
Reverse time migration (RTM) is a powerful seismic migration technique, providing geophysicists with the ability to create accurate 3D images of the subsurface. Steep dips? Complex salt structure? High velocity contrast? No problem. By splitting the upgoing and downgoing wavefields and combining them with an accurate velocity model, RTM can image even the most complex geologic formations.
The algorithm migrates each shot independently using this basic workflow:
- Compute the downgoing wavefield.
- Reconstruct the upgoing wavefield and reverse it in time.
- Correlate up and down wavefields at each image point.
- Repeat for all shots and combine in a 3D image.
While simple in concept, the computational costs made RTM economically unviable until the early 2010s, when parallel processing with NVIDIA GPUs dramatically reduced the migration time and hardware footprint needed.
Reducing RTM costs by increasing computational efficiency
There are several factors driving computational requirements for tilted transversely isotropic (TTI) RTM. One is the calculation of first, second, and cross-derivatives along x, y, and z. Earlier versions of GPU, such as the Fermi and Kepler generations, had limited streaming multiprocessors (SMs), shared memory, and compiler technology.
Paulius Micikevicius famously overcame these issues by splitting the derivative calculations into two or three passes, with each pass computing a set of derivatives. This major breakthrough allowed seismic processors to run RTM in an economical and time-efficient manner. However, each pass requires a round-trip to memory. Each round-trip to memory hinders performance and drives up costs.
While multi-pass RTM was the best you could do in 2012, you can do much better today with the NVIDIA Volta or NVIDIA Ampere Architecture generations. If your RTM kernel hasn’t been tuned since the days of Paulius, you are leaving significant value on the table.
Moving to a one-pass RTM
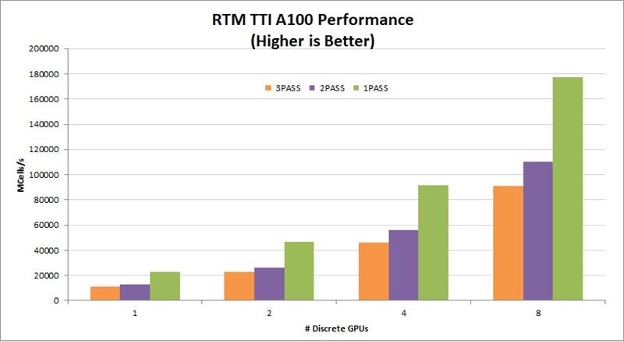
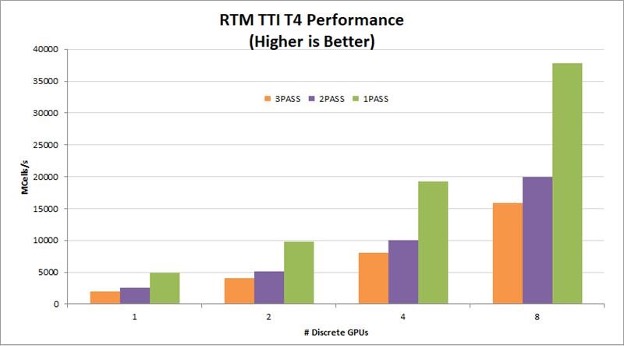
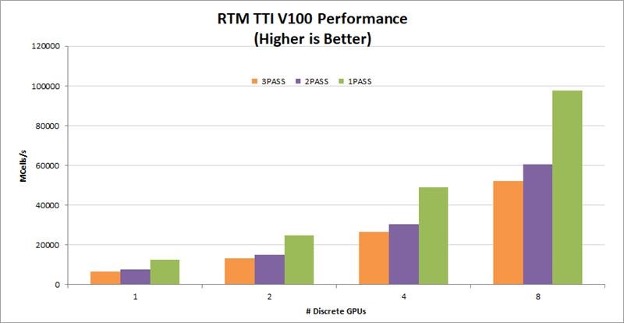
A one-pass TTI RTM kernel reads the wavefield one time, computes all necessary derivatives, and writes the updated wavefields to global memory one time. By eliminating multiple read/write roundtrips to memory, this implementation dramatically increases the performance gained on GPUs. It also helps the algorithm scale linearly across multiple GPUs in a node. Figures 2-4 show the relative performance of the TTI RTM kernel normalized to single-GPU, one-pass performance. The graphs show linear scaling across eight GPUs and greater than 50% performance improvement moving from two passes to one pass. To see absolute performance instead of relative performance and compare T4, V100, and A100, leave a comment.
For seismic processing in the cloud, T4 provides a particularly good price/performance solution. On-premises servers for seismic processing typically have four to eight V100 or A100 GPUs per node. For these configurations, reducing the number of passes from three to one improves RTM kernel performance by 78-98%!
Conclusion
Reducing the number of passes in your RTM kernel can dramatically improve code performance and decrease costs. To make the development easier, NVIDIA has developed a collection of code examples showing how to implement a GPU-accelerated RTM using best practices. If we have an NDA in place for you, you can have free access to this code.
Of course, the number of passes in an RTM kernel is only one piece of the puzzle. There are several other tricks shown in the example code to further increase performance, such as compression.
If you’re interested in accessing the NVIDIA RTM implementation or want assistance in optimizing your code, please comment below.
