
Back in 2012, NVIDIAN Mark Harris wrote Six Ways to Saxpy, demonstrating how to perform the SAXPY operation on a GPU in multiple ways, using different languages and libraries. Since then, programming paradigms have evolved and so has the NVIDIA HPC SDK.
In this post, I demonstrate five ways to implement a simple SAXPY computation using NVIDIA GPUs. Why is this interesting? Because it demonstrates the breadth of options that you have today for programming NVIDIA GPUs. It also covers the four main approaches to GPU computing:
- GPU-accelerated libraries
- Compiler directives
- Standard language parallelism
- GPU programming languages
SAXPY stands for Single-Precision A·X Plus Y, a function in the standard Basic Linear Algebra Subroutines (BLAS) library. SAXPY is a combination of scalar multiplication and vector addition, and it’s simple: it takes as input two vectors of 32-bit floats X and Y with N elements each, and a scalar value A. It multiplies each element X[i] by A and adds the result to Y[i]. A simple C implementation looks like the following:
void saxpy_cpu(int n, float a, float *x, float *y) { for (int i = 0; i < n; ++i) y[i] = a * x[i] + y[i]; }...// Perform SAXPY on ~33M elements saxpy_cpu(n, 2.0, x, y);
Given this basic example code, I can now show you five ways to SAXPY on GPUs. I chose SAXPY because it is a short and simple code, but it shows enough of the syntax of each programming approach to compare them. Because it does relatively little computation, SAXPY isn’t that useful for demonstrating the difference in performance between the different programming models, but that’s not my intent here. My goal is to demonstrate multiple ways to program on the NVIDIA platform today, rather than to recommend one over another. That would require taking other factors into account and is beyond the scope of this post.
I discuss implementations of SAXPY in the following models:
- CUDA C++—A C++ language extension to support the CUDA programming model and allow C++ code to be executed on NVIDIA GPUs.
- cuBLAS—A GPU-accelerated implementation of the basic linear algebra subroutines (BLAS) optimized for NVIDIA GPUs.
- OpenACC—Using compiler directives to tell the compiler that a given portion of the code can be parallelized and letting the compiler figure out how to do it.
- Standard C++—Using the NVC++ compiler and parallel execution policies added to the standard library with C++ 17.
- Thrust—A high-level, GPU-accelerated parallel algorithms library.
After going through all the implementations, I show what performance looks like when SAXPY is accelerated through these approaches.
CUDA C++ SAXPY
__global__ void saxpy_cuda(int n, float a, float *x, float *y){
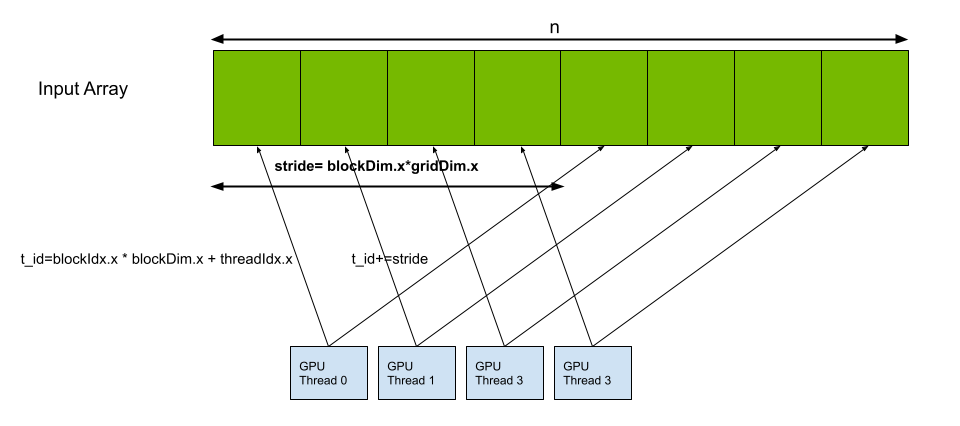
int t_id = threadIdx.x + blockDim.x * blockIdx.x;
int stride = blockDim.x * gridDim.x;
for (int i = t_id; i < n; i += stride)
{
y[i] = a * x[i] + y[i];
}
}
...
int n = 1UL << 25;
float *x, *y, alpha=2.0;
cudaMalloc(&x, n * sizeof(float));
cudaMalloc(&y, n * sizeof(float));
saxpy_cuda<<<32, 1024>>>(n, alpha, x, y);
cudaDeviceSynchronize();
cudaFree(x);
cudaFree(y);CUDA C++ is a GPU programming language that provides extensions to the C/C++ language for expressing parallel computation. A kernel is a function decorated with the __global__ execution space specifier. It is callable from the host and executed on the device. Device memory to hold the float vector is allocated using cudaMalloc. Then, the kernel defined is called with an execution configuration:
<<<number_of_thread_blocks, threads_per_thread_block>>>
Each thread launched executes the kernel, using built-in variables like threadIdx, blockDim, and blockIdx. The variables are assigned by the device for each thread and block and are used to calculate the index of the elements in the vector for which it is responsible. In doing so, each thread does the multiply-add operation on a limited number of elements of the vector. In the case where the number of threads is less than the size of the vector, each thread computes a stride to operate on multiple elements so that the entire vector is taken care of (Figure 1).
cuBLAS SAXPY
cublasHandle_t handle;cublasCreate(&handle); int n = 1UL << 25; float *x, *y, alpha=2.0; cudaMalloc(&x, n * sizeof(float)); cudaMalloc(&y, n * sizeof(float)); cublasSaxpy(handle, n, &alpha, x, 1, y, 1); cublasDestroy(handle); cudaFree(x); cudaFree(y);
SAXPY, being a BLAS operation, has an implementation in the NVIDIA cuBLAS library. It involves initializing a cuBLAS library context by passing a handle to cublasCreate, allocating memory for the vectors, and then calling the library function cublasSaxpy while passing in the vector and scalar values. Finally, cublasDestroy and cudaFree are used to release the resources associated with the cuBLAS library context and device memory allocated for the vectors, respectively.
OpenACC C++ SAXPY
void saxpy(int n, float a, float *restrict x, float *restrict y){
#pragma acc kernels loop
for (int i = 0; i < n; ++i)
y[i] = a * x[i] + y[i];
}
...
float alpha = 2.0;
int n = 1UL << 25;
float *x = new float[n];
float *y = new float[n];
saxpy(n, alpha, x, y);
delete[] x;
delete[] y;OpenACC is a directive-based programming model that uses compiler directives through #pragma to tell the compiler that a portion of the code can be parallelized. The compiler then analyzes the instruction and automatically generates code for the GPU. OpenACC provides options for fine-tuning launch configurations in those instances where the automatically generated code may not be optimal.
Compilers with support for NVIDIA GPUs like nvc++ can offload computation to the GPU using unified memory to seamlessly copy data between the host and device. Adding #pragma acc kernels loop tells the compiler to generate a kernel for the following for loop. Because you allocated x and y on the host using the malloc instruction, the compiler uses unified memory to move the vector to the device before computation and back to the host afterwards.The compiler generates instructions to move the vectors x and y into device memory and do a fused multiply-add for each element.
stdpar C++ SAXPY
float alpha = 2.0;int n = 1UL << 25; std::vector<float> x(n); std::vector<float> y(n); std::fill(x.begin(), x.end(), 1.0); std::fill(y.begin(), y.end(), 1.0); std::transform(std::execution::par_unseq, x, x + n, y, y, [=](float xi, float yi) { return alpha * xi + yi; });
With the NVIDIA NVC++ compiler, you can use GPU acceleration in standard C++ with no language extensions, pragmas, directives, or libraries, other than the C++ standard library. The code, being standard C++, is portable to other compilers and systems and can be accelerated on NVIDIA GPUs or multicore CPUs using NVC++.
With the new features for parallel execution and execution policies introduced with C++ 17, algorithms in the standard library, like std::transform and std::reduce, added an execution policy as the first parameter to any algorithm that supports execution policies. You can thus pass std::execution::par_unseq to std::transform, defining a lambda that captures by value and performs the saxpy operation. When compiled using the -stdpar command line option, the compiler compiles standard algorithms that are called with a parallel execution policy for execution on NVIDIA GPUs.
Thrust SAXPY
float alpha = 2.0;unsigned int n = 1UL << 25; thrust::universal_vector<float> x(n); thrust::universal_vector<float> y(n); thrust::fill(x.begin(), x.end(), 1.0); thrust::fill(y.begin(), y.end(), 1.0); thrust::transform(x.begin(), x.end(), y.begin(), y.begin(), [=] __device__ (float x_1, float y_1) { return alpha * x_1 + y_1; });
Thrust is a header-only library that provides parallel building blocks to develop fast, portable algorithms. Interoperability with established technologies like CUDA and TBB, along with its modular design, allows you to focus on the algorithms instead of the platform-specific implementations.
Here, you allocate memory on the device, in this case the NVIDIA GPU for x and y. You then use the fill function to initialize them. Finally, you use the Thrust transform algorithm along with a device lambda to apply the y=a*x+y operation to each element of x and y.
SAXPY performance
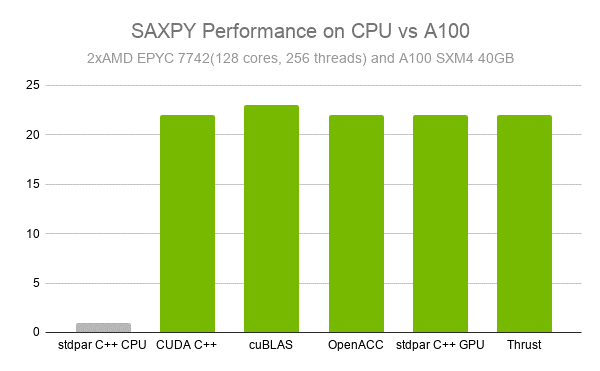
While SAXPY is a bandwidth-bound operation and not computationally complex, its highly parallel nature means that it still benefits from GPU acceleration if the problem size is large enough. When compared to a dual-socket AMD EPYC 7742 system with 128 cores and 256 threads, an A100 was 23x faster. Furthermore, all GPU-accelerated implementations gave us similar performance, with cuBLAS edging out the rest by a slight margin (Figure 2).
Accelerating your code with NVIDIA GPUs
The NVIDIA HPC SDK is a comprehensive suite of compilers, libraries, and tools enabling you to choose the programming model that works best for you and still get excellent performance by accelerating your code using NVIDIA GPUs. Learn more and get started today:
Try NVIDIA GPU acceleration for your code from any major cloud service provider. Try A100 in the cloud at Google Cloud Platform, Amazon Web Services, or Alibaba Cloud.
