
Lowering response times to new market events is a driving force in algorithmic trading. Latency-sensitive trading firms keep up with the ever-increasing pace of financial electronic markets by deploying low-level hardware devices like Field Programmable Gate Arrays (FPGAs) and Application Specific Integrated Circuits (ASICs) into their systems.
However, as markets become increasingly efficient, traders need to rely on more powerful models like deep neural networks (DNNs) to improve their profitability. Since the implementation of such complex models on low-level hardware devices requires substantial investments, general purpose GPUs present a viable, cost-effective alternative to FPGAs and ASICs.
NVIDIA has demonstrated in the STAC-ML inference benchmark, audited by STAC,1 that the NVIDIA A100 Tensor Core GPU can run LSTM model inference consistently with low latencies. This shows that GPUs can replace or complement less versatile low-level hardware devices in modern trading environments.
STAC-ML inference benchmark results
Deep neural networks with long short-term memory (LSTM) are an established tool for time series forecasting. They are also applied in modern finance. The STAC-ML inference benchmark is designed to measure the latency of LSTM model inference. This is defined as the time from receiving new input information until the model output is computed.
The benchmark defines the following three LSTM models of varying complexity: LSTM_A, LSTM_B, and LSTM_C. Each model has a unique combination of features, timesteps, layers, and units per layer. LSTM_B is roughly 6x greater than LSTM_A, and LSTM_C is roughly two orders of magnitude greater.
There are two separate benchmark suites: Tacana and Sumaco. Tacana is for inference performed on a sliding window, where a new timestep is added and the oldest removed for each inference operation. In Sumaco, each inference is performed on an entirely new set of data.
Low-latency optimized results for the Tacana Suite
NVIDIA demonstrated the following latencies (99th percentile) on a Supermicro Ultra SuperServer SYS-620U-TNR with a single NVIDIA A100 80 GB PCIe Tensor Core GPU in FP32 precision (SUT ID NVDA221118b):
- LSTM_A: 35.2 microseconds2
- LSTM_B: 68.5 microseconds3
- LSTM_C: 640 microseconds4
The numbers above are for running inference on one model instance. It is also possible to deploy ensembles of independent model instances on a single GPU. For 16 independent model instances, the corresponding latencies are:
- LSTM_A: 54.1 microseconds5
- LSTM_B: 140 microseconds6
- LSTM_C: 748 microseconds7
Moreover, there were no large outliers in latency. The maximum latency was no more than 2.3x the median latency across all LSTMs,8 even when the number of concurrent model instances was increased to 32. Having such predictable performance is crucial for low-latency environments in finance, where extreme outliers may result in substantial losses during fast market moves.
NVIDIA is the first vendor to submit numbers for the Tacana Suite of the benchmark. In contrast to the Sumaco Suite, the Tacana benchmark allows for sliding window optimizations, which facilitate exploiting the stream-like nature of time series data. Previous submissions for the Sumaco Suite of the STAC ML benchmark claimed latency figures within the same order of magnitude.
High-throughput optimized results for the Sumaco Suite
NVIDIA also submitted a throughput-optimized configuration on the same hardware for the Sumaco Suite in FP16 precision (NVDA221118a):
- LSTM_A: 1.629 to 1.707 M9 inferences per second at a power consumption of 949 watts
- LSTM_B: exceeded190 K10 inferences per second at a power consumption of 927 watts
- LSTM_C: 12.8 K11 inferences per second at a power consumption of 722 watts
These figures confirm that NVIDIA GPUs are unrivaled in terms of throughput and energy efficiency for workloads like backtesting and simulation.
Impact on automated trading
Why do microseconds—a time span in which light can only travel 300 meters—even matter in automated trading? Mature electronic markets disseminate new information at high speed. Trading applications that rely on complex neural networks like LSTMs run the risk that model inference takes too long.
To place our inference latencies in a high frequency trading context, we analyzed the time intervals between market trades in one of the most actively traded financial contracts in Europe: the EURO STOXX 50 Index Futures (FESX).12
The High Precision Timestamp (HPT) dataset comprises nanosecond tick data corresponding to trades on new price levels during the month of October 2022. We counted how often the time difference between two consecutive trades was less than the latencies reported in the Tacana Suite results (see above). The resulting estimates on the frequency of events queuing up in the inference engine were as follows:
- LSTM_A: 0.14% occurrences
- LSTM_B: 0.58% occurrences
- LSTM_C: 8.52% occurrences
As shown, NVIDIA GPUs enable electronic trading applications to run inference in real time on very large LSTM models serving some of today’s fastest-moving markets. A model as complex as LSTM_B achieves an extraordinarily low queuing frequency of 0.58%. And even for the most complex model, LSTM_C, with a queuing frequency of 8.52%, the NVIDIA submission delivers a state-of-the-art inference latency below 1 millisecond.
