
In today’s globalized world, the ability of AI systems to understand and communicate in diverse languages is increasingly crucial. Large language models (LLMs) have revolutionized the field of natural language processing, enabling AI to generate human-like text, answer questions, and perform various language tasks. However, most mainstream LLMs are trained on data corpora that primarily consist of English, limiting their applicability to other languages and cultural contexts.
This is where multilingual LLMs come into play, bridging the language gap and unlocking the potential of AI for a broader audience.
In particular, current state-of-the-art LLMs often struggle with Southeast Asian (SEA) languages due to limited training data and the unique linguistic characteristics of these languages. This results in lower performance compared to high-resource languages like English. While some LLMs can handle certain SEA languages to an extent, they still exhibit inconsistencies, hallucinations, and safety issues.
Meanwhile, there is a strong interest and determination in developing localized multilingual LLMs in SEA. One notable example is Singapore’s launch of a S$70M initiative to develop the National Multimodal Large Language Model Programme (NMLP).
This two-year national-level initiative aims to build Southeast Asia’s first regional LLM, focusing on understanding the region’s unique linguistic and cultural nuances. As the demand for AI solutions grows in SEA, the development of localized multilingual LLMs becomes a strategic necessity.
A similar trend can be seen in other regions, where current state-of-the-art LLMs are not sufficient to support the complexity of the regional languages. These models can help businesses and organizations better serve their customers, automate processes, and create more engaging content that resonates with the region’s diverse population.
NVIDIA NeMo is an end-to-end platform for developing custom generative AI, anywhere. It includes tools for training, and retrieval-augmented generation (RAG), guardrailing and toolkits, data curation tools, and pretrained models, offering enterprises an easy, cost-effective, and fast way to adopt generative AI.
In this series, we explore the best practices for adding new language support to base LLMs using NeMo. This tutorial walks you through steps such as tokenizer training and merging; model architecture modification, and model continual pretraining.
In this post, we use Thai Wikipedia data to continually pretrain a GPT-1.3B model. We focus on training and merging a multilingual tokenizer in Part 1 and then discuss adopting the customized tokenizer in NeMo models and performing continual pretraining in Part 2.
By following these guidelines, you can contribute to the growth of multilingual AI and make the benefits of LLMs accessible to a wider global audience.
Overview for training localized multilingual LLM
One significant challenge for multilingual LLMs is the insufficiency in pretrained foundation LLMs that understand the target language. To construct a multilingual LLM, you have several options:
- Use a multilingual dataset to pretrain the LLM from scratch.
- Adopt continual pretraining on English foundation models using a dataset of the target language.
In the context of low-resource languages, the latter option is more feasible. Low-resource languages, by definition, have limited available training data. Continual pretraining can effectively adapt the model to a new language even with a relatively small amount of data by leveraging transfer learning from the high-resource language on which the model was originally trained.
Pretraining from scratch would require a much larger amount of data in the low-resource language to reach the same level of performance.
One challenge raised when attempting to use low-resource data for continual pretraining is the suboptimal tokenizer. The majority of foundation models adopt byte-pair encoding (BPE) tokenizers. The original tokenizer does not adequately cover the unique characters, subwords, and morphology of the low-resource language.
Without a sufficiently expressive tokenizer, the model struggles to represent the low-resource language efficiently, leading to suboptimal performance. It’s necessary to build a customized tokenizer that enables the model to process and learn from the low-resource language data more effectively during continual pretraining.
To address these problems, we propose the following workflow to add new language support for LLMs.
