Graphs are mathematical structures used to model many types of relationships and processes in physical, biological, social and information systems. They are also used in the solution of various high-performance computing and data analytics problems. The computational requirements of large-scale graph processing for cyberanalytics, genomics, social network analysis and other fields demand powerful and efficient computing performance that only accelerators can provide. With CUDA 8, NVIDIA is introducing nvGRAPH, a new library of GPU-accelerated graph algorithms. Its first release, nvGRAPH 1.0, supports 3 key graph algorithms (PageRank, Single-Source Shortest Path, and Single-Source Widest Path), and our engineering and research teams are already developing new parallel algorithms for future releases. I’ll discuss one of them in detail in this blog post.
Many applications need to partition graphs into subgraphs, or to find clusters within them. For example, graph partitioning can be used in the numerical solution of partial differential equations (PDEs) to perform more efficient sparse matrix-vector multiplications, and graph clustering can be used to identify communities in social networks and for cybersecurity (see Figure 1).

The quality of graph partitioning or clustering can have a significant impact on the overall performance of an application. Therefore it is very important not only to find the splitting into subgraphs fast by taking advantage of GPUs (our GPU spectral graph partitioning scheme performs up to 7x faster than a CPU implementation), but also to find the best possible splitting, which requires development of new algorithms.
Also, graph partitioning and clustering aims to find a splitting of a graph into subgraphs based on a specific metric. In particular, spectral graph partitioning and clustering relies on the spectrum—the eigenvalues and associated eigenvectors—of the Laplacian matrix corresponding to a given graph. Next, I will formally define this problem, show how it is related to the spectrum of the Laplacian matrix, and investigate its properties and tradeoffs.
Definition
Let a graph \(G=(V,E)\) be defined by its vertex set \(V\) and edge set \(E\). The vertex set \(V = \{1,…,n\}\) represents \(n\) nodes in a graph, with each node identified by a unique integer number \(i \in V\). The edge set \(E = \{(i_{1},j_{1}),…,(i_{e},j_{e})\}\) represents \(e\) edges in a graph, with each edge from node \(i\) to \(j\) identified by a pair \((i,j) \in E\).
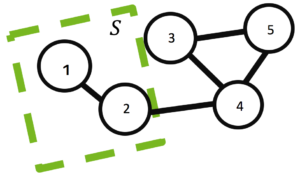
Applications often need to find a splitting of the graph into subgraphs of similar size connected by as few edges as possible. This statement is often formulated as the problem of finding a set of vertices \(S \in V\) that induces a minimum balanced cut of a graph \(G=(V,E)\) in the sense of a cost function
\(\rho(S) = \min_{S} \frac{|\partial(S)|}{|S||\bar{S}|} ,\)
where \(\bar{S}\) denotes complement of set \(S\) with respect to \(V\), \(|.|\) denotes the cardinality (number of elements) of a set, and \(\partial(S)= \{(i,j): i \in S \land j \notin S\}\) denotes the boundary of a set.
For example, a minimum balanced cut of a graph \(G=(V,E)\), with \(V=\{1,2,3,4,5\}\) and \(E=\{(1,2),(2,4),(3,4),(3,5),(4,5)\}\) induced by a set of vertices \(S=\{1,2\}\) with \(\bar{S}=\{3,4,5\}\) and boundary \(\partial(S)=\{(2,4)\}\) is shown in Figure 2.
It is important to point out that both partitioning and clustering aim to split the original graph into multiple sub-graphs. However, in partitioning the number of partitions and often their size is fixed, while in clustering the fact that there are no partitions can be a result in itself [1]. Also, the optimality of the splitting can be measured by different cost functions, including modularity, betweenness centrality, or flow.
Cost Function
I will focus on the popular ratio and normalized cut cost functions, which are variations of the minimum balanced cut of a graph \(G=(V,E)\). The ratio and normalized cut cost functions are defined as
\(\tilde{\rho}(S_{1},…,S_{p}) = \min_{S_{1},…,S_{p}} \sum_{k=1}^{p} \frac{|\partial(S_{k})|}{|S_{k}|}\)
and
\(\tilde{\eta}(S_{1},…,S_{p}) = \min_{S_{1},…,S_{p}} \sum_{k=1}^{p} \frac{|\partial(S_{k})|}{\text{vol}(S_{k})} ,\)
respectively, where set \(S_{k} \subseteq V\) for \(k=1,…,p\), the intersection of sets \(S_{k} \cap S_{j} = \emptyset\) for \(k \neq j\), and \(\text{vol}(S)=\sum_{i \in S} \text{d}(i)\) denotes the volume of a set, where \(d(i)\) is the degree (number of edges) of node \(i\).
