보내고 읽는 것처럼 GPU 메모리로 직접 데이터를 보내고 읽는 작업을 용이하게 합니다.
GPU Direct RDMA는 CPU 간 사본을 제거하여 레이턴시를 줄이고 이론적인 제한이 8GB/s인 PCIe Gen3 8개에서 최대 6GB/s의 대역폭을 달성합니다.
GPU 전반에서 확장
컴퓨팅 워크로드가 증가함에 따라 하나 이상의 GPU가 필요했습니다. 시스템에 GPU가 점점 더 많이 추가되면서 GPU 간 통신에서도 병목 현상이 발생할 수 있습니다. 스테이징 버퍼를 통해 CPU를 통과하면 CPU 비용이 증가하고 전체 대역폭이 제한됩니다.
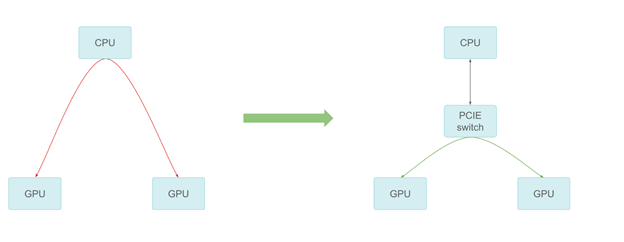
저희는 가능한 한 최상의 피어 투 피어 전송 성능을 제공하는 PCIe 스위치를 추가했습니다.피어 투 피어 통신은 측정 시 PCIe 라인 속도에 도달할 수 있으므로 여러 GPU에서 훨씬 더 나은 확장성을 제공합니다.
전용 하드웨어로 컴퓨팅 오프로드
또한 이전까지 CUDA 코어에서 실행되던 작업을 전용 하드웨어에 오프로드하여 센서 데이터 처리를 가속화했습니다.
예를 들어 FHD 카메라 이미지를 JPEG 문자열로 인코딩하는 경우 NvJPEG 라이브러리는 RTX5000 GPU가 있는 단일 CPU 스레드에서 최대 4ms를 필요로 합니다. NvJPEG는 허프만 인코딩과 같은 일부 단계가 완전히 CPU에 있을 수 있으므로 CPU 및 GPU 리소스를 소비할 수 있습니다.
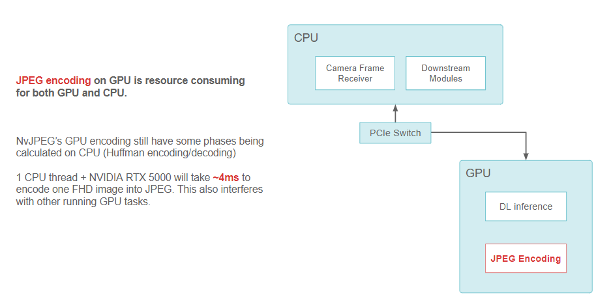
GPU에서의 JPEG 인코딩은 GPU 및 CPU 양쪽에서 리소스를 소모합니다. NvJPEG GPU 인코딩에는 여전히 CPU(허프만 인코딩 및 디코딩)에서 일부 단계가 계산됩니다. CPU 스레드 1개와 NVIDIA RTX 5000은 4ms 정도 소요하여 하나의 FHD 이미지를 JPEG로 인코딩합니다. 이는 다른 실행 중인 GPU 작업도 방해합니다.
저희는 CPU 및 GPU(CUDA 부분)가 이미지 인코딩 및 디코딩을 수행하지 않도록 차량 내 사용을 위한 NVIDIA 비디오 코덱을 채택했습니다. 이 코덱은 GPU의 전용 부분에서 인코더를 사용합니다. 이는 GPU의 일부이지만 커널 및 딥 러닝 모델을 실행하는 데 사용되는 다른 CUDA 리소스와 충돌하지 않습니다.