Advantages of NVIDIA GPUs for electronic trading
NVIDIA GPUs provide numerous benefits that help to lower the total cost of ownership of an electronic trading stack, as detailed below.
Training and deployment platform
Regardless of whether you need to develop, backtest, or deploy an AI model, NVIDIA GPUs deliver world-class performance without forcing developers to learn different programming languages and programming models for research and trading. All NVIDIA GPUs speak CUDA and therefore can be programmed in the same way, regardless of whether you are using the respective device in a development workstation or a data center.
In addition, NVIDIA Nsight tools consist of a collection of powerful developer resources to debug and profile applications, improving their performance. In many cases, it is not even necessary to learn CUDA. Modern machine learning frameworks like PyTorch expose performance-relevant features of CUDA such as CUDA Graphs and CUDA streams and offer sophisticated profiling capabilities.
Performance improvements
NVIDIA is continuously improving the performance of its core libraries such as cuBLAS for accelerating basic linear algebra subroutines, CUTLASS for high-performance matrix-multiplications (GEMMs), or cuDNN for accelerating deep neural network primitives. All these libraries facilitate flexible performance tuning or even provide autotuning capabilities to select the best primitives for a given combination of GPU and application. For this reason, a stack for AI applications based on NVIDIA GPUs becomes even faster throughout its lifetime (Figure 1).
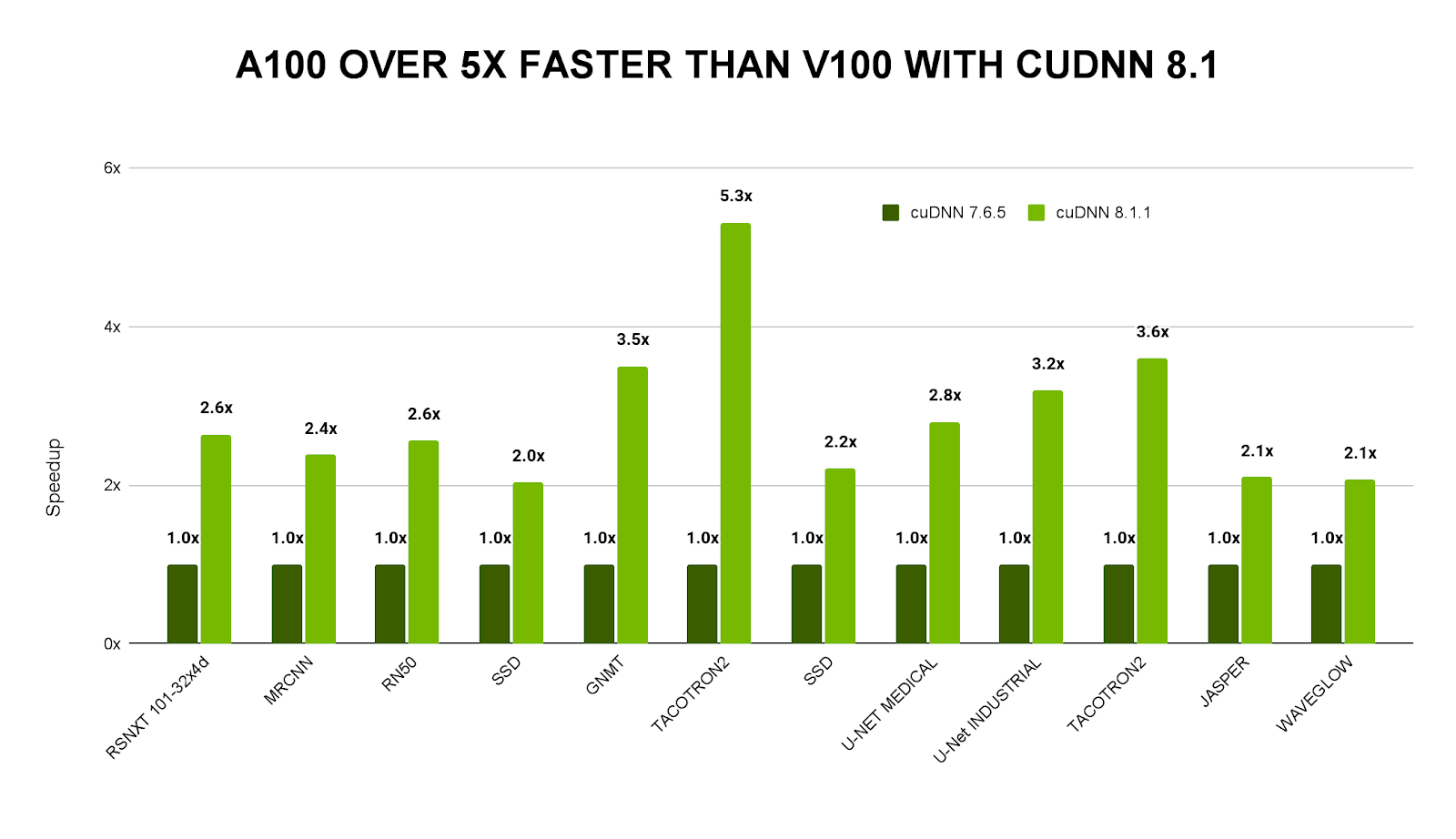
High compute density
Efficient use of space in data centers is essential. With even a single NVIDIA A100 Tensor Core GPU installed in a server, it is possible to achieve the following space efficiency numbers:
- LSTM_A: 666,621 to 694,874 inferences per second per cubic feet13
- LSTM_B: 77,714 to 77,801 inferences per second per cubic feet14
- LSTM_C: 5,212 inferences per second per cubic feet15
Note that these numbers are taken from the report on the throughput optimized configuration (SUT ID NVDA221118a), not the latency-optimized. The Supermicro server is NVIDIA-certified for up to four NVIDIA A100 GPUs, which would increase the compute density accordingly.