These cost functions are simpler than they look. Notice that the numerator refers to the number of edges cut between partitions and the denominator is related to the number of elements assigned to a particular partition. For example, in distributed sparse matrix-vector multiplication, the numerator relates to the number of elements that must be sent between partitions and the denominator to the work done per partition, measured in terms of the number of rows in the former or number of non-zero elements in the latter equation.
Also, it turns out that it is possible to express these cost functions as
\(\tilde{\rho}(S_{1},…,S_{p}) = \min_{S_{1},…,S_{p}} \sum_{k=1}^{p} \textbf{u}_{k}^{T} L \textbf{u}_{k} = \min_{U^{T}U=I} \text{Tr} (U^{T} L U)\)
and
\(\tilde{\eta}(S_{1},…,S_{p}) = \min_{S_{1},…,S_{p}} \sum_{k=1}^{p} \textbf{u}_{k}^{T} L \textbf{u}_{k} = \min_{U^{T}DU=I} \text{Tr} (U^{T} L U) ,\)
where tall matrix \(U=[\textbf{u}_{1},…,\textbf{u}_{p}]\), \(I \in \mathbb{R}^{p \times p}\) is the identity matrix and \(\text{Tr}(.)\) is the trace of a matrix (the sum of its diagonal elements). Here vectors \(\textbf{u}_{k}\) take only discrete values, with non-zeroes corresponding to indices in the set \(S_{k}\), while \(L\) is the Laplacian matrix, which will be defined next.
Laplacian Matrix
The Laplacian matrix is defined as \(L=D-A\), where \(A \in \mathbb{R}^{n \times n}\) is the adjacency matrix of the graph \(G=(V,E)\) and the diagonal matrix \(D = \text{diag}(A\textbf{e})\), where vector \(\textbf{e}=(1,…,1)^{T}\).
For example, the Laplacian matrix for the graph \(G=(V,E)\) shown ing Figure 2 can be written
\(\begin{bmatrix} 1 & -1 & & \\ -1 & 2 & & -1 & \\ & & 2 & -1 & -1 \\ & -1 & -1 & 3 & -1 \\ & & -1 & -1 & 2 \end{bmatrix} = \begin{bmatrix} 1 & & & & \\ & 2 & & & \\ & & 2 & & \\ & & & 3 & \\ & & & & 2 \end{bmatrix} – \begin{bmatrix} & 1 & & & \\ 1 & & & 1 & \\ & & & 1 & 1 \\ & 1 & 1 & & 1 \\ & & 1 & 1 & \end{bmatrix}\)
The Laplacian matrix has very interesting properties. To illustrate it, let the set \(S=\{1,2\}\) as shown in Figure 2 and vector \(\textbf{x}\) be such that it has 1 at position \(i \in S\) and zero otherwise. Then, I can express the cardinality \(|S|\), volume \(\text{vol}(S)\) as well as the cardinality of the boundary \(|\partial(S)|\) of the set \(S\) using the vector \(\textbf{x}\) and the Laplacian matrix \(L\) in the following way.