또한 NVIDIA GPU의 전용 하드웨어 비디오 인코더를 사용하여 이미지 압축 형식을 JPEG에서 HEVC(H.265)로 마이그레이션했습니다. 인코딩 속도를 높이고 다른 작업을 위한 CPU 및 GPU 리소스를 모두 확보했습니다.
CUDA 성능에 영향을 미치지 않고 GPU에서 FHD 이미지를 완전히 인코딩하는 데는 최대 3ms가 필요합니다. 성능은 I-프레임 전용 모드에서 측정되며, 이는 프레임 간에 일관된 품질과 압축 아티팩트를 보장합니다.

NVIDIA 비디오 코덱은 CUDA 코어 또는 CPU를 소모하지 않는 GPU 칩의 전용 파티션에서 인코더를 사용합니다. NVENC는 H264/H265를 지원합니다. 하나의 FHD 이미지를 HEVC에 인코딩하는 데 소요되는 시간이 약 3ms이므로 GPU와 CPU가 다른 작업을 수행할 수 있습니다. I-프레임 전용 모드를 사용하여 각 프레임이 동일한 품질과 아티팩트 유형을 갖도록 했습니다.
GPU상의 데이터 흐름
또 다른 중요한 주제는 카메라 프레임을 메시지로서 다운스트림에 전송하는 작업의 효율성입니다.
저희는 Google의 protobuf를 사용하여 메시지를 정의합니다. CameraFrame 메시지를 예로 들어 보겠습니다. 카메라 사양 및 속성은 메시지의 기본 유형입니다. protobuf의 제한 때문에 실제 페이로드(카메라 데이터)는 주 시스템 메모리의 바이트 필드로 정의해야 합니다.
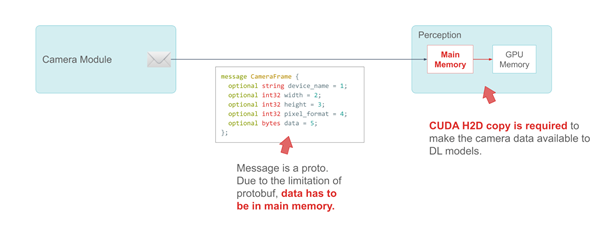
다음 코드 예제의 메시지는 프로토입니다. Protobuf의 제한으로 인해 데이터는 주 메모리에 있어야 합니다.
message CameraFrame {
optional string device_name = 1;
optional int32 width = 2;
optional int32 height = 3;
optional int32 pixel_format = 4;
optional bytes data = 5;
};
카메라 데이터를 DL 모델에 사용하려면 CUDA H2D 사본이 필요합니다.
저희는 정보를 공유하기 위해 모듈 간에 제로 카피 메시지 전달이 있는 퍼블리셔-구독자 모델을 사용합니다. 이 CameraFrame 메시지의 많은 구독자 모듈은 카메라 데이터를 사용하여 딥 러닝 추론을 합니다.
원래 디자인에서는 이러한 모듈이 메시지를 받았을 때 추론 전에 카메라 데이터를 GPU로 전송하기 위해 CUDA HostToDevice 메모리 사본을 호출해야 했습니다.
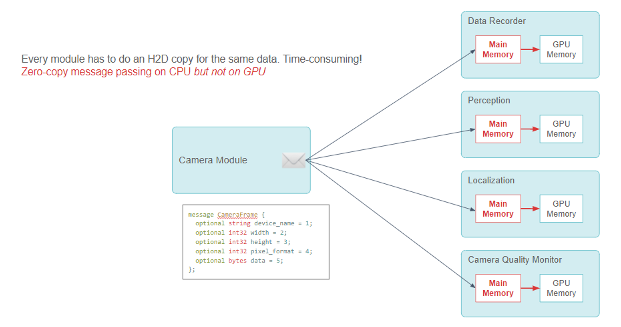
모든 모듈은 동일한 데이터에 대해 H2D 복사를 해야 하며, 이 작업에는 시간이 많이 걸립니다! 다음 코드 예제에서는 GPU가 아닌 CPU에서 전달되는 제로 카피 메시지를 보여줍니다.
message CameraFrame {
optional string device_name = 1;
optional int32 width = 2;
optional int32 height = 3;
optional int32 pixel_format = 4;
optional bytes data = 5;
};
모든 모듈은 중복되고 리소스가 많이 소요되는 CUDA HostToDevice 복사를 수행해야 합니다. 제로 카피 메시지 전달 프레임워크는 CPU에서 잘 작동하지만 수많은 CPU-GPU 데이터 사본이 관여합니다.

