

The continuing explosive growth of AI model size and complexity means the appetite for more powerful compute solutions continues to accelerate rapidly. NVIDIA is introducing HGX-2, our latest, most powerful cloud server platform for AI and High-Performance Computing (HPC) workloads, to meet these new requirements. HGX-2 comes with multi-precision computing capabilities, allowing high-precision calculations using FP64 and FP32 for scientific computing and simulations, while also enabling FP16 and INT8 for AI training and inference.
Let’s dig deeper into the HGX-2 server architecture. We’ll also discuss how we cooperate with ecosystem partners in bringing their HGX-2 based servers to the cloud, walk through the benefits to end-user applications, and discuss platform optimizations targeted for cloud data center deployment.
HGX-2 Server Architecture
The GPU baseboard
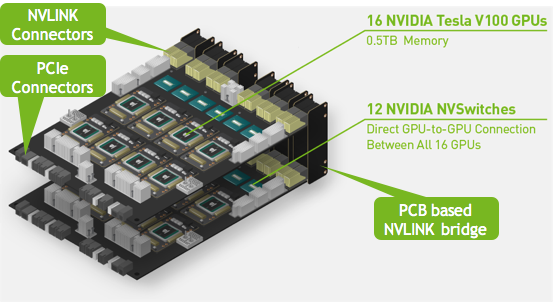
The GPU baseboard represents the key building block to the HGX-2 server platform. The baseboard hosts eight V100 32GB Tensor Core GPUs and six NVSwitches. Each NVSwitch is a fully non-blocking NVLink switch with 18 ports so any port can communicate with any other port at full NVLink speed. Each V100 Tensor Core GPU includes six NVLinks; each NVLink routes to one of the six NVSwitches. (More on the Volta GPU architecture can be found here). Each HGX-2 server platform consists of a pair of baseboards with full-speed connectivity offered via 48 NVLink ports between the two baseboards.
Figure 1 shows the logical diagram of the dual GPU baseboard sub-system. This topology enables all 16 V100 Tensor Core GPUs to be fully connected; every GPU can communicate with any other GPU simultaneously at the full NVLink speed of 300GB/s.
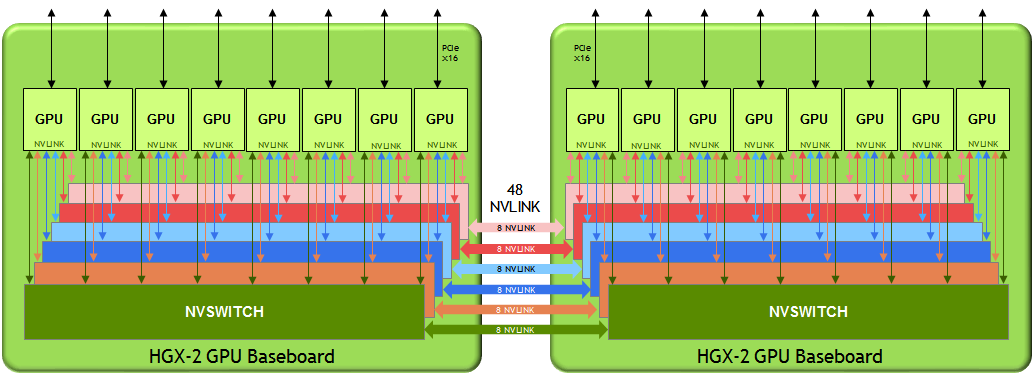
Figure 2 shows the physical implementation. The two GPU baseboards connect via passive NVLink bridge PCBs. A GPU on one baseboard still has full-bandwidth access to any GPU, including one on a different baseboard.
Putting the HGX-2 server platform together
With the GPU baseboard building block, We work with our server ecosystem partners to build the full server platform using this GPU baseboard building block. Since every cloud data center has their own unique requirements, this building-block approach enables our partners to, customize for their unique needs. For example, some data centers like to have PCIe and networking cables emerge from the front of the server to ease servicing. Other providers prefer cabling routing out the back in more traditional enterprise style. Some data centers like using a power bus bar to power the entire rack versus using an individual PSU (power supply unit) in each server.
Using the GPU baseboard approach allows us to focus on delivering the most performance optimized GPU sub-system, while our server partners focus on system-level design, such as mechanicals, power, and cooling. Partners can tailor the platform to meet the specific cloud data center requirements. This reduces our partners’ resource usage; together, we can bring the latest solution to the market much faster.
Figure 3 shows our server architecture recommendations, which enable higher performance for AI and HPC workloads.
