
Accurately annotated datasets are crucial for camera-based deep learning algorithms to perform autonomous vehicle perception. However, manually labeling data is a time-consuming and cost-intensive process.
We have developed an automated labeling pipeline as a part of the Tata Consultancy Services (TCS) artificial intelligence (AI)-based autonomous vehicle platform. This pipeline uses NVIDIA DGX A100 and the TCS feature-rich semi-automatic labeling tool for review and correction. This post explains the design of the labeling pipeline, how NVIDIA DGX A100 accelerates labeling, and the savings achieved by implementing an auto labeling process.
Designing an auto labeling pipeline
An auto labeling pipeline must be able to generate the following annotations from images downloaded in a network storage drive:
- 2D object detection with visibility attributes (such as fully visible and occluded)
- 3D object detection with visibility attributes (such as fully visible and occluded)
- lane detection with attributes (such as lane classification and lane color)
We designed and trained customized deep neural networks (DNN) for 2D object detection, 3D object detection, and lane detection tasks. However, when testing the outputs from detectors for auto labeling purposes, we observed minor missed detections. This added more work for people performing the labeling. Additionally, assigning attributes per object or lane took a considerable amount of time.
To fix these issues, we added an effective tracking algorithm that provides track identifications to all the detections. The algorithm, coupled with an enhanced copy-by-track-ID feature in the TCS semi-automatic labeling tool, helps correct attributes or detections with the same track ID.
The correction in one frame is replicated to subsequent frames where the track ID is the same, thereby accelerating the corrections. The end-to-end pipeline consists of the following additional modules:
- 2D object tracker
- lane tracker
Optimizing the pipeline
Due to the interdependencies between the underlying modules, all the modules cannot run in parallel. As a solution, we divided the entire pipeline execution into three stages to enable the parallel execution of modules.
The input to the pipeline is a sequence of 206 images, each having a resolution of 1920 x 1280 pixels. The timings provided in Figures 1, 2, and 3 are based on the batch processing for each module.
Initially, with the base version for the pipeline, the end-to-end execution time of a batch was 16 minutes and 40 seconds, or 4.854 seconds per frame, when deployed on an NVIDIA DGX A100 GPU.
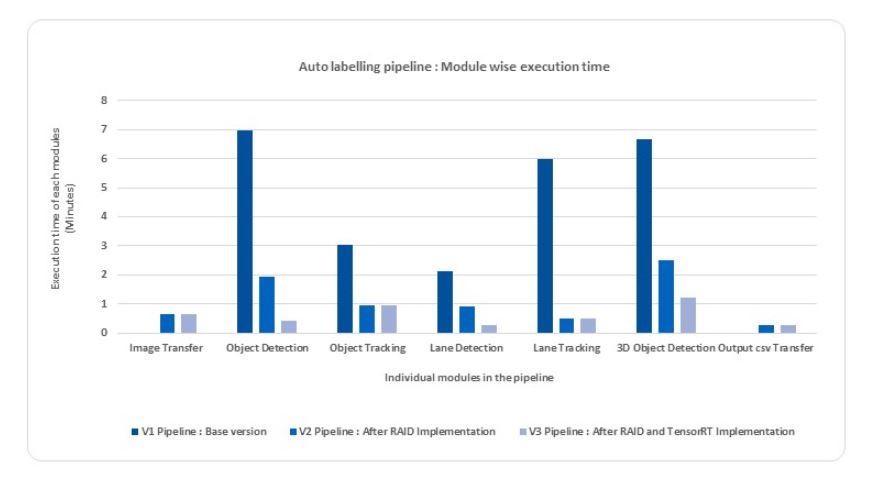
Figure 1 shows the module-wise time profiling for the base version. This execution time includes reading the image from the network drive where the raw images are stored, processing all the pipeline modules, and saving the automated annotations to the network drive.
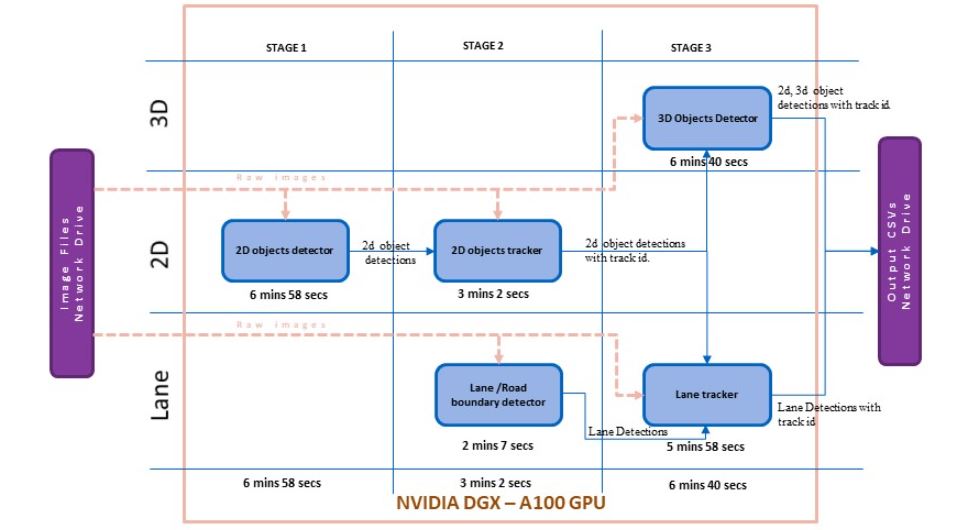
A time profiler analyzed the processing time, showing that the reading of raw images from the network drive is considerably high. The modules use raw images as one of the inputs, and the latency in reading images from the network drive results in huge overhead for the entire pipeline execution.