저희는 GPU 메모리의 데이터 필드를 활성화하기 위해 Protobuf codegen 플러그인을 사용했습니다. 다음 코드 예제에서는 GPU에서 전달되는 제로 카피 메시지를 보여줍니다. GPUData 필드는 GPU 메모리에 있습니다.
message CameraFrame {
optional string device_name = 1;
optional int32 width = 2;
optional int32 height = 3;
optional int32 pixel_format = 4;
optional GpuData data = 5;
};
새로운 유형의 데이터인 GpuData 필드를 Protobuf의 플러그인 API를 통해 Protobuf 코드 생성기에 추가하여 이 문제를 해결했습니다. GpuData는 CPU 메모리 bytes 필드와 같이 표준 resize 작업을 지원합니다. 그러나 물리적 데이터 스토리지는 GPU에 있습니다.
구독자 모듈은 메시지를 받으면 직접 사용하기 위해 GPU 데이터 포인터를 검색할 수 있습니다. 이렇게 해서 전체 파이프라인에서 전체 제로 카피를 달성했습니다.
GPU 메모리 할당 개선
GpuData 프로토의 resize 함수를 호출하면, 이는 CUDA cudaMalloc을 호출합니다. GpuData proto 메시지가 소멸되면 cudaFree를 호출합니다.
이 두 API 작업은 GPU의 메모리 맵을 수정해야 하기 때문에 비용이 저렴하지 않습니다. 각 호출에는 최대 0.1ms가 소요될 수 있습니다.
이 프로토 메시지는 카메라가 쉬지 않고 데이터를 생성하는 동안 광범위하게 사용되므로 GPU 프로토 메시지의alloc/free 비용을 최적화해야 합니다.
이 문제를 해결하기 위해 고정 슬롯 크기의 GPU 메모리를 구현했습니다. 아이디어는 간단합니다. 원하는 카메라 데이터 프레임 버퍼 크기에 맞게 사전 할당된 GPU 메모리 슬롯의 스택을 유지하는 것입니다. alloc이 호출될 때마다 스택에서 슬롯을 하나 가져옵니다. free가 호출될 때마다 슬롯이 풀로 반환됩니다. GPU 메모리를 다시 사용함으로써 alloc/free 시간이 0에 가까워집니다.

camera_frame.mutable_gpu_data()->Resize(size); ptr = pool->Alloc();
camera_frame destructs pool->Free(ptr);
서로 다른 해상도의 카메라를 지원하려면 어떻게 해야 할까요? 이 고정 크기 메모리 풀을 사용하여 가능한 한 가장 큰 크기를 할당하거나 여러 메모리 풀을 다양한 슬롯 크기로 초기화해야 합니다. 어느 쪽이든 효율이 낮아집니다.
CUDA 11.2의 새로운 기능이 이 문제를 해결했습니다. 공식적으로 cudaMemPool을 지원합니다. 이는 사전 할당되며 나중에 cudaMalloc 및 free에 사용됩니다. 이전 구현과 비교했을 때 모든 할당 크기에 도움이 됩니다. 이를 통해 적은 성능 비용(할당당 최대 2us)으로 유연성을 크게 개선할 수 있습니다.

camera_frame.mutable_gpu_data()->Resize(size); pool->cudaMallocFromPoolAsync(&ptr, pool, ...);
camera_frame destructs pool->cudaFreeAsync(ptr);
두 메서드에서 resize 호출은 메모리 풀이 오버플로되면 기존 cudaMalloc 및 free로 되돌아갑니다.