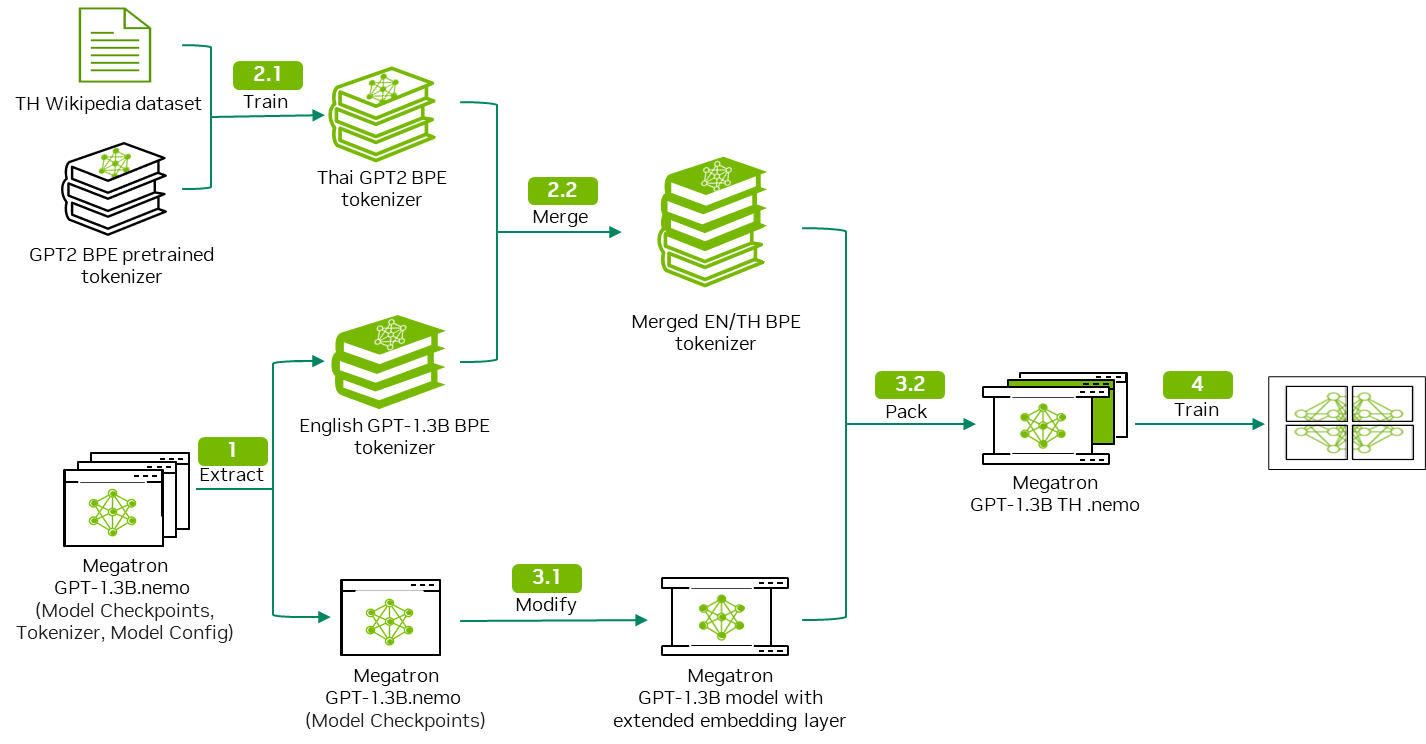
This workflow uses Thai Wikipedia data as example input in the following steps::
- Download and extract the GPT model to obtain model weights and the model tokenizer.
- Customize the tokenizer training and merge to output a bilingual tokenizer.
- Modify the GPT model architecture to accommodate the bilingual tokenizer.
- Perform continual pretraining using the Thai Wikipedia data.
This workflow is generic and can be applied to different language datasets. Steps 1 and 2 are covered in this post. For steps 3 and 4, see part 2.
Tutorial prerequisites
For continual pretraining of a GPT-1.3B model, we recommend using the following hardware setup:
- NVIDIA GPU with at least 30 GB of GPU memory
- CUDA and NVIDIA Drivers: CUDA 12.2 with Driver 535.154.05
- Ubuntu 22.04
- NVIDIA-container-toolkit version 1.14.6
- NeMo framework container 24.01.01
The NGC catalog provides access to GPU-accelerated software that speeds up end-to-end workflows with performance-optimized containers, pretrained AI models, and industry-specific SDKs that can be deployed on-premises, in the cloud, or at the edge.
As a first step, download the NeMo framework container from the NGC catalog and run JupyterLab in the container image:
docker pull nvcr.io/nvidia/nemo:24.01.01.framework
docker run -it --gpus all -v <your working directory>:<your working directory in container> --workdir <your working directory> -p 8888:8888/ nvcr.io/nvidia/nemo:24.01.01.framework bash -c "jupyter lab"
Data collection and cleaning
For this tutorial, use the NVIDIA NeMo Curator repository on GitHub to download and curate high-quality Thai Wikipedia data. NVIDIA NeMo Curator consists of a collection of scalable data-mining modules for curating NLP data for training LLMs. The modules within NeMo Curator enable NLP researchers to mine high-quality text at scale from massive uncurated web corpora.
