Apache Spark continued the effort to analyze big data that Apache Hadoop started over 15 years ago and has become the leading framework for large-scale distributed data processing. Today, hundreds of thousands of data engineers and scientists are working with Spark across 16,000+ enterprises and organizations.
One reason why Spark has taken the torch from Hadoop is because it can process data on average about 100x faster. These capabilities are created in an open community by over 1000 contributors across 250+ companies. The Databricks founders started this effort and their platform alone spins up over 1 million virtual machines per day to analyze data.
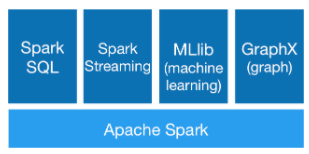
With high-level operators and libraries for SQL, stream processing, machine learning (ML), and graph processing, Spark makes it easy to build parallel applications in Scala, Python, R, or SQL, using an interactive shell, notebooks, or packaged applications. Spark supports batch and interactive analytics, using a functional programming model and associated query engine, Catalyst. Spark converts jobs into query plans and schedules operations within the query plan across nodes in a cluster.
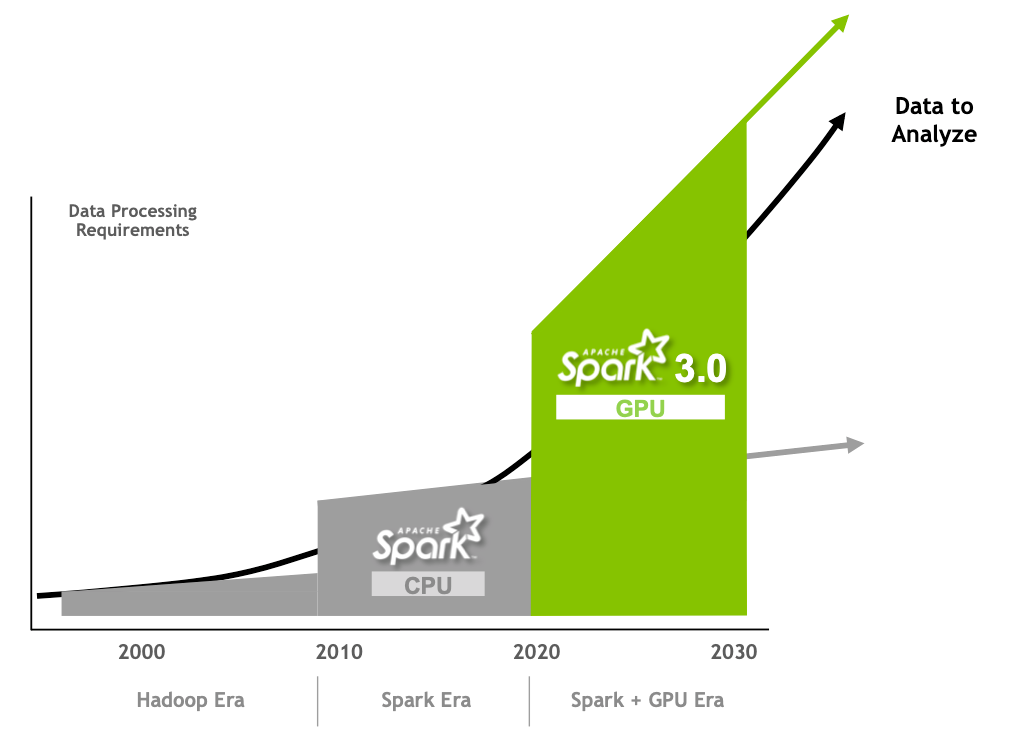
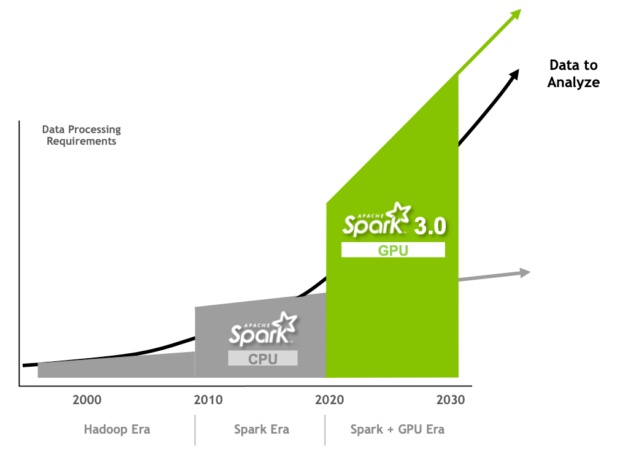
With each release of Spark, improvements have been implemented to make it easier to program and execute faster. Apache Spark 3.0 continues this trend with innovations to improve Spark SQL performance, and NVIDIA GPU acceleration, which I cover in this post.