YUV 색 공간에서 더 깨끗한 데이터 흐름
저희는 하드웨어 설계 및 시스템 소프트웨어 아키텍처에 선행하는 모든 최적화를 통해 매우 효율적인 데이터 흐름을 달성했습니다. 다음 단계는 데이터 형식 자체를 최적화하는 것입니다.
NVIDIA의 시스템은 RGB 색 공간에서 카메라 데이터를 처리하는 데 사용됐습니다. 그러나 카메라의 ISP 출력은 YUV 색 공간에 있으며 GPU에서 YUV를 RGB로 전환하면 최대 0.3ms가 소요됩니다. 일부 인식 구성 요소에는 색 정보가 필요하지 않습니다. RGB 색조 픽셀을 입력하는 것은 낭비입니다.
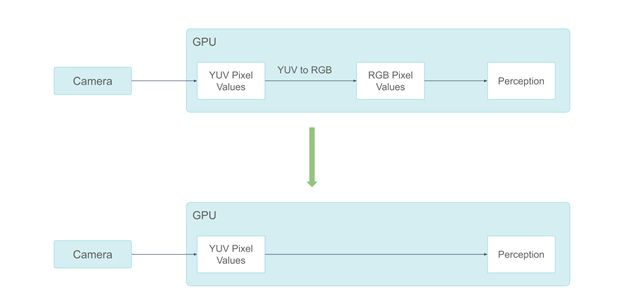
이러한 이유로 NVIDIA는 RGB 카메라 프레임에서 YUV 프레임으로 마이그레이션했습니다. 인간의 시각은 색차보다 휘도에 민감하기 때문에 YUV420 픽셀 형식을 사용하기로 결정했습니다.
YUV420 픽셀 형식을 채택함으로써 GPU 메모리 소비량을 절반으로 절감했습니다. 또한 색차 정보가 필요하지 않은 인식 구성 요소에 Y 채널만 보낼 수 있게 하여 RGB에 비해 GPU 메모리 소비량의 3분의 2를 절약했습니다.
GPU에서 라이다 데이터 처리
카메라 데이터뿐 아니라 보다 희소한 라이다 데이터도 대부분 GPU에서 처리합니다. 라이다는 유형이 다양하므로 처리하기가 더 어렵습니다. 저희는 라이더 데이터를 처리할 때 몇 가지 최적화를 수행했습니다.
- 라이다 스캔 데이터에는 많은 물리적 정보가 포함되어 있으므로, 포인트 클라우드를 설명하기 위해 구조 배열(Array of Structure) 대신 GPU 친화적인 배열 구조(Structure of Array)를 사용하여 GPU 메모리 액세스 패턴이 흩어지지 않고 더 결합되게 만들었습니다.
- CPU와 GPU 간에 일부 필드를 교환해야 하는 경우 전송 가속화를 위해 페이지 고정 메모리에 보관합니다.
- NVIDIA CUB 라이브러리는 처리 파이프라인, 특히 스캔/선택 작업에 광범위하게 사용됩니다.
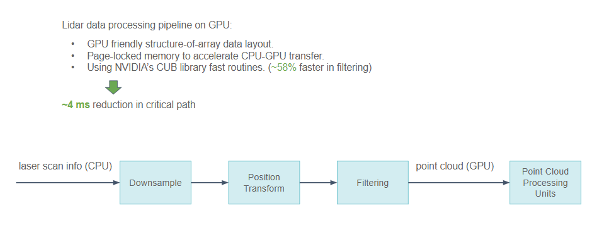
GPU의 라이다 데이터 처리 파이프라인은 다음 결과를 생성합니다.
- GPU 친화적인 배열 구조 데이터 레이아웃.
- CPU-GPU 전송을 가속화하는 페이지 고정 메모리.
- 필터링 속도가 최대 58% 빠른 NVIDIA CUB 라이브러리 루틴.
