
cuDF-pandas, introduced in a previous post, is a GPU-accelerated library that accelerates pandas to deliver significant performance improvements—up to 50x faster—without requiring any changes to your existing code. As part of the NVIDIA RAPIDS ecosystem, cuDF-pandas acts as a proxy layer that executes operations on the GPU when possible, and falls back to the CPU (via pandas) when necessary. This ensures compatibility with the full pandas API and third-party libraries while leveraging GPU acceleration for faster data processing. By simply loading cuDF-pandas, users can maintain their familiar pandas workflows while benefiting from a unified CPU/GPU experience.
Under the hood, cuDF-pandas uses a managed memory pool by default, enabling it to handle datasets that exceed the physical memory of the GPU. This is achieved through CUDA Unified Virtual Memory (UVM), which provides a unified address space spanning both host (CPU) and device (GPU) memory. UVM allows cuDF-pandas to oversubscribe GPU memory, automatically migrating data between host and device as needed.
This blog post will go over why UVM is needed and its benefits.
Why cuDF-pandas uses UVM
Unified Virtual Memory is critical for addressing two key challenges in GPU-accelerated data processing:
- Limited GPU Memory: Many GPUs, especially consumer-grade models, have significantly less memory than modern datasets require. UVM enables oversubscription, allowing workloads to scale beyond the physical GPU memory by utilizing system memory.
- Ease of Use: UVM simplifies memory management by automatically handling data migration between CPU and GPU. This reduces programming complexity and ensures that users can focus on their workflows without worrying about explicit memory transfers.
Details on UVM
Unified Virtual Memory (UVM), introduced in CUDA 6.0, creates a single virtual address space shared between the CPU and GPU, simplifying memory management for developers. UVM transparently migrates data at page granularity based on access patterns:
- When the GPU accesses data residing in host memory, it triggers a page fault, prompting the data to migrate to GPU memory.
- Conversely, when GPU memory is full, less-used pages are evicted back to host memory.
While UVM extends memory capacity and simplifies programming by eliminating the need for explicit memory transfers, it can introduce performance bottlenecks due to page faults and migration overhead. To mitigate these issues, optimizations like prefetching (e.g., using cudaMemPrefetchAsync) are employed to proactively move data to the GPU before kernel execution. Below is an nsys profile plot showing multiple calls to cudaMemPrefetchAsync in the CUDA API layer right before a libcudf kernel execution:

For a deeper dive into Unified Memory, including its benefits and practical examples of optimizations like prefetching and memory advice (cudaMemAdvise), refer to the technical blog Unified Memory for CUDA Beginners. The blog explains how UVM works across different GPU architectures and provides tips for maximizing performance in real-world applications.
How cuDF-pandas leverages UVM
In cuDF-pandas, UVM plays a pivotal role in enabling high-performance data processing:
- Managed Memory Pool: By default,
cuDF-pandasuses a managed memory pool backed by UVM. This pool reduces allocation overheads and ensures efficient use of both host and device memory. - Prefetching Optimization: Prefetching ensures that data is migrated to the GPU before it is accessed by kernels, reducing runtime page faults. For example, during I/O operations or joins that require large amounts of data, prefetching ensures smoother execution by proactively moving data into device memory. As mentioned earlier, these prefetch calls occur in the
libcudflayer for specific kernels like hash joins.
Example: A large join and write parquet on Google Colab
Consider performing a merge/join operation on two very large tables, cuDF-pandas on Google Colab with limited GPU memory:
- Without UVM, this operation would fail due to insufficient device memory.
- With UVM enabled, the datasets are split between host and device memory. As the join proceeds, only the required portions of data are migrated to the GPU.
- Prefetching further optimizes this process by ensuring that relevant data is brought into device memory ahead of computation.
Users can leverage GPUs for larger datasets that exceed GPU memory without code changes. Using Unified Virtual Memory (UVM), speedups vary by operation but still provide significant gains for end-to-end applications while maintaining stability.

CPU hardware: Intel(R) Xeon(R) Gold 6130 CPU @ 2.10GHz, GPU hardware: NVIDIA T4
Same is the case for writing to a parquet file. What would have run into a MemoryError with cudf, now completes successfully with cuDF-pandas and even faster than pandas.
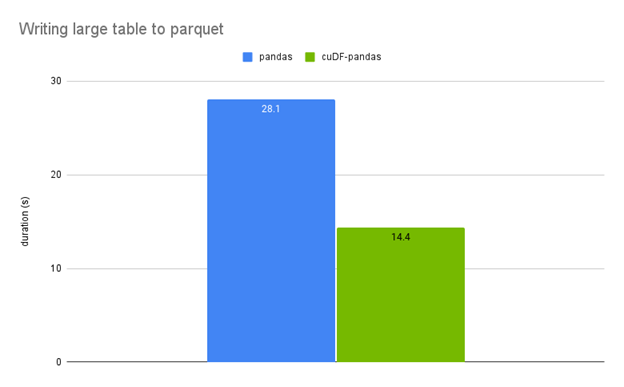
CPU hardware: Intel(R) Xeon(R) Gold 6130 CPU @ 2.10GHz, GPU hardware: NVIDIA T4
Conclusion
Unified Virtual Memory is a cornerstone of cuDF-pandas, enabling it to process large datasets efficiently while maintaining compatibility with low-end GPUs. By leveraging features like managed memory pools and prefetching, cuDF-pandas delivers both performance and stability for pandas workflows on constrained hardware. This makes it an ideal choice for scaling data science pipelines without sacrificing usability or requiring extensive code modifications.
Try this Google Colab notebook to see the ability of execution of larger than GPU memory datasets in action.
