
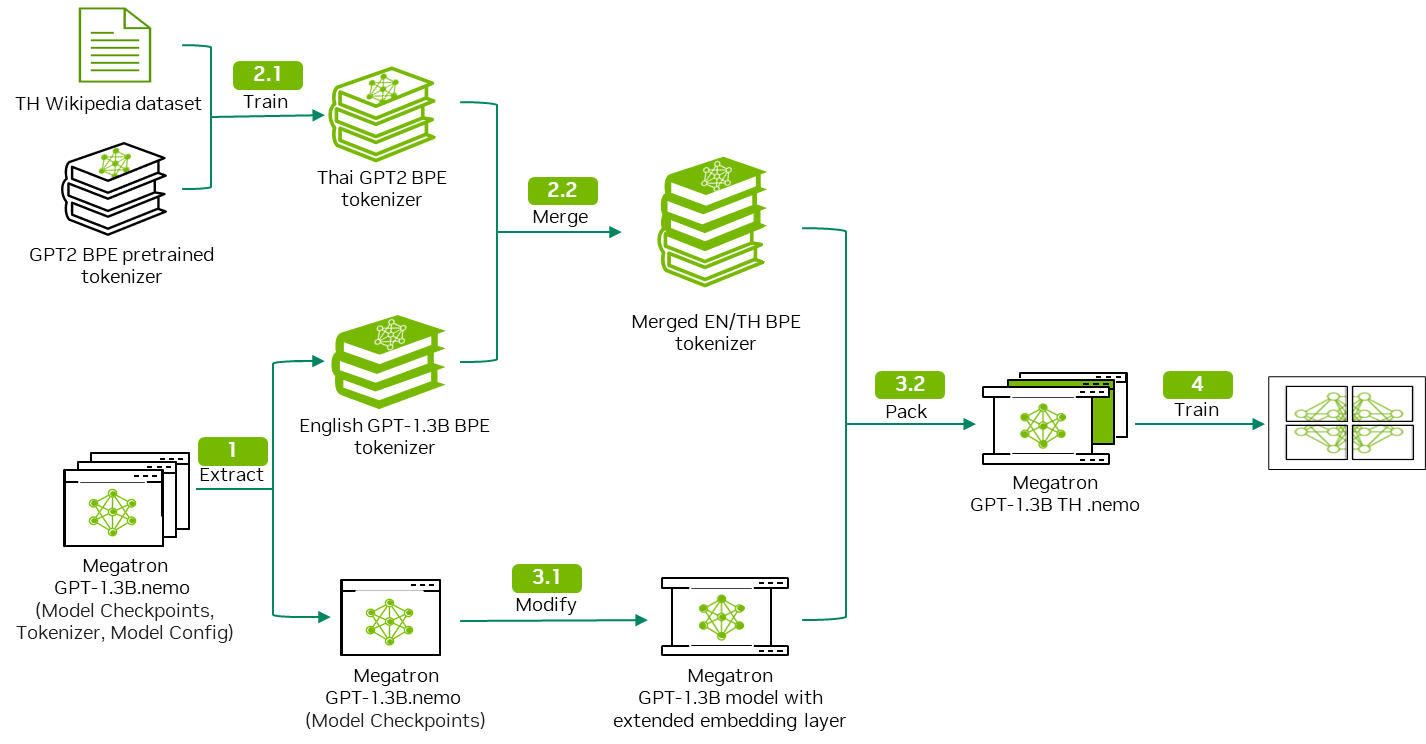
In Part 1, we discussed how to train a monolingual tokenizer and merge it with a pretrained LLM’s tokenizer to form a multilingual tokenizer. In this post, we show you how to integrate the customized tokenizer into the pretrained LLM as well as how to start a continual pretraining task in NVIDIA NeMo.
Preparation
Please import the following libraries before starting:
import torch
from nemo.collections.nlp.models.language_modeling.megatron_gpt_model import MegatronGPTModel
from nemo.collections.nlp.parts.megatron_trainer_builder import MegatronTrainerBuilder
from omegaconf import OmegaConf
Model modification
After merging, the vocabulary size of the combined tokenizer is larger than that of the GPT-megatron-1.3B model pretrained tokenizer. This means that you must extend the embedding layer of the GPT-megatron-1.3B model to accommodate the combined tokenizer (Figure 2).

