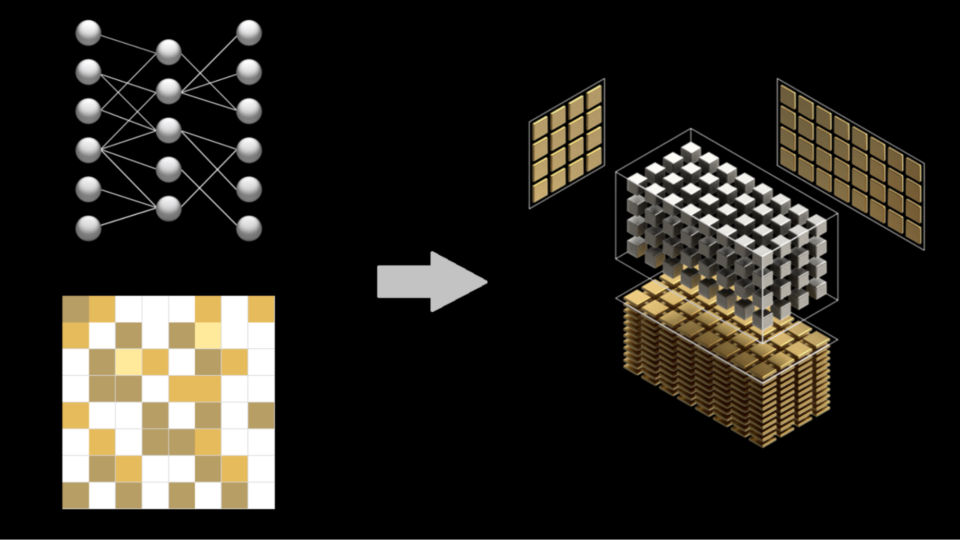
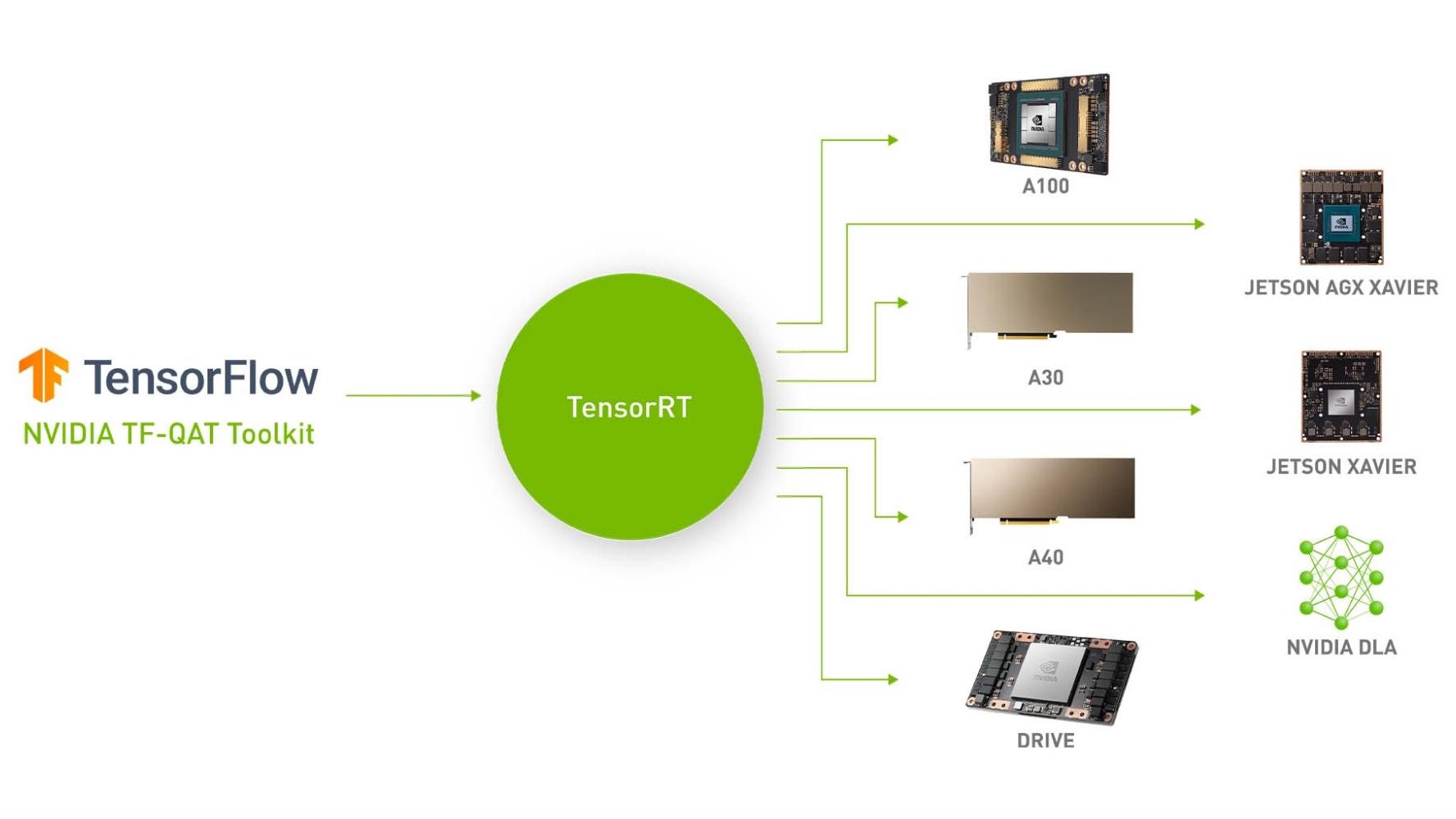
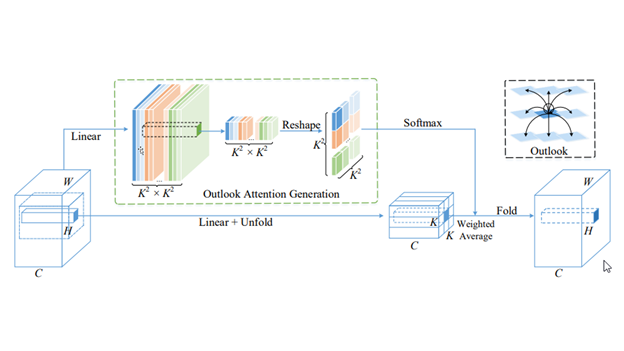
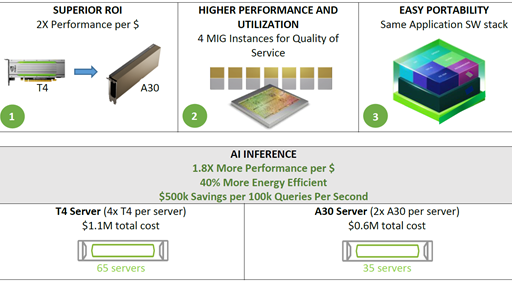
Sep 08, 2021
Register for the NVIDIA Metropolis Developer Webinars on Sept. 22
Join NVIDIA experts and Metropolis partners on Sept. 22 for webinars exploring developer SDKs, GPUs, go-to-market opportunities, and more. All three sessions,...
2 MIN READ