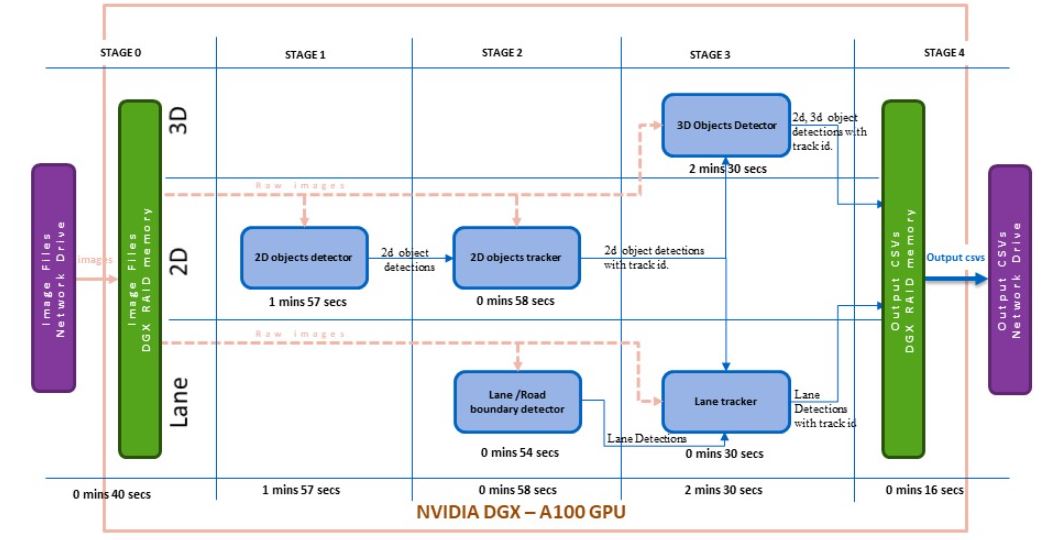
The DGX RAID memory was set up as an intermediate storage for the second version of the pipeline. In stage 0, all the raw images are read from the network drive to the DGX RAID memory (Figure 2).
The modules load the raw images from the RAID memory and all the outputs are stored in the RAID memory. After the pipeline execution, the final annotated outputs are moved to the network drive.
The total execution time of a batch of 206 images with version 2 of the pipeline was reduced to 6 minutes 21 seconds or 1.84 seconds per frame. Figure 2 shows the module-wise time profiling for version 2 of the pipeline.
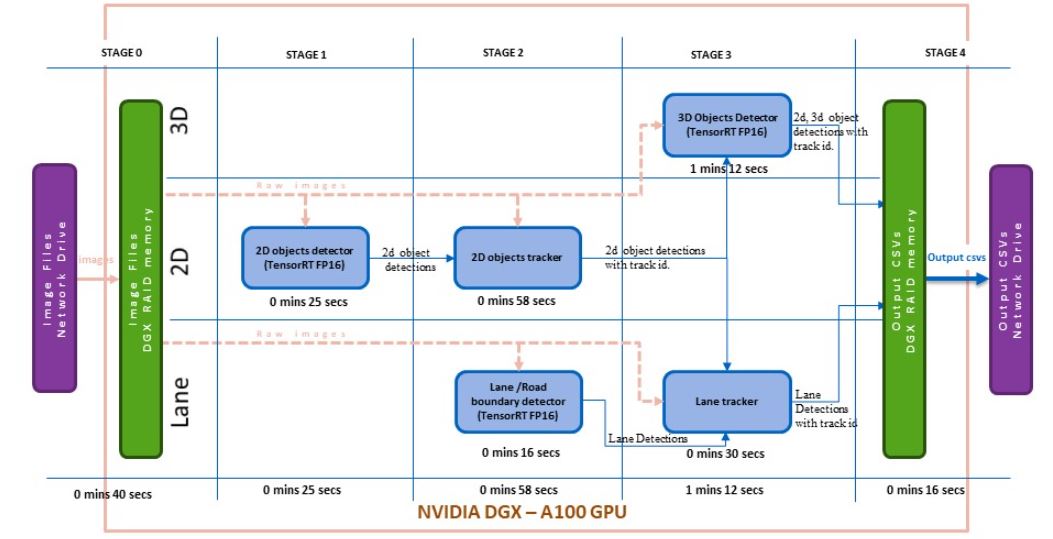
Version 3 of the pipeline uses an NVIDIA NGC container with TensorFlow 2.5 and NVIDIA CUDA 11.4.1 (tensorflow:21.08-tf2-py3). PyTorch was installed to meet the dependencies of the underlying DNN modules. GPU-supported OpenCV was built from the source, on top of this base image.