Follow these steps for the curation pipeline:
- Separate languages to filter non-Thai content.
- Reformat documents to rectify any Unicode.
- Perform document-level exact deduplication and fuzzy deduplication to remove duplicated data points.
- Perform document-level heuristic filtering to remove low-quality documents.
The curation process for additional languages can be replicated by using the same flow demonstrated in NVIDIA NeMo Curator.
Model download and extraction
For this post, we use the nemo-megatron-gpt-1.3B model. This model was trained on the Pile dataset (monolingual English dataset). You should be able to download the model directly from HuggingFace. Alternatively, you can run the following command to download the model:
!wget -P './model/nemo_gpt_megatron_1pt3b_fb16/' https://huggingface.co/nvidia/nemo-megatron-gpt-1.3B/resolve/main/nemo_gpt1.3B_fp16.nemo
Verify the MD5 checksum of the downloaded file to ensure its integrity:
!md5sum nemo_gpt1.3B_fp16.nemo
You should get the following as output:
38f7afe7af0551c9c5838dcea4224f8a nemo_gpt1.3B_fp16.nemo
After downloading the model, extract the vocab.json and merge.txt files from the model:
!tar -xvf ./model/nemo_gpt_megatron_1pt3b_fb16/nemo_gpt1.3B_fp16.nemo -C ./model/nemo_gpt_megatron_1pt3b_fb16/
The command produces the following output and you now have access to the vocab.json and merge.txt files, which are later used for tokenizer merging.
./
./50284f68eefe440e850c4fb42c4d13e7_merges.txt
./c4aec99015da48ba8cbcba41b48feb2c_vocab.json
./model_config.yaml
./model_weights.ckpt
Tokenizer training
To train a tokenizer that’s capable of tokenizing other languages and English, you can adopt one of two approaches:
- Multilingual dataset: Use a multilingual dataset that includes English to train the tokenizer from scratch. The advantage is that you can obtain a real distribution of the multilingual dataset.
- Single-language dataset: Train a monolingual tokenizer and then merge it with the original English tokenizer. The advantage is that you can keep the original token mappings of English tokens and reuse the embedding layer of the foundation model. The time consumed for tokenizer training is much shorter.
This tutorial uses the single-language dataset approach to retain the embedding layer of the pretrained GPT Megatron model.
Detailed steps for this method include:
- Collect tokenizer training data: Subsample from the dataset prepared for continual pretraining. In this tutorial, 30% of the training data is randomly sampled for tokenizer training.
- Train the customized GPT2 tokenizer: Use the pretrained HuggingFace GPT2 tokenizer as a starting point and train the TH GPT2 tokenizer using your own data corpus.
- Merge both tokenizers: Manually merge
merges.txtandvocab.jsonfor both tokenizers.
For this tutorial, use Thai as the target language.
Import the necessary libraries
Import the following libraries before starting:
import os
from transformers import GPT2Tokenizer, AutoTokenizer
import random import json
Prepare the training corpus
Define a function convert_jsonl_to_txt that samples from the training document data and writes them into an output file in .txt format. For this tutorial, use 'text' as a JSON key to access the training document data. Change the key as needed.
def convert_jsonl_to_txt(input_file, output_file, percentage, key='text'):
with open(input_file, 'r', encoding='utf-8') as in_file, open(output_file, 'a', encoding='utf-8') as out_file:
for line in in_file:
if random.random() < percentage:
data = json.loads(line)
out_file.write(f"{data[key].strip()}\n")
Now you can read your input files and form your tokenizer training corpus:
for file in os.listdir('./training_data'):
if 'jsonl' not in file:
continue
input_file = os.path.join('./training_data',file)
convert_jsonl_to_txt(input_file,'training_corpus.txt', 0.3)
with open('training_corpus.txt', 'r') as file:
training_corpus = file.readlines()
In the case where the training corpus is too large to be loaded in one goal, use iterator methods to load the training corpus. For more information, see Training a new tokenizer from an old one.
Train the monolingual tokenizer
Load a pretrained GPT2 tokenizer as a starting point, followed by calling the tokenizer.train_new_from_iterator method to train a new tokenizer.