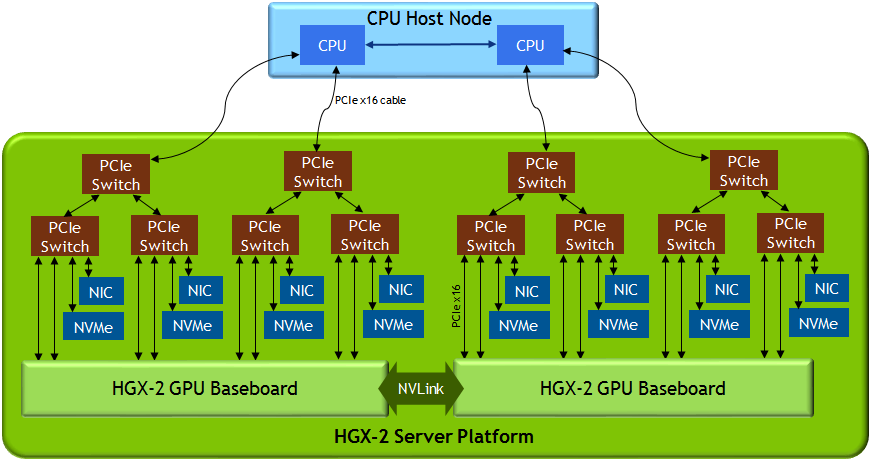
Let’s look at a few highlights of the HGX-2 architecture:
- Separate CPU host node and GPU server platform connect via PCIe cables. GPU and CPU innovate at different paces and refresh at different times. A disaggregate architecture allows CPU and GPU side to upgrade independently.
- Uses a shallow and balance PCIe tree topology. Four PCIe x16 connections from the CPU ensures sufficient bandwidth to keep the fast GPU busy.
- Places network interface card (NIC) and NVMe flash close to the GPU and uses a GPU remote DMA capable NIC. For scale-out applications, remote DMA enables any local GPU in a node to communicate with any remote GPU in another node with the lowest latency and highest bandwidth. NVIDIA designs in eight 100Gb NICs for the best multi-node scale-out performance.
The NVSwitch Advantage
The highest performance server deployed in cloud data center today implements the HGX-1 “hybrid cube mesh” architecture. The cube mesh is a carefully chosen topology to enable the best performance for HPC and AI given the available NVLinks, as figure 5 shows.
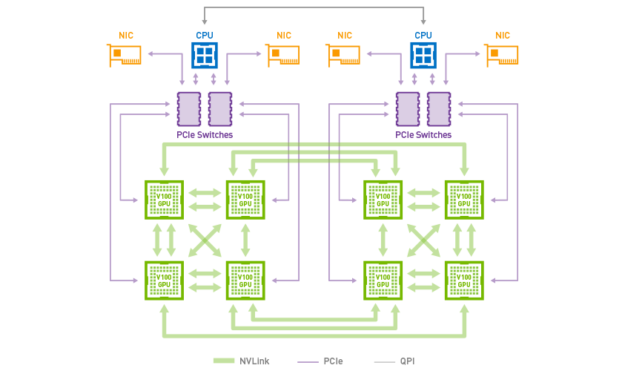
NVSwitch scales up GPU density and improves communication performance. Table 1 outlines the improvements garnered using NVSwitch instead of Hybrid Cube Mesh.
| HGX-1
Hybrid Cube Mesh |
HGX-2
with NVSwitch |
|
| # of V100 GPU | 8 | 16 |
| Tensor Core FLOPS | 1 Petaflop | 2 Petaflops |
| GPU Mem Size | 256GB | 512GB |
| 1 GPU to 1 GPU | 1 or 2 NVLink or PCIe | Always 6 NVLink |
| Fully Connected
by NVLink |
4 GPU | 16 GPU |
| Bisection Bandwidth | 300GB/s | 2,400GB/s
(48 NVLink) |
| Multi-GPU
Deep Learning |
Data Parallel All-Reduce | Faster Data Parallel All-Reduce,
Model Parallel |
Table 1. HGX-1 hybrid cube mesh vs. HGX-2 with NVSwitch
Every GPU in HGX-2 can access the entire 512GB GPU memory space at the full 300GB/s NVLink speed. This symmetric and fully connected topology makes programming easier for application developers. Developers can dedicate more time solving the science problems rather than optimizing for the underlying topology. We look forward to enabling new use cases, such as making “model parallel” and allowing multiple GPUs to work together to handle a large model, much easier to implement.
HGX-2 Application Benefit for End Users
The HGX-2 server platform enables substantial performance improvements for HPC and AI workloads. A single HGX-2 can replace 300 dual CPU server nodes on deep learning training, resulting in dramatic savings on cost, power, and data center floor space.
