Parallel Compiler Assisted Software Testing (PCAST) is a feature available in the NVIDIA HPC Fortran, C++, and C compilers. PCAST has two use cases. The first is testing changes to parts of a program, new compile-time flags, or a port to a new compiler or to a new processor. You might want to test whether a new library gives the same result, or test the safety of adding OpenMP parallelism, enabling autovectorization (-Mvect=simd), or porting from an X86 system to OpenPOWER or Arm. This use case works by adding pcast_compare calls or compare directives to your application at places where you want intermediate results to be compared. Those results are saved in a golden file in the initial run, where you know the results are correct. During the test runs, the same calls or directives compare the computed intermediate results to the saved results and report differences.
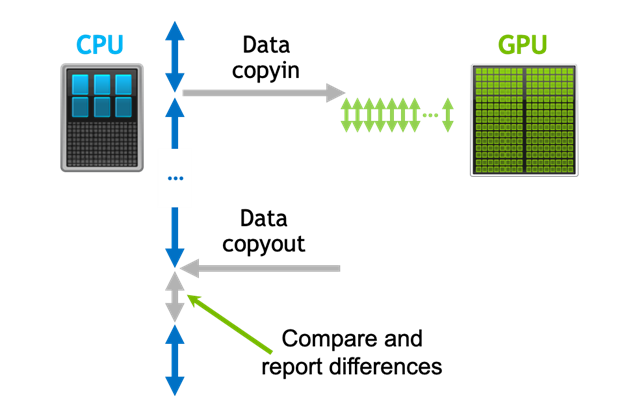
The second use case is specific to the NVIDIA OpenACC implementation. This compares the GPU computation against the same program running on the CPU. In this case, all compute constructs are done redundantly, on both CPU and GPU. The GPU results can then be compared against the CPU results and the differences reported.
PCAST with a golden file
In this use case, good results are saved to a golden file, and test results compared against those. This is done by adding pcast_compare calls or compare directives to your program. It is controlled by the PCAST_COMPARE environment variable. The following code example shows a procedure that calls a solver:
void solve(double* a, double* b, double* r, int* pivot, int n){
int fail;
dgesv(n, 1, a, n, pivot, b, n, &fail);
}
....
solve(a, b, r, pivot, n);
You want to compare the results against the NAG version:
#include
void solve(double* a, double* b, double* r, int* pivot, int n){
NagError fail;
nag_dgesv(NAG_RowMajor, n, 1, a, n, pivot, b, n, &fail);
}
....
solve(a, b, r, pivot, n);
You can use PCAST to save and compare these results by adding one, two, or three pcast_compare calls or compare directives after the call to solve. In this case, you might want to compare the results in the b vector, as well as the LU decomposition of the a matrix and the pivot index vector. This is done easily with directives:
solve(a, b, r, pivot, n);
#pragma pcast compare(b[0:n])
#pragma pcast compare(a[0:n*n])
#pragma pcast compare(pivot[0:n])
Alternatively, you can insert direct calls to pcast_compare:
solve(a, b, r, pivot, n);
pcast_compare(b, "double", n, "b", "solve.c", "myfunc", 1);
pcast_compare(a, "double", n*n, "a", solve.c", "myfunc", 2);
pcast_compare(pivot, "int", n, "pivot", solve.c", "myfunc", 3);
- The first argument to
pcast_compareis the address of the data to be saved or compared. - The second argument is a string containing the data type, here double precision.
- The third argument is the number of elements to compare.
- The next three arguments are strings which
pcast_comparetreats as the variable name, source file name, and function name where the call appears. - The last argument is an integer, which
pcast_comparetreats as a line number.
You can, of course, use any strings or value for the last four arguments; they are only used for output and to ensure that the same sequence of calls is made in the test run as was made in the first golden run.
The data types supported by PCAST include the basic numeric types for C, C++, and Fortran:
float,real,real(4)double,double precision,real(8)complex,float _Complexdouble _Complex,complex(8)shortint,integer,integer(4)long,integer(8)unsigned shortunsigned intunsigned long
The compare directive or pcast_compare call writes to or reads from a golden data file, which is named pcast_compare.dat by default. If the file does not exist, the runtime assumes that this is the first golden run, creates the file, and fills it with the computed data. If the file exists, the runtime assumes that this is a test run, reads the file, and compares the computed data with the saved data from the file.
You can change the name of the file with the PCAST_COMPARE environment variable. The default behavior is to consider any difference, no matter how small, to be an error and to report the first 50 differences. The PCAST_COMPARE environment variable can be used to tolerate small differences, or to change what output is generated.
