NVIDIA TAO is a framework designed to simplify and accelerate the development and deployment of AI models. It enables you to use pretrained models, fine-tune them with your own data, and optimize the models for specific use cases without needing deep AI expertise.
TAO integrates seamlessly with the NVIDIA hardware and software ecosystem, providing tools for efficient AI model training, deployment, and inferencing and speeding up time-to-market for AI-driven applications.
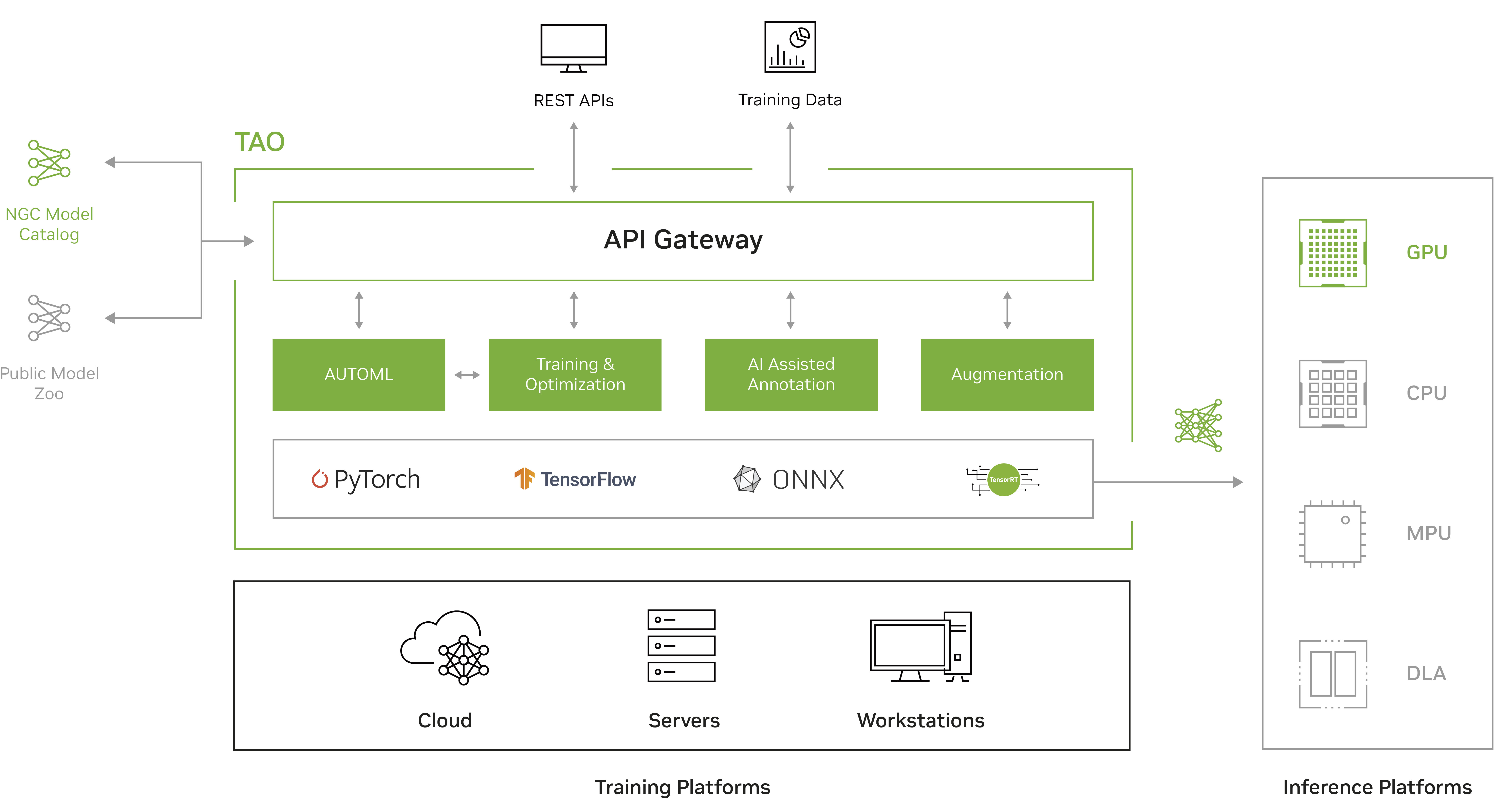
Figure 1 shows that TAO supports frameworks like PyTorch, TensorFlow, and ONNX. Training can be done on multiple platforms, and the resulting models can be deployed on various inference platforms, such as GPU, CPU, MCU, and DLA.