Spark 3.0 optimizations for Spark SQL
Using its SQL query execution engine, Apache Spark achieves high performance for batch and streaming data. The engine builds upon ideas from massively parallel processing (MPP) technologies and consists of a state-of-the-art DAG scheduler, query optimizer, and physical execution engine. Most Spark application operations run through the query execution engine, and as a result the Apache Spark community has invested in further improving its performance. Adaptive query execution, dynamic partition pruning, and other optimizations enable Spark 3.0 to execute roughly 2x faster than Spark 2.4, based on the TPC-DS benchmark.
Spark 3.0 adaptive query execution
Spark 2.2 added cost-based optimization to the existing rule based query optimizer. Spark 3.0 now has runtime adaptive query execution (AQE). With AQE, runtime statistics retrieved from completed stages of the query plan are used to re-optimize the execution plan of the remaining query stages. Databricks benchmarks yielded speed-ups ranging from 1.1x to 8x when using AQE.
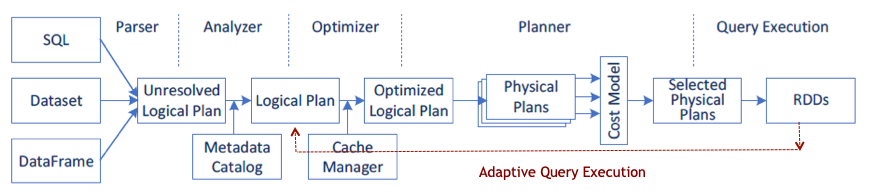
Spark 3.0 AQE optimization features include the following:
- Dynamically coalescing shuffle partitions: AQE can combine adjacent small partitions into bigger partitions in the shuffle stage by looking at the shuffle file statistics, reducing the number of tasks for query aggregations.
- Dynamically switching join strategies: AQE can optimize the join strategy at runtime based on the join relation size. For example, converting a sort merge join to a broadcast hash join which performs better if one side of the join is small enough to fit in memory.
- Dynamically optimizing skew joins: AQE can detect data skew in sort-merge join partition sizes using runtime statistics and split skew partitions into smaller sub-partitions.
Spark 3.0 dynamic partition pruning
Spark 2.x static partition pruning improves performance by allowing Spark to read only a subset of the directories and files for queries that match partition filter criteria. Spark 3.0 brings this data pruning technique at runtime for queries that resemble data warehouse queries, which join a partitioned fact table with filtered values from dimension tables. Reducing the amount of data read and processed results in significant time savings.
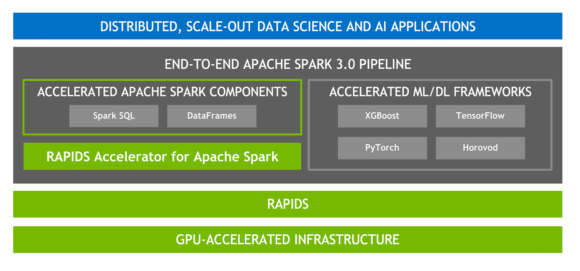
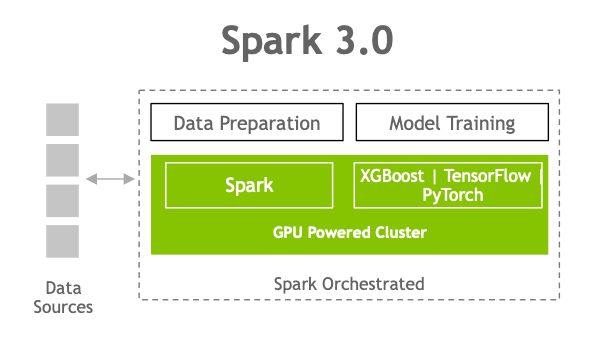
Spark 3.0 GPU acceleration
GPUs are popular for their extraordinarily low price per flop (performance). They are addressing the compute performance bottleneck today by speeding up multi-core servers for parallel processing.