The key steps involve the following:
- Creating a new embedding layer with the desired increased vocabulary size.
- Initializing it by copying the existing weights from the original embedding layer.
- Setting the new vocabulary entries to zero weights.
This expanded embedding layer then replaces the original layer in the pretrained model, enabling it to handle the additional tokens in the new language while retaining the knowledge learned during the initial pretraining process.
Load and extract the embedding layer
Run the following code to load the GPT-megatron-1.3B.nemo model:
#Initialization
trainer_config = OmegaConf.load('/opt/NeMo/examples/nlp/language_modeling/conf/megatron_gpt_config.yaml')
trainer_config.trainer.accelerator='gpu' if torch.cuda.is_available() else 'cpu'
trainer = MegatronTrainerBuilder(trainer_config).create_trainer()
#load gpt-megatron-1.3b.nemo and its config
nemo_model = MegatronGPTModel.restore_from('./path_to_1.3B_nemo_model',trainer=trainer)
nemo_config = OmegaConf.load('./path_to_1.3B_nemo_model_config.yaml')
After loading the model, you can extract the weight of the embedding layer from the model state_dict parameter. The embedding layer is used to generate the new embedding layer.
#Extract original embedding layer
embed_weight = nemo_model.state_dict()[f'model.language_model.embedding.word_embeddings.weight']
print(f"Shape of original embedding layer: {embed_weight.shape}")
Generate new embedding layer
Now you must calculate the dimension difference between your new embedding layer and the original embedding layer. You create a tensor based on this difference and concatenate it to the original embedding layer to form the new embedding layer.
The difference is calculated based on the following:
- Combined tokenizer vocabulary size
- Original embedding layer length
- A parameter in
model_config.yaml,model.make_vocab_size_divisible_by
Here’s the equation for the difference:
\(Diff = [\frac{N}{X}] \times X-O\)
- Combined tokenizer vocabulary size = \(N\)
- Original NeMo embedding layer length = \(O\)
- model.make_vocab_size_divisible_by = \(X\)
The mechanism is that to maximize the computation efficiency, you pad the embedding layer to a number divisible by multiples of 8. Given a tokenizer vocabulary size, the model is expected to have a padded embedding layer.
This process should be automatic if you are training from scratch, but in this case, you must manually pad the new embedding layer.
tokenizer = AutoTokenizer.from_pretrained('./path_to_new_merged_tokenizer')
if len(tokenizer)% nemo_config.make_vocab_size_divisible_by != 0:
tokenizer_diff = (int(len(tokenizer)/nemo_config.make_vocab_size_divisible_by)+1) * nemo_config.make_vocab_size_divisible_by - embed_weight.shape[0]
else:
tokenizer_diff = tokenizer.vocab_size - embed_weight.shape[0]
Now you can generate the additional tensor as initial weights for new tokens. This tensor is then concatenated to the original embedding layer extracted previously to form the new embedding layer.
hidden_size = embed_weight.shape[1]
random_embed = torch.zeros((tokenizer_diff, hidden_size)).to('cuda')
new_embed_weight = torch.cat((embed_weight, random_embed), dim=0)
Modify and output new model
In this step, you modify the tokenizer-related settings in the model configuration to align with the new vocabulary. Recall that the shape of the new embedding is different from the original embedding layer. You will encounter a layer size mismatching error if you directly replace the embedding layer in the original model.
Load an empty model instance with the updated tokenizer configuration and assign it the state_dict value from the pretrained model, along with the new embedding layer.
Finally, save this modified model in the .nemo format, ready for continual pretraining on the expanded vocabulary.