Vocab_size is an important parameter in tokenizer.train_new_from_iterator. It determines the maximum number of unique tokens in the vocabulary. A larger value enables more fine-grained tokenization but increases model complexity, while a smaller value leads to more coarse-grained tokenization with fewer unique tokens but a simpler model.
old_tokenizer = AutoTokenizer.from_pretrained("gpt2")
new_tokenizer = old_tokenizer.train_new_from_iterator(training_corpus, vocab_size=8000)
new_tokenizer.save_pretrained('./new_monolingual_tokenizer/')
Now that you’ve finished training a new monolingual tokenizer, inspect the effectiveness of the new tokenizer on the target language. Use both the pretrained GPT2 tokenizer and TH tokenizer to tokenize a Thai sentence and an English sentence, respectively:
- Thai sentence: “เมืองหลวงของประเทศไทยคือกรุงเทพฯ” meaning “The capital of Thailand is Bangkok.”
- English sentence: “The capital of Thailand is Bangkok.”
Thai_text='เมืองหลวงของประเทศไทยคือกรุงเทพฯ'
print(f"Sentence:{Thai_text}")
print("Output of TH tokenizer: ",new_tokenizer.tokenize(Thai_text,return_tensors='pt'))
print("Output of pretrained tokenizer: ", old_tokenizer.tokenize(Thai_text,return_tensors='pt'))
Eng_text="The capital of Thailand is Bangkok."
print(f"Sentence:{Eng_text}")
print("Output of TH tokenizer: ",new_tokenizer.tokenize(Eng_text,return_tensors='pt'))
print("Output of pretrained tokenizer: ", old_tokenizer.tokenize(Eng_text,return_tensors='pt'))
You should expect to get the following lines as output:
Sentence:เมืองหลวงของประเทศไทยคือกรุงเทพฯ
Output of TH tokenizer: ['à¹Ģม', 'ื', 'à¸Ńà¸ĩหลวà¸ĩ', 'à¸Ĥà¸Ńà¸ĩà¸Ľà¸£à¸°à¹Ģà¸Ĺศà¹Ħà¸Ĺย', 'à¸Ħ', 'ื', 'à¸Ńà¸ģร', 'ุ', 'à¸ĩà¹Ģà¸Ĺà¸ŀฯ']
Output of pretrained tokenizer: ['à¹', 'Ģ', 'à¸', '¡', 'à¸', '·', 'à¸', 'Ń', 'à¸', 'ĩ', 'à¸', '«', 'à¸', '¥', 'à¸', '§', 'à¸', 'ĩ', 'à¸', 'Ĥ', 'à¸', 'Ń', 'à¸', 'ĩ', 'à¸', 'Ľ', 'à¸', '£', 'à¸', '°', 'à¹', 'Ģ', 'à¸', 'Ĺ', 'à¸', '¨', 'à¹', 'Ħ', 'à¸', 'Ĺ', 'à¸', '¢', 'à¸', 'Ħ', 'à¸', '·', 'à¸', 'Ń', 'à¸', 'ģ', 'à¸', '£', 'à¸', '¸', 'à¸', 'ĩ', 'à¹', 'Ģ', 'à¸', 'Ĺ', 'à¸', 'ŀ', 'à¸', '¯']
Sentence:The capital of Thailand is Bangkok.
Output of TH tokenizer: ['The', 'Ġc', 'ap', 'ital', 'Ġof', 'ĠThailand', 'Ġis', 'ĠB', 'ang', 'k', 'ok', '.']
Output of pretrained tokenizer: ['The', 'Ġcapital', 'Ġof', 'ĠThailand', 'Ġis', 'ĠBangkok', '.']
From the output, you can see the TH tokenizer produces a much shorter list of tokens as compared to the English tokenizer for the Thai sentence, and the reverse for the English sentence.
The reason is that many Thai characters, especially those representing vowels and tonal markers, are likely to be considered out-of-vocabulary (OOV) for an English tokenizer. The tokenizer may split these into individual bytes or replace them with an UNK token, increasing the token count.
Tokenizer merging
To merge two tokenizers, you must handle the vocab.json and merges.txt files. Here’s how to merge the files.
For the vocab.json file:
- Maintain the pretrained tokenizer’s
vocab.jsonID-token mapping. - Iterate through the customized monolingual tokenizer’s
vocab.jsonfile when encountering a new token. - Add it to the original
vocab.jsonfile with the accumulating token ID.
For the merges.txt file:
- The pretrained tokenizer’s
merges.txtfile remains unchanged. - Iterate through the customized monolingual tokenizer’s
merges.txtfile. - When you encounter a new merge rule, add it to the original
merges.txt.