PCAST with OpenACC and Autocompare
For OpenACC programs, PCAST includes an option to simplify the testing of the GPU kernels against the corresponding CPU code. When enabled, the compiler generates both CPU and GPU code for each compute construct. At runtime, both the CPU and GPU versions run redundantly. The CPU code reads and modifies values in system memory, and the GPU reads and modifies values in device memory. You can then insert calls to acc_compare at points where you want to compare the GPU-computed values against those computed by the CPU. Essentially, this method treats the CPU code as computing the golden values. Instead of writing and reading a file, it computes and compares the values in memory. The redundant CPU+GPU code generation mode is enabled with -gpu=redundant.
An even more interesting and semi-automatic method is to allow the runtime to automatically compare values when they are downloaded from device memory. This is enabled with the -gpu=autocompare compiler flag, which also enables the redundant option. This runs each compute construct redundantly on CPU and GPU and compares the results, with no changes to the program itself.
The following code example tests the results of a matrix or vector product:
void matvec(double* a, double* x, double* v, int n){
#pragma acc parallel loop copyin(a[0:n*n], x[0:n]) copyout(v[0:n])
for (int i = 0; i < n; ++i) {
double r = 0.0;
#pragma acc loop reduction(+:r)
for (int j = 0; j < n; ++i)
r += a[i*n+j] * x[j];
v[i] = r;
}
}
If you build this program with the -acc=gpu flag, without autocompare, the generated code performs the following sequence of operations:
- Allocate space for
a,x, andv. - Copy the input values for
aandxfrom host to device memory. - Launch the compute kernel on the device.
- Copy the output values for
vfrom device memory back tovin host memory. - Deallocate space for
a,x, andv.
If instead you build with the -acc=gpu:autocompare flag, the sequence of operations is as follows:
- Allocate space for
a,x, andv. - Copy the input values for
aandxfrom host to device memory. - Launch the compute kernel on the device.
- Redundantly execute the loop on the CPU.
- Download the GPU-computed values for
vfrom device memory back to temporary memory. - Compare the downloaded values with those computed by the CPU.
- Deallocate space for
a,x, andv.
The compiler and OpenACC runtime know the datatype, and the number of elements comes from the data clauses. The result is like a pcast_compare call on the downloaded data. In fact, the comparisons can be controlled by the same PCAST_COMPARE environment variable as for PCAST with a golden file. For more information, see the PCAST_COMPARE environment variable section later in this post.
The autocompare feature only compares data when it would get downloaded to system memory. To compare data after some compute construct that is in a data region, where the data is already present on the device, there are three ways to do the comparison at any point in the program.
First, you can insert an update self directive to download the data to compare. With the autocompare option enabled, any data downloaded with an update self directive will be downloaded from the GPU and compared to the values computed on the host CPU. In this example, inserting the following directive would do the compare:
...
v[i] = r;
}
#pragma acc update host(v[0:n])
}
Alternatively, you can add a call to acc_compare, which compares the values then present on the GPU with the corresponding values in host memory. The acc_compare routine has only two arguments: the address of the data to be compared and the number of elements to compare. The data type is available in the OpenACC runtime, so doesn’t need to be specified. In this example, the call is as follows:
...
v[i] = r;
}
acc_compare(v, n);
}
You can call acc_compare on any variable or array that is present in device memory. You can also call acc_compare_all with no arguments to compare all values that are present in device memory against the corresponding values in host memory. These only work in conjunction with -gpu=redundant or autocompare, where all the compute constructs are executed on both CPU and GPU and the values are expected to be the same.
Finally, you can use the new acc compare directive:
...
v[i] = r;
}
#pragma acc compare(v[0:n])
}
PCAST_COMPARE environment variable
The PCAST_COMPARE environment variable has several useful settings to control PCAST. You can assign multiple settings separated by commas, such as in the following command:
export PCAST_COMPARE=rel=5,summary,file=myfile.dat
The PCAST_COMPARE options are listed below. The first three file options below do not apply to OpenACC autocompare or acc_compare.
file=name—Use this filename when writing and reading a golden file.create—Create the golden file, even if it already exists.compare—Compare results against the golden file. If the file does not exist, issue an error message.report=n—Report up to n differences; the default is 50.stop—Stop after finding one data block with differences.summary—Print a summary of comparisons at the end of the run.abs=n—Tolerate or ignore differences for floating-point data when the absolute differenceabs(a-b)is less than10^(-n).rel=n—Tolerate ignore differences for floating-point data when the relative differenceabs((a-b)/a)is less than10^(-n).ieee—Report differences in IEEE NaN values as well.