A CPU consists of a few cores, optimized for sequential serial processing. A GPU has a massively parallel architecture consisting of thousands of smaller, more efficient cores designed to handle multiple tasks simultaneously. GPUs are capable of processing data much faster than configurations containing CPUs alone. GPUs have been responsible for the advancement of DL and ML model training in the past several years. However, 80% of a data scientist’s time is spent on data preprocessing.
While Spark distributes computation across nodes in the form of partitions, computation within a partition has historically been performed on CPU cores. Spark mitigated the I/O problems found in Hadoop by adding in-memory data processing but now the bottleneck has shifted from I/O to compute for a growing number of applications. This performance bottleneck can be prevented with the advent of GPU-accelerated computation.
To meet and exceed the modern requirements of data processing, NVIDIA has been collaborating with the Apache Spark community to bring GPUs into Spark’s native processing through the release of Spark 3.0 and the open-source RAPIDS Accelerator for Spark. For more information, see Google Cloud and NVIDIA’s enhanced partnership accelerates computing workloads.
The benefits of GPU acceleration in Spark are many:
- Data processing, queries and model training are completed faster, reducing time to results.
- The same GPU-accelerated infrastructure can be used for both Spark and ML/DL frameworks, eliminating the need for separate clusters and giving the entire pipeline access to GPU acceleration.
- Fewer servers are required, reducing infrastructure cost.
RAPIDS Accelerator for Apache Spark
RAPIDS is a suite of open-source software libraries and APIs for executing end-to-end data science and analytics pipelines entirely on GPUs, allowing for a substantial speed up, particularly on large data sets. Built on top of NVIDIA CUDA and UCX, the RAPIDS Accelerator for Apache Spark enables GPU-accelerated SQL and DataFrame operations and Spark shuffles with no code change.
Accelerated SQL/DataFrame
Spark 3.0 supports SQL optimizer plugins to process data using columnar batches rather than rows. Columnar data is GPU-friendly, and this feature is what the RAPIDS accelerator plugs into to accelerate SQL and DataFrame operators. With the RAPIDS accelerator, the Catalyst query optimizer has been modified to identify operators within a query plan that can be accelerated with the RAPIDS API, mostly a one-to-one mapping, and to schedule those operators on GPUs within the Spark cluster when executing the query plan.
Accelerated shuffle
Spark operations that sort, group, or join data by value must move data between partitions when creating a new DataFrame from an existing one between stages. The process, called a shuffle, involves disk I/O, data serialization, and network I/O. The new RAPIDS accelerator shuffle implementation leverages UCX to optimize GPU data transfers, keeping as much data on the GPU as possible. It finds the fastest path to move data between nodes by using the best of available hardware resources, including bypassing the CPU to do GPU-to-GPU memory intra- and inter-node transfers.
Accelerator-aware scheduling
As part of a major Spark initiative to better unify DL and data processing on Spark, GPUs are now a schedulable resource in Apache Spark 3.0. This allows Spark to schedule executors with a specified number of GPUs, and you can specify how many GPUs each task requires. Spark conveys these resource requests to the underlying cluster manager: Kubernetes, YARN, or Standalone. You can also configure a discovery script that can detect the GPUs that were assigned by the cluster manager. This greatly simplifies running ML applications that need GPUs, as previously you had to work around the lack of GPU scheduling in Spark applications.
Accelerated XGBoost
XGBoost is a scalable, distributed, gradient-boosted decision tree (GBDT) ML library.
