
As the global service economy grows, companies rely increasingly on contact centers to drive better customer experiences, increase customer satisfaction, and lower costs with increased efficiencies. Customer demand has increased far more rapidly than contact center employment ever could. Combined with the high agent churn rate, customer demand creates a need for more automated real-time customer communication augmenting the agents.

Researchers recognized these trends as early as the 1970s and began developing primitive voice menus navigable through touch-tone phones. While voice menus may answer frequently asked questions and reduce pressure on contact center agents, customers often find it frustrating to interact with them.
Chances are that you may have been one of the callers who wanted to speak to an agent directly, instead listening to multiple layers of prerecorded voice prompts, due to any of the following reasons:
- Listening to menu options that best match your queries takes time. Moreover, after you reach a contact center agent, your issue may be complex enough that it cannot be resolved in one call.
- Your issue may not closely match the menu options, or it might fall under multiple options.
- You and the contact center agent may not speak the same native languages, particularly if the contact center is outsourced to another country.
- Some contact centers may not be staffed at a convenient time for you to call.
To effectively resolve these issues, companies have begun integrating intelligent virtual assistants, also known as AI virtual assistants, into their contact center solutions.
In this post, we provide an overview of building and deploying contact center intelligent virtual assistants with the NVIDIA contact center intelligent virtual assistants workflow and components such as NVIDIA Riva voice technology and speech AI skills:
- Automatic speech recognition (ASR) or speech-to-text (STT)
- Text-to-speech (TTS)
Reducing development time for intelligent virtual assistants applications
Intelligent virtual assistants are AI-powered software that recognize human speech, understand the intent, and provide precise and personalized responses in human-like voices while engaging with customers in conversation.
Around the clock, intelligent virtual assistants collect customer information and reasons for the call and manage customer issues without the need for a live agent. For complex cases, this information is automatically prepared for the live agent, to optimize servicing customers with a personal touch.
You can use NVIDIA Riva speech and translation AI building blocks to create intelligent virtual assistant applications. To reduce development time, you can leverage the NVIDIA contact center intelligent virtual assistants workflow with integrated Riva skills.