\(|S|=\textbf{x}^{T}\textbf{x}= \begin{bmatrix} 1 & 1 & & & &\end{bmatrix}\begin{bmatrix} 1 \\ 1 \\ \\ \\ \\ \end{bmatrix} = 2\)
\(\text{vol}(S) =\textbf{x}^{T}D\textbf{x} = \begin{bmatrix} 1 & 1 & & & &\end{bmatrix}\begin{bmatrix} 1 & & & & \\ & 2 & & & \\ & & 2 & & \\ & & & 3 & \\ & & & & 2 \end{bmatrix}\begin{bmatrix} 1 \\ 1 \\ \\ \\ \\ \end{bmatrix} = 3\)
\(|\partial(S)|=\textbf{x}^{T}L\textbf{x} = \begin{bmatrix} 1 & 1 & & & &\end{bmatrix}\begin{bmatrix} 1 & -1 & & \\ -1 & 2 & & -1 & \\ & & 2 & -1 & -1 \\ & -1 & -1 & 3 & -1 \\ & & -1 & -1 & 2 \end{bmatrix}\begin{bmatrix} 1 \\ 1 \\ \\ \\ \\ \end{bmatrix} = 1\)
This illustrates why in the previous section I could express all the terms in the ratio and normalized cost functions in terms of vector \(\textbf{x}\) and the Laplacian matrix \(L\). A more detailed explanation is given in our technical report [2].
Key Idea of Spectral Scheme
Notice that obtaining the minimum of the cost function by finding the best non-zero discrete values for the vector \(\textbf{u}\) is no easier than finding the best indices for the set \(S\). The two formulations of the cost functions are equivalent and both are NP-hard problems.
The key idea of spectral partitioning and clustering is not to look for the discrete solution directly, but instead to do it in two steps.
First, relax the discrete constraints and let vector \(\textbf{u}\) take real instead of discrete values. In this case, following the linear algebra Courant-Fischer theorem (sometimes referred to as the Min-Max theorem), the minimum of the cost function is obtained by the eigenvectors associated with the \(p\) smallest eigenvalues of the Laplacian matrix.
Second, map the obtained real values back to the discrete ones to find the solution of interest. This step can be done using simple heuristics, such as sorting and looking for a gap in the real values, or using more advanced multi-dimensional algorithms, such as the k-means algorithm. In the former case all real values in between gaps, while in the latter case all real values clustered around a particular centroid, will be assigned the same discrete value and therefore will belong to the same particular partition or cluster.
There is no guarantee that the two-step approach will find the best solution, but in practice it often finds a good enough approximation and works reasonably well.
Figure 3 provides a visual outline of the process and Algorithm 1 presents the algorithm in pseudocode.
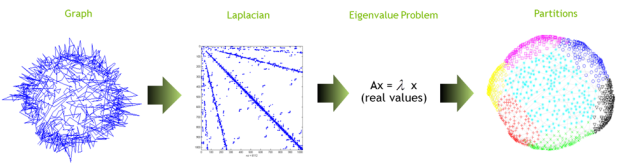
Let G=(V,E) be an input graph Let A be the adjacency matrix of G Let diagonal matrix D = diag(Ae) Set the Laplacian matrix L=D-A Solve the eigenvalue problem L u = λu Use heuristics to transform real into discrete values
Eigenvalue Problem
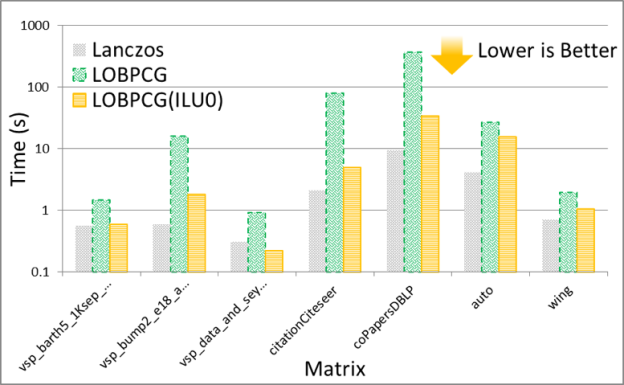
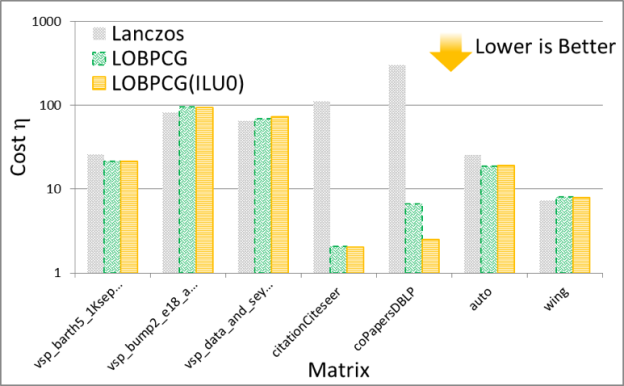
The solution of the eigenvalue problem is often the most time consuming part of spectral graph partitioning /clustering. There are many eigenvalue solvers that can be used to solve it, including Lanczos, Tracemin, Jacobi-Davidson and LOBPCG. In particular, Figures 3 and 4 show experimental results comparing the performance and quality, respectively, of the Lanczos and LOBPCG methods when looking for the 30 smallest eigenvectors of a few matrices from the DIMACS graph collection. Although Lanczos is often the fastest eigenvalue solver, when incomplete-LU with 0 fill-in (ILU0) is available, the preconditioned LOBPCG eigenvalue solver can be competitive and often computes a superior-quality solution.