The pcast_compare.dat file can be huge. It doesn’t take many iterations of a loop containing writes of a large data structure to create files of many gigabytes. Writing and rereading this file can be correspondingly slow as well. For large applications, we recommend that you use the pcast_compare call or the PCAST compare directive sparingly and then dial in when differences start to appear.
The comparisons are not done in a thread-safe fashion, and the comparisons do not consider which thread is doing the comparison. When adding PCAST to a program running with multiple host threads, you should choose one thread to do the comparisons. When adding PCAST to an MPI program using a golden file, the multiple MPI ranks writes or reads the same file unless you have a script to rename the file using PCAST_COMPARE with the MPI rank encoded in the file name.
There is currently no facility to compare results after changing datatypes. For instance, you might want to know whether your results are significantly different after reducing from double to single precision. PCAST has no way to compare a double precision value from a golden file against a single precision value computed in the test run. Currently, PCAST has no way to compare structs or derived types, unless they can be compared as arrays.
When using OpenACC autocompare or redundant execution with acc_compare, you can’t use CUDA Unified Memory or the -gpu=managed option. The OpenACC PCAST comparison depends on having the GPU doing its computations into device memory, separate from the CPU doing the redundant computation in host memory.
If you have some computation or data movement outside of the control of OpenACC that affects only host or only device memory, you have to account for that when using PCAST. For instance, an MPI data transfer to host memory would have to be copied to the device. If you use CUDA-aware MPI and do an MPI data transfer directly between two GPUs, then the host memory values are stale and must be updated. Similarly, if you have any cuBLAS or cuSolver calls on the device, then the host memory values are stale. This is likely where you have the OpenACC host_data construct, which says that something in device memory is being processed.
Important considerations
Even when the modified program is correct, there can be differences in the computed results, especially for floating-point data. Differences may arise if the modification changes the way some intrinsic function is implemented. This is very possible when moving to a new processor or using a different compiler.
Differences may also arise if the modified program uses fused-multiply-add (FMA) instructions differently than the original program. FMA instructions compute (A*B)+C in a single instruction. The difference between the FMA result and the result from a multiply followed by an add instruction is that the FMA intermediate product A*B is not rounded before being added to C. In fact, the FMA intermediate result carries more significant bits to the addition, so you could argue that the result is better, for some definition of better, but the point is that it’s different.
Differences can also arise for parallel operations in several ways. Atomic operations may occur in a different order each time that you run a parallel program. Parallel reductions, especially parallel sums, accumulate results in a different order than the sequential program, resulting in a different roundoff error.
Given the potential for differences, it’s important to distinguish significant differences from insignificant ones. It’s no longer reasonable to require that all floating-point computations be bit-exact after modifying the program. Only you can determine when a difference is significant, or how big a difference must be to be significant. There is a lot of ongoing work to identify and isolate all these causes of differences, and even workshops dedicated to this. Hopefully, this will eventually result in more automation of this process and less work for the programmer.
As I write this, there is one known limitation with the OpenACC redundant execution and autocompare. A compute construct with an if clause is not properly executed redundantly on both CPU and GPU, even when the condition is true.
Future directions
We are exploring compressing the generated data file, which addresses the file size issue at the cost of some additional compute time. We would like to explore doing the comparisons themselves in parallel, either on the CPU, or when using OpenACC, comparing on the GPU. We would also like to allow struct and derived types.
Because PCAST is designed for testing and debugging programs, we’d like to work on ways to control the frequency of the comparisons. Perhaps to be able to use the PCAST_COMPARE environment variable to specify a filename or function name, and only actually do the comparisons in that file or that function. Especially with the directive interface, this could allow one to leave the directives in the program, and to start the debug process with coarse, infrequent comparison. If some difference arises after calling some module, enable more frequent comparisons within that module, and repeat this process until finding the cause of the difference.
Our experiences and that of our users has determined that most of the errors found with PCAST are due to missing data or update directives, where either the CPU or the GPU is working on stale data values updated by the other.
When comparing CPU and GPU runs, a frequent source of differences arises from sum reductions. The parallel code on the GPU accumulates the sum reduction in a different order than the CPU, so roundoff error accumulates differently. We are looking at ways to try to reduce those differences, to satisfy the programmer that the differences are only due to roundoff error on the summation, not from some other error.
Summary
This post described the PCAST features to support software testing, specifically comparing results from a known good program against a test run of a modified program that is supposed to perform the same computations. The modifications can be source changes, linking against a different library or build differences (compiler flags), or changing to a new processor type.
PCAST is supported by the C, C++, and Fortran HPC compilers included in the NVIDIA HPC SDK. Download it for free today and give it a try. We’ve heard several success stories from users and would like to hear back from you, with success stories, feature requests, or suggestions for improvements.