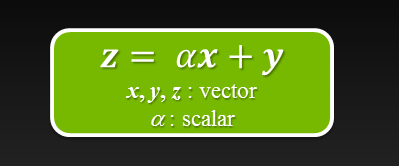Aug 21, 2025
Less Coding, More Science: Simplify Ocean Modeling on GPUs With OpenACC and Unified Memory
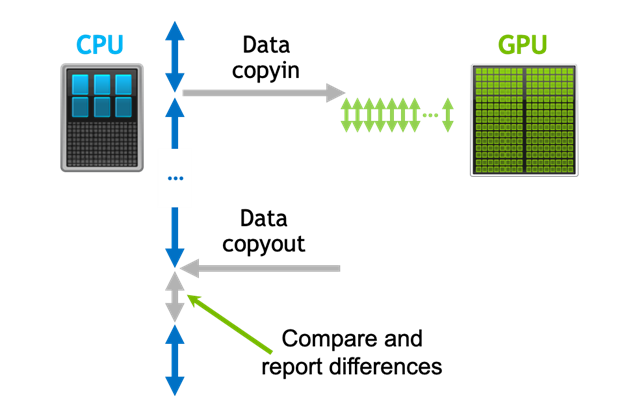
NVIDIA HPC SDK v25.7 delivers a significant leap forward for developers working on high-performance computing (HPC) applications with GPU acceleration. This...
11 MIN READ