Experiments
Now I’ll compare the spectral scheme on the GPU with the spectral scheme implemented on the CPU in the CHACO software package. The experiments are performed on a workstation with a 3.2 GHz Intel Core i7-3930K CPU and an NVIDIA Tesla K40c GPU.
The schemes are very similar, but not identical because CHACO has a slightly different implementation of the algorithms, and also attempts to provide a load-balanced cut within a fixed threshold \(\epsilon\), so that for instance \(|S_{k}| \le (1+\epsilon)|V|/p\). Therefore, CHACO’s cost function is similar to the ratio cut, but the clustering at the end is biased towards providing a load-balanced partitioning, while still minimizing the edge cuts. Also, CHACO implements spectral bisection, so when comparing to it I split the graph into only two partitions.
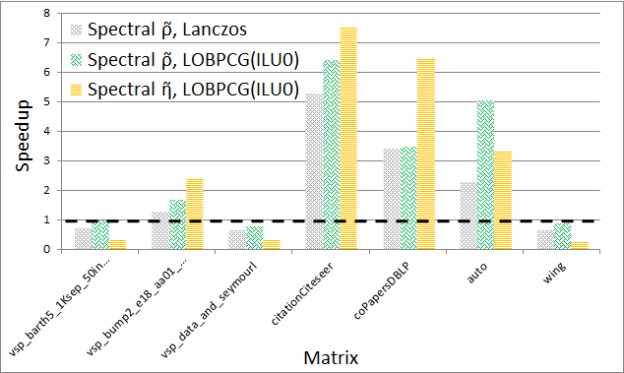
Figures 5 and 6 show the performance and quality of both spectral schemes, respectively. Notice that the GPU spectral scheme using Lanczos often obtains the solution faster, but with variable quality compared to the CPU spectral scheme in CHACO, which also uses a variation of the Lanczos method. On the other hand when using preconditioned LOBPCG the GPU implementation is usually faster, and most of the time obtains a higher quality solution as measured by the cost functions. The detailed results of these experiments can be found in our technical report [2].
Finally, as mentioned earlier there exist many different partitioning and clustering strategies. In particular, some of the popular approaches for providing a balanced cut of a graph use multi-level schemes, implemented in software packages such as METIS. Both spectral and multi-level schemes are global methods that work on the entire graph, in contrast to local heuristics, such as the Kernighan-Lin algorithm.