The core deep learning algorithms required further acceleration to reach the desired processing time. By leveraging NVIDIA TensorRT 8.0.1.6 in the NGC Docker, the lane detection model, the 2D object detection model, and the 3D object detection model were all transformed into FP16 TensorRT models and implemented in version 3 of the pipeline.
As a result, the pipeline’s end-to-end execution time dropped to 3 minutes 30 seconds for 206 frames, or 1.01 seconds per frame. Figure 3 shows the module-wise time profiling for version 3. We achieved the results without compromising the required accuracy of the models. Figure 4 shows results from this auto labeling pipeline.
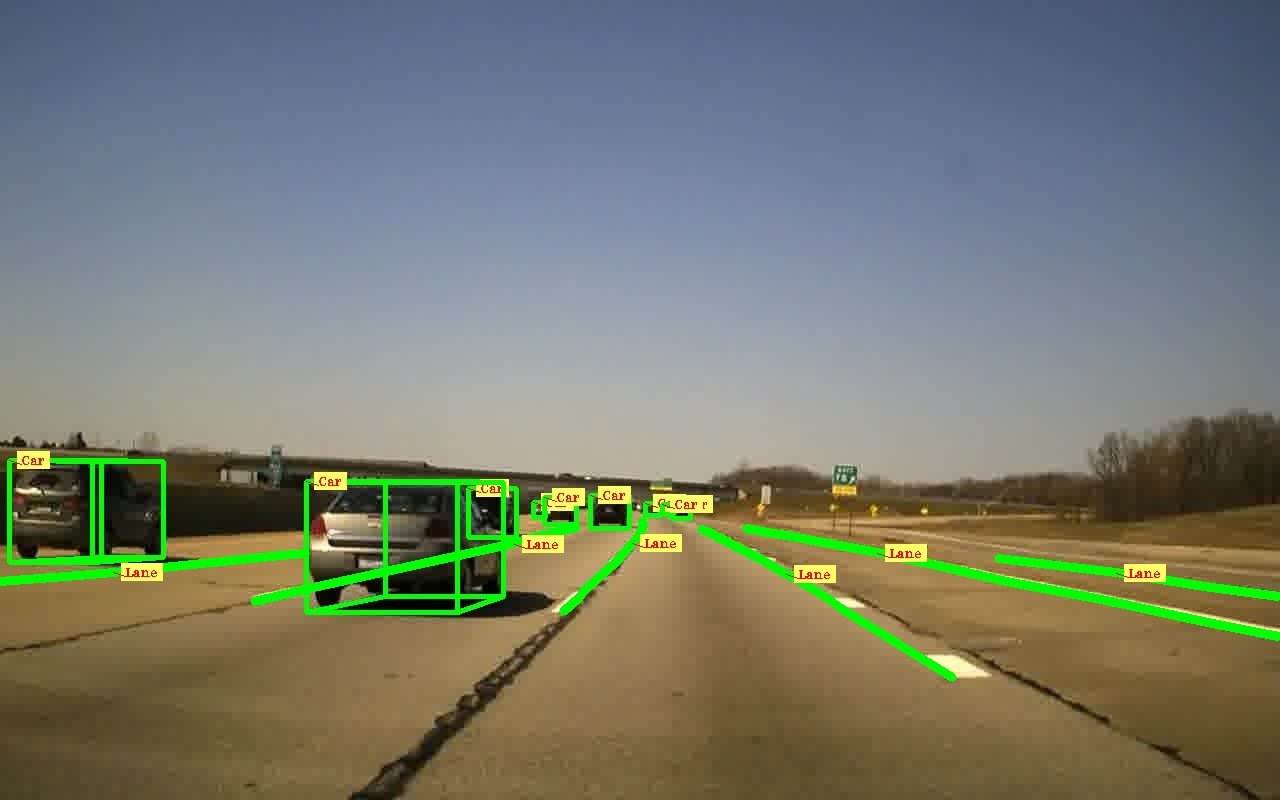
The processing time savings per module during the end-to-end execution of the pipeline is shown in Figure 5. With one NVIDIA A100 40 GB GPU in NVIDIA DGX, the deep learning algorithms were optimized to reduce overhead of model loading time, resulting in greater savings to achieve the required scale-up for round-the-clock auto labeling.
Conclusion
With the compute performance of the NVIDIA DGX A100 GPU, along with TCS expertise in AI and deep learning algorithm deployment, we developed a highly efficient auto labeling pipeline for AV camera perception algorithms. Effective utilization of the DGX RAID memory and NVIDIA TensorRT reduced the processing time of the auto labeling pipeline to one-fourth of the total time.
Deploying this auto labeling pipeline for a global automotive component supplier achieved a 65% reduction in manual efforts, compared to state-of-the-art open models such as YOLOX and LaneNet, which provided just a 34% reduction.
Want to learn more? Register for NVIDIA GTC 2023 for free and join us March 20–23 for Developing Robust Multi-Task Models for AV Perception. Check out the targeted session tracks for autonomous vehicle developers, including mapping, simulation, safety, and more.