This NVIDIA AI solution workflow provides a reference for you to get started without preparation, helping you achieve the desired AI outcome more quickly.
NVIDIA contact center intelligent virtual assistant workflow and components
The NVIDIA contact center intelligent virtual assistant workflow (Figure 1) was designed as a microservice, which means it can be deployed on Kubernetes alone or with other microservices to create a production-ready application for seamless scaling.
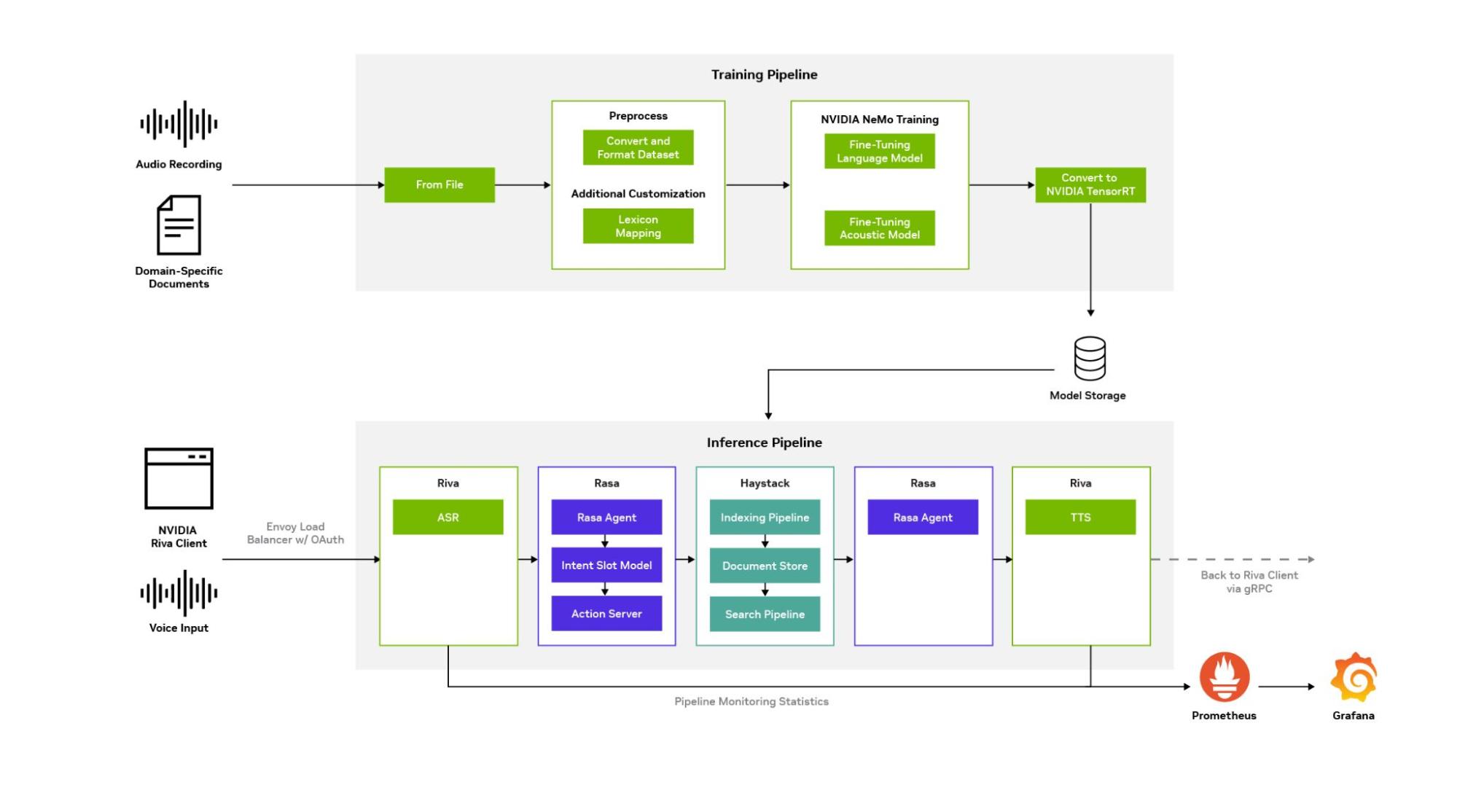
with NVIDIA Riva ASR and TTS, Rasa Dialog Manager, and Haystack NLP IRQA components
How services and dialog managers are integrated for deployment
This workflow integrates NVIDIA Riva ASR and TTS services with Haystack, a third-party open-source natural language information retrieval question answering (NLP IRQA) service, and Rasa, an open-source dialog manager.
Figure 1 shows that the Riva ASR service transcribes a user’s spoken question. Rasa and Haystack are used to interpret the user’s intent in the question and construct a relevant response. This response is delivered to the user in synthesized natural speech using Riva TTS.
For context, NVIDIA Riva provides tools for building and deploying conversational AI and speech and translation AI pipelines to any device containing an NVIDIA GPU, whether on the edge, in a data center, or in the cloud. The tools also run inference with those pipelines.
Language-specific customizations for the financial industry
The NVIDIA contact center intelligent virtual assistant workflow features Riva ASR customizations for the financial services industry use case.
These Riva ASR customizations are performed in two sample Jupyter notebooks:
- To improve the recognition of finance-specific terms.
- To enhance recognition of finance terms in challenging acoustic environments, including noise, accents, and dialects.
- To provide explicit guides for pronunciation of finance-specific words.
For more information about customizing Riva ASR models, see ASR Customization Best Practices.
Dialog manager training and IRQA components
After Riva ASR customization, you can work on the intelligent virtual assistant dialog manager on information retrieval and question-answering (IRQA) components. Every intelligent virtual assistant requires a way to manage the state and flow of the conversation.
A dialog manager employs a language model like BERT to recognize the user intent in the transcribed text obtained from the Riva ASR service. It then routes the question to the correct prepared response or a fulfillment service. This provides context for the question and frames how the intelligent virtual assistant can give the proper response.
