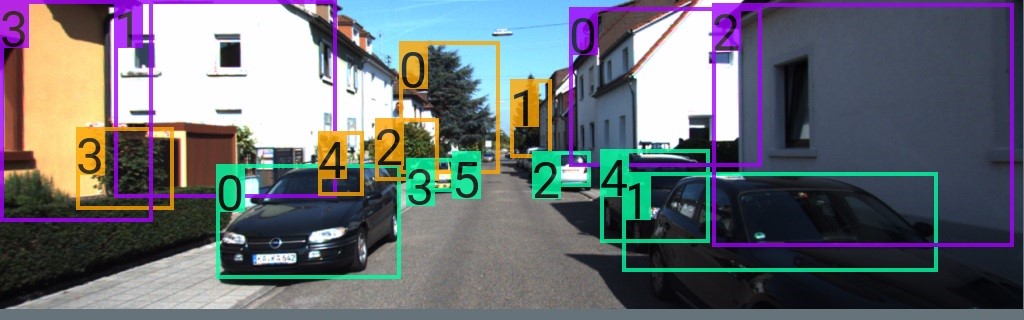
Scene graphs (SGs) in both computer vision and computer graphics are an interpretable and structural representation of scenes. A scene graph summarizes entities in the scene and plausible relationships among them. SGs have applications in the fields of computer vision, robotics, autonomous vehicles, and so on.
Current SG-generation techniques rely on the limited availability of expensive labeled datasets. Synthetic data is a viable alternative to this problem, as annotations are essentially free. Although synthetic data has been used for a variety of tasks such as image classification, object detection, and semantic segmentation, the use of synthetic data for SG generation and visual relationships is yet to be explored. The crucial issue is that training neural network models on labelled synthetic data and evaluating on unlabeled real data leads to the domain gap problem, because the synthetic and real data differ in both appearance and content.
Sim2SG framework
To overcome these challenges, we propose Sim2SG, a scalable technique for sim-to-real transfer for scene-graph generation. The primary goal of this research is to enable scene-graph generation from real-world images by first training a neural network on a simulated dataset that contains labelled SG information and then transferring the learned model onto a real-world dataset.
During the training process, Sim2SG addresses the domain gap and learns to generate scene graphs. The domain gap can be subdivided into the following gaps:
- Appearance gap is the discrepancy in the appearance of the two domains, such as differences in texture, color, light, or reflectance of objects in the scene.
- Content gap refers to discrepancies between the two domains, including the difference in distribution of the number of objects and their class, placement, pose, and scale.
We analyze the content gap further and address its subcomponents – label and prediction discrepancies. Figure 1 showed Sim2SG generating accurate scene graphs for a real-world driving dataset and Figure 2 shows the entire pipeline.
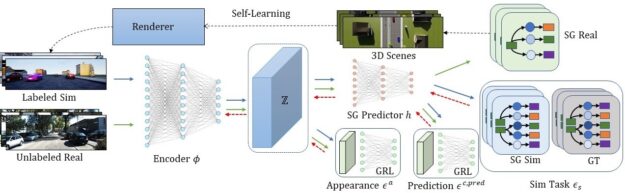
In Figure 2, the Sim2SG pipeline takes labelled synthetic data from the source domain and unlabeled real data from the target domain as input. The labeled synthetic and unlabeled real data are mapped to a shared representation, Z, using an encoder. We then train the scene graph prediction network, h, on Z using synthetic data. We handle the label discrepancy by using pseudo-statistic–based self-learning to generate label-aligned synthetic data for training. We further align both the prediction discrepancies as well as appearance discrepancies between the two domains using adversarial techniques using gradient reversal layer (GRL) and domain discriminator.
Quantitative evaluation
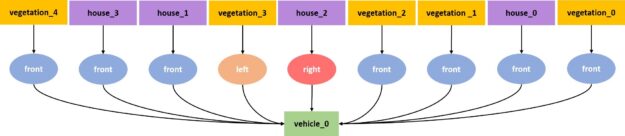
We used four classes—car, pedestrian, vegetation, and house—and four types of relationships—front, left, right, and behind. All relationships have the car as the subject.
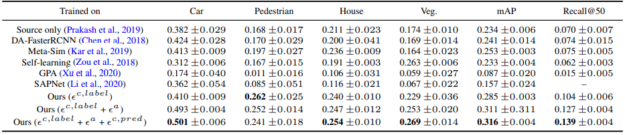
Table 1 shows how label alignment and appearance alignment in the proposed method drastically reduce the domain gap compared to the baselines. We compared Sim2SG to the randomization-based method (Prakash et al., 2019), the method addressing content gap (Kar et al., 2019), self-learning based on pseudo labels (Zou et al., 2018) and domain adaptation methods for object detection (Chen et al., 2018; Xu et al., 2020; Li et al., 2020). The domain gap reduces further by combining label, appearance, and prediction alignment (final row).
Qualitative evaluation
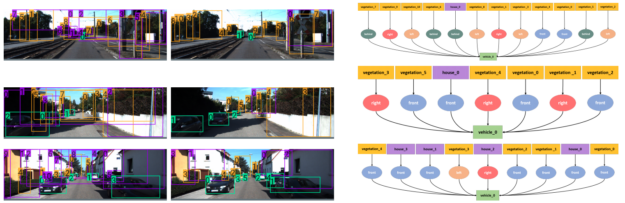
Figure 3 shows the qualitative results of Sim2SG on the target domain. The first column shows that the source-only baseline fails to either detect objects or has a high number of false positives (mislabels), leading to poor scene graphs. Our method detects objects better, has fewer false positives, and ultimately generates more accurate scene graphs, as shown in the second and third column, respectively. This is because the appearance alignment term reduces false positive detections. Also, the label alignment term improves detection performance as it helps generate synthetic data for training that is more label aligned regarding target domain. Figure 4 shows some label-aligned, synthetic reconstructions corresponding to target domain samples.

Summary
In this work, we propose Sim2SG, a model that achieves sim-to-real transfer learning for scene graph generation on unlabeled real-world datasets. We decompose the domain gap into label, prediction, and appearance discrepancies between synthetic and real domains. We propose methods to address these discrepancies and achieve significant improvements over baselines in all three environments: Clevr, Dining-Sim, and Drive-Sim.
For more information, see the following resources:
