
The NVIDIA mission is to accelerate the work of the Da Vincis and Einsteins of our time and empower them to solve the grand challenges of society. With the complexity of artificial intelligence (AI), high-performance computing (HPC), and data analytics increasing exponentially, scientists need an advanced computing platform that is able to drive million-X speedups in a single decade to solve these extraordinary challenges.
To answer this need, we introduce the NVIDIA HGX H100, a key GPU server building block powered by the NVIDIA Hopper Architecture. This state-of-the-art platform securely delivers high performance with low latency, and integrates a full stack of capabilities from networking to compute at data center scale, the new unit of computing.
In this post, I discuss how the NVIDIA HGX H100 is helping deliver the next massive leap in our accelerated compute data center platform.
HGX H100 8-GPU
The HGX H100 8-GPU represents the key building block of the new Hopper generation GPU server. It hosts eight H100 Tensor Core GPUs and four third-generation NVSwitch. Each H100 GPU has multiple fourth generation NVLink ports and connects to all four NVSwitches. Each NVSwitch is a fully non-blocking switch that fully connects all eight H100 Tensor Core GPU.
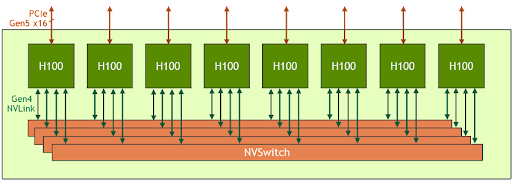
This fully connected topology from NVSwitch enables any H100 to talk to any other H100 concurrently. Notably, this communication runs at the NVLink bidirectional speed of 900 gigabytes per second (GB/s), which is more than 14x the bandwidth of the current PCIe Gen4 x16 bus.
The third-generation NVSwitch also provides new hardware acceleration for collective operations with multicast and NVIDIA SHARP in-network reductions. Combining with the faster NVLink speed, the effective bandwidth for common AI collective operations like all-reduce go up by 3x compared to the HGX A100. The NVSwitch acceleration of collectives also significantly reduces the load on the GPU.
| HGX A100 8-GPU | HGX H100 8-GPU | Improvement Ratio | |
| FP8 | – | 32,000 TFLOPS | 6X (vs A100 FP16) |
| FP16 | 4,992 TFLOPS | 16,000 TFLOPS | 3X |
| FP64 | 156 TFLOPS | 480 TFLOPS | 3X |
| In-Network Compute | 0 | 3.6 TFLOPS | Infinite |
| Interface to host CPU | 8x PCIe Gen4 x16 | 8x PCIe Gen5 x16 | 2X |
| Bisection Bandwidth | 2.4 TB/s | 3.6 TB/s | 1.5X |
*Note: FP performance includes sparsity
HGX H100 8-GPU with NVLink-Network support
The emerging class of exascale HPC and trillion parameter AI models for tasks like accurate conversational AI require months to train, even on supercomputers. Compressing this to the speed of business and completing training within hours requires high-speed, seamless communication between every GPU in a server cluster.
To tackle these large use cases, the new NVLink and NVSwitch are designed to enable HGX H100 8-GPU to scale up and support a much larger NVLink domain with the new NVLink-Network. Another version of HGX H100 8-GPU features this new NVLink-Network support.
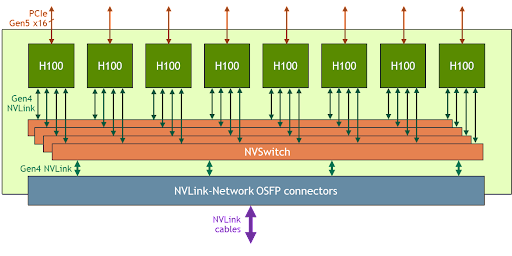
System nodes built with HGX H100 8-GPU with NVLink-Network support can fully connect to other systems through the Octal Small Form Factor Pluggable (OSFP) LinkX cables and the new external NVLink Switch. This connection enables up to a maximum of 256 GPU NVLink domains. Figure 3 shows the cluster topology.