state_dict = nemo_model.state_dict()
state_dict[f'model.language_model.embedding.word_embeddings.weight'] = new_embed_weight
NEW_TOKENIZER_PATH = './path_to_new_merged_tokenizer'
nemo_config['tokenizer']['vocab_file'] = f"{NEW_TOKENIZER_PATH}/vocab.json"
nemo_config['tokenizer']['merge_file'] = f"{NEW_TOKENIZER_PATH}/merges.txt"
nemo_config['vocab_file'] = f"{NEW_TOKENIZER_PATH}/vocab.json"
nemo_config['merges_file'] = f"{NEW_TOKENIZER_PATH}/merges.txt"
new_nemo_model = MegatronGPTModel(nemo_config,trainer)
new_nemo_model.load_state_dict(state_dict)
new_nemo_model.save_to('./path_to_modified_nemo_model')
Run the following code to examine if the new model is performing well on an English prompt:
python /opt/NeMo/examples/nlp/language_modeling/megatron_gpt_eval.py \ gpt_model_file='./path_to_modified_nemo_model' \
prompts='ENTER YOUR PROMPT' \
inference.greedy=True \
inference.add_BOS=True \
trainer.devices=1 \
trainer.num_nodes=1 \
tensor_model_parallel_size=-1 \
pipeline_model_parallel_size=-1
Data preprocessing
Run the data preprocessing script repeatedly for the training, validation, and test dataset. For more information, see Step 3: Split the data into train, validation and test.
Replace the --json_key value with the key that contains the document text in your dataset:
python /opt/NeMo/scripts/nlp_language_modeling/preprocess_data_for_megatron.py \ --input='./path_to_train/val/test_dataset' \
--json-keys=text \
--tokenizer-library=megatron \
--vocab './path_to_merged_tokenizer_vocab_file'\
--dataset-impl mmap \
--tokenizer-type GPT2BPETokenizer \
--merge-file './path_to_merged_tokenizer_merge_file' \
--append-eod \
--output-prefix='./path_to_output_preprocessed_dataset'
Continual pretraining
The default config file for continual pretraining might have a different model configuration as compared to your model. Run the following code to overwrite those configurations. Update the tokenizer and data prefix parameters accordingly as well.
ori_conf = OmegaConf.load('./path_to_original_GPT-1.3B_model/model_config.yaml')
conf = OmegaConf.load('/opt/NeMo/examples/nlp/language_modeling/conf/megatron_gpt_config.yaml')
for key in ori_conf.keys():
conf['model'][key] = ori_conf[key]
# Set global_batch_size based on micro_batch_size
conf['model']["global_batch_size"] = conf['model']["micro_batch_size"] * conf.get('data_model_parallel_size',1) * conf.get('gradient_accumulation_steps',1)
# Reset data_prefix (dataset path)
conf['model']['data']['data_prefix'] = '???'
# Reset tokenizer config
NEW_TOKENIZER_PATH = "./path_to_new_merged_tokenizer"
conf['model']['tokenizer']['vocab_file'] = f"{NEW_TOKENIZER_PATH}/vocab.json"
conf['model']['tokenizer']['merge_file'] = f"{NEW_TOKENIZER_PATH}/merges.txt"
conf['model']['vocab_file'] = f"{NEW_TOKENIZER_PATH}/vocab.json"
conf['model']['merges_file'] = f"{NEW_TOKENIZER_PATH}/merges.txt"
OmegaConf.save(config=conf,f='/opt/NeMo/examples/nlp/language_modeling/conf/megatron_gpt_config.yaml')
Run the following code to start continual pretraining. The following parameters should be modified based on your specific hardware and setup:
nproc_per_node: Number of GPUs per node.model.data.data_prefix: Path to your training, validation, and test dataset. For format, see the code example.exp_manager.name: Output folder name. Intermediate checkpoints are saved in the./nemo_experiments/<exp_manager.name>folder.trainer.devices: Number of GPUs per node.trainer.num_nodes: Number of nodes.trainer.val_check_interval: Frequency (in steps) for performing validation checks during training.trainer.max_steps: Maximum step for training steps.model.tensor_model_parallel_size: For the 1.3B model, keep to1. Use a larger size for larger models.model.pipeline_model_parallel_size: For the 1.3B model, keep to1. Use a larger size for larger models.model.micro_batch_size: Change depending on the GPU vRAM.model.global_batch_size: Depends on themicro_batch_sizevalue. For more information, see Batching.