XGBoost provides parallel tree boosting and is the leading ML library for regression, classification, and ranking problems. The RAPIDS team works closely with the Distributed Machine Learning Common (DMLC) XGBoost organization, and XGBoost now includes seamless, drop-in GPU acceleration.
Spark 3.0 XGBoost is also now integrated with the Rapids accelerator to improve performance, accuracy, and cost with the following features:
- GPU acceleration of Spark SQL/DataFrame operations
- GPU acceleration of XGBoost training time
- Efficient GPU memory utilization with in-memory optimally stored features
Real-world examples of accelerating end-to-end machine learning
At GTC 2020, Adobe, Verizon Media, and Uber each discussed how they used a preview version of Spark 3.0 with GPUs to accelerate and scale ML big data pre-processing, training, and tuning pipelines.
Adobe
Building on its strategic AI partnership with NVIDIA, Adobe was one of the first companies working with a preview release of Spark 3.0 running on Databricks. At the NVIDIA GTC conference, Adobe Intelligent Services provided the evaluation results of a GPU-based Spark 3.0 and XGBoost intelligent email solution to optimize the delivery of marketing messages. In initial tests, Adobe achieved a 7x performance improvement and 90 percent cost savings.
The performance gains in Spark 3.0 enhance model accuracy by enabling scientists to train models with larger datasets and retrain models more frequently. This makes it possible to process terabytes of new data every day, which is critical for data scientists supporting online recommender systems or analyzing new research data. In addition, faster processing means that fewer hardware resources are needed to deliver results, providing significant cost savings.
When asked about these advancements, William Yan, senior director of Machine Learning at Adobe said, “We’re seeing significantly faster performance with NVIDIA-accelerated Spark 3.0 compared to running Spark on CPUs. With these game-changing GPU performance gains, entirely new possibilities open up for enhancing AI-driven features in our full suite of Adobe Experience Cloud apps.”
Verizon Media
To predict customer churn for their tens of millions of subscribers, Verizon Media built a distributed Spark ML pipeline for XGBoost model training and hyperparameter tuning on a GPU based cluster. Verizon Media achieved a 3x performance improvement compared to a CPU-based XGBoost solution, enhancing their capabilities to do hyperparameter search for finding the best hyperparameters for optimized models and maximized accuracy. For more information, see GTC 2020: Democratized M pipelines and Spark Rapids based-hyperparameter tuning.
Uber
Uber applies DL across their business; from self-driving research to trip forecasting and fraud prevention. Uber developed Horovod, a distributed DL training framework for TensorFlow, Keras, PyTorch, and Apache MXNet, to make it easier to speed up DL projects with GPUs and a data parallel approach to distributed training.
Horovod now has support for Spark 3.0 with GPU scheduling, and a new KerasEstimator class that uses Spark Estimators with Spark ML Pipelines for better integration with Spark and ease of use. This enables TensorFlow and PyTorch models to be trained directly on Spark DataFrames, leveraging Horovod’s ability to scale to hundreds of GPUs in parallel, without any specialized code for distributed training. With the new accelerator-aware scheduling and columnar processing APIs in Apache Spark 3.0, a production ETL job can hand off data to Horovod running distributed DL training on GPUs within the same pipeline.
To learn more
- For more information about new Spark 3.0 features, see the Spark 3.0 release notes.
- For the RAPIDS Accelerator for Apache Spark and the getting started guide, see the spark-rapids GitHub repo.
- Databricks recently announced the availability of Spark 3.0.0 as part of Databricks Runtime 7.0 and Spark 3.0.0 with preconfigured GPU-acceleration as part of Databricks Runtime 7.0 for Machine Learning, which is also available on Microsoft Azure and AWS.
- Google Cloud recently announced the availability of a Spark 3.0 preview on Dataproc image version 2.0.
- To see a side-by-side comparison of the performance of a CPU cluster with that of a GPU cluster on the Databricks platform, see Spark 3 Demo: Comparing Performance of GPUs vs. CPUs.
- For more information, see Accelerating Apache Spark 3.0 with RAPIDS and GPUs.