이러한 최적화를 통해 전체 파이프라인 레이턴시를 중요 경로에서 최대 4ms 낮출 수 있었습니다.
전체 타임라인
이러한 모든 최적화를 통해 사내 타임라인 시각화 도구를 사용하여 시스템 트레이싱을 볼 수 있습니다.

전체 타임라인은 오늘날 우리가 얼마나 집약적으로 GPU에 의존하는지 대략적으로 보여줍니다. 두 GPU는 최대 80%의 시간 동안 사용되지만 GPU0 및 GPU1 워크로드의 균형이 이상적으로 조정되지는 않습니다. GPU 0의 경우 인식 모듈 반복 작업에 많이 사용됩니다. GPU 1의 경우 반복 작업 도중에 유휴 간격이 더 많습니다.
향후에는 GPU 효율을 더욱 개선하는 데 주력할 것입니다.
생산 준비
개발 초기에 FPGA를 통해 하드웨어 기반 센서 데이터 처리 분야에서 아이디어를 쉽게 실험할 수 있었습니다. 센서 데이터 처리 장치가 점점 더 발전함에 따라 저희는 SoC(System-on-a-Chip)를 사용하여 신뢰할 수 있고 생산 준비된 컴팩트 센서 데이터 프로세서를 제공할 가능성을 모색하고 있습니다.
저희는 자동차 등급 NVIDIA DRIVE Orin SoC가 요구 사항을 완벽하게 충족한다는 사실을 발견했습니다. ASIL 등급이므로 생산 차량에서 실행하기에 매우 적합합니다.
FPGA에서 NVIDIA DRIVE Orin으로 마이그레이션
개발 초기에 FPGA를 통해 하드웨어 기반 센서 데이터 처리 분야에서 아이디어를 쉽게 실험할 수 있었습니다.
센서 데이터 처리 장치가 점점 더 발전함에 따라 저희는 SoC(System-on-a-Chip)를 사용하여 신뢰할 수 있고 생산 준비된 컴팩트 센서 데이터 프로세서를 제공할 가능성을 모색하고 있습니다.
저희는 자동차 등급 NVIDIA DRIVE Orin SoC가 요구 사항을 완벽하게 충족한다는 사실을 발견했습니다. ASIL 등급이므로 생산 차량에서 실행하기에 매우 적합합니다. 컴팩트한 크기와 저렴한 비용에도 불구하고 광범위한 자동차 등급 센서에 연결하여 대규모 센서 데이터를 효율적으로 처리할 수 있습니다.
NVIDIA Orin을 사용하여 모든 센서 신호 처리, 동기화, 패킷 수집, 카메라 프레임 인코딩을 처리할 예정입니다. 이 디자인은 다른 아키텍처 최적화와 결합하여 총 BOM 비용을 최대 70% 절감할 것으로 추정됐습니다.
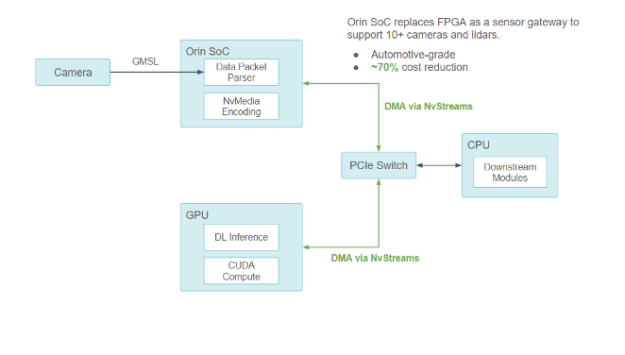
Orin SoC는 FPGA를 센서 게이트웨이로 대체하여 자동차 등급인 10개 이상의 카메라와 라이더를 지원함으로써 최대 70%의 비용 절감을 실현합니다.