DATA = '{train:[1.0,training_data_indexed/train_text_document], validation:[training_data_indexed/val_text_document], test:[training_data_indexed/test_text_document]}'
!torchrun --nproc_per_node=1 \ /opt/NeMo/examples/nlp/language_modeling/megatron_gpt_continue_training.py \
"model.data.data_prefix={DATA}"\
name=megatron_gpt_ \
exp_manager.name=megatron_gpt_1 \
restore_from_path='./path_to_modified_nemo_model' \
trainer.devices=1 \
trainer.num_nodes=1 \
trainer.precision=16 \
trainer.val_check_interval=300 \
trainer.max_steps=1200 \
model.megatron_amp_O2=False \
model.tensor_model_parallel_size=1 \
model.pipeline_model_parallel_size=1 \
model.micro_batch_size=1 \
model.global_batch_size=1 \
++model.use_flash_attention=False \
++model.seq_len_interpolation_factor=null
Model inference
During training, the intermediate files are generated and stored in the ./nemo_experiments folder. You should find the desired model checkpoint files and hparams.yaml in this folder
Use the following code to inference using checkpoint files:
python /opt/NeMo/examples/nlp/language_modeling/megatron_gpt_eval.py \
'checkpoint_dir="./path_to_checkpoint_folder"' \
'checkpoint_name="name of checkpoint file in .ckpt format"' \
'hparams_file="./path_to_hparams_file"' \
prompts='ENTER YOUR PROMPT' \
inference.greedy=True \
inference.add_BOS=True \
trainer.devices=1 \
trainer.num_nodes=1 \
tensor_model_parallel_size=-1 \
pipeline_model_parallel_size=-1
Table 1 is a comparison of sentence output generated by the original GPT-megatron-1.3B model and GPT-megartron-1.3B model trained using Thai Wikipedia data. For this post, some repeated output tokens are truncated.
| Prompt | Output of GPT-megatron-1.3B.nemo | Output of Trained GPT-megatron-1.3B-TH.nemo |
| The capital city of Thailand is | The capital city of Thailand is from the capital city of Bangkok. The capital city of Thailand is from the capital city of Bangkok.\n\nHistory\n\nThe capital city of Thailand was originally called Chiang Mai, which means “city of the sun”. The capital city of Thailand was originally called Chiang Mai, which means “city of the sun”. | The capital city of Thailand is by the Thai Government of Thailand\n\nแหล่งข้อมูลอื่น \n\nเมืองในจังหวัดเชียงราย\nเมืองโบราณในประเทศไทย\n(The Capital city of Thailand is by the Thai Government of Thailand\n\nOther sources \n\nCities in Chiang Rai Province\nAncient cities in Thailand\n) |
| กรุงเทพมหานครเป็นสถานที่ท่องเที่ยวยอดนิยม สถานที่ท่องเที่ยวที่มีชื่อเสียงที่สุดคือ (Bangkok is a popular tourist destination. The most famous tourist attractions are ) | กรุงเทพมหานครเป็นสถานที่ท่องเที่ยวยอดนิยม สถานที่ท่องเที่ยวที่มีชื่อเสียงที่สุดคือการทำงานที่สุดท (Bangkok is a popular tourist destination. The most famous tourist attraction is the most famous working place.) | กรุงเทพมหานครเป็นสถานที่ท่องเที่ยวยอดนิยม สถานที่ท่องเที่ยวที่มีชื่อเสียงที่สุดคือ “วัดธรรมาธิปไตย” ซึ่งเป็นวัดที่พระบาทสมเด็จพระจุลจอมเกล้าเจ้าอยู่หัว (Bangkok is a popular tourist destination. The most famous tourist attractions are: “Wat Thammathipatai” which is the temple that King Chulalongkorn built.) |
After training, the model has improved its understanding of Thai, although its performance in English has degraded. This is due to model forgetting caused by continual pretraining using a monolingual dataset. To avoid this, we recommend training with a corpus containing both English and the target language.
Conclusion
By following this workflow, you can effectively extend the language support of foundation LLMs, enabling them to understand and generate content in multiple languages. This approach uses existing knowledge and representations learned during the initial pretraining, while enabling the model to adapt and acquire new language skills through continual learning.
The success of this process does depend on the quality and quantity of the target language data used for tokenizer training and continual pretraining. A careful training curriculum and training strategies are also necessary to ensure optimal performance, especially to mitigate catastrophic forgetting.
To get started, download the NeMo framework container or download and set up the /NVIDIA/NeMo open-source library on GitHub. You can use your own curated dataset on low-resourced languages and follow the steps in this post to add desired new language support on foundation LLMs.
As part of the NeMo microservices early access program, you can also request access to the NVIDIA NeMo Curator and NVIDIA NeMo Customizer microservices. Together, these microservices simplify the data curation and customization of LLMs and enable you to bring solutions to market faster.