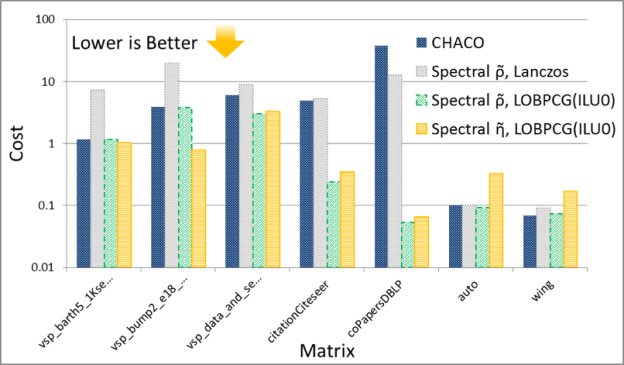
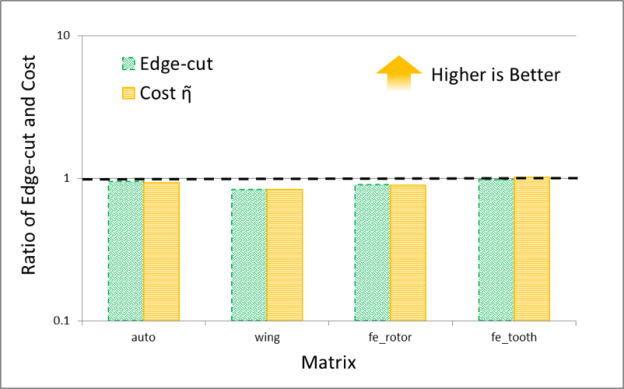
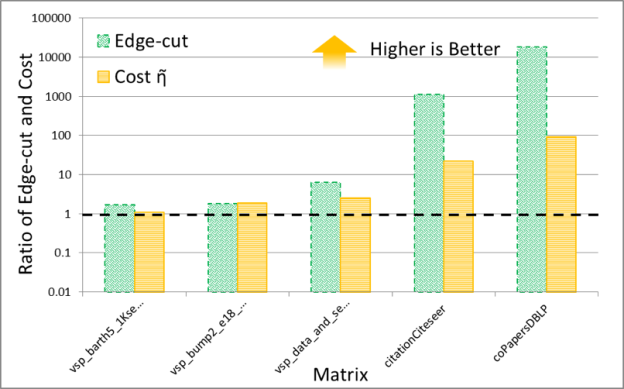
It is interesting to compare the quality of spectral and multi-level schemes in terms of the the edge-cut and cost function obtained by them. The numerical experiments shown in Figures 7 and 8 plot the ratio of these quantities (the cost obtained by METIS divided by the cost obtained by the GPU spectral scheme), for 30 partitions. The result trends indicate that the behavior of the spectral and multi-level schemes is starkly different for two classes of problems: (i) meshes arising from discretization of PDEs and (ii) social network graphs that often have power-law-like distributions of edges per node. My conjecture is that the difference in quality between these schemes results from the fact that multi-level schemes often rely on local information to construct a graph hierarchy that is used to partition the graph.
Notice that for PDEs the quality of the partitioning obtained by both schemes is essentially the same, while for networks with high degree nodes, such as social networks, spectral schemes can obtain significantly higher quality partitions. Even though in our experiments the time taken by the spectral schemes is often larger than that taken by the multi-level schemes, I think that spectral schemes can be a good choice in applications where quality is important. For example, in sparse linear algebra applications, even modest improvements in the quality of partitioning can lead to a significant impact on the overall application performance, so the extra partitioning cost of a spectral scheme may be worthwhile.
Conclusion
I hope that after reading this blog post you have learned some of the intuition behind the spectral graph partitioning/clustering scheme and how it compares to other similar algorithms. A more formal treatment of the subject, with precise derivation of the theoretical results and detailed numerical experiments, can be found in our technical report [2].
The numerical experiments show that spectral partitioning on GPUs can outperform spectral partitioning on the CPU by up to 7x. Also, it is clear that multi-level schemes are a good choice for partitioning meshes arising from PDEs, while spectral schemes can achieve high quality partitioning and clustering on network graphs with high-degree nodes, such as graphs of social networks.
If you need to accelerate graph algorithms in your applications, check out the new GPU-accelerated nvGRAPH library. You can also read more about nvGRAPH in the post “CUDA 8 Features Revealed”. We are considering adding spectral partitioning to nvGRAPH in the future. Please let us know in the comments if you would find this useful.
A Note on Drawing Graphs
Finally, note that eigenvectors of the Laplacian matrix have many other applications. For example, they can be used for drawing graphs. In fact, the graph drawings in this blog were done with them. The interpretation of eigenvectors for this application has been studied in [3].
References
[1] M.E.J. Newman, “Modularity and Community Structure in Networks”, Proc. National Academy of Science, Vol. 103, pp. 8577–8582, 2006.
[2] M. Naumov and T. Moon, “Parallel Spectral Graph Partitioning”, NVIDIA Research Technical Report, NVR-2016-001, March, 2016.
[3] Y. Koren, “Drawing Graphs by Eigenvectors: Theory and Practice”, Computers & Mathematics with Applications, Vol. 49, pp. 1867–1888, 2005.