NVIDIA와의 협업을 통해 Orin-CPU-GPU 구성 요소 간의 모든 통신이 NvStream을 통한 DMA 지원과 함께 PCIe 버스를 거치게 했습니다.
- 컴퓨팅 집약적인 DL 작업의 경우 NVIDIA Orin SoC는 NvStream을 사용하여 센서 데이터를 외장 GPU로 전송하고 처리합니다.
- GPU 작업이 아닌 경우 NVIDIA Orin SoC는 NvStream을 사용하여 데이터를 처리하기 위해 호스트 CPU로 전송합니다.
레벨 2/3 컴퓨팅 플랫폼 애플리케이션
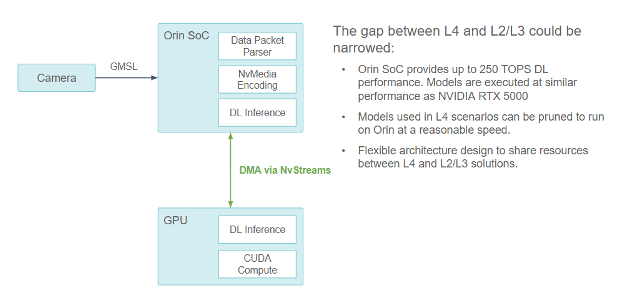
Orin SoC가 최대 250 TOPS DL 성능을 제공하므로 L4와 L2/L3 간의 격차를 좁힐 수 있습니다. 모델은 NVIDIA RTX 5000과 비슷한 성능으로 실행되므로 L4 시나리오에 사용된 모델을 Orin에서 합리적인 속도로 실행되도록 정리할 수 있습니다. 유연한 아키텍처 설계는 L4와 L2/L3 솔루션 간에 리소스를 공유할 수 있습니다.
이 설계의 훌륭한 이점은 L2/L3 컴퓨팅 플랫폼으로 사용될 여지가 있다는 것입니다.
NVIDIA Orin은 현재 레벨 4 자율주행 자동차 컴퓨팅 플랫폼에서 사용되는 RTX5000 외장 GPU와 유사한 워크로드를 처리할 수 있는 초당 254조 회 연산 컴퓨팅 성능을 제공합니다. 하지만 NVIDIA Orin SoC의 잠재력을 최대한 활용하기 위해서는 다음과 같은 여러 가지 최적화가 필요합니다.
- 구조적 sparse 네트워크
- DLA 코어
- 여러 NVIDIA Orin SoC에서 확장
결론
Pony의 센서 데이터 처리 파이프라인 발전은 더 높은 안전 목표를 달성하는 데 도움이 되는 고효율 데이터 처리 파이프라인 및 향상된 시스템 신뢰성에 대한 저희의 체계적인 접근 방식을 제시했습니다. 이 접근 방식의 핵심은 다음과 같습니다.
- 데이터 흐름을 단순하고 매끄럽게 만듭니다. 데이터는 전환 오버헤드를 최소화하는 형식으로 소비되는 위치로 직접 전송되어야 합니다.
- 컴퓨팅 집약적인 작업에 전용 하드웨어를 사용하여 다른 작업에 대한 범용 컴퓨팅 리소스를 절약합니다.
- 레벨 4와 레벨 2 시스템 간의 리소스 공유는 신뢰를 높이고 엔지니어링 비용을 절감합니다.
이러한 접근 방식은 소프트웨어나 하드웨어 하나만으로는 달성할 수 없으며 소프트웨어 및 하드웨어 공동 설계를 통해서 둘 다 활용해야 가능합니다. 이는 빠르게 성장하는 컴퓨팅 요구 사항과 생산 측면의 기대를 충족하는 데 매우 중요하다고 생각합니다.
도움 주신 분들
이 게시물에는 Pony의 센서 데이터 파이프라인에서 수년 동안 개발된 내용이 포함되어 있습니다. 이 대단히 효율적인 센서 데이터 파이프라인 개발에 지속적으로 기여해 온 여러 팀과 엔지니어에게 감사드립니다.