
Navigating a new indoor space without any prior knowledge or even a map is a challenging task for a human, let alone a robot.
To help develop intelligent machines that interact more effectively with complex 3D environments, Facebook researchers developed a GPU-accelerated deep reinforcement learning model that achieves near 100 percent success in navigating a variety of virtual environments without a pre-provided map.
To achieve this breakthrough, the team focused their work on developing an efficient approach to scaling RL models, which require a significant number of training samples, using multi-node distribution.
“A single parameter server and thousands of (typically CPU) workers may be fundamentally incompatible with the needs of modern computer vision and robotics communities,” the researchers explained in their post, Near-perfect point-goal navigation from 2.5 billion frames of experience. “Unlike Gym or Atari, 3D simulators require GPU acceleration…. The desired agents operate from high-dimensional inputs (pixels) and use deep networks, such as ResNet50, which strain the parameter server. Thus, existing distributed RL architectures do not scale and there is a need to develop a new distributed architecture.”
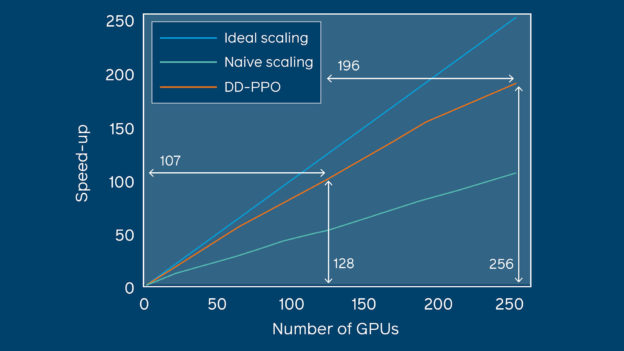
Using NVIDIA V100 GPUs, with the cuDNN-accelerated PyTorch deep learning framework, and the NVIDIA Collective Communications Library (NCCL) in the backend, the researchers achieved a speedup of 107x over a serial implementation, by training their model on over 2.5 billion frames of experience.
“We leverage this scaling to train an agent for 2.5 billion steps of experience (the equivalent of 80 years of human experience) – over 6 months of GPU-time training in under 3 days of wall-clock time with 64 GPUs,” the researchers stated in their paper, Decentralized Distributed PPO: Solving PointGoal Navigation, to be presented at ICLR 2020 in Ethiopia later this year.
In the paper, the team describes their decentralized method for scaling policy optimizations, aptly named Decentralized Distributed Proximal Policy Optimization (DD-PPO).
In DD-PPO, each virtual agent alternates between collecting experience in a resource-intensive and GPU-accelerated simulated environment and optimizing the model.
Previous systems achieved a 92% success rate on these tasks. However, failing in the physical world can have serious ramifications, such as damaging a robot or its surroundings.
“DD-PPO-trained agents reach their goal 99.9 percent of the time. Perhaps even more impressively, they do so with near-maximal efficiency, choosing a path that comes within 3 percent (on average) of matching the shortest possible route from the starting point to the goal,” the Facebook researchers stated in their newly published post on the Facebook AI blog.
“It is worth stressing how uncompromising this task is. There is no scope for mistakes of any kind — no wrong turn at a crossroads, no backtracking from a dead-end, no exploration or deviation of any kind from the most direct path.”
The Facebook team trained and evaluated their model using the AI Habitat platform, an open source modular framework with a highly performant and stable simulator.
“Reaching billions of steps of experience not only sets the state of the art on the Habitat Autonomous Navigation Challenge 2019 but also essentially solves the task,” the researchers said. “It achieves a success rate of 99.9 percent and a score of 96.9 percent on the SPL efficiency metric. (SPL refers to success rate weighted by normalized inverse path length.)”
The team says they hope to build on DD-PPO’s success by creating systems that accomplish point-goal navigation with only the camera input, and no compass or GPS data.
In addition to their in-depth explainer post, Near-perfect point-goal navigation from 2.5 billion frames of experience, the researchers have made the code publicly available on GitHub.