NVIDIA just released TAO 5.5, bringing state-of-the-art foundation models and groundbreaking features to enhance any AI model development. The new features include the following:
- Multi-modal sensor fusion models: Integrate data from multiple sensors into a unified bird’s-eye view (BEV) representation, preserving both geometric and semantic information.
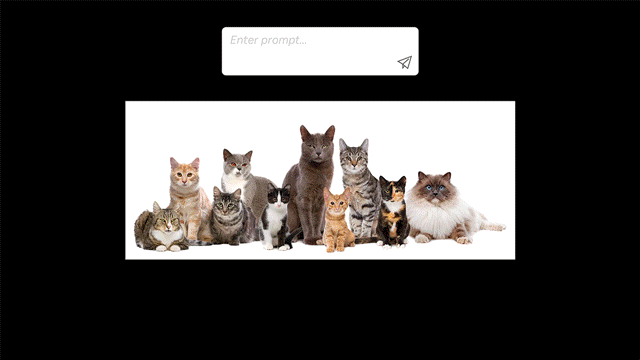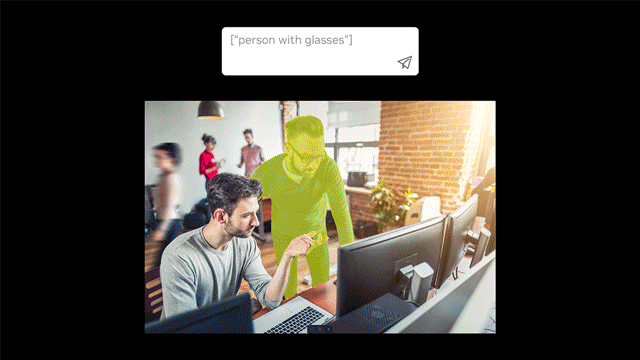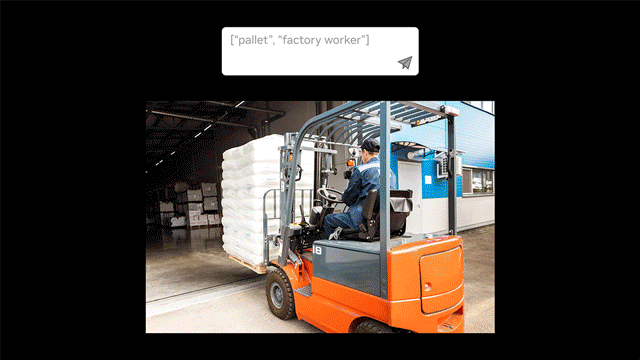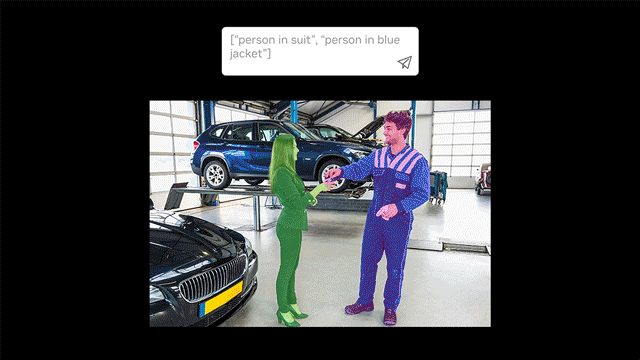
- Auto-labeling with text prompts: Automatically create label datasets for object detection and segmentation using text prompts.
