
Currently, one of the most compelling questions in AI is whether large language models (LLMs) can continue to improve through sustained reinforcement learning (RL), or if their capabilities will eventually plateau.
Developed by NVIDIA Research, ProRL v2 is the latest evolution of Prolonged Reinforcement Learning (ProRL), specifically designed to test the effects of extended RL training on LLMs. Leveraging advanced algorithms, rigorous regularization, and comprehensive domain coverage, ProRL v2 pushes the boundaries well beyond typical RL training schedules. Our experiments systematically explore whether models can achieve measurable progress when subjected to thousands of additional RL steps.
Today, we’re excited to announce the release of ProRL v2. This post explains key innovations and advanced methods, and shares new empirical results of ProRL v2 that achieve state-of-the-art performance, shedding light on how LLMs can continue to learn and improve.
How does ProRL v2 enable RL scaling?
Chain-of-thought prompting, tree search, and other AI techniques help models better exploit knowledge they already possess. RL, especially with rigorous, programmatically-verifiable rewards, holds the promise to push models into genuinely new territory. However, traditional short-horizon RL techniques often suffer from instability and quickly diminishing returns, earning a reputation as “temperature distillation” rather than a true enabler of boundary expansion.
ProRL fundamentally challenges this paradigm. It provides:
- Extended training: Over 3,000 RL steps across five distinct domains achieve new state‑of‑the‑art performance among 1.5B reasoning models.
- Stability and robustness: Incorporates KL-regularized trust regions, periodic reference policy resets, and scheduled length regularization.
- Fully verifiable rewards: Every reward signal is determined programmatically and is always checkable.
- Brevity enforced: Scheduled cosine length penalties ensure outputs remain concise and efficient.
The goal is to move beyond resampling familiar solutions, to genuinely expanding what the model can discover.
| Conventional RL fine-tuning | ProRL v2 |
| Few-hundred steps, one domain | 3,000+ steps, five domains |
| Entropy collapse, KL spikes | PPO-Clip, REINFORCE++-baseline, Clip-Higher, Dynamic Sampling, reference resets |
| Risky reward model drift | Fully verifiable rewards |
| Verbose, lengthy outputs | Scheduled cosine length penalty |
Core techniques: ProRL algorithms and regularizers
ProRL v2 builds on the REINFORCE++ baseline, which employs local mean and global batch advantage normalization to enhance RLVR training stability, and additionally incorporates methods such as Clip-Higher to encourage exploration and Dynamic Sampling to reduce noise and improve learning efficiency. We introduce several innovations, including:
- Scheduled cosine length penalties for producing concise outputs
- KL-regularized trust regions with periodic reference resets to the current best checkpoint to help prevent overfitting and ensure stability
Proximal policy optimization with REINFORCE++ baseline
At the core of ProRL is clipped proximal policy optimization (PPO-Clip) loss, which stabilizes policy updates by restricting how much the new policy can diverge from the old ones:
\(\mathcal{L}_{\text{PPO}}(\theta) = \mathbb{E}_{\tau}\left[ \min\left( r_{\theta}(\tau) A(\tau), \ \text{clip}\left(r_{\theta}(\tau), 1 – \varepsilon_{\text{low}}, 1 + \varepsilon_{\text{high}}\right) A(\tau) \right) \right]\)
Where:
- \(r_\theta(\tau) = \frac{\pi_\theta(\tau)}{\pi_{\text{old}}(\tau)}\)
- \(\tilde{R}_\tau = R_\tau – \mu_{\text{group}}\)
- \(\mu_{\text{group}} = \text{mean}_{\text{group}}(R_\tau)\)
- \(A(\tau) = \frac{\tilde{R}\tau – \mu_{\text{batch}}}{\sigma_{\text{batch}}}\)
- \(\mu_{\text{batch}} = \text{mean}_{\text{batch}}(\tilde{R}_\tau)\)
- \(\sigma_{\text{batch}} = \text{std}_{\text{batch}}(\tilde{R}_\tau)\)
And group refers to all generated responses for the same prompt (group normalization).
Global Batch Normalization in the REINFORCE++ baseline helps prevent value instability caused by small group sizes. It first subtracts the mean reward of the small group to reshape the rewards. Therefore, the algorithm is not insensitive to reward patterns such as 0 (incorrect) / 1 (correct) / -0.5 (format reward) or -1 (incorrect) / 1 (correct) / -0.5 (format reward). Then it applies global batch normalization.
Clip bounds:
\(\varepsilon_{\text{low}} = 0.20 \qquad \varepsilon_{\text{high}} = 0.28\)
Clip-Higher and Dynamic Sampling
Clip-Higher uses a higher upper bound of the PPO clipping range to mitigate policy entropy collapse and promote sampling diversity (\(\varepsilon_{\text{high}} > \varepsilon_{\text{low}}\)).
Dynamic Sampling discards prompts with group responses with all 1 (fully correct) or 0 (fully incorrect) rewards to reduce noise in gradient estimates.
Scheduled cosine length penalty
To promote concise, token-efficient outputs, a scheduled cosine length penalty is applied:
\(\text{length\_reward}(t) = \eta_{\min} + 0.5 \times (\eta_{\max} – \eta_{\min}) \times [ 1 + \cos ( \pi t / T ) ]\)
Where:
- \(t\) = current output length (tokens)
- \(T\) = context token limit
- \(\eta_\text{min}\), \(\eta_\text{max}\) = reward/penalty boundaries
Reward update:
\(R’_\tau = R_{\text{correct}} + \lambda_{\text{len}} \cdot \eta_{\text{len}}(t)\)
The penalty cycles on and off at regular intervals (for example, 100 updates on, 500 off) to balance informativeness and conciseness.
KL regularization and reference policy resets
A KL penalty keeps the policy close to a reference. Periodic resets help prevent overfitting and ensure stability:
\(\mathcal{L}_\mathrm{KL\text{-}RL} = \mathcal{L}_\mathrm{PPO} – \beta\, D_\mathrm{KL}(\pi_\theta\ \|\ \pi_\mathrm{ref})\)
KL divergence in REINFORCE++ baseline is regularized using a \(k_2\) estimator:
\(\mathcal{L}_{k_{2}} = \mathbb{E}_{s \sim D,\ a \sim \pi_{\theta_{\text{old}}}(\cdot|s)} \left( \frac{1}{2} ( -\log x )^2 \right)\)
With:
\(x = \exp \left( \mathrm{clamp}\left( \log \frac{\pi_{\text{ref}}(a_t \mid s_t)}{\pi_{\theta_{\text{old}}}(a_t \mid s_t)}, -10, 10 \right) \right)\)
Here, the function \(\mathrm{clamp}(z, -10, 10)\) limits \(z\) to the range \([-10, 10]\) to improve the value stability.
Reference resets
Every 200–500 RL steps (or upon KL spikes/stalled validation), the reference policy \(\pi_\mathrm{ref}\) is reset to the current policy, optimizer state is not cleared.
By regularly resetting the reference policy, the model avoids being constrained by outdated guidance, allowing it to continue learning effectively.
The scheduled cosine length penalty, applied periodically, also plays an important role. By cycling the penalty on and off, the model avoids becoming trapped in short or fixed context lengths, enabling it to improve both the accuracy and token efficiency of its outputs. Together, these two strategies prevent the model from being limited by either the reference policy or context length, supporting continuous improvements in accuracy and overall performance over time.
What was discovered about scaling RL for LLMs?
We discovered new state-of-the-art performance, sustained improvement, novel solutions, and boundary breakthroughs.
- New state-of-the-art performance: Performance continually improves with more RL training steps, ProRL v2 3K sets a new record for 1.5B reasoning models.
- Sustained, non-trivial improvement: Both Pass@1 and pass@k metrics climb over thousands of RL steps, expanding the base model’s reasoning boundary.
- Creative and novel solutions: ProRL outputs show reduced n-gram overlap with pretraining data, indicating true innovation rather than rote memorization.
- Boundary breakthroughs: On tasks where base models always failed, ProRL not only achieves strong pass rates, but also demonstrates robust out-of-distribution generalization.