The rule is that, when merging, you can’t take the union of the vocab.json files or the merges.txt files, regardless of the original order.
For vocab.json, you must keep the original ID-token mapping identical to reuse the pretrained embedding layer. If the mapping is disturbed when you load the newly merged tokenizer to the pretrained model and try to get the embedding of the token ‘dog’, the model might output the pretrained embedding of other token, such as ‘cat’, as the token ID of token ‘dog’ is changed during merging.
For merges.txt, the order of the merge rules in merge.txt is crucial for the BPE tokenizer to function optimally when tokenizing new text. The tokenizer applies these rules sequentially, starting from the first rule and proceeding down the list until no further rules can be applied. Changing the order of the merge rules can significantly impact the tokenizer’s performance and lead to suboptimal tokenization.
Here’s an example. Suppose that you have a token list ['N', 'VI', 'D', 'IA'] and two different sets of merge rules:
Set A:
N VI
D IA
NVI DIA
Set B:
D IA
NVI DIA
N VI
When applying Set A to the token list, the tokenizer follows the merge rules in the given order:
['N', 'VI', 'D', 'IA'] -> ['NVI', 'D', 'IA'](Rule 1 applied.)['NVI', 'D', 'IA'] -> ['NVI', 'DIA'](Rule 2 applied.)['NVI', 'DIA'] -> ['NVIDIA'](Rule 3 applied.)
The final tokenized output is ['NVIDIA'], which is the desired result.
However, when applying Set B to the same token list, the tokenizer encounters a problem:
['N', 'VI', 'D', 'IA'] -> ['N', 'VI', 'DIA'](Rule 1 applied.)['N', 'VI', 'DIA'](No further rules can be applied since the first token in the next merge rule,'NVI', is not found.)
In this case, the tokenizer fails to merge 'N' and 'VI' because the merge rule 'N VI' appears after 'NVI DIA'. As a result, the tokenizer produces the suboptimal output ['N', 'VI', 'DIA'] instead of the desired ['NVIDIA'].
Changing the order of the rules alters the tokenizer’s behavior and potentially degrades its performance.
Run the following code for tokenizer merging:
output_dir = './path_to_merged_tokenizer'
# Make the directory if necessary
if not os.path.exists(output_dir ):
os.makedirs(output_dir)
#Read vocab files
old_vocab = json.load(open(os.path.join('./path_to_pretrained_tokenizer', 'vocab.json')))
new_vocab = json.load(open(os.path.join('./path_to_cusotmized_tokenizer', 'vocab.json')))
next_id = old_vocab[max(old_vocab, key=lambda x: int(old_vocab[x]))] + 1
# Add words from new tokenizer
for word in new_vocab.keys():
if word not in old_vocab.keys():
old_vocab[word] = next_id
next_id += 1
# Save vocab
with open(os.path.join(output_dir , 'vocab.json'), 'w') as fp:
json.dump(old_vocab, fp, ensure_ascii=False)
old_merge_path = os.path.join('./path_to_pretrained_tokenizer', 'merges.txt')
new_merge_path = os.path.join('./path_to_cusotmized_tokenizer', 'merges.txt')
#Read merge files
with open(old_merge_path, 'r') as file:
old_merge = file.readlines()
with open(new_merge_path, 'r') as file:
new_merge = file.readlines()[1:]
#Add new merge rules, the order of merge rule has to be maintained
old_merge_set = set(old_merge)
combined_merge = old_merge + [merge_rule for merge_rule in new_merge if merge_rule not in old_merge_set]
# Save merge.txt
with open(os.path.join(output_dir , 'merges.txt'), 'w') as file:
for line in combined_merge:
file.write(line)
You can now load and test the combined tokenizer and compare its tokenization output with the pretrained tokenizer and customized monolingual tokenizer. You should be able to observe that the combined tokenizer is working well on tokenizing both the target language and English.
Conclusion
At this point, you’ve successfully customized a BPE tokenizer capable of tokenizing English and the target language.
In the next post, you alter the pretrained model’s embedding layer to adopt the customized tokenizer and start using the modified model together with the customized tokenizer for continual pretraining in NeMo.
To get started with training a multilingual tokenizer, start curating a low-resourced language dataset for training by downloading and setting up the open-sourced NeMo Curator on GitHub. Alternatively, as part of the NeMo microservices early access program, you can also request access to NVIDIA NeMo Curator to accelerate and simplify your data curation pipeline.