- Open-vocabulary detection: Identify objects from any category using natural language descriptions instead of predefined labels.
- Knowledge distillation: Create smaller, more efficient, and accurate networks from the knowledge of larger networks.
In this post, we discuss the new features of TAO 5.5 in more detail.
| Model | NVIDIA TensorRT Optimized | Training Dataset | Supported Backbone |
| GroundingDINO | ✓ | Real data: 1.8M images, Labels: 14.5M instances of object detection and grounding annotations with Auto-labeler | swin_tiny_224_1k swin_base_224_22k swin_base_384_22k swin_large_224_22k swin_large_384_22k |
| Mask-GroundingDINO | ✓ | DINOv2-L CLIP-B (pretrained with an NVIDIA proprietary dataset) | swin_tiny_224_1k swin_base_224_22k swin_base_384_22k swin_large_224_22k swin_large_384_22k |
| BEVFusion | <coming up> | Synthetic data: ~5M images | Image: Swin-Transformers and ResNet-50Lidar: Second |
| NVCLIP | ✓ | Real data: 700M images | ViT-H-336 ViT-L-336 |
| SEGIC | ✓ | Real data: 110K images Synthetic data: 50K images | DINOv2-L CLIP-B (pretrained with an NVIDIA proprietary dataset) |
| FoundationPose | ✓ | Synthetic data: 1M images | – |
NVIDIA TAO integrates open-source, foundation, and proprietary models, all trained on extensive proprietary and commercially viable datasets, making them versatile for tasks such as object detection, pose detection, image classification, segmentation, and so on. TAO simplifies fine-tuning these models for specific use cases, making it easy to customize and deploy them commercially.
Most models are accelerated by NVIDIA TensorRT and optimized for performance on NVIDIA hardware, ensuring powerful and efficient AI solutions.
Swapping model backbones in TAO is straightforward and requires no coding, just a simple configuration change. This flexibility enables you to experiment with different architectures like ResNet, shifted window (Swin) transformers, and Fully Attentional Network (FAN), tailoring models to specific needs.
This ease of customization supports diverse applications, such as product identification in retail, medical imaging classification in healthcare, robotic assembly monitoring in manufacturing, and traffic management in smart cities.
GroundingDINO model
Traditional object detection models are limited to recognizing objects from predefined categories (closed-set detection). This constraint makes them ineffective for applications requiring the identification of arbitrary objects based on human inputs, such as specific category names or detailed referring expressions.
GroundingDINO addresses this limitation by integrating a text encoder into the DINO model, transforming it into an open-set object detector. This enables the model to detect any object described by human inputs.
GroundingDINO effectively fuses language and vision modalities by employing a feature enhancer, language-guided query selection, and a cross-modality decoder. This enables the model to generalize concepts beyond predefined categories, achieving superior performance.
GroundingDINO with TAO
This model was trained with a Swin-Tiny backbone using a supervised manner on the NVIDIA proprietary dataset for commercial usage. In addition, BERT-Base was used as the starting weight for the text tower. Finally, GroundingDINO was trained end-to-end on about 1.8M images that were collected from publicly available datasets.
All the raw images used during training have commercial licenses to ensure safe commercial usage.
| Model | Precision | mAP | mAP50 | mAP75 | mAPs | mAPm | mAPI |
| grounding_dino_swin_tiny | BF16 | 46.1 | 59.9 | 51.0 | 30.5 | 49.3 | 60.8 |
Mask-GroundingDINO model
Mask-GroundingDINO is a single-stage, open-vocabulary instance segmentation model that generates a segmentation mask around a specific instance of an object. This model is built on top of the GroundingDINO architecture and Conditional Convolutions for Instance Segmentation (CondInst) inspire the segmentation graph.