Large ecosystem and developer community
NVIDIA GPUs support many deep learning frameworks, such as PyTorch, TensorFlow, or mxNet, which are used by data scientists and quantitative researchers worldwide. To ease the pain of dependency management, all frameworks are shipped as container images comprising the latest version of our libraries. This lowers the burden of setting up development environments and ensures reproducibility of results. These container images can be obtained easily through NVIDIA NGC, which offers fully-managed cloud services as well as a catalog of GPU-optimized AI software and pretrained models (Figure 2).
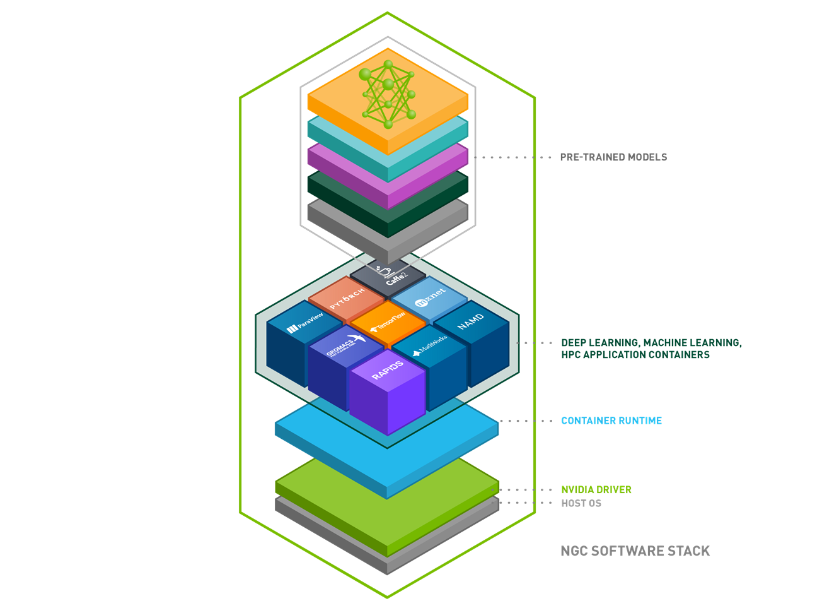
Summary
The results achieved in the STAC-ML inference benchmark demonstrate the added value of GPUs in low-latency environments, both standalone and complementary. With quant research and trading development being conducted on the same platform, the time to production can be significantly reduced. A single hardware target lifts the burden of having to maintain several implementations for distinct platforms. This paradigm shift—the consolidation of the development stack between research and trading—is a unique advantage of the NVIDIA accelerated computing platform.
References
- ‘STAC’ and all STAC names are trademarks or registered trademarks of the Securities Technology Analysis Center, LLC
- STAC-ML.Markets.Inf.T.LSTM_A.1.LAT.v1
- STAC-ML.Markets.Inf.T.LSTM_B.1.LAT.v1
- STAC-ML.Markets.Inf.T.LSTM_C.1.LAT.v1
- STAC-ML.Markets.Inf.T.LSTM_A.16.LAT.v1
- STAC-ML.Markets.Inf.T.LSTM_B.16.LAT.v1
- STAC-ML.Markets.Inf.T.LSTM_C.16.LAT.v1
- STAC-ML.Markets.Inf.T.LSTM_A.2.LAT.v1
- STAC-ML.Markets.Inf.S.LSTM_A.[1,2,4].TPUT.v1
- STAC-ML.Markets.Inf.S.LSTM_B.[1,2,4].TPUT.v1
- STAC-ML.Markets.Inf.S.LSTM_C.[1,2,4].TPUT.v1
- Data courtesy of Deutsche Börse
- STAC-ML.Markets.Inf.S.LSTM_A.[1,2,4].SPACE_EFF.v1
- STAC-ML.Markets.Inf.S.LSTM_B.[1,2,4].SPACE_EFF.v1
- STAC-ML.Markets.Inf.S.LSTM_C.[1,2,4].SPACE_EFF.v1