ProRL comprehensive results
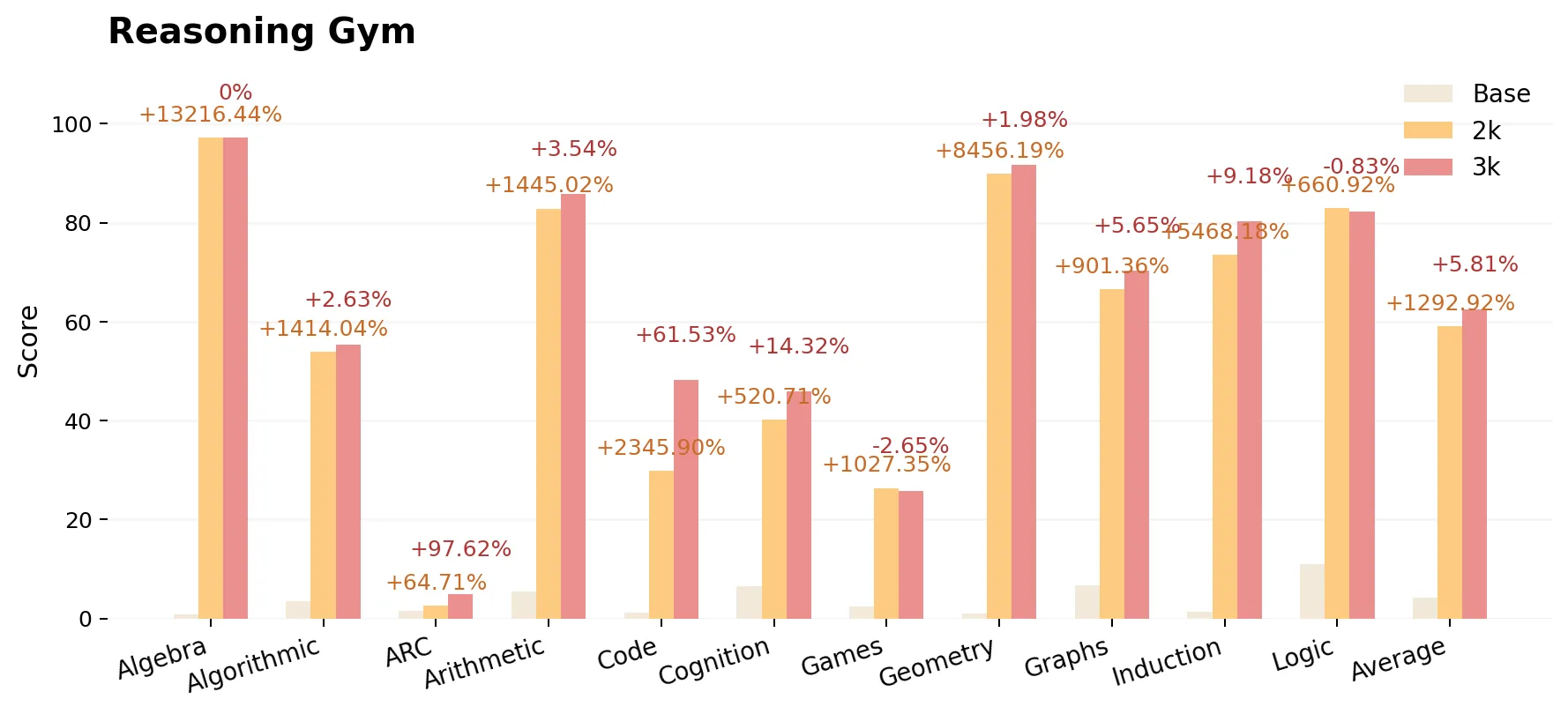
ProRL was evaluated across math, code generation, and diverse reasoning gym benchmarks. Scores are reported for:
- Base: DeepSeek-R1-Distill-Qwen-1.5B
- ProRL v1 2K: 2,000 RL steps (trained with 16K context)
- ProRL v2 3K: 3,000 RL steps (trained with 8K context)
As of the time of writing, the model is still undergoing continuous training and accuracy improvements. The figures below illustrate the performance gains of the 2K-step model over the base model and of the 3K-step model over the 2K-step model. Even with the training context length cut in half (16K to 8K)—greatly reducing computational cost—overall model accuracy improves across the tasks.



Conclusion
Our empirical results indicate that LLMs can achieve sustained improvements in math, code, and reasoning tasks through prolonged RL, surpassing the performance typically observed with conventional training routines. Our evaluation demonstrates robust gains across a wide array of benchmarks—including challenging and out-of-distribution tasks—suggesting that extended RL training can meaningfully expand a model’s reasoning capabilities.
- New state-of-the-art 1.5B reasoning model, ProRL v2 3K significantly outperforms its base model, DeepSeek-R1-1.5B, and surpasses the previous state-of-the-art performance achieved by ProRL v1 2K.
- ProRL delivers sustained, reliable improvements across math, code, and reasoning—particularly in domains where base models (even with aggressive sampling) fail outright.
- More compute and more parameters: Pushing RL steps further—rather than just scaling up model size—drives substantially more boundary expansion.
- Gains are robust: Improvements are not isolated flukes; nearly every subtask benefits from continued RL.
For practitioners aiming to push the boundaries of model performance or explore the reasoning potential of LLMs, ProRL offers a reproducible foundation and a practical training recipe. With open source models and benchmarks available, the community is encouraged to further explore and validate these findings as part of ongoing research into the limits and opportunities of RL for LLMs.
Ready to get started? Explore ProRL models on Hugging Face.