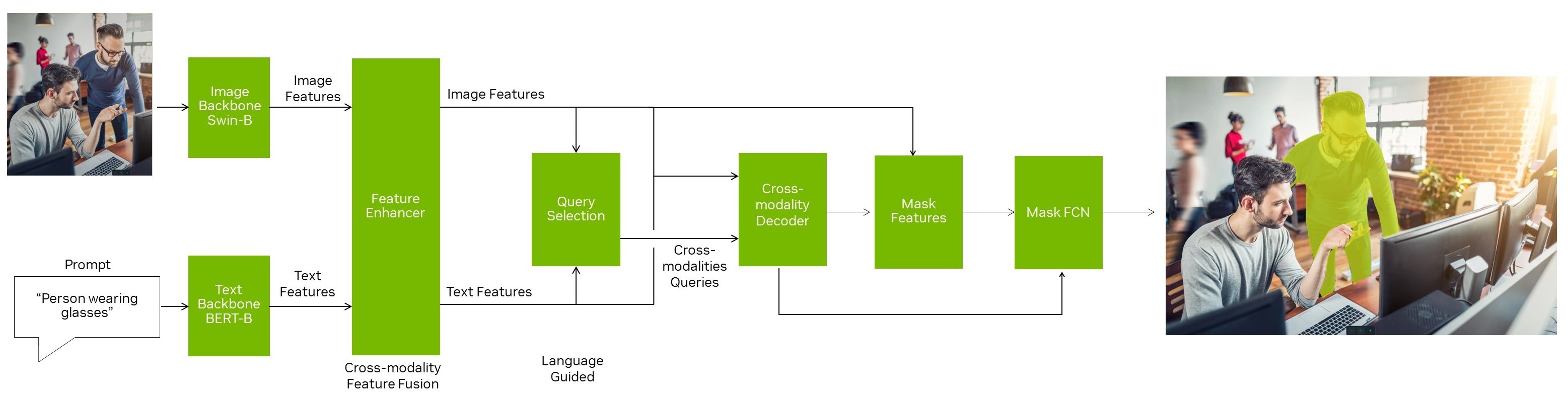
Mask-GroundingDINO with TAO
CondInst proposes a conditional convolution head for instance segmentation, which updates its convolutional kernel weights based on the input or feature maps. We extended the mask branch and instance-aware mask heads originally designed only for CNNs in CondInst to Transformers or query-based models.
In Mask-GroundingDINO, we chose to use the same encoder and decoder design as in DINO. Still, similar connections can be made to other Transformer encoders and decoders.
- Input: Text or image.
- Text can be either a list of categories (box, forklift) or a scene/object description in natural language.
- Backbone: Text or image.
- Text backbone can be BERT or other NLP models.
- Image backbone can be a Swin Transformer model or other Transformer or CNN-based backbones.
- Feature Enhancer: A stack of self-attention, text-to-image cross-attention, and image-to-text cross-attention layers that promote multimodal alignment.
- Query Selection module: Selects top K queries based on the dot product between text features and image features.
- Mask FCN head: A few convolutional layers with dynamic kernels.
- Controller: A few convolutional layers that predict the weights of the dynamic kernels in the Mask FCN head.
This model was fine-tuned with the commercial GroundingDINO pretrained model on the pseudo-labeled Open Images dataset, which allows commercial usage. The model uses a Swin-Tiny backbone and its segmentation head was fine-tuned end-to-end on about 830K images that have pseudo-labeled ground-truth masks.
You can use this model as is or fine-tune it with TAO. For fine-tuning, we provide the Mask-GroundingDINO Jupyter notebook for an easy and interactive environment where minimal coding is required.
| Model | Precision | mAP | mAP50 | mask_mAP | mask_mAP50 |
| mask_grounding_dino_swin_tiny | BF16 | 47.5 | 61.7 | 32.9 | 55.7 |
BEVFusion model
In many domains, from autonomous driving to robotics and smart cities, systems rely on various sensors to perceive and interact with their environment. Each sensor type, such as cameras, LiDAR, or radar, provides unique information but also has inherent limitations. For example, cameras capture rich visual details but struggle with depth perception, while LiDAR excels in measuring distances but lacks semantic context.