When compared to NVIDIA’s earlier HGX-1, the current highest performance cloud server available, we see performance gains on four key workloads, shown in figure 6. We compare two nodes of HGX-1 with 16 V100 Tensor Core GPUs, in which the two nodes interconnect with four 100Gb Infiniband connections versus a single-node HGX-2 with 16 V100 Tensor Core GPUs. Using the same GPU count allows us to isolate performance benefits with the new NVSwitch-based architecture and show an apples-to-apples comparison.
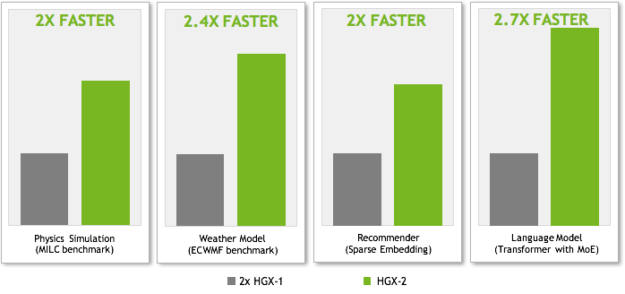
NVSwitch contributes to performance increases in several ways:
- MILC (physics simulation) and ECWMF (weather model) benchmark use high dimensional data structures, requiring significant data movement between GPUs. As the GPUs compute very rapidly, the all-to-all traffic in which each GPU communicates with every other GPU becomes the performance bottleneck. NVSwitch excels at accelerating this all-to-all traffic and speeds up the applications.
- Recommender models click-through rate prediction. This model looks up a one billion entry embedded table with 64 dimensions per entry. The embedded table is partitioned and distributed to the 16 GPU memory. The lookup results are combined across GPUs and followed by a fully connected network to make the prediction. The inter-GPU communication in this use case limits the overall performance. NVSwitch accelerates the inter-GPU transfers, minimizing the effect of this bottleneck.
- Transformer with Mixture of Experts (MoE) layers is used for language modeling. The MoE layer consists of 128 experts, each of which consists of a standalone deep neural network. The experts are distributed to different GPUs in a model parallel implementation, creating significant all-to-all traffic between the Transformer layers and the MoE layers. NVSwitch enables higher throughput and minimizes latency on the all-to-all transfers.
Optimized for Cloud Data Center Deployment
Cloud data centers wish to optimize their infrastructure for the most efficient computing. Partners want to devote higher fractions of their budget to compute and minimize overhead such as networking. The HGX-2 server platform’s 16-GPU strong node approach helps cloud data centers scale up and perform as much compute as possible, efficiently within a node first, before scaling out to multiple nodes.
When sharing a single server platform with multiple users via virtual machines, NVSwitch enables flexible partitioning while maintaining high NVLink bandwidth within each VM.
While AI and deep learning favor higher GPU density within a node, some HPC applications prefer more CPU capacity to match the fast GPU for a more balanced CPU-to-GPU ratio. The same HGX-2 server can also pair up to 2 separate CPU host nodes to become 2 logically independent servers with more CPU capacity per GPU. See figure 7 for a virtualization example and a dual CPU host nodes example.
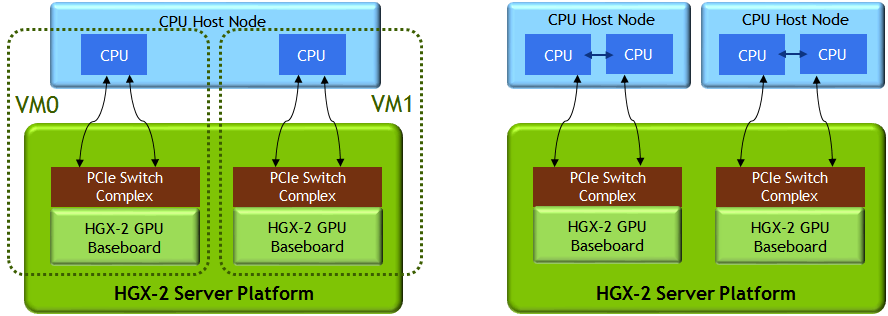
In both of these examples, the NVLink between the two GPU baseboards can be simply programmed to “Off”, enabling proper isolation between the different tenants.
Be Ready for the Future with HGX-2
A variety of server ecosystem partners will bring the HGX-2 server platform to the cloud later this year. HGX-2 will enable developers with this higher performance platform to build larger and more complex AI and HPC models while training them in less time.
You can find more information on HGX-2 on the product page here:
https://www.nvidia.com/en-us/data-center/hgx/
More details on NVSwitch capabilities can be found in the NVSwitch technical overview here:
http://images.nvidia.com/content/pdf/nvswitch-technical-overview.pdf
If you have interesting use cases, please add any feedback and comments you wish to share viathe comments section.