The Rasa dialog manager also maintains the dialog state, by filling slots set by the developer for remembering the context of the conversation. It can be trained to understand user intent by giving it a few examples of each intent and the slots to be recognized.
IRQA with Haystack NLP is then used to search a list of given documents and generate a long-form response to the user’s question. This assists companies with massive amounts of unstructured data that need to be consumed in a form that is helpful to the customer. After IRQA generates the answer, Riva TTS synthesizes a human-like audio response.
To summarize, the NVIDIA contact center intelligent virtual assistant workflow can be deployed on any cloud Kubernetes distribution as a collection of Helm charts, each running a microservice.
While the NVIDIA contact center intelligent virtual assistant architecture uses Haystack and Rasa components, you can use your preferred components.
All the NVIDIA contact center intelligent virtual assistant workflow-packaged components include enterprise-ready implementation best practices that range from authentication, monitoring, reporting, and load balancing while enabling customization.
Optimal inference based on usage metrics
The NVIDIA contact center intelligent virtual assistant workflow includes NVIDIA Triton Inference Server, which provides Prometheus with metrics indicating GPU and request statistics. The metric format is plain text so you can view them directly in the Grafana dashboard.
Based on the Triton Inference Server metrics, we have calculated metrics that are specific and important to Riva (Table 1).
| Metric name | Metrics formula | Definition |
| Average queue time | avg(delta(nv_inference_queue_duration_us[1m])/(1+delta(nv_inference_request_success[1m]))/1000) | Time in milliseconds that a request stays in the Triton Inference Server queue averaged over all the requests in a one-minute time window. This is a measure of your server’s computing capability. If this increases over a threshold, consider scaling your server to more replicas. |
| Number of successful requests per minute | sum(delta(nv_inference_request_success[1m])) | Total number of successful inference requests captured over a one-minute time window. |
| Number of failed requests per minute | sum(delta(nv_inference_request_failure[1m])) | Total number of successful inference requests captured over a one-minute time window. |
| P99 latency in seconds | quantile_over_time(0.99, nv_inference_compute_infer_duration_us[1m]) / 1000 / 1000 | The p99 ASR latency of all the request samples captured over a one-minute time window. |
| P95 latency in seconds | quantile_over_time(0.95, nv_inference_compute_infer_duration_us[1m]) / 1000 / 1000 | The p95 ASR latency of all the request samples captured over a one-minute time window. |
| GPU memory utilization | avg(nv_gpu_memory_used_bytes / 1024 / 1024 / 1024) | GPU memory used by the Riva server. |
| Number of Riva Servers | count (count by (instance) (nv_cache_hit_lookup_duration_per_model)) | Riva server replicas on the Kubernetes cluster. |
| GPU Utilization | avg(nv_gpu_utilization) | Average GPU utilization. |
| GPU Power Utilization | avg(nv_gpu_power_usage) | GPU power consumption over a period of time. |
Depending on these usage metrics, the Riva pods can be scaled manually or automatically.
Conclusion
NVIDIA Riva provides speech and translation AI tools that enable companies to build and deploy intelligent virtual assistants in contact centers. These assistants relieve the pressure on human agents while granting customers the interactivity and personal treatment that they expect from live employees. This all drives a better customer experience.
Intelligent virtual assistants can also significantly increase contact center efficiency by reducing customer wait times, providing real-time translation, resolving customer challenges faster, reducing agent onboarding time, and enabling customers to reach contact centers 24/7. Companies can also use contact center call transcripts to further hone their products and services.
Related resources
The NVIDIA contact center intelligent virtual assistant workflow is available on NVIDIA NGC as a 90-day free trial for developers. Contact us to learn more about purchasing Riva for production deployments.
Sign up for NVIDIA LaunchPad to gain hands-on experience and tap into the necessary hardware and software stacks to test and prototype your conversation-based solutions.
For step-by-step instructions on enhancing contact centers with Riva speech and translation AI services, see the webinar, How to Build and Deploy an AI Voice-Enabled Virtual Assistant for Financial Services Contact Centers.
To learn how real companies have benefited from Riva speech and translation AI skills in their contact centers, see the T-Mobile and Floatbot use case stories.