The challenge is effectively combining these diverse data sources to improve system performance and reliability.
BEVFusion offers a solution to this challenge by integrating data from multiple sensors into a unified bird’s-eye view (BEV) representation. It revolutionizes this process by unifying multi-modal features into a shared BEV representation, preserving both geometric (from LiDAR) and semantic (from camera) information.
BEVFusion with TAO
In TAO, we began with the BEVFusion codebase from mmdet3d to train our model. The original code was enhanced to handle three angles in 3D space (roll, pitch, yaw), whereas initially, it supported only yaw. The TAO-trained BEVFusion model detects people within a single camera view and a LiDAR and creates a 3-D bounding box around people.
| Content | AP11 | AP40 |
| Evaluation Set | 77.71% | 79.35% |
CLIP model
Efficiently learning meaningful and contextually rich representations of both images and text is a significant challenge, especially for applications requiring multimodal understanding. Use cases such as zero-shot learning, image captioning, visual search, content moderation, and multimodal interaction demand robust models that can accurately interpret and integrate visual and textual data.
The Contrastive Language-Image Pre-training (CLIP) model addresses this challenge by employing a dual encoder architecture to simultaneously process images and text. Using contrastive learning, CLIP maximizes the similarity between correct image-text pairs while minimizing it for incorrect pairs, enabling the model to learn general representations that capture a wide range of concepts.
This approach enables CLIP to excel in various applications, such as generating descriptive image captions, performing visual searches based on textual queries, and enabling zero-shot learning, where the model can classify images into unseen categories by leveraging its learned representations.
NVCLIP with TAO
In TAO, we provide a pretrained TensorRT-accelerated CLIP model on the NVIDIA dataset. We used ~700M images to train this model. For evaluation, we used 50K validation images from the ImageNet dataset.
You can deploy the model from NVIDIA Jetson to NVIDIA Ampere architecture GPUs.
| Model | Top-1 accuracy |
| ViT-H-336 | 0.7786 |
| ViT-L-336 | 0.7629 |
SEGIC model
SEGIC is an innovative end-to-end segment-in-context framework that revolutionizes in-context segmentation with a single-vision foundation model (VFM).
Unlike traditional methods, SEGIC captures dense relationships between target images and in-context examples, extracting geometric, visual, and meta instructions to guide the final mask prediction. This approach significantly reduces labeling and training costs while achieving state-of-the-art performance on one-shot segmentation benchmarks.
SEGIC’s versatility extends to diverse tasks, including video object segmentation and open-vocabulary segmentation, making it a powerful tool in the field of image segmentation.
SEGIC with TAO
For the SEGIC model training in TAO, we provided a pretrained ONNX model and a deployment recipe with NVIDIA Triton Inference Server. For training, we used the following resources:
- Image encoder: DINOv2-L, trained with proprietary images from NVIDIA.
- Meta description encoder: CLIP-B, trained with proprietary images from NVIDIA.
| Model | mIOU |
| SEGIC: DINOv2-L , CLIP-B, mask_decoder | 69.57 |
FoundationPose model
Accurate 6D object pose estimation and tracking are crucial for various applications, such as robotics, augmented reality, and autonomous driving. However, existing methods often require extensive fine-tuning and are limited by their dependency on either model-based or model-free setups. This creates a challenge in achieving robust performance across different scenarios and objects, particularly when CAD models are unavailable or when dealing with novel objects.
FoundationPose addresses this problem by providing a unified foundation model for 6D object pose estimation and tracking that supports both model-based and model-free setups. It can be applied instantly to novel objects at test time, leveraging either CAD models or a few reference images.
By using a neural implicit representation for novel view synthesis and employing large-scale synthetic training with advanced techniques like an LLM, a novel transformer-based architecture, and contrastive learning, FoundationPose achieves strong generalizability and outperforms specialized methods across various public datasets.