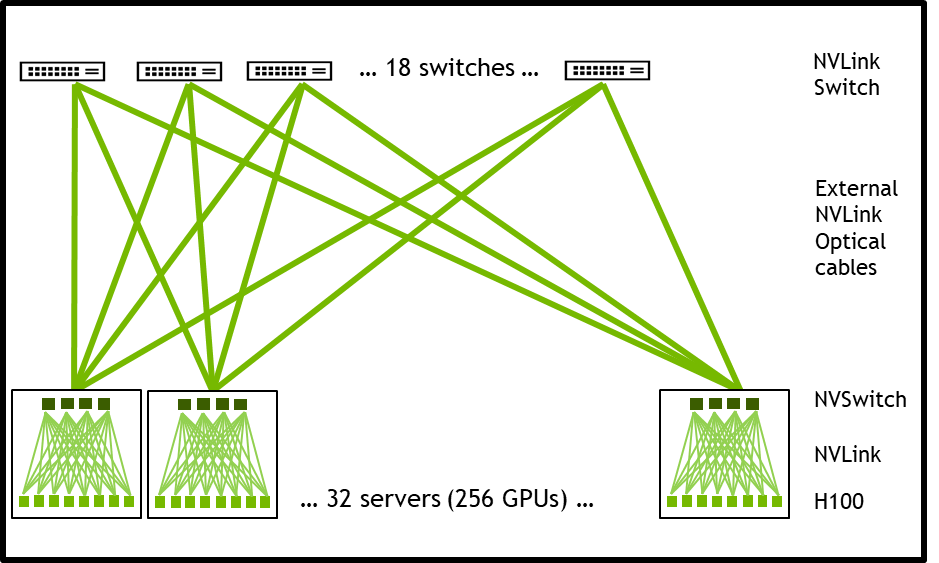
| 256 A100 GPU Pod | 256 H100 GPU Pod | Improvement Ratio | |
| NVLINK Domain | 8 GPU | 256 GPU | 32X |
| FP8 | – | 1,024 PFLOPS | 6X (vs A100 FP16) |
| FP16 | 160 PFLOPS | 512 PFLOPS | 3X |
| FP64 | 5 PFLOPS | 15 PFLOPS | 3X |
| In-Network Compute | 0 | 192 TFLOPS | Infinite |
| Bisection Bandwidth | 6.4 TB/s | 70 TB/s | 11X |
*Note: FP performance includes sparsity
Target use cases and performance benefit
With the dramatic increase in HGX H100 compute and networking capabilities, AI and HPC applications performances are vastly improved.
Today’s mainstream AI and HPC model can fully reside in the aggregate GPU memory of a single node. For example, BERT-Large, Mask R-CNN, and HGX H100 are the most performance-efficient training solutions.
For the more advanced and larger AI and HPC model, the model requires multiple nodes of aggregate GPU memory to fit. For example, a deep learning recommendation model (DLRM) with terabytes of embedded tables, a large mixture-of-experts (MoE) natural language processing model, and the HGX H100 with NVLink-Network accelerates the key communication bottleneck and is the best solution for this class of workload.
Figure 4 from the NVIDIA H100 GPU Architecture whitepaper shows the extra performance boost enabled by the NVLink-Network.
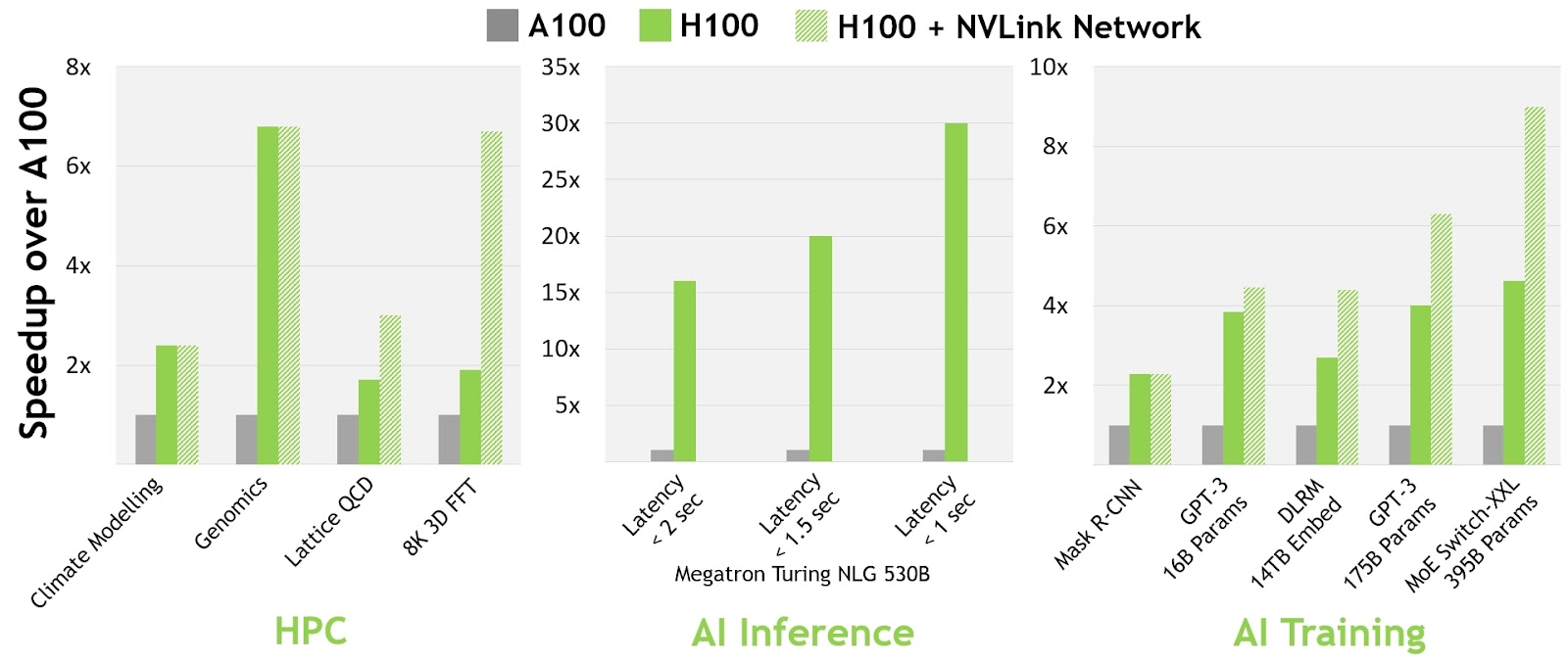
All performance numbers are preliminary based on current expectations and subject to change in shipping products. A100 cluster: HDR IB network. H100 cluster: NDR IB network with NVLink-Network where indicated.
# GPUs: Climate Modeling 1K, LQCD 1K, Genomics 8, 3D-FFT 256, MT-NLG 32 (batch sizes: 4 for A100, 60 for H100 at 1 sec, 8 for A100 and 64 for H100 at 1.5 and 2sec), MRCNN 8 (batch 32), GPT-3 16B 512 (batch 256), DLRM 128 (batch 64K), GPT-3 16K (batch 512), MoE 8K (batch 512, one expert per GPU)
HGX H100 4-GPU
In addition to the 8-GPU version, the HGX family also features a version with a 4-GPU, which is directly connected with fourth-generation NVLink.
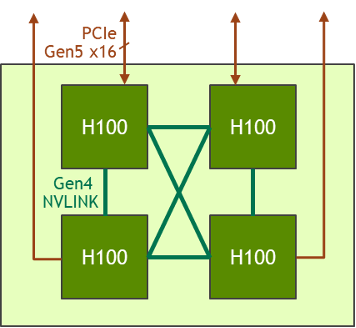
The H100-to-H100 point-to-point peer NVLink bandwidth is 300 GB/s bidirectional, which is about 5X faster than today’s PCIe Gen4 x16 bus.
The HGX H100 4-GPU form factor is optimized for dense HPC deployment:
- Multiple HGX H100 4-GPUs can be packed in a 1U high liquid cooling system to maximize GPU density per rack.
- Fully PCIe switch-less architecture with HGX H100 4-GPU directly connects to the CPU, lowering system bill of materials and saving power.
- For workloads that are more CPU intensive, HGX H100 4-GPU can pair with two CPU sockets to increase the CPU-to-GPU ratio for a more balanced system configuration.
An accelerated server platform for AI and HPC
NVIDIA is working closely with our ecosystem to bring the HGX H100 based server platform to the market later this year. We are looking forward to putting this powerful computing tool in your hands, enabling you to innovate and fulfill your life’s work at the fastest pace in human history.