For example, in augmented reality applications, FoundationPose enables seamless integration of virtual objects into real-world environments by accurately estimating and tracking the pose of objects without the need for extensive manual adjustments.
FoundationPose with TAO
We provided a pretrained ONNX model and deployment recipe with NVIDIA Triton Inference Server. Our training data consisted of scenes rendered in high-quality photorealism, using 3D assets from Scanned Objects by Google Research and Objaverse. Each data point includes RGB images, depth information, object poses, camera poses, instance segmentation, and 2D bounding boxes, with extensive domain randomization. We then created ~1M synthetic images with NVIDIA Isaac Sim.
In the worldwide BOP leaderboard, model-based novel object pose estimation was at the #1 position as of March 2024 (Figure 3).

Prompt-based auto-labeling for object detection and segmentation
Having a well-labeled dataset is essential for training and fine-tuning models, especially in tasks like object detection and segmentation. However, obtaining a labeled dataset for new categories and instances takes a lot of time and effort. This is particularly true for instance segmentation, where annotating each object with precise masks can take up to 10x longer than drawing simple bounding boxes.
This is where a simple-to-use, prompt-based, auto-labeling method can help:
- GroundingDINO: An open-vocabulary object detection model that uses prompts such as object categories to generate bounding boxes.
- Mask Auto-Labeler: A Transformer-based framework that uses the bounding boxes to produce high-quality instance segmentation masks.
This combination significantly reduces the effort required to create detailed labels, making it easier and faster to build robust datasets for training advanced models.

We provide a complete end-to-end Jupyter notebook (text2box.ipynb) for auto labeling with no coding needed. We provide two spec files, one for bbox labels and another for segmentation, where you can define the objects to label, for example [person, helmet], the path of the unlabeled dataset, and the result directory in which to store the labels.
Generate the auto labels with the generate command:
tao dataset auto_label generate [-h] -e <spec file>
[results_dir=<results_dir>]
[num_gpus=<num_gpus>]
Efficient AI with knowledge distillation
Knowledge distillation is a technique in machine learning where a smaller, more efficient model (the student) learns to mimic the behavior of a larger, more complex model (the teacher). This process helps reduce training and fine-tuning time, as the student model uses the knowledge already captured by the teacher, including more nuanced information like soft labels, and doesn’t need to be trained from scratch for any new task.
By distilling this knowledge, the student model can achieve similar performance with significantly fewer computational resources, making it ideal for deployment in resource-constrained environments and speeding up the training process.

TAO supports knowledge distillation. Specify the binding between various layers to formulate compute the distillation loss. For more information, see Optimizing the Training Pipeline.
We provide the dino_distillation.ipynb reference notebook to showcase knowledge distillation and how to distill the intermediate feature maps from DINO and FAN small to DINO and ResNet-50 using an L2 loss.
distill.yaml:
model:
backbone: resnet_50 # Student model
train_backbone: True
distill:
teacher:
backbone: fan_small
train_backbone: False
num_feature_levels: 4 # Number of feature-maps to map from teacher
pretrained_teacher_model_path: /workspace/tao-experiments/dino/pretrained_dino_coco_vdino_fan_small_trainable_v1.0/dino_fan_small_ep12.pth
bindings:
- teacher_module_name: 'model.backbone.0.body'
student_module_name: 'model.backbone.0.body'
criterion: L2
In the distill.yaml file, you can define the teacher model, student model backbone, and loss function. Train the model:
!tao model dino distill \ -e $SPECS_DIR/distill.yaml \ results_dir=$RESULTS_DIR/
After the student model is trained, you can use the TAO evaluate tool to evaluate the distilled model, inference tool to visualize the inference, export tool to export the trained model to ONNX, and eventually generate the gen_trt_engine file to export the DINO and ResNet-50 model to TensorRT.
Getting started with TAO 5.5
Developers around the world are using NVIDIA TAO to accelerate AI training for their vision AI applications. Use the new capabilities of TAO 5.5 to enhance your AI application.
For more information, see the following